# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
通过“视觉神经增强”机制,直接放大模型中的视觉关键注意力头输出,显著降低模型的幻觉现象。
中科院自动化所联合新加坡国立大学、东南大学等团队提出大模型幻觉的一种高效的解决方案VHR。

此前的主流方法主要通过对齐训练或输出层分布修正来缓解LVLMs的幻觉问题,但这些方法仅作用于模型的最终输出阶段,未能深入干预其内部表征和生成机制,因此难以实现高效且精准的幻觉抑制。
大型视觉语言模型(LVLMs)能够结合视觉和语言信息生成流畅的文本回答,但其输出常因过度依赖语言先验知识而非图像真实内容,导致事实性错误。
在图1中,通过对照实验揭示语言先验与幻觉现象之间的关联。当给定图像并提示模型「请详细描述该图像」时,模型生成的描述中错误地包含「椅子」和「杯子」这类图像中未出现的实体,呈现出典型的幻觉表现。
为了验证这种幻觉是否源于语言偏好,移除原始图像,重新提示模型根据此前生成的正确描述「图中有一张木桌,桌上有一个花瓶」进行补全。结果显示,模型补全的内容与之前的幻觉部分显著重叠,这表明模型并非基于视觉依据进行推理,而是系统性地依赖语言共现模式来生成内容。
这一现象证实了LVLMs产生的幻觉并非随机错误,而是受到其内部语言建模偏好的系统性影响。

图1. 揭示LVLMs中幻觉现象与语言偏好关联的示例。当幻觉发生时(对话1),移除图像输入并提示模型补全描述(对话2)。其输出内容与幻觉生成部分高度相似。
当前主流解决方案(如对齐训练、解码优化)主要通过对输出层的结果进行干预来缓解幻觉问题。这类”末端干预”方法虽然简单有效,但未能触及模型产生幻觉的根本原因——即注意力机制内部的不平衡性。最新研究发现:
这种功能分化形成了潜在的风险,可能导致模型过度依赖参数化知识而忽视视觉证据。
为量化这一现象,提出视觉感知头散度(VHD)——该指标能测量每个注意力头对视觉输入的响应强度。通过VHD分析发现模型中的少数注意力头对视觉信息表现出显著敏感性,而大多数头则更依赖于语言规律。这很可能是多模态模型经常产生幻觉的关键原因之一。
基于此开发了视觉感知头增强(VHR)技术。该方法通过识别并强化对视觉信息敏感的注意力头的输出,有效减少了模型对语言先验的依赖,从而显著降低了幻觉现象。实验证明,VHR在多个基准测试中均优于现有方法,同时保持了高效性,几乎不增加额外的时间开销。
视觉感知头的识别
团队首先提出VHD指标,用于量化注意力头对视觉信息的敏感度。VHD旨在衡量每个注意力头在生成过程中对视觉上下文的依赖程度。具体而言,对于第 层的第 个注意力头,其VHD得分计算如下:
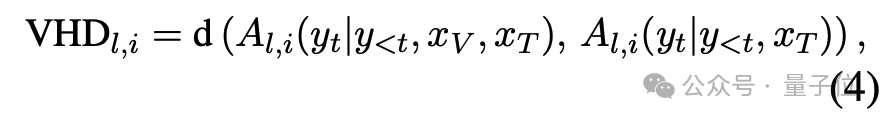
其中,为欧式距离,表示注意力头的输出, 和 分别代表视觉和文本输入。VHD通过对比有无图像输入时注意力头输出的差异,量化其对视觉信息的敏感度。实验发现,仅有少数注意力头表现出高VHD值,表明模型内部存在视觉感知与语言偏好头的显著分化。
进一步,我们提出 Token-VHD(T-VHD)指标,聚合每层中VHD得分最高的 个头,以评估生成每个词时模型对视觉信息的依赖程度:
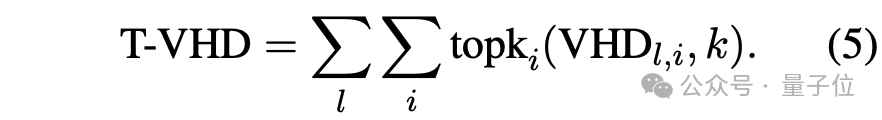
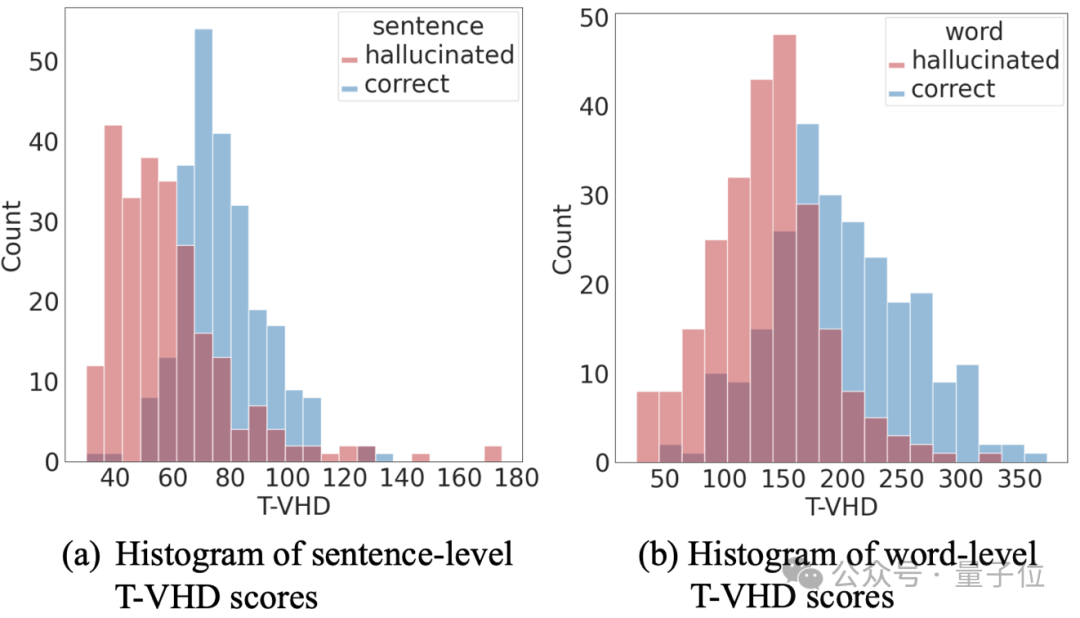
统计表明,幻觉词通常对应较低的T-VHD值,验证了语言偏好是幻觉的主要诱因之一。
视觉感知头的增强
基于VHD的分析,VHR通过以下步骤动态强化视觉敏感的注意力头:
1. 异常VHD过滤:为避免强化因视觉缺失而异常激活的注意力头,对满足以下条件的VHD得分置零:
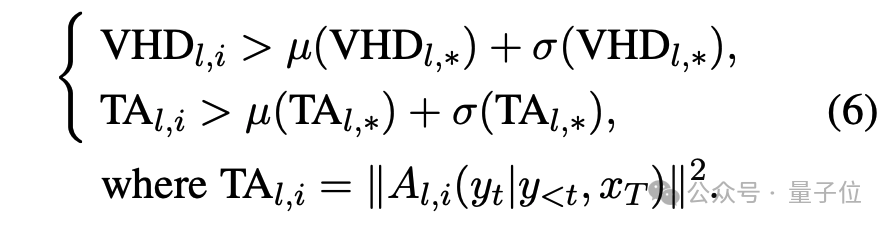
其中 衡量无视觉输入时注意力头的激活强度。
2. 注意力头选择与强化:每层选择VHD得分前50%的注意力头,将其输出缩放 $\alpha$ 倍。
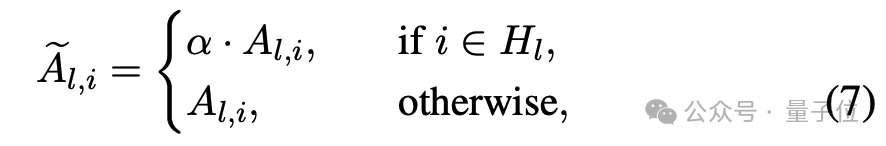
其中 为高VHD注意力头集合。此操作通过重定向注意力模块的输出方向,增强视觉上下文的贡献。
3. 分层渐进式增强:为避免层间干扰,采用逐层强化策略,并在首步生成时确定每层的关键注意力头。
为了评估VHR方法的有效性,在CHAIR、POPE和LLaVABench三个基准及多个大模型上与基线方法对比了效果。部分定量的实验结果如下表所示。更多结果烦请移步论文或代码。
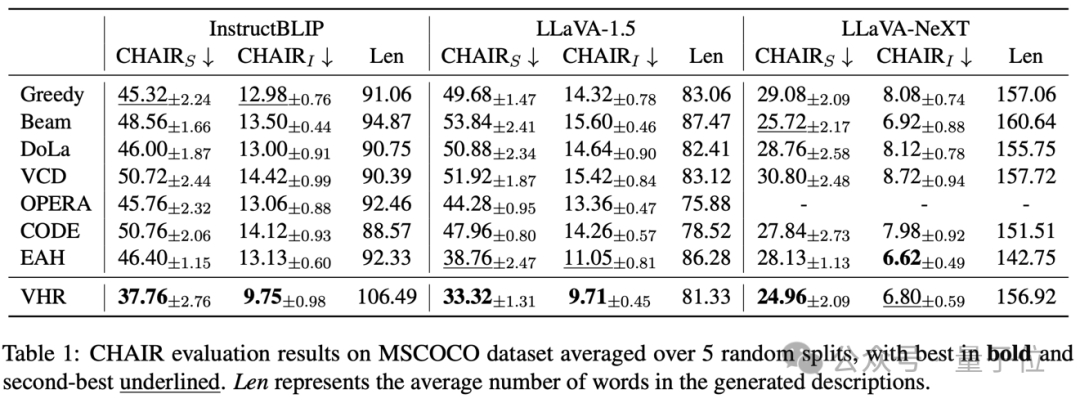
△表1. MSCOCO数据集上的CHAIR评估结果
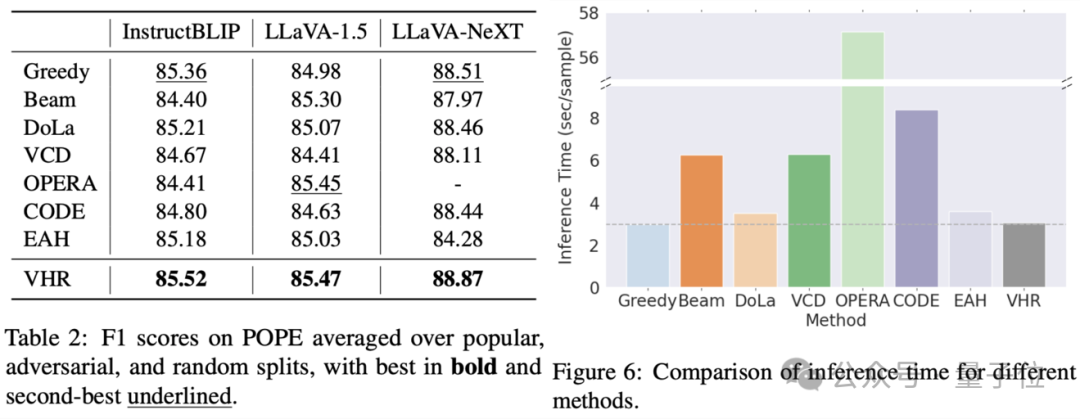
△表2. POPE数据集上的F1分数结果;图6. 不同方法的推理时间对比
此外,SSL方法从语义引导的角度出发,通过分析模型内部表征空间来缓解LVLMs的幻觉问题。

该方法受到稀疏自编码器(SAEs)在LLMs语义表征研究中成功应用的启发,将其拓展到LVLMs领域:首先利用SAE识别出”幻觉”和”真实”两种语义方向,然后在模型特定层进行针对性干预。具体而言,对于视觉信息融合阶段,注入真实语义方向以增强视觉表示的忠实性;对于语言生成阶段,则通过适度抑制模型在幻觉语义方向上的投影,减少幻觉内容的产生。
值得注意的是,虽然本研究使用在LLaVA-Next-8b模型上训练的SAE,但其识别的语义方向在其他架构的LVLMs(如LLaVA1.5-7b,InstructBLIP-7b)中也起到了缓解幻觉的作用,展现出良好的跨模型迁移能力。这一发现不仅验证了SAE在LVLM语义解析中的普适性价值,更为跨模型幻觉缓解研究开辟了新路径。
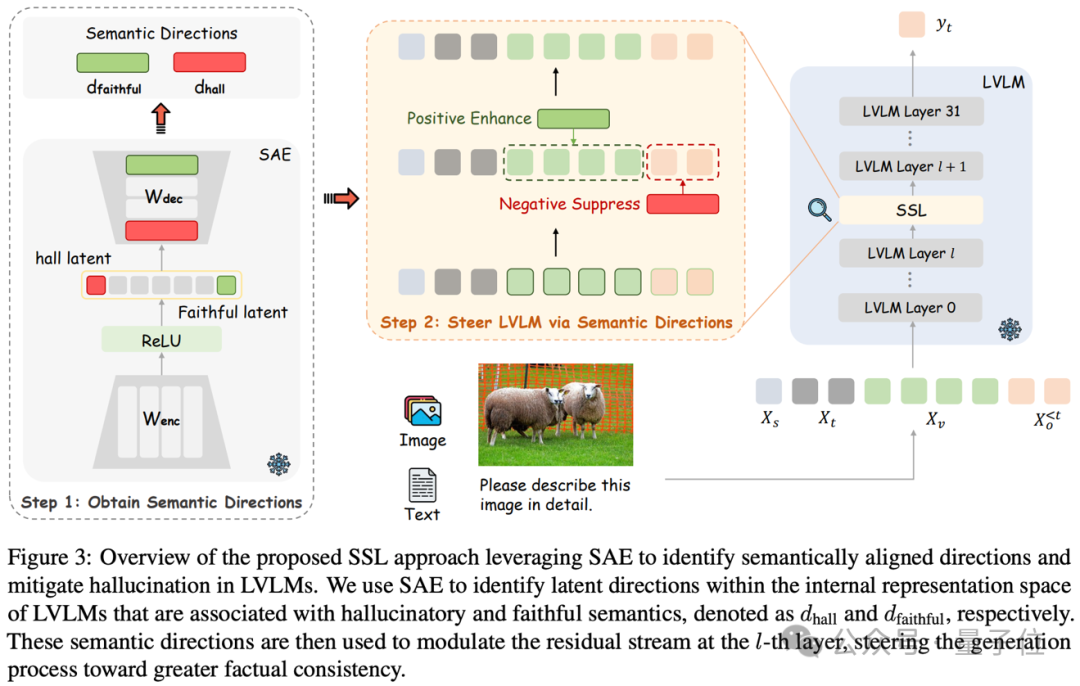
图3. SSL方法框架图:通过SAE识别LVLM内部表征空间中的幻觉语义方向和真实语义方向,并在特定层通过调节残差流引导生成过程,提升事实一致性。
VHR论文链接: https://arxiv.org/abs/2412.13949
代码链接: https://github.com/jinghan1he/VHR
SSL论文链接: https://arxiv.org/abs/2505.16146
文章来自于微信公众号“量子位”。


