# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
端侧设备迎来了新架构的 AI 模型。
本周五凌晨,谷歌正式发布、开源了全新端侧多模态大模型 Gemma 3n。
谷歌表示,Gemma 3n 代表了设备端 AI 的重大进步,它为手机、平板、笔记本电脑等端侧设备带来了强大的多模式功能,其性能去年还只能在云端先进模型上才能体验。
Gemma 3n 的特性包含如下几个方面:
谷歌表示,要想实现设备性能的飞跃需要彻底重新思考模型。Gemma 3n 独特的移动优先架构是其基础,而这一切都始于 MatFormer。
MatFormer:一种型号,多种尺寸
Gemma 3n 的核心是 MatFormer(Matryoshka Transformer) 架构,这是一种专为弹性推理而构建的新型嵌套 Transformer。你可以将其想象成俄罗斯套娃:一个较大的模型包含其自身更小、功能齐全的版本。这种方法将俄罗斯套娃表征学习的概念从单纯的嵌入扩展到所有 Transformer 组件。

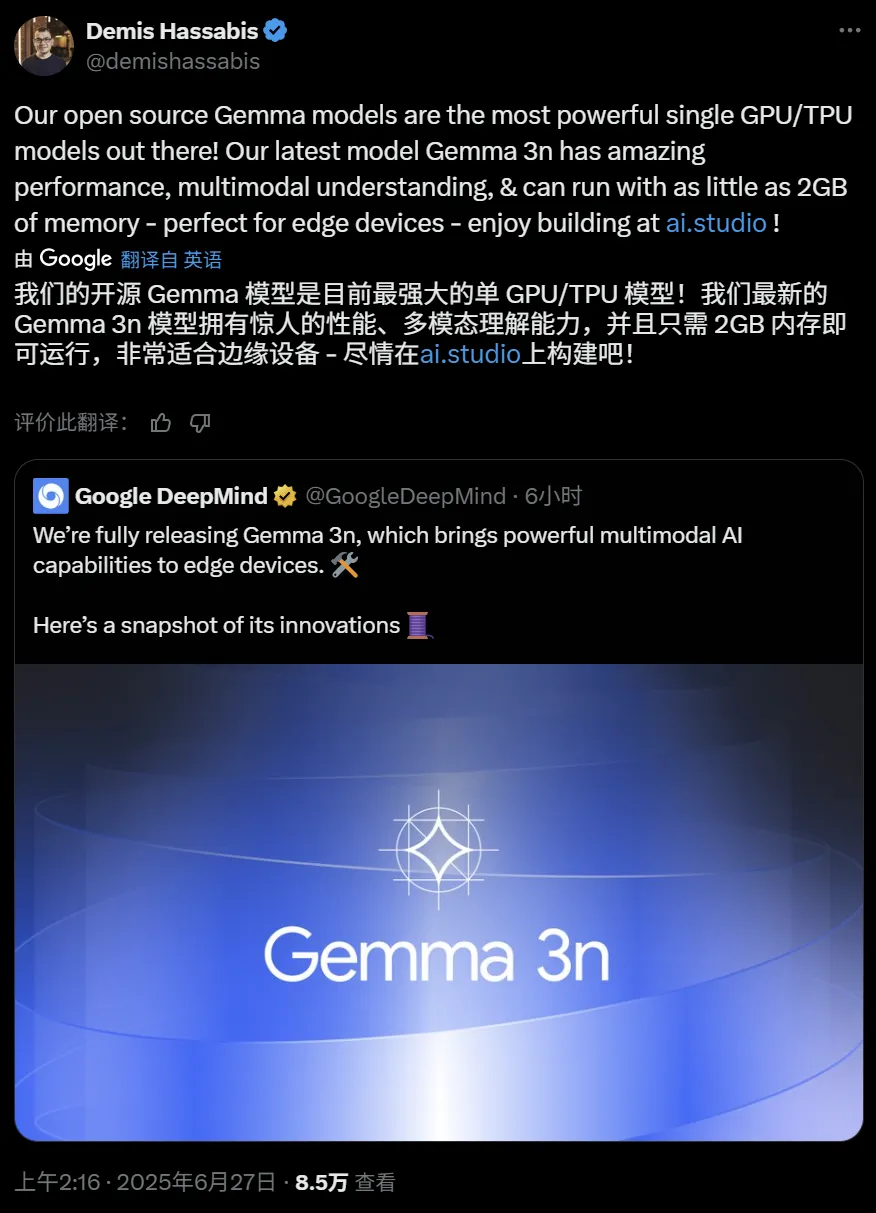
因此,MatFormer 在训练 4B 有效参数 (E4B) 模型时,会同时优化 2B 有效参数 (E2B) 子模型,如上图所示。这为开发者提供了两项强大的功能和用例:
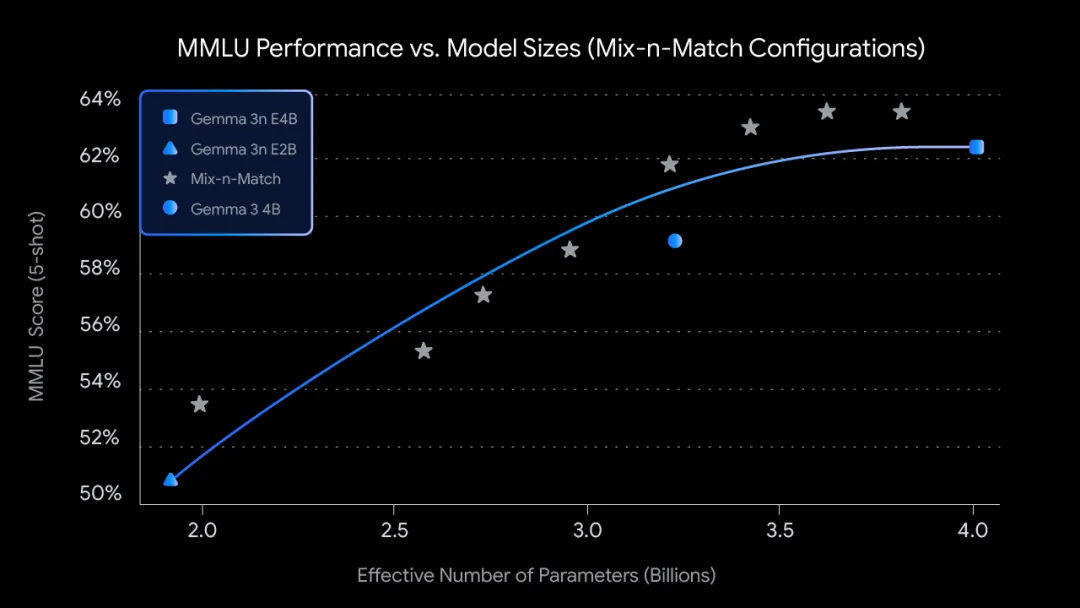
不同模型大小的预训练 Gemma 3n 的 MMLU 分数(使用 Mix-n-Match)。
展望未来,MatFormer 架构也为弹性执行铺平了道路。虽然此功能不属于今天发布的实现,但它允许单个部署的 E4B 模型在 E4B 和 E2B 推理路径之间动态切换,从而根据当前任务和设备负载实时优化性能和内存使用情况。
每层嵌入(PLE):释放更多内存效率
Gemma 3n 模型采用了逐层嵌入 (PLE) 技术。这项创新专为设备部署而设计,可大幅提高模型质量,同时不会增加设备加速器 (GPU/TPU) 所需的高速内存占用。
虽然 Gemma 3n E2B 和 E4B 模型的总参数数量分别为 5B 和 8B,但 PLE 允许很大一部分参数(与每层相关的嵌入)在 CPU 上加载并高效计算。这意味着只有核心 Transformer 权重(E2B 约为 2B,E4B 约为 4B)需要存储在通常较为受限的加速器内存 (VRAM) 中。

通过每层嵌入,你可以使用 Gemma 3n E2B,同时仅在 AI 加速器中加载约 2B 个参数。
KV Cache 共享:更快的长上下文处理
处理长内容输入(例如来自音频和视频流的序列)对于许多先进的设备端多模态应用至关重要。Gemma 3n 引入了键值缓存共享 (KV Cache Sharing),旨在加快流式响应应用的首个 token 获取时间 (Time-to-first-token)。
KV Cache Sharing 优化了模型处理初始输入处理阶段(通常称为「预填充」阶段)的方式。来自局部和全局注意力机制的中间层的键和值将直接与所有顶层共享,与 Gemma 3 4B 相比,预填充性能显著提升了两倍。这意味着模型能够比以往更快地提取和理解较长的提示序列。
音频理解:将语音引入文本并进行翻译
在语音方面,Gemma 3n 采用基于通用语音模型(USM)的高级音频编码器。该编码器每 160 毫秒的音频生成一个 token(约每秒 6 个 token),然后将其作为语言模型的输入进行集成,从而提供声音上下文的精细表示。
这种集成音频功能为设备开发解锁了关键功能,包括:
经过实践可知,Gemma 3n 在英语与西班牙语、法语、意大利语、葡萄牙语之间的翻译 AST 效果尤为出色。对于语音翻译等任务,利用「思维链」提示可以显著提升翻译效果。以下是示例:
<bos><start_of_turn>user
Transcribe the following speech segment in Spanish, then translate it into English:
<start_of_audio><end_of_turn>
<start_of_turn>model
Gemma 3n 编码器在发布时已可以处理长达 30 秒的音频片段,但这并非极限。底层音频编码器是一个流式编码器,能够通过额外的长音频训练处理任意长度的音频。后续的实现将解锁低延迟、长流式传输应用程序。
MobileNet-V5:最先进的视觉编码器
除了集成的音频功能外,Gemma 3n 还配备了全新的高效视觉编码器 MobileNet-V5-300M,为边缘设备上的多模态任务提供最先进的性能。
MobileNet-V5 专为在受限硬件上实现灵活性和强大功能而设计,可为开发人员提供:
这一性能水平是通过多种架构创新实现的,其中包括:
得益于新架构设计和先进蒸馏技术,MobileNet-V5-300M 在 Gemma 3 中的表现显著优于基线 SoViT(使用 SigLip 训练,未进行蒸馏)。在 Google Pixel Edge TPU 上,它在量化的情况下实现了 13 倍的加速(不使用量化的情况下为 6.5 倍),所需参数减少了 46%,内存占用减少了 4 倍,同时在视觉语言任务上实现了更高的准确率。
谷歌表示,更多细节会在即将发布的 MobileNet-V5 技术报告中展示。
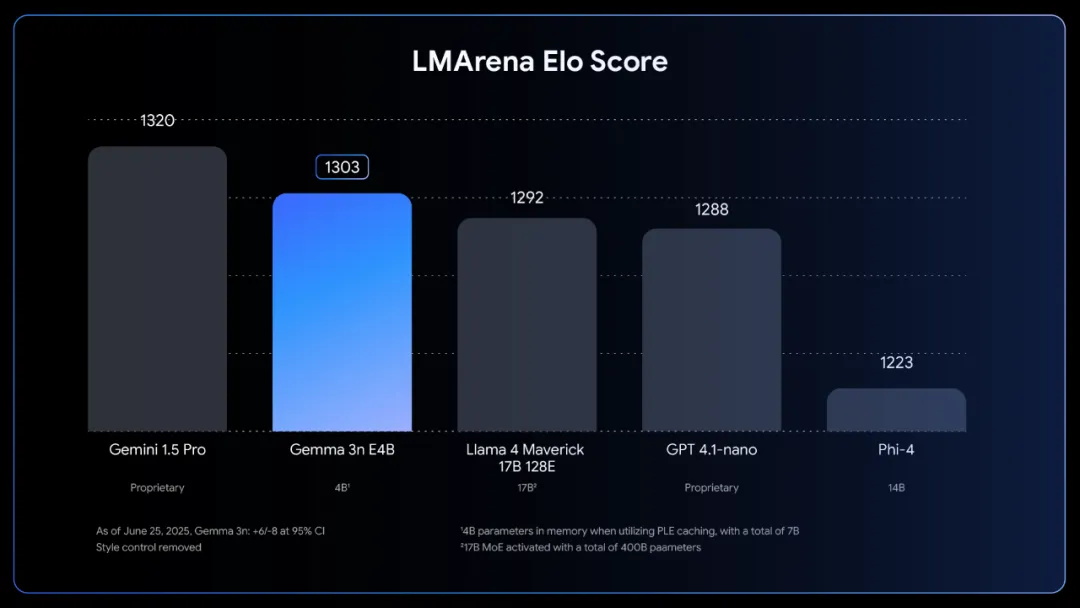
5 月 20 日,谷歌 DeepMind 在 I/O 大会上宣布了 Gemma-3n,其小体量、高性能和低内存占用的特性让人印象深刻。
谷歌的首个 Gemma 模型于去年年初发布,目前该系列的累计下载量已经超过了 1.6 亿次。
文章来自微信公众号 “ 机器之心 ”



【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
