# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

2022年10月30日,ChatGPT的横空出世,仅用几天的时间就改变了包括学术界在内的各行各业的,在OpenAI的成果的光辉下,有一个独特的模型,来自Meta团队的Galactica在ChatGPT三天前上线就被迫下线,这一度成为了LeCun教授的意难平。
顺着LeCun的意难平,来自上海交通大学的团队,将这一颇具潜力的模型引入到了地球科学领域。
首先让我们回顾一下Galactica。Galactica最初在⼤量的科学⽂献上进⾏预训练,包括超过 4800 万篇论⽂、教科书、讲义、数百万种化合物和蛋⽩质知识、科学⽹站、百科全书等。
虽然Galactica⽣成的⽂本存在⼀定的不严谨性,但由于其在处理学术⽂献等问题上具有先天的优势,因此仍然是某些场景下合适的选择。
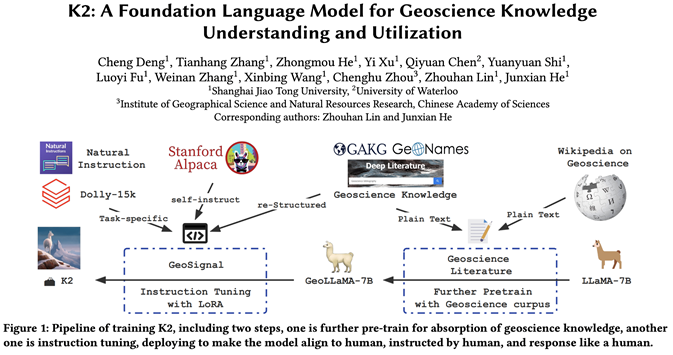
上海交通大学团队在五月份推出70亿参数的地学⼤语⾔模型K2(https://github.com/davendw49/k2)之后,于七⽉份正式完成了300亿参数的地学⼤语⾔模型GeoGalactica的训练。
Galactica的训练语料库主要涵盖与计算机科学和⽣物化学相关的⽂献,相对⽽⾔地球科学领域的覆盖较少,为了丰富Galactica在地球科学领域的专业知识,他们收集了⼤约600万篇专⻔针对地球科学的研究论⽂,这些论⽂由地学领域的专业专家精⼼挑选。
此外,GeoGalactica还扩展了基于K2的GeoSignal数据集,以更全⾯地⽀持地球科学研究中的⾃然语⾔处理任务,扩展后的数据集⽤于进⼀步预训练后的模型微调。
通过不断的改进和训练,GeoGalactica作为其更进一步探索大语言模型在地学领域的能力的演进版本展现出了更⾼⽔平的地学的科学语⾔⽣成能⼒。
市⾯上涌现出诸如GeoGPT、SkyGPT、SpaceGPT等⾃然科学⼤模型,进⼀步凸显了地球科学等自然科学领域的多样性和复杂性。这⼀系列模型的问世为地学研究提供了新的视⻆和⼯具。
目前,关于GeoGalactica的文章已经以技术报告的形式放在了arXiv上,代码和相关资源也在Github上公开。

Paper: https://arxiv.org/abs/2401.00434
Code: https://github.com/geobrain-ai/geogalactica
在地学这一博大精深的领域中,GeoGalactica大模型以其更贴近地球科学专业知识的特色,成为了地球科学领域学生和研究者的新利器。它不仅继承了Galactica模型在学术问答方面的先进性,更专注于为地球科学科学家们解读和摘要科学论文,提升研究效率。
今天,我们将深入了解GeoGalactica如何利用大数据和机器学习技术,辅助地学专家高效获取信息,提炼知识精华,同时在AI伦理的框架内稳步发展,推动科学的进步。虽然Galactica的航程遭遇暂时挫折,但GeoGalactica承载着其理念,继续在科学的海洋中破浪前行。
图:GeoGalactica模型的全貌。本图主体由Midjourney绘制,经手动微调后完成。整个画面由不同地貌的场景组成,突出GeoGalactica大模型在地学信息处理方面的垂类特色,图像逐步从具象的自然和人造景观转化为抽象的数据和信息流,寓意信息从原始形态向数字化转换的过程。
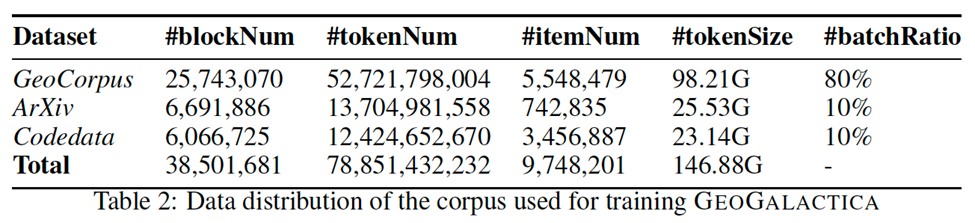
首先,GeoGalactica在⼤约600万篇专⻔针对地球科学的研究论⽂,这些论⽂由地学领域的专业专家精⼼挑选。加上原本的arXiv的论文以及代码数据,累计使用了65B Tokens的语料。
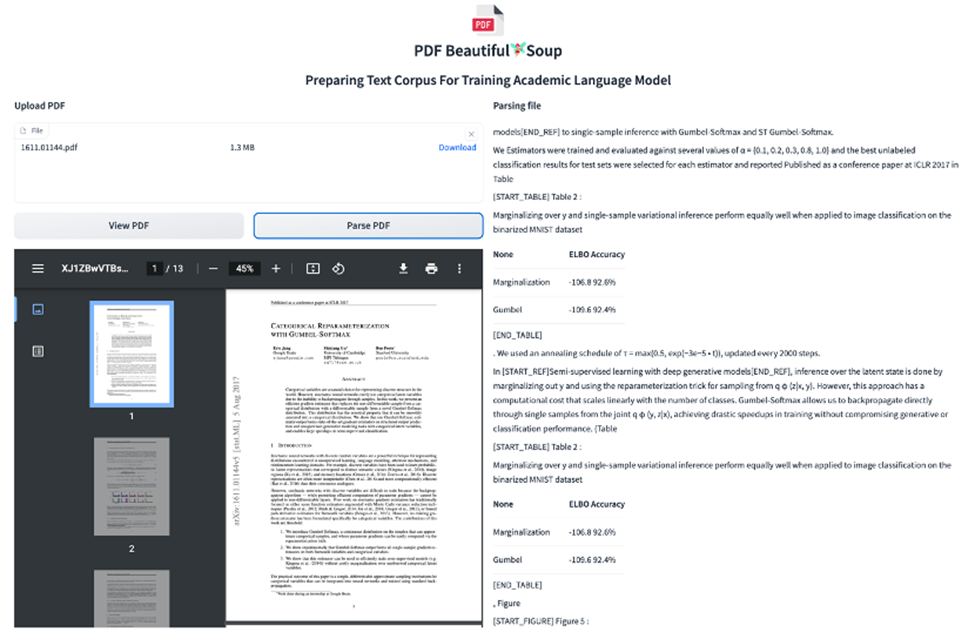
在这个过程中,交大团队还开源了他们进行数据处理的脚本(https://github.com/davendw49/sciparser),下图展示了脚本处理的效果,同K2模型一样,所有的数据均转换成Markdown的形式进行训练。
此外,GeoGalactica还扩展了基于K2的GeoSignal数据集,基于上海交通大学团队的若干平台项目以及8个地学的开源平台。他们将这些结构化网站进行重构,构建了一批SFT的训练数据。


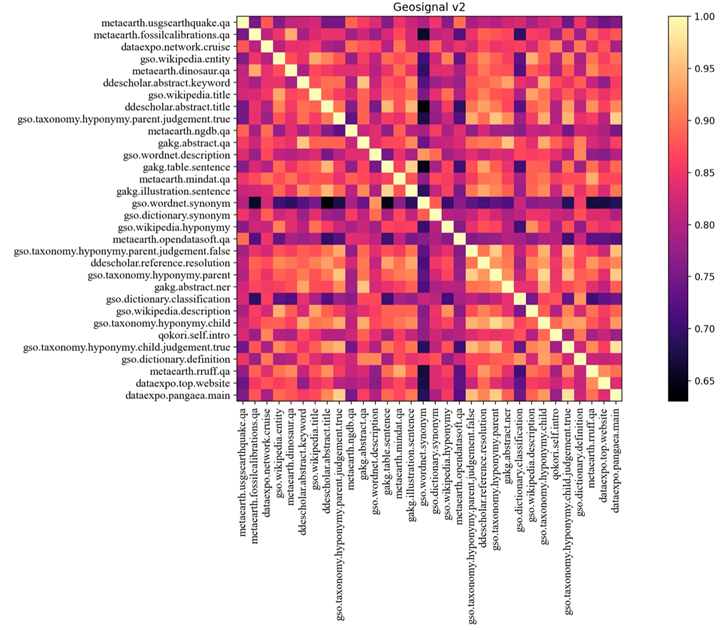
经过一系列的数据构建,最后我们可以看到训练数据的多样性:
Further Pretraining
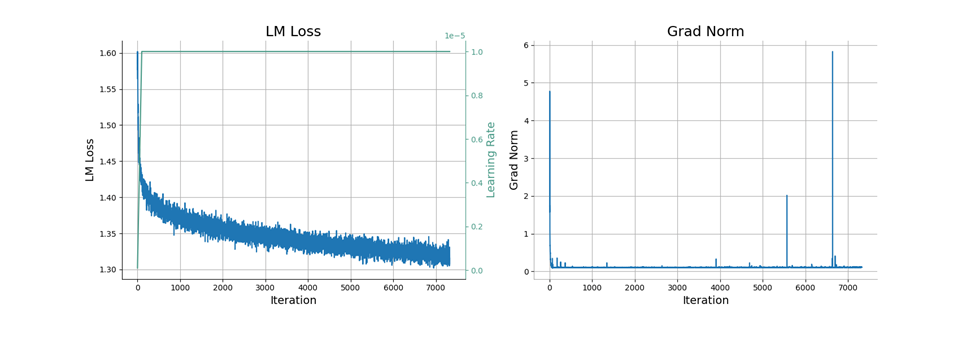
借助Megatron-LM框架,GeoGalactica在基于Hygon DCU架构的超级计算集群上,对Galactica模型进行在专业地学语料上进行了更进一步的预训练,以增强其在专业领域的理解和⽣成能⼒。
计算集群包括512个节点,每个节点配备了32核CPU、128GB内存和4个DCU加速卡,每个卡具有16GB内存。总共调用了2048个加速卡,其中每个卡提供的计算能⼒约为NVIDIA A100 GPU的0.2倍。
为了最⼤限度地提⾼GPU性能,同时最⼩化通信开销,Megatron-LM框架在训练过程中采⽤了各种并⾏策略,如流⽔线并⾏、模型并⾏和数据并⾏。考虑到每个节点有4个加速卡,为了⾼效的模型并⾏执⾏,模型并⾏⼤⼩为4。
此外,当使⽤迷你批处理⼤⼩为1时,设置流⽔线并⾏⼤⼩等于或⼤于16,以充分利⽤可⽤的内存资源。
Supervised Fine-Tuning
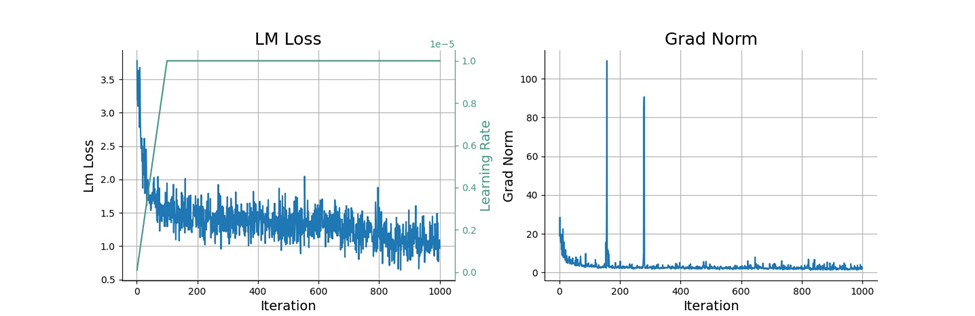
为了使模型适应特定的任务或在某些领域提⾼其性能,交大团队在预训练之后,对GeoGalactica使⽤自研GeoSignal v2数据集,进⾏SFT。这个过程使模型能够适应特定任务或在某些领域提⾼性能。
GeoGalactica使⽤SFT来提⾼预训练模型模型在地球科学任务上涉及专业知识的问答能力。这⼀过程对于有效地将high-level语⾔能⼒转移到地球科学特定任务以及保持预训练期间获得的模型泛化性能⾄关重要。
GeoGalactica进⾏了两个阶段的SFT。在第⼀阶段,通过Alpaca指令微调数据将模型与⼈类进⾏了对⻬,⽽在第⼆阶段
使⽤了继承自K2大模型并进一步完善的GeoSignal v2。SFT的训练曲线如下:
Tool Learning
此外,模型可以被设计成与各种⼯具(⽐如浏览器、数据库或其他软件界⾯)交互并从中学习。模型可以执⾏需要外部信息或特定功能的更复杂的任务。
为了让地球科学领域的⼤规模模型能够充分利⽤⼯具API的功能,GeoGalactica基于ToolBench数据集构造了一批地学文献搜索工具的训练数据并和ToolBench中的相关工具数据一并作为SFT数据。训练数据在提示词中明确了⼯具的描述以及相应的API参数说明。模型训练完成后,模型会在对应提示词的引导下调用相关的工具。
对于给定的问题,GeoGalactica⾸先输出相关的API调⽤(思考、动作、动作输⼊),以获取外部⼯具返回的结果。然后,这些结果被⽤作观察,反馈到模型中,⽣成新⼀轮迭代所需的新思考、动作和动作输⼊(如果需要进⼀步的⼯具调⽤)。这个过程⼀直持续,直到模型收集到⾜够的信息并输出最终答案。

此次交大团队公布的论文还详细记录了从continue-pretraining到tool learning整个过程中的训练细节,甚至包括了各种试错经历。
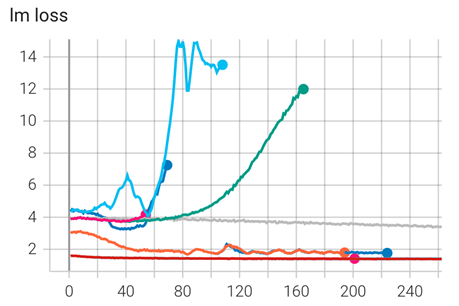
Galactica还行,GeoGalactica可以!
为了评估GeoGalactica对地学科学知识的掌握程度,评估分为两部分。⾸先是沿用在K2开发过程中积累的GeoBench进⾏⾃动评估,其次是在地学科学领域的⼦任务上进⾏的⼈⼯评估。
自动评估
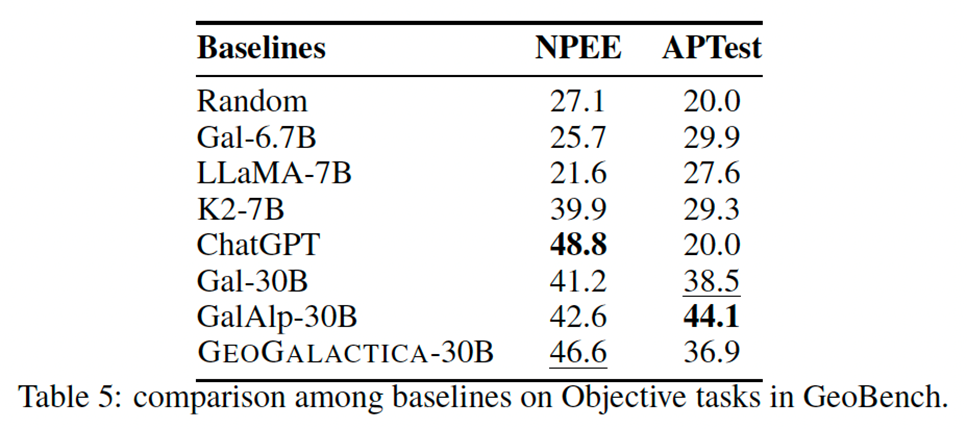
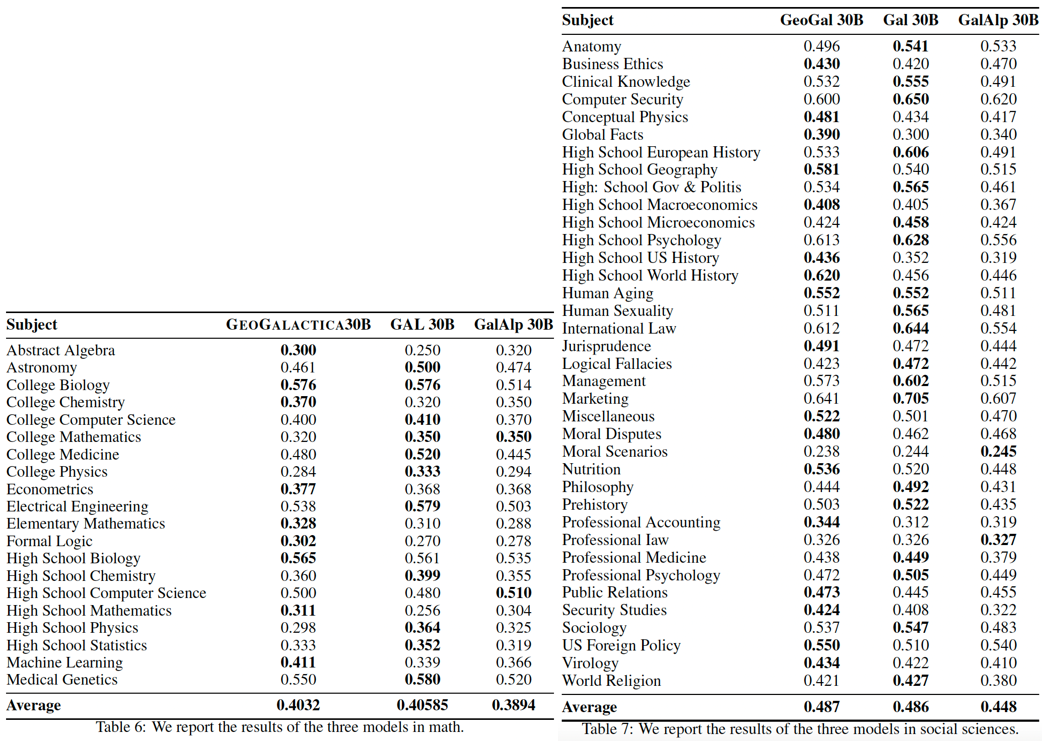
在⾃动评估部分,上海交通大学团队使⽤了GeoBench和MMLU进行评估。其中GeoBench是⼀个专⻔设计⽤于评估和测试⼤模型的地球科学理解和能⼒的基准⼯具。它侧重于评估模型如何处理和⽣成涉及地理和地质信息的响应。可以观察到更⼤、更学术的模型优于NPEE这样倾向于学术研究的基准。
然⽽,他们在AP学习等基准测试中表现不佳,AP学习更倾向于基础教育。这种差异可能是由指导模型思考更⾼级知识的训练数据造成的。训练数据是学术研究成果,即论⽂,这可能会导致对基础知识的偏离和缺乏。
Galactica拥有300亿个参数,但在⼀般的基准任务中,它的表现往往⽆法超过拥有70亿个参数的Llama,⽽建⽴在Galactica的GeoGalactica超越了建⽴在Llama之上的K2。
从MMLU结果可以明显看出,在处理了600万份与地球科学相关的⽂献⽂档后,模型的特定技能,如代数、⽣物学、化学和数学,都得到了改善。这⼀现象似乎与关注数学地质学、⽣物地球科学和化学地质学的论⽂有关,突显了地球科学的跨学科性质。值得注意的是,可能是由于语料库中包含GitHub代码,机器学习能力也在训练之后得到了显著增强。
总体⽽⾔,与地球科学密切相关的学科,包括与地质学及其⼦领域有逻辑联系的学科,取得了显著进展。然⽽,与地球科学⽆关的学科结果,如医学遗传学、医学和电⽓⼯程,表现都有所下降。除此之外,GeoGalactica和最初的Galactica在数学相关科⽬的平均表现相似。
人工评估
参考k2的⼈⼯评估中定义的开放性问题的评价指标:科学性、正确性和连贯性。
每个评价指标分成三个等级,分数越⾼越好。基于三个评价指标可以计算累积分数。评估参与者将从所有六个模型中收到相同输⼊的回复,专家评委将按照1、2、3、4、5和6的顺序对这些模型进⾏评分。
最后,将计算每个模型的平均排名。具体的评估内容在论文中均有公开透明的记录。下面这边展示两个具体场景的实例展示:
名词解释

给论文命名

我们可以发现,这些问题是属于我们平时科研中经常遇到的,GeoGalactica继承Galactica的特征,在学术场景下是地学科研工作者又一探索的选择。
通过在⼴泛的地球科学学术数据集上进⾏训练,并利⽤地球科学领域的知识密集型指令进⾏微调,GeoGalactica在地球科学⾃然语⾔处理(NLP)任务中表现优于现有模型。GeoGalactica得到了资深地球科学家的验证,进⼀步证了它的有效性。
GeoGalactica的发布⽬标在于为推动⼈⼯智能在地球科学领域的发展做出积极贡献。在这个过程中,地学+AI的发展的速度越来越快,从之前的40年的时间间隔,到现在已经基本上做到了实时响应的效果。
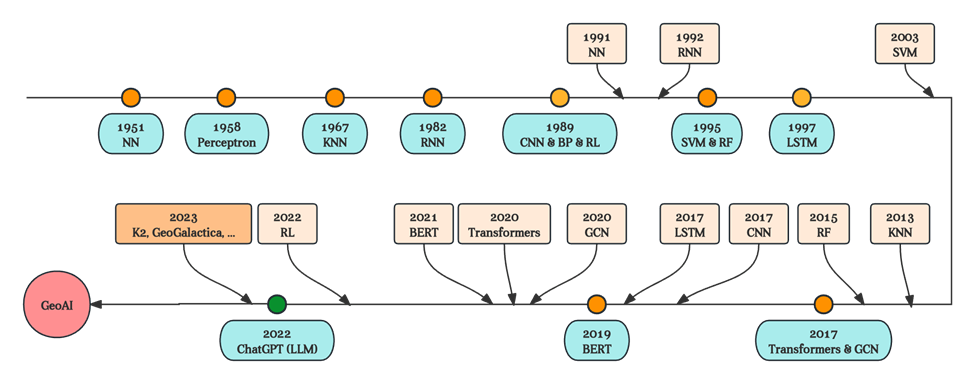

随着计算机科技的⻜速发展,地学领域的⼤规模模型研究正经历着翻天覆地的变⾰。在计算机技术的引领下,地学⼤模型研发周期显著缩短。
GeoGalactica的快速诞⽣计算机的前沿技术可以很好的适配地学这样的自然科学的领域,极⼤地推动了地学领域的前沿研究。
我们也期待,在未来有越来越多的垂直领域的基于这些大模型的应用和探索!


关于Deep-time Digital Earth
GeoGalactica是继K2之后又一个在深时数字地球(DDE)国际大科学计划的号召下,利用计算机的前沿技术深入地学领域进行数据分析、任务需求探索以及共商共建的科研项目。
DDE 国际大科学计划是由中国地质大学王成善院士,中国科学院地理科学与资源研究所周成虎院士等中国地球科学的科学家领导的,致力于建设一个为应对全球科技挑战、支撑全球或者区域命运共同体提供社会所需知识的国际平台来实现聚合全球地学大数据,构建数据驱动的地球科学发现的目的。
文章来自于微信公众号 “机器之心”,作者 “ScienceAI”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
