# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在高质量视频生成任务中,扩散模型(Diffusion Models)已经成为主流。然而,随着视频长度和分辨率的提升,Diffusion Transformer(DiT)模型中的注意力机制计算量急剧增加,成为推理效率的最大瓶颈。这是因为在视频生成中,DiT 通常使用 3D 全局注意力来建模时空一致性,虽然效果出色,但计算量会随着 token 数量呈平方增长,带来了巨大的计算负担。在 HunyuanVideo 等视频生成模型中,注意力模块计算时间占比超过 80%,生成仅 8 秒的 720p 视频甚至需要接近一小时的时间。因此,提升视频生成模型的生成速度成为了迫切的需求。
现有视频生成加速方法,如 Sparse VideoGen(https://arxiv.org/abs/2502.01776)和 AdaSpa(https://arxiv.org/abs/2502.21079),多采用稀疏注意力机制,在 GPU 上实现了一定程度的端到端加速。然而,受限于稀疏度不足和稀疏模式设计的刚性,这些方法的加速效果仍不理想。此外,它们普遍依赖固定的稀疏算子,缺乏对输入内容的动态适应能力,难以实现细粒度、内容感知的稀疏模式调控。因此,设计一种具备动态可调性、硬件友好且无需训练的稀疏注意力机制,对提升视频扩散模型的效率与实用性具有重要意义。
近期,来自美国东北大学、香港中文大学、Adobe Research 等机构的研究团队提出了一种无需训练、即插即用的,基于动态稀疏注意力的视频扩散模型加速方法 ——DraftAttention,显著降低了注意力机制的计算开销,并且在几乎不损失生成质量的前提下,实现高达 2 倍的 GPU 端到端推理加速。

在视频生成任务中,注意力机制的计算开销是当前模型推理效率的主要瓶颈。如图所示(Figure 1),在 HunyuanVideo 模型中,随着生成视频时长从 8 秒扩展至 32 秒,注意力的计算量(FLOPs)占比迅速上升,最高超过 90%,远超其他模块。这种趋势在高分辨率视频(如 720p 或更高)中尤为显著。造成这一问题的根本原因在于:视频生成模型通常采用时空全局注意力机制,其计算复杂度随 token 数量呈平方增长。而 token 数量本身又与视频的帧数和空间分辨率成正比,因此一旦提升时长或清晰度,计算量将呈几何级数上升,导致推理速度显著下降,难以满足实际部署需求。
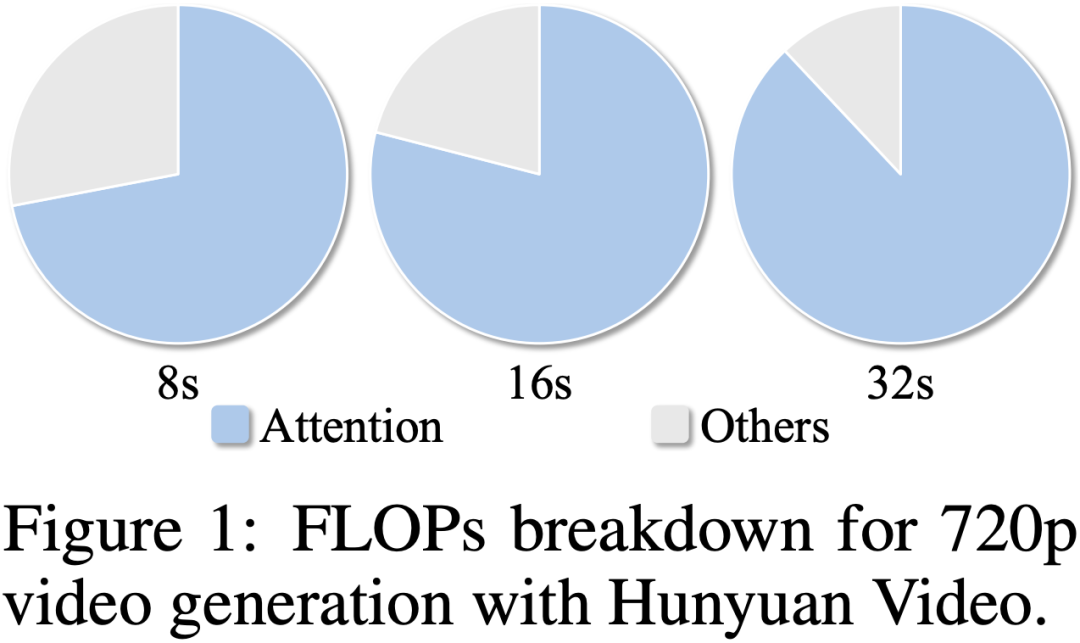
因此,引入稀疏注意力机制以降低计算开销,是视频生成加速的有效路径。然而,现有稀疏注意力方法普遍依赖固定的稀疏模式或算子,缺乏对输入内容或扩散过程动态变化的适应能力。这种 “静态稀疏” 策略无法根据不同的文本提示、多样化的视频语义,或扩散过程中的中间状态灵活调整注意力分布,最终往往在高稀疏率下造成视频生成质量的显著下降。因此,设计一种具备 “动态可调性” 的稀疏注意力机制,能够根据输入语义和扩散步长自适应调整注意力结构,是维持视频生成质量的关键。
对于视频生成模型,往往会使用 3D VAE(Variational Autoencoder)来压缩视频到隐藏空间(latent space),以显著减少扩散过程中处理的 token 数量。该隐藏空间保留了视频的核心结构,具有的三维形态,其中代表被压缩后的视频帧数(时间维度),和分别对应视频的分辨率(空间维度)。在此基础上,我们进一步关注隐藏空间内的时空冗余性。由于生成任务中存在大量冗余特征,并非所有 latent token 对注意力机制都同等重要,因此我们提出对 token 重要性进行分析:跳过低重要性的 token 注意力计算,在减少计算量的同时,依然保留关键的视频特征,从而实现有效加速且维持生成质量。
为此,本文提出了一种无需训练、动态可调、硬件友好的稀疏注意力机制 ——DraftAttention。其核心思想是:
通过低分辨率 “草图注意力图”(Draft Attention Map)高效估计 token 重要性,并据此指导高分辨率注意力计算中的稀疏模式选择。
具体流程如下:
1. 草图构建:首先,对隐藏空间的特征图进行空间下采样(如 816 平均池化),生成低分辨率版本的 Query 和 Key;
2. 草图注意力计算:基于下采样后的 Query 和 Key 计算草图注意力图(Draft Attention Map),以识别注意力图中最具信息量的区域;
3. 稀疏模式引导:从 Draft Attention Map 中选出得分最高的区域,生成结构化稀疏 Mask,用于指导高分辨率下的注意力计算;
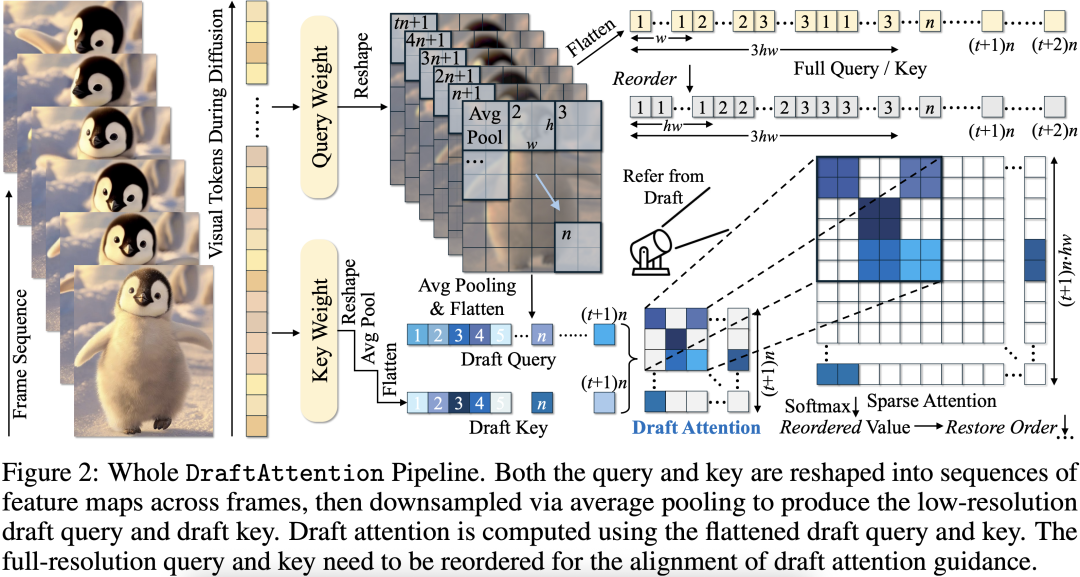
4.Token 重排以适配硬件:为了使稀疏区域连续分布、满足 GPU 对 memory layout 的需求,作者提出了一种 token 重排策略,显著提升了稀疏计算的执行效率;
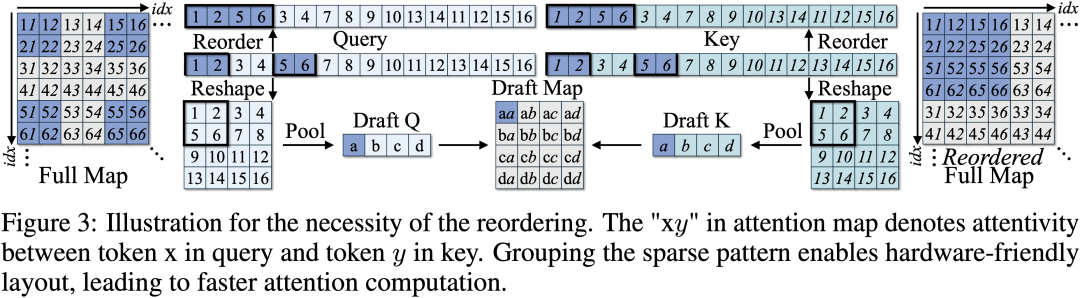
5. 无需训练、即插即用:该机制可直接插入现有视频扩散模型(如 HunyuanVideo 和 Wan2.1)中,无需任何额外训练或微调。
这一设计既从计算图层面降低了注意力的冗余,也从系统执行层面提升了稀疏算子的硬件效率,实现了视频生成速度与质量的双赢。
值得一提的是,DraftAttention 并非经验驱动的启发式方法,而是具备坚实的理论基础。我们从两个角度对其有效性进行了理论分析与证明:
1. 近似误差可控:我们证明了,使用平均池化构建的 Draft Attention Map 与原始高分辨率 Attention Map 之间的差异在 Frobenius 范数意义下是有界的,且该误差随 token 的空间连续性降低;
2. 稀疏掩码引入的误差有界:进一步地,从 Draft Attention Map 中提取的稀疏注意力模式在用于稀疏注意力加速计算后,其影响同样可以被严格界定在一个可控范围内。
这两项理论结果共同说明,草图注意力在提供高质量稀疏引导的同时,并不会显著破坏注意力机制原有的结构表达能力,从而为 DraftAttention 的实际加速效果与生成质量提供了有力的理论保障。
我们在多个主流视频生成模型上评估了 DraftAttention 的性能,包括 HunyuanVideo 和 Wan2.1。实验主要从两个维度进行评估:生成质量和推理加速。
在相同计算量下,我们与代表性稀疏注意力方法 Sparse VideoGen (SVG) 进行了对比。在多个评价指标上,DraftAttention 表现更优:
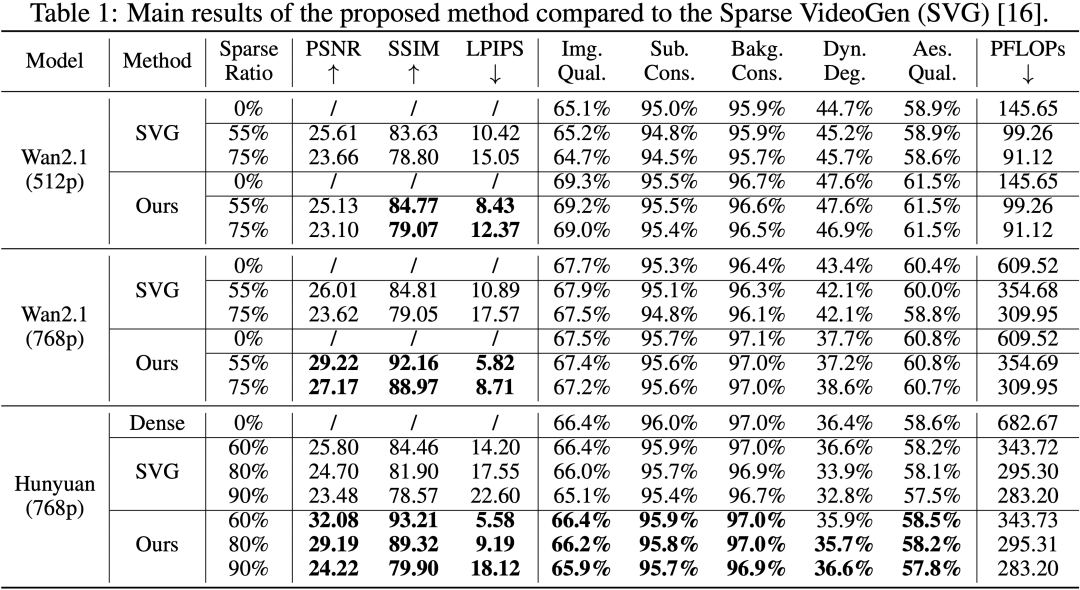
特别是在高稀疏率(如 75%~90%)设置下,DraftAttention 能更好保留视频的时空一致性和关键结构,而 SVG 等静态方法则常出现模糊、断帧等质量劣化现象。
同时,我们测试了在 H100 和 A100 GPU 上的加速效果:
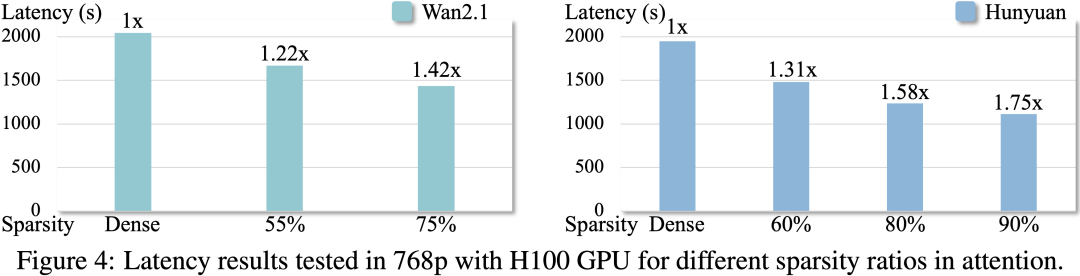
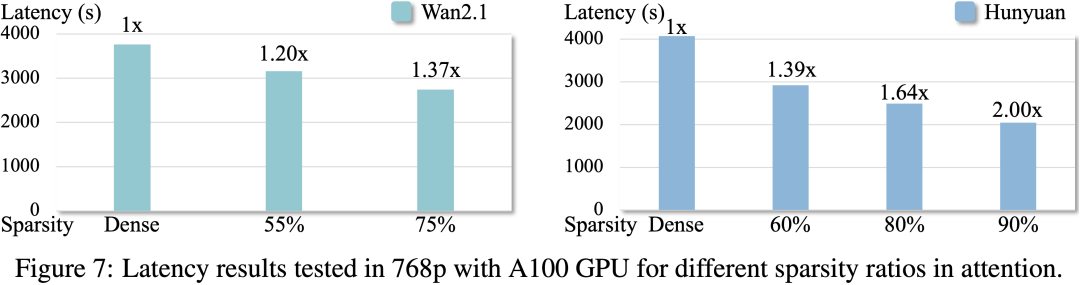
另外,我们也提供以下视频生成结果的直接对比:
Prompt: "The banks of the Thames, as the camera moves vertically from low to high."

Dense

Sparse VideoGen

DraftAttention
Prompt: "On the green grass, the white-walled Leaning Tower of Pisa stands tall. The camera moves vertically from top to bottom during filming."

Dense

Sparse VideoGen

DraftAttention
Prompt: "A blue long dress fell from the balcony clothes rack and dropped into the water on the ground."

Dense

Sparse VideoGen

DraftAttention
Prompt: "Realistic, High-quality. A woman is drinking coffee at a café."

input image

Dense

DraftAttention
DraftAttention 提供了一种简洁而高效的解决方案:通过低分辨率草图引导、结构化稀疏掩码生成与硬件友好的 token 重排,不仅显著提升了视频扩散模型的推理效率,还在高稀疏率下保持了出色的生成质量。其「无需训练、即插即用、动态可调、适配主流模型与硬件」的特性,使其具备良好的工程可落地性和研究拓展性。
未来,作者计划进一步结合量化与蒸馏等技术,继续优化长视频生成过程中的效率瓶颈,推动高质量视频生成模型走向移动端、边缘端等资源受限场景。
文章来自于微信公众号“机器之心”。



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
