# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
都知道AI卷,卷大语言模型,卷多模态,卷视频,反正啥玩意都都卷。
AI绘图作为跟大语言模型并驾齐驱的最成熟的模态之一。
那更是卷到飞起。
前几天,Meta这个搅屎棍,正式公开上线了他们的AI绘图模型,叫Meta Imagine,就是这个玩意。
网址:https://imagine.meta.com/ (对魔法要求比较高,找个美国的干净的节点)
最关键的是吧,他免费。
你说他是不是搅屎棍。。。
但是Meta确实也有这个底气,毕竟你架不住他卡多啊。。
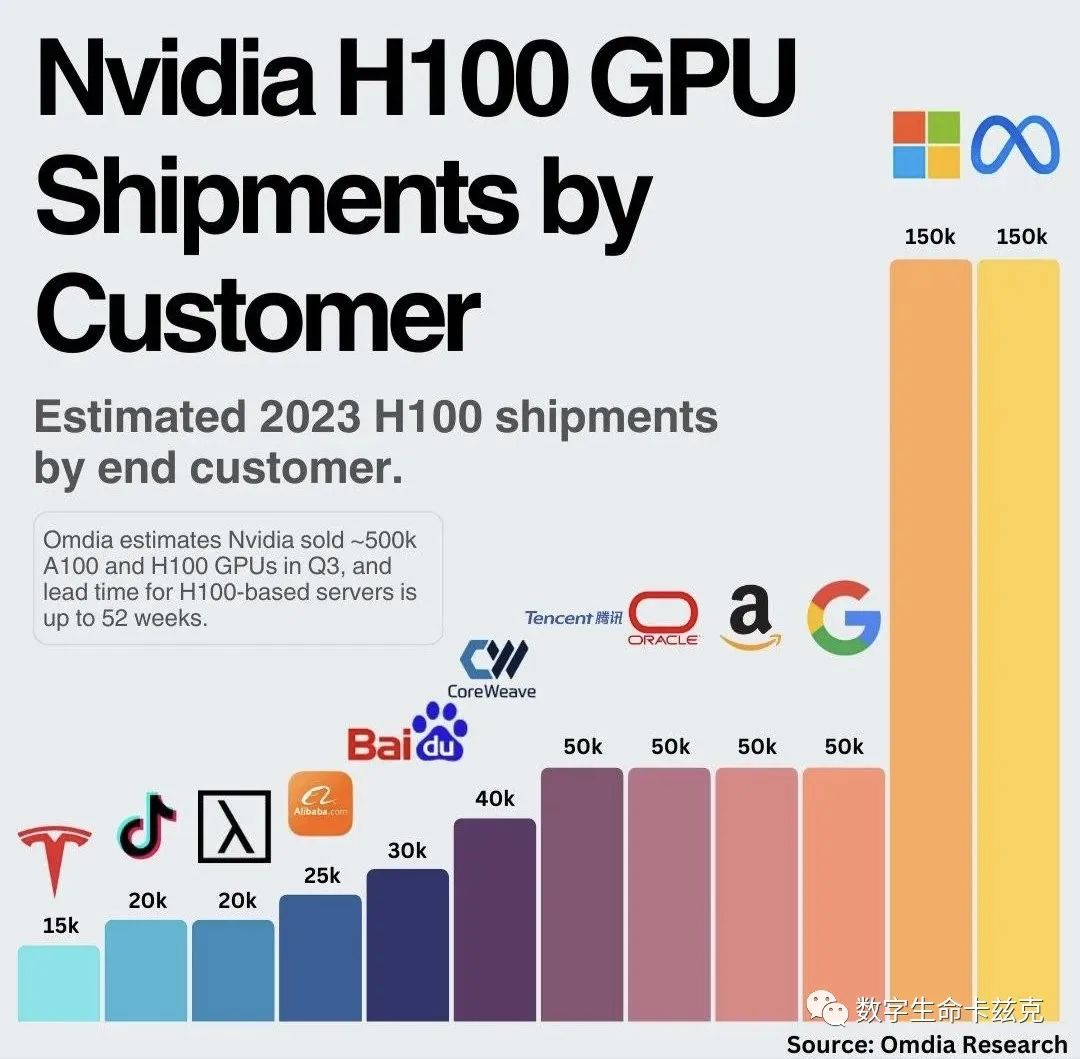
一个不做云服务的,搞这么多卡。。。甚至囤的H100超过了微软。。
你说他想干啥。。。
当然是来当搅屎棍了(笑。
当然,其实前两天就想按我的体系,去评测一下Meta这个免费的AI绘图了,但是因为PIKA1.0的关系,实在没有空,这周六下午才腾出手来好好的去玩。
正好也想借着这个机会,来对比评测一下我心中的现在四个比较大的AI绘图模型:
Meta Imagine,Midjourney,Adobe Firefly,Dalle。

SDXL之所以没放在里面是因为他毕竟是个开源模型,是靠后续大神们的微调和生态来玩的,而且原生的质量确实有一点点差。。。
所以主要来对比这四个大模型。
我会从细节质量、审美(构图色彩等)、风格多样化、语义理解这四个维度来评测,每个维度3个Prompt,同时每个Prompt我会在AI绘图模型中roll3次,取效果最具有代表性的那个图,尽量减少偏见。
同时,为了有最后整体可视化的评分让大家看着更直观,所以我会进行打分。在每个案例中,第一名为4分,第二为3分,第三为2分,最后一名为1分,最后计算和。
OK,让我们开始。
主要测试AI绘图对于细节的表现能力,比如人物面部皮肤的质感、比如织物纹理的细节、场景细微元素的细节等等,这个是对模型精度和输出质量一个非常重要的考量。
Prompt1:Portrait of a 2000s blonde woman posing on a sports car, white wired headphones, expressionless, 2000s hairstyle, 2000s fashion, sun rays, light teal and
amber,Cinestill 50D
2000年代金发女郎在跑车上摆姿势的肖像,白色有线耳机,面无表情,2000年代发型,2000年代时尚,太阳光线,浅青色和琥珀色,Cinestill 50D

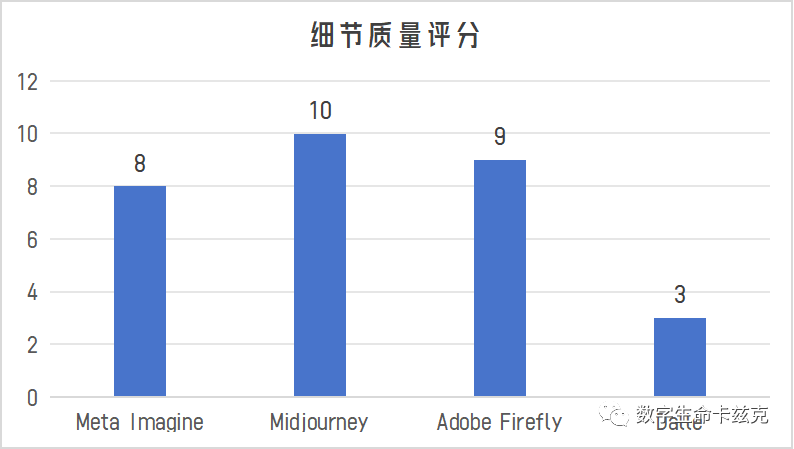
明显可以看出,Adobe在人物皮肤质感和衣服质感上最佳,Meta和MJ其次,Dalle3最差;耳机细节都有问题,Dalle3取巧了所以没有BUG,Meta直接没给你画;背景的细节都差不多。
Adobe:4,MJ:3,Meta:2,Dalle:1。
-
Prompt2:Amazing photo of golden retriever chasing tennis ball underwater, close-up portrait
金毛猎犬在水下追逐网球的惊人照片,特写肖像

Meta整体最好,MJ其次,被水沾湿的细节都画出来了,Adobe狗身上的细节少了一些,Dalle3还是拉了,水的气泡的细节崩了。
Meta:4,MJ:3,Adobe:2,Dalle:1。
-
Prompt3:A girl with a bunny sitting and smiling in 1970s fashion in a field of flowers
一个带着兔子的女孩,穿着 1970 年代的时尚,坐在花丛中微笑
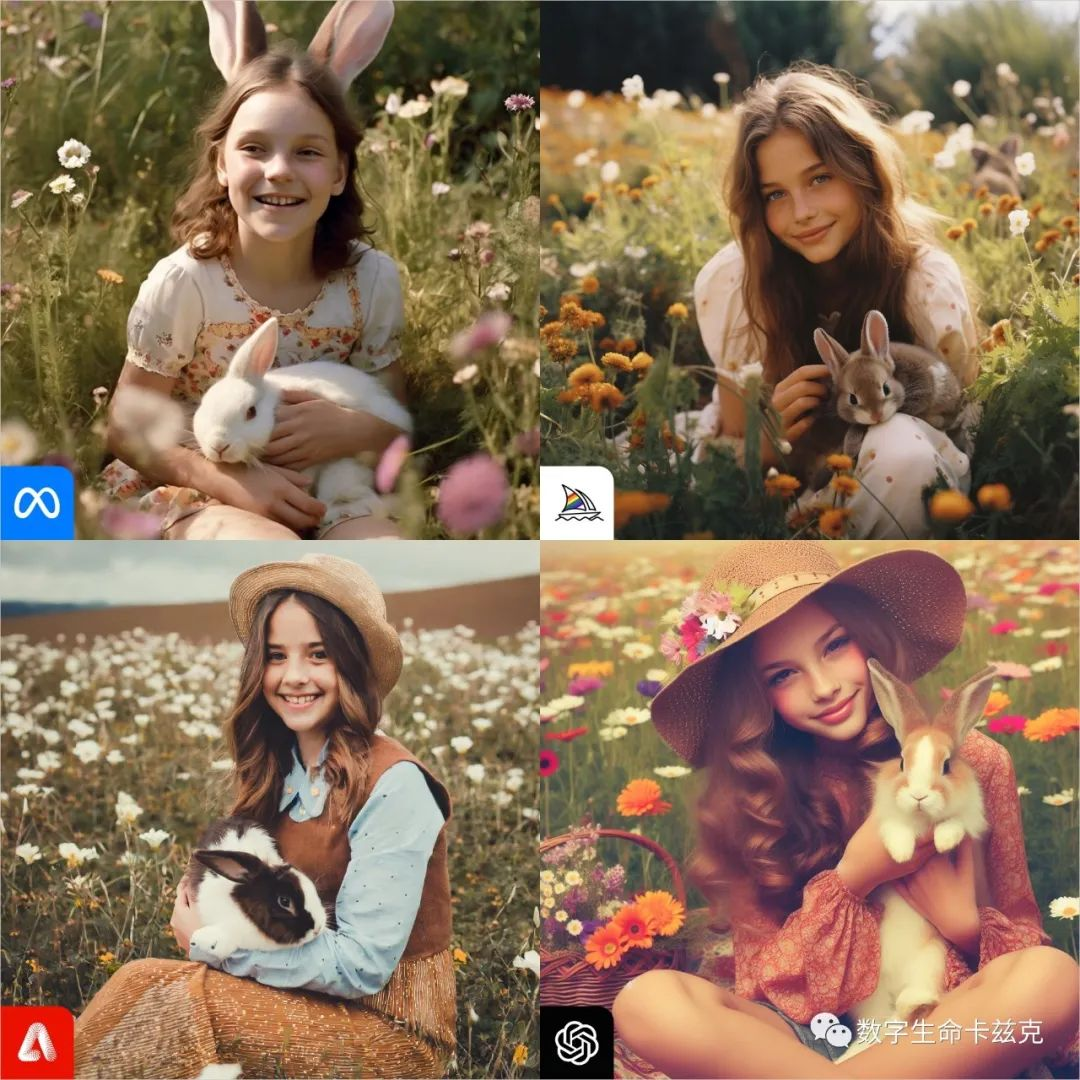
MJ完胜,花和兔子、头发细节基本都没啥可挑的,Adobe的细节很足但是裤子崩了,Meta的面部皮肤质感很难受,Dalle基本就没啥东西,一股子油画感。
MJ:4,Adobe:3,Meta:2,Dalle:1。
在细节质量上,总分如下:
主要测试AI绘图的审美能力,一张图好不好看,是美是丑,除了细节之外,更多的还需要看模型的审美能力,比如构图、色彩、光影等等,审美强,出的图才好看。
Prompt1:Product shot of juicy burger, artisan, rustic, food photography, delicious, close-up
多汁汉堡的产品拍摄, 工匠, 质朴, 食物摄影, 美味, 特写镜头

一张非常强调审美的图,Meta的色彩几乎就不能看,让人毫无食欲,Dalle的构图问题很大背景太乱,两个瓶子跟门神一样,MJ也没有构图就一个大主体,Adobe完胜。
Adobe:4,MJ:3,Dalle:2,Meta:1。
-
Prompt2:Dungeons and Dragons, Close up of a fire breathing flying dragon, cinematic shot
龙与地下城,喷火飞龙的特写,电影镜头
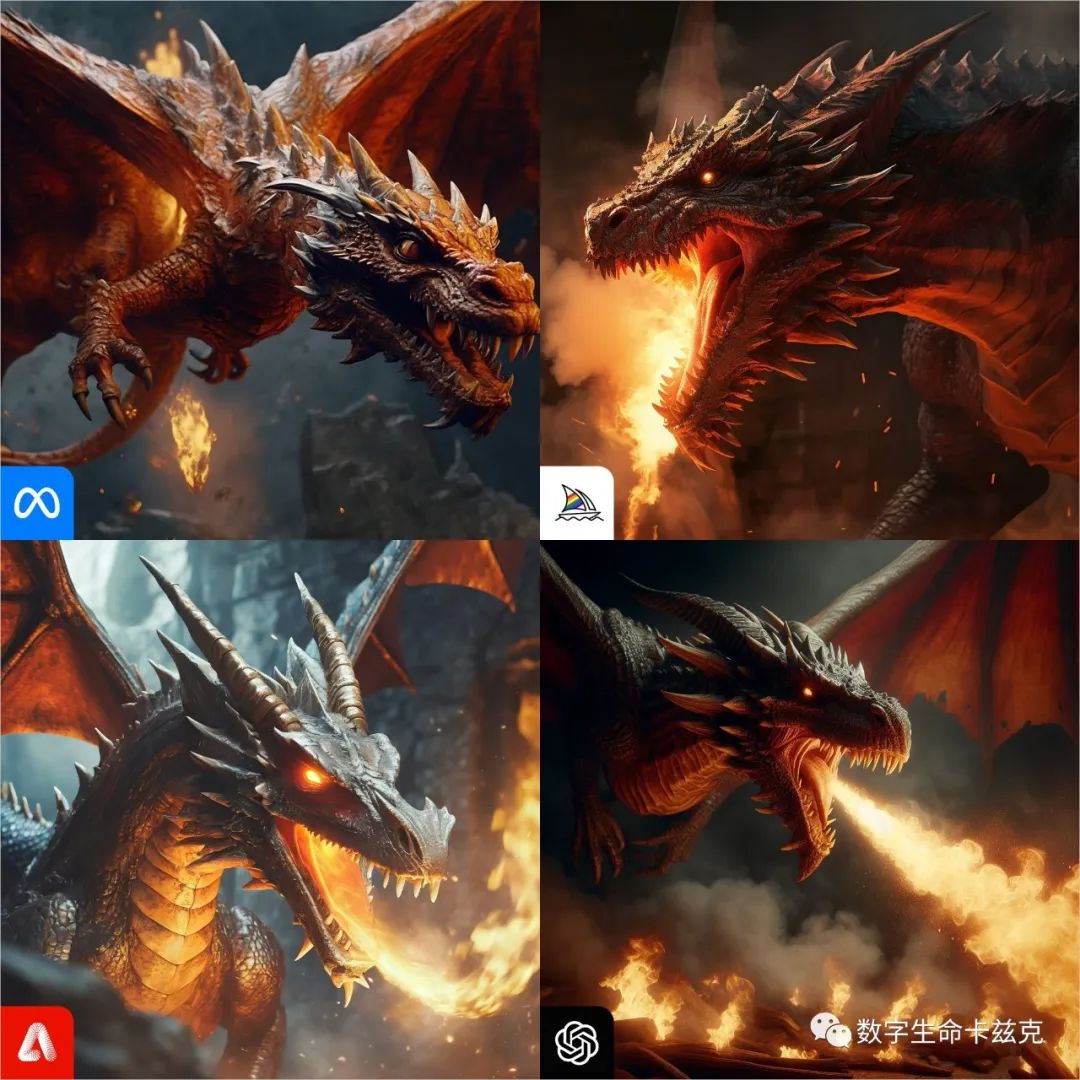
特写镜头,很强调构图,还有火与龙身的光影对比,Meta的龙极其呆逼,其他所有的龙眼睛也都会发光来做强调,就它真画了个眼睛上去,色彩和构图也不太行,整体最佳还是Adobe,色彩和构图都棒,其次是MJ,再次是Dalle,构图差点意思,太偏左上了,最次是Meta。
Adobe:4,MJ:3,Dalle:2,Meta:1。
-
Prompt:Diagonal Shot. Constantinople, 1453, masked sorceress, in the style of biblical drama, movie scene, low saturation, muted colors, extreme detail, 8K
对角线拍摄。君士坦丁堡,1453年,蒙面女巫,圣经戏剧风格,电影场景,低饱和度,柔和的色彩,极端细节,8K
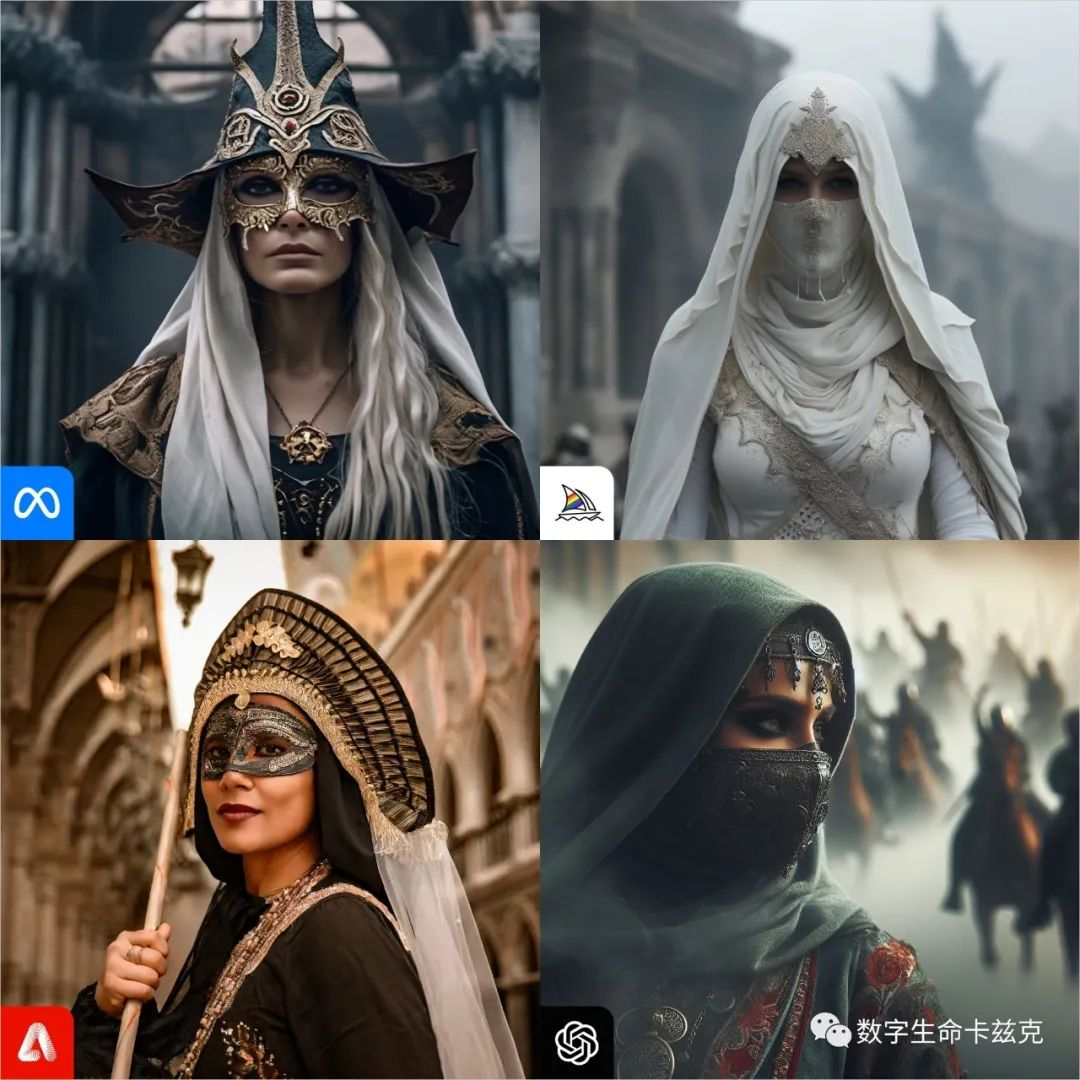
MJ的构图和色彩质感基本爆杀全场了,Adobe完全没理解我最后的低饱和度,Dalle的构图也很奇怪。
MJ:4,Meta:3,Adobe:2,Dalle:1。
在审美上,总分如下:
主要测试AI绘图对于风格的包容度,比如皮克斯风格、吉卜力风格、折纸艺术等等,理论上是需要大规模用几百个艺术风格去测成功率的,但是我个人精力有限,所以简单测试3个稍微常见一点但是不是那么烂大街的艺术风格吧。
Prompt1:an anime illustration of a samurai girl carrying a ninja sword, in the style of ethereal brushstrokes, ink painting, dark white and dark gray, fluid formation
拿着忍者剑的武士女孩的动画插图,风格空灵,水墨画,深白色和深灰色,流体形成

在水墨画这块,得神韵得还是MJ和dalle,Meta那个笔触就很诡异一点都不连贯断断续续得,Adobe画出来就感觉一个日漫一样。
MJ:4,Dalle:3,Meta:2,Adobe:1。
-
Prompt2:small boy looking out of his bedroom window into a cyberpunk world, pixelated, 8 bit style
小男孩从卧室窗户望向赛博朋克世界,像素化,8 位风格

8bit的像素画+赛博朋克,Adobe和Dalle都画出了这种风格,Meta差了一些,MJ是完全没画出。在像素化上,Adobe确实最好。
Adobe:4,Dalle:3,Meta:2,MJ:1。
-
Prompt3:Colorful logo of a French restaurant called "Khazix" with a flying seagull
一家名为“Khazix”的法国餐厅的彩色标志,上面有一只飞翔的海鸥

在做Logo上,Dalle3的精准文字目前确实是独一档,无人可比,logo的设计上,Dalle最强,MJ次之,Adobe普普通通,Meta的图形和细节简直稀碎。
Dalle:4,MJ:3,Adobe:2,Meta:1。
在风格多样化上,总分如下:
主要测试AI绘图对于复杂语义的理解能力,能否将文本内容都能清晰的表达出来并保证生成图片的质量。
Prompt1:A cup of coffee sitting on a table in front of a window; outside the window is a futuristic city; a futuristic monorail can be seen close by; many lush plants around; shot from ground floor; clouds above
窗前的桌子上放着一杯咖啡;窗外是一座未来的城市;附近可以看到未来派的单轨列车;周围有许多茂盛的植物;从一楼拍摄;上面有云

MJ崩了,是唯一没画出列车的,Adobe画了列车但是轨道有BUG,Meta画出来了但是很乱,Dalle完美。
Dalle:4,Meta:3,Adobe:2,MJ:1。
-
Editorial photography of astronaut cooking Christmas colorful chocolate honey cookies on spaceship, Christmas honey cookies floating around astronaut, no gravity, in spaceship, levitated
宇航员在宇宙飞船上烹饪圣诞彩色巧克力蜂蜜饼干的编辑摄影,圣诞蜂蜜饼干漂浮在宇航员周围,没有重力,在宇宙飞船中,悬浮

Dalle暴揍全场,唯一理解了圣诞、彩色元素的,Adobe在做饼干但是没这些元素,MJ好看是好看但是快把自己炸没了,饼干都没在做,Meta的饼干没漂浮。。。
Dalle:4,Adobe:3,Meta:2,MJ:1。
-
Prompt3:Shot diagonally. Cinematic shot of several astronauts in the space station, surrounding a chromium metal water droplet suspended in the air, the surface of the water droplet can reflect everything like a mirror, indoor scene
对角线拍摄。几名宇航员在空间站中的电影镜头,围绕着一个铬金属水滴周围,铬金属水滴悬浮在空中,水滴的表面可以像镜子一样反射一切,室内场景

之前做《三体》时一个天坑镜头,镜面能反射一切的铬金属水滴没几个AI能理解的,Dalle不亏是语义之王,Adobe理解成了从天上往下滴的水滴,Meta和MJ不知道在玩个啥。。。
Dalle:4,Adobe:3,MJ:2,Meta:1。
在语义理解上,总分如下:
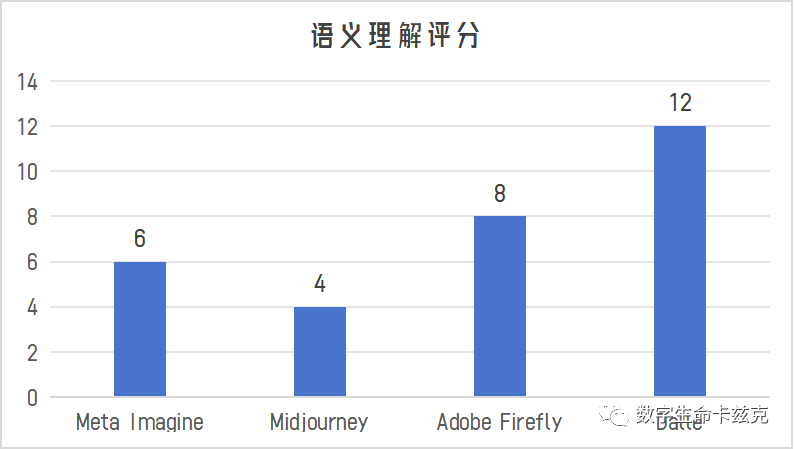
在四个维度评完了以后,我们应该能对这几个大模型有大概的了解了。
但是为了更直观一些,我再来做个雷达图吧。
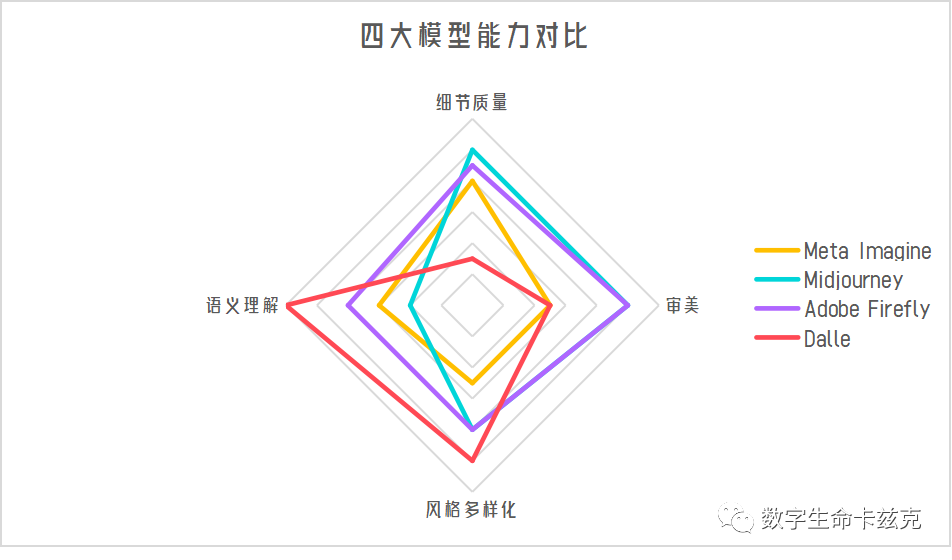
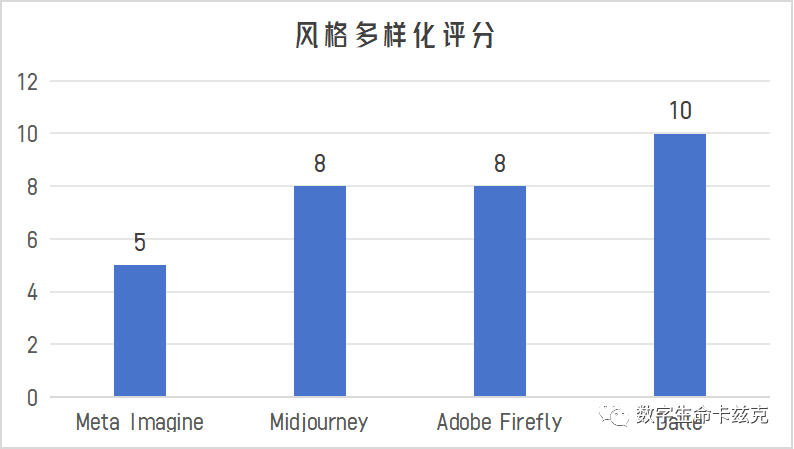
细节质量方面,MJ > Adobe > Meta > Dalle。
审美方面,MJ = Adobe > Meta = Dalle。
风格多样化方面,Dalle > Adobe = MJ > Meta。
语义理解方面,Dalle > Adobe > Meta > MJ。
综合看,目前Adobe是最水桶的,其次是MJ,然后是Meta,Dalle偏科过于严重。
虽然只放出来了12个prompt,但是我在后面跑了将近14个小时,测了300多个例子,选出了典型。。快吐了。。
希望这个评测,能抛砖引玉吧,让大家对AI绘图综合有一些了解。
文章来自于微信公众号 “5G创见”,作者 “数字生命卡兹克”




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
