# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

用AMD的软硬件系统也能训练GPT-3.5级别的大模型了。
位于美国橡树岭国家实验室(Oak Ridge National Laboratory)的全世界最大的超算Frontier,集合了37888个MI250X GPU和9472个Epyc 7A53 CPU。

最近,研究人员只使用了其中8%左右的GPU,就训练了一个GPT-3.5规模的模型。
研究人员成功地使用ROCM软件平台在AMD硬件上成功地突破了分布式训练模型的很多难点,建立了使用ROCM平台在AMD硬件上为大模型实现最先进的分布式训练算法和框架。
成功地在非英伟达和非CUDA平台上为高效训练LLM提供了可行的技术框架。
训练完成后,研究人员将在Frontier上训练大模型的经验的总结成了一篇论文,详细描述了期间遇到的挑战以及克服的困难。

论文链接:https://arxiv.org/abs/2312.12705
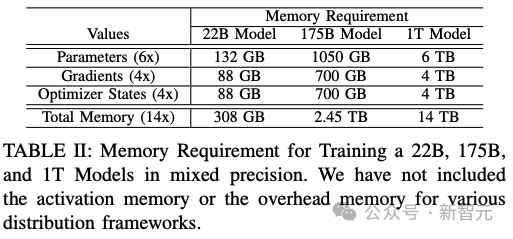
在研究人员看来,训练一万亿参数规模的LLM最为重大的挑战是所需的内存量——至少需要14TB的内存。
而单块GPU最大的内存只有64GB,这意味着需要并行使用多个AMD MI250X GPU才能完成训练。
而并行更多的GPU,对GPU之间的通信提出非常高的要求。如果不能有效地利用GPU之间的带宽通信,大部分的GPU计算资源都会被浪费。
具体来说,研究人员将Megatron-DeepSpeed分布式训练框架移植到Frontier上,以支持在AMD硬件和ROCM软件平台上进行高效的分布式训练。
研究人员将基于CUDA的代码转换为HIP代码,还预构建DeepSpeed ops以避免ROCM平台上的JIT编译错误,并且修改代码以接受主节点IP地址为参数进行PyTorch Distributed初始化。
在220亿参数模型上,Frontier的训练峰值吞吐量达到了38.38%,1750亿参数模型峰值吞吐量的36.14%,1万亿参数模型峰值吞吐量的31.96%。
训练一个1000B级别的模型,最终研究团队将缩放效率(scaling efficiency)做到了87%。同时,作为对比,研究人员还同时训练了另一个1750亿参数的模型,缩放效率也达到了89%。
另一方面,因为现在这样规模的模型训练都是在基于英伟达的硬件和CUDA生态中完成的,研究人员表示在AMD的GPU之上想要达到类似的训练效率和性能,还有很多工作需要做。
GPT式模型结构和模型尺寸
Transformer模型由两个不同的部分组成,编码器块和解码器块。
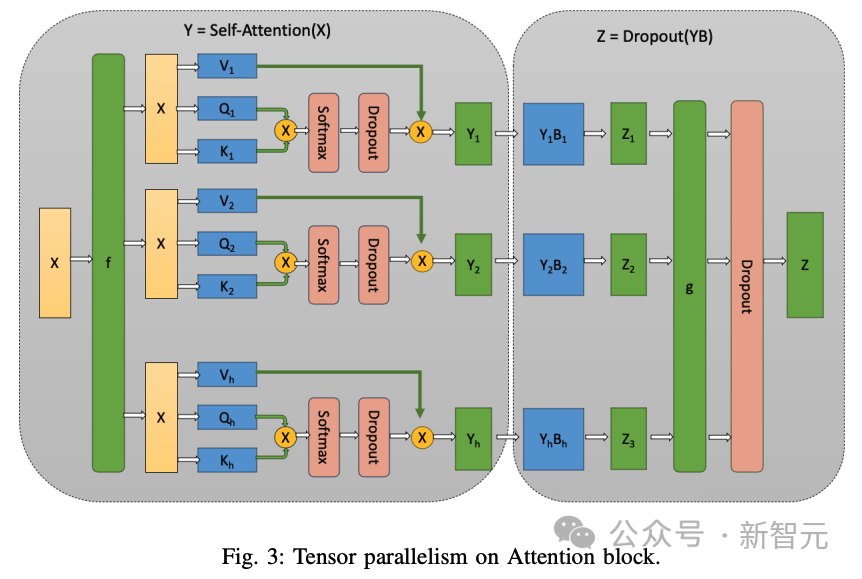
编码块有助于捕捉非因果自注意力,即句子中的每个标记都能注意到左右两边的token。
另一方面,解码块有助于捕捉因果自注意,即一个token只能注意到序列中过去的标记。
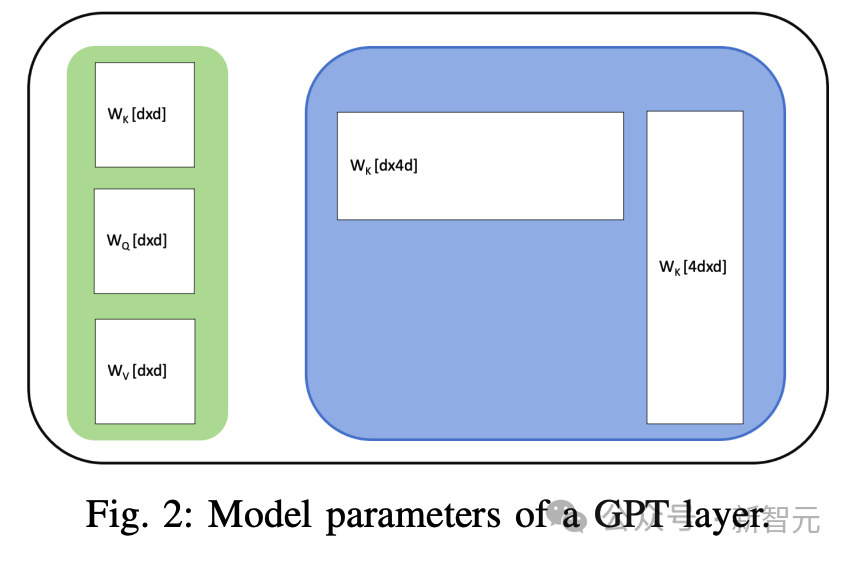
最简单的GPT类模型由一叠类似的层组成。
每一层都有一个注意力区块和一个前馈网络(FFN)2。注意力区块有三组参数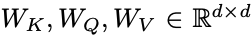 ,其中d是模型的隐藏维度。FFN模块有两层,分别为权重
,其中d是模型的隐藏维度。FFN模块有两层,分别为权重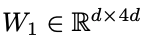 和
和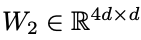 所以,每层有11d^2个参数。
所以,每层有11d^2个参数。
由于嵌入层位于模型的起始层,参数数大致为12Ld^2,其中L为层数,d为隐藏维度。
根据这个公式,研究人员可以定义出下表中大小分别为22B、175B和1T的三个模型。
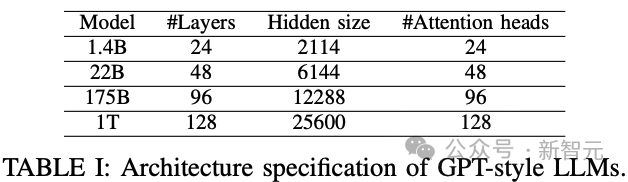
大部分内存需求来自模型权重、优化器状态和梯度。
在混合精度训练中,每个模型参数需要6个字节,4个字节用于在fp32中保存模型,2个字节用于在fp16中进行计算。
优化器状态的每个参数需要4个字节,以将动量保存在fp32中。
研究人员需要为每个参数保存一个fp32梯度值。因此,在使用Adam优化器进行混合精度训练时,最小内存需求如下表所示。
每个Frontier节点有8个MI250X GPU构成,每个都有64GB的HBM内存。
因此,内存需求表中,可以得出结论:要拟合模型的一个副本,模型并行化是必要的。模型并行可以通过张量和碎片数据并行在隐维度上实现,也可以通过管线并行(pipeline paralism)在层维度上实现。
管线并行
管线并行将模型分成p个阶段,每个阶段大约有L/p层。然后,将批次分割成微批次,每执行一步,一个微批次通过一个阶段。
每个阶段都放置在一个GPU上。
最初,只有第一个GPU可以处理第一个微批次。在第二个执行步骤中,第一个微批次进入第二个阶段,而第一个微批次现在可以进入第一个阶段。
如此反复,直到最后一个微批次到达最后一个阶段。
然后,反向传播开始,整个过程反向继续。在每个批次之后引入同步点,以保持正确的计算顺序,这需要冲洗管线阶段。
因此,在一个批次处理的开始和结束时,托管较早和较晚阶段的GPU会处于空闲状态,从而导致计算时间的浪费或管线泡沫。
管线泡沫分数为p-1m,其中m是批次中微批次的数量。
简单的GPipe调度会产生很大的管线泡沫。有一些额外的方法可以减少管线泡沫。
其中一种方法是PipeDream提出的1F1B调度,在前向传递过程中,最初允许微批次向前流动,直到最后一组收到第一个微批次。
但随后第一个批次开始向后传播,从那时起,前向传递总是伴随着后向传递,因此被称为1F1B。为了进一步缩小气泡大小,研究人员提出了一种交错计划,即在单个GPU上放置多个较小的管线组,而不是在单个GPU上放置一个管线组。
1F1B计划的管线泡沫大小大约为p/m,其中p是管线组的数量,m是微批次的数量。
微批次的数量。对于带交错功能的1F1B计划,泡沫大小为m×v p-1,其中v是放置在单个GPU上的交错组的数量。
分片数据并行(Sharded Data Parallelism)
分片数据并行将模型参数、优化器状态和梯度按行分片,并在每个GPU上放置一个分区。
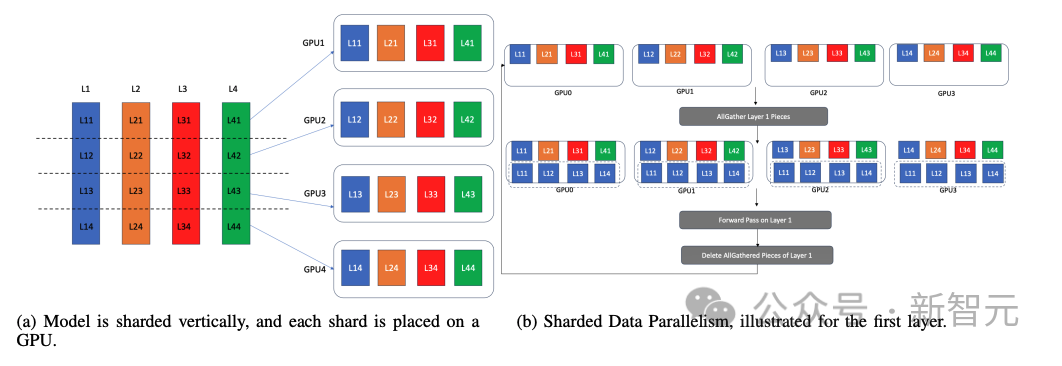
由于训练一次推进一个层,因此计算设备的内存中只需要一个完整的层和相关值(优化器状态、梯度和参数)。
分片数据并行性正是利用了这一点;在执行一个层之前,通过在所有GPU上执行该层的所有收集,在所有GPU 上将该层实体化4b。
现在,所有GPU都有相同层的副本。然后,在不同的GPU上对不同的数据批次执行该层。之后,每个GPU会删除该层的所有收集部分,并通过全收集为下一层的实体化做好准备。
通过这种方式,它模拟了数据并行性,但不是每个GPU都托管了整个模型的完整副本,而只是托管当前活动层的副本。
分片数据并行可以促进大型模型在GPU上的数据并行训练,即使模型太大,无法容纳在单个GPU的内存中。
DeepSpeed的ZeRO优化器在不同程度上支持分片数据并行。ZeRO-1只对优化器状态进行分片,ZeRO-2对梯度和优化器状态进行分片,ZeRO-3则对优化器状态、梯度和模型参数进行分片。
另一方面,PyTorch FSDP(完全分片数据并行)对所有三种数据进行了分片,并通过将分片数据并行与传统数据并行相结合,支持混合数据并行。
3D并行和Megatron-DeepSpeed
仅使用单一并行策略来实现模型并行可能是一种低效方法。例如,如果研究人员只使用张量并行来对模型进行水平切分,那么张量可能太薄,需要频繁进行全还原通信,从而减慢训练速度。
另一方面,如果研究人员将模型划分为过多的管线阶段,每个阶段的计算量就会很小,这就需要频繁的通信。一个已知的问题是,在多个节点上执行张量并行训练需要缓慢的树状allreduce。
以混合方式使用多种并行模式,可以最大限度地减少性能不佳的地方。三维并行结合了张量、管线和数据(传统和分片)并行技术,以充分利用资源。
通过适当的设置,三维并行技术可将通信与计算重叠,从而减少通信延迟。
人工智能领域使用的三维并行标准代码库基于Megatron-LM。MegatronDeepSpeed扩展了Megatron-LM的功能,增加了DeepSpeed功能,如ZeRO-1 sharded数据并行和重叠1F1B的管线并行。
计划的管线并行。不过,这些标准代码库都是针对英伟达GPU和CUDA平台开发的。
作为最完整的框架,研究人员希望在Frontier上使用Megatron-DeepSpeed,Frontier 是AMD系统,其软件栈建立在ROCM软件平台上。
将Megatron-DeepSpeed移植到Frontier
Megatron-DeepSpeed代码库来源自英伟达公司的Megatron-LM代码库,然后微软在其中添加了DeepSpeed ZeRO优化器、管线并行性和MoE。
英伟达负责开发Megatron-LM,因此其代码库是以英伟达GPU和CUDA环境为目标平台开发的。
将该代码库移植到AMD平台上运行会面临一些挑战。
1. CUDA代码:CUDA代码不能在AMD硬件上运行,但HIP(一种类似CUDA的C/C++扩展语言)可以。
研究人员使用hipify工具将CUDA源代码转换为HIP代码,使用hipcc构建可共享对象(so文件)然后使用pybind从Python代码访问这些可共享对象。
2. DeepSpeed操作:大多数DeepSpeed操作都是在执行训练管线期间通过JIT(及时)编译构建的。
但是,DeepSpeed操作的JIT编译在ROCM平台上不起作用,因此研究人员在安装DeepSpeed时预先构建了所有操作。
研究人员禁用了Megatron-DeepSpeed代码库中的所有JIT功能,以避免任何运行时错误。
3. 初始化PyTorch分布式环境:Megatron-DeepSpeed利用PyTorch分布式初始化创建各种数据和模型并行组。
初始化过程需要指定一个计算节点作为「主」节点,所有分布式进程都需要它的IP地址。
研究人员修改了代码库,以接受MASTER ADDR作为参数。
研究人员准备了一个启动脚本,从SLURM节点列表中读取第一个节点的IP地址,并将其作为参数传递给所有使用srun启动的进程。
然后,初始化代码会使用这个MASTER ADDR进行PyTorch分布式初始化。
4. 通过ROCM平台软件提供的库/软件包:研究人员与AMD开发人员合作,获得了一些基本CUDA软件包的ROCM版本,如APEX。
APEX是英伟达的混合精度库,Megatron-DeepSpeed代码库大量使用该库进行混合精度训练。
他们还改编了支持ROCM的FlashAttention和FlashAttention2库版本,供Frontier上的编译器使用。Flash-Attention操作被移植到AMDGPU上,使用的内核来自Composable Kernel库。
张量并行
张量并行法按行划分模型层,每层之后都需要通过Allreduce对部分激活值进行聚合。
每层执行后的AllReduce成本很高,这取决于张量并行组中GPU之间的通信带宽,通信量取决于隐藏大小和微批量大小。
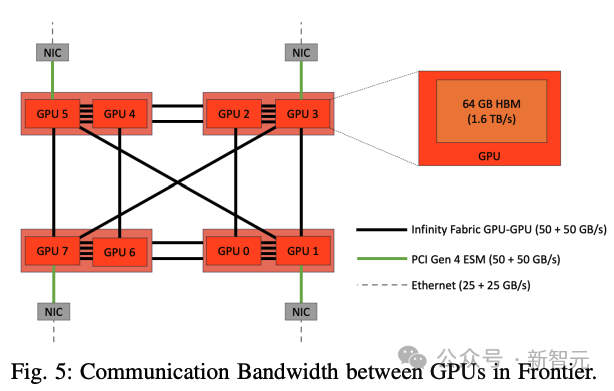
下图5显示了前沿GPU之间的通信带宽。一个节点中有8个GPU,单个芯片中的GPU通过四个(50+50 GB/s)无限结构连接。
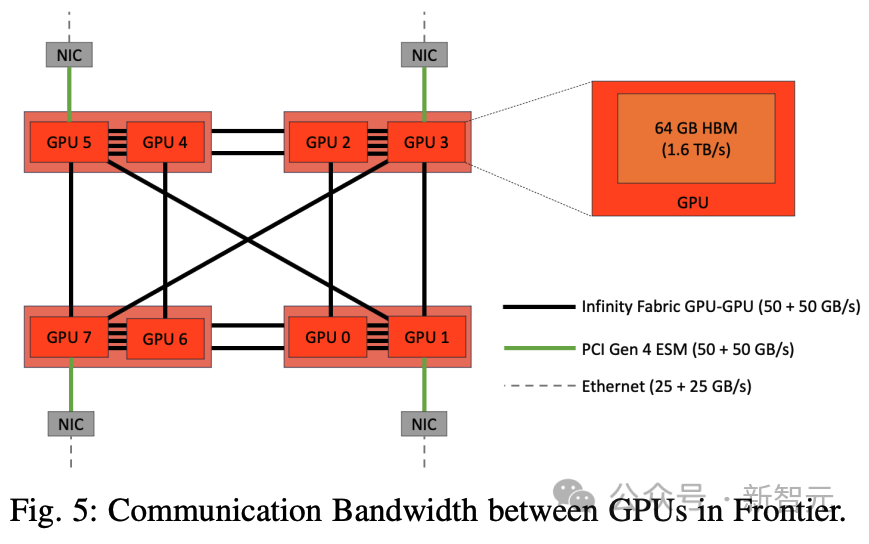
跨芯片的GPU之间的带宽是它的一半。但是,跨节点的GPU之间的带宽是25+25 GB/s。
因此,从网络拓扑和配置来看,TP = 2的通信速度最快,TP = 4或8的通信速度次之。
但是,如果TP ¿ 8,通信将通过较慢的以太网进行,通信速度将大大降低。因此,将TP保持在[2, 4, 8]范围内应该是最佳策略。
研究人员使用8个GPU训练一个1.4B的模型,TP值从1到8不等,结果发现TP值越小,吞吐量越高。
观察结果III.1:TP值越大,训练效果越差。
B. 管线并行
管线并行化沿着层维度划分模型,并将连续的层划分为管线阶段。一个微批次的执行从一个阶段流向下一个阶段。
管线气泡是使用这种并行方式进行高效训练的限制因素。
研究人员观察了大M或大GBS的效果,以了解22B参数和1T参数大小的两个模型对GPU吞吐量的影响(下图7)。
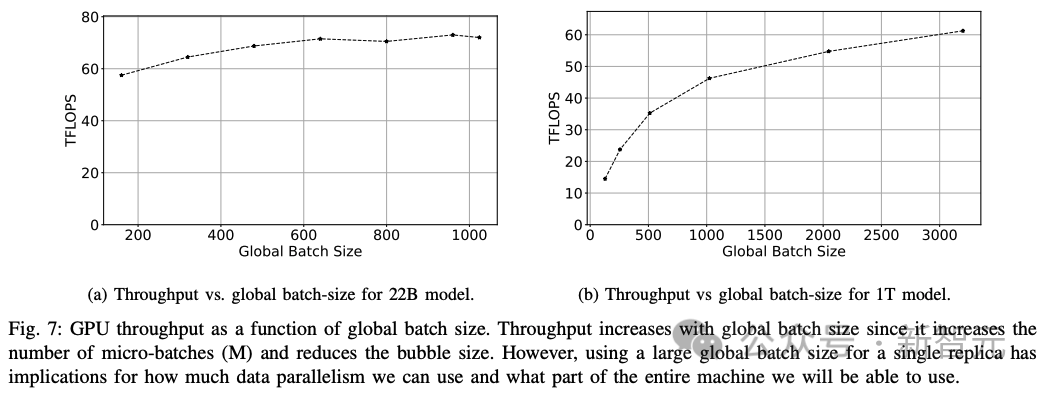
观察结果III.2:使用大的全局批次大小或许多微批次使管线阶段饱和,可将管线气泡大小降至最低。
管线阶段数量的影响:接下来,研究人员研究管线级数对训练性能的影响。直观地说,管线阶段越多,意味着通信发生前的计算量越少。
在全局批次大小(微批次数量)固定的情况下,管线阶段数量越多,计算量越少。
气泡大小会随着管线级数的增加而增加。研究人员还尝试增加管线级数,同时保持PMP固定不变,按比例增加全局批量大小。
观察结果III.3:在保持全局批量大小不变的情况下,增加管线级数会增加管线气泡的大小,并降低训练性能。
观察结果III.4:如果管线级数与微批次数的比例保持不变,则随着管线级数的增加,训练性能也会保持不变。
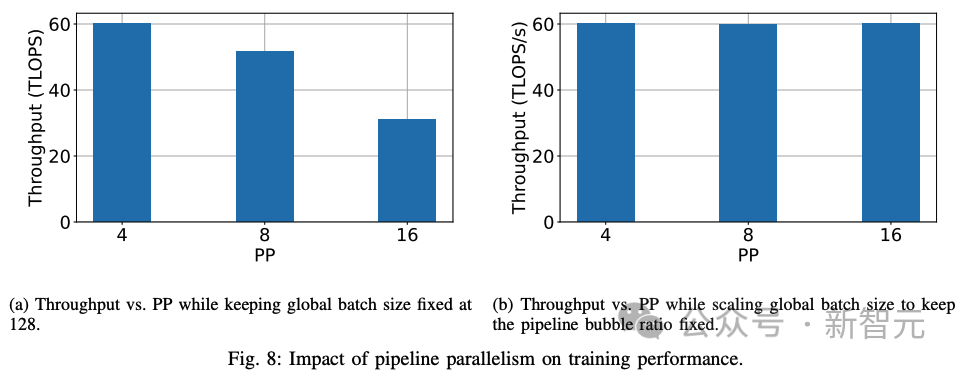
从第一个实验(上图8a)来看,随着管线级数的增加,训练性能会下降。但是,通过调整全局批次大小来固定气泡比例,可以保持吞吐量(上图8b)。
通过实验、超参数调整和分析,研究人员确定了在Frontier上训练Trillionparameter模型的高效策略,该策略结合了各种分布策略和软件优化。
训练万亿参数模型的高效策略
通过增加微批次数量使管线阶段饱和:研究人员使用DeepSpeed(来自 DeepSpeed-Megatron,但不是Megatron的版本)提供的管线并行性。这种管线并行算法是PipeDream的算法,其中多个阶段相互重叠,并采用1F1B算法来减少气泡大小。
但是,如果管线级数没有达到饱和,气泡大小就会增大。为确保饱和,微批次的数量必须等于或超过管线级数。
将张量并行限制为单个节点/八个GPU:由于AllReduce操作过于频繁,而且需要对每一层都执行,因此分散在不同节点上的层会导致跨节点GPU之间基于树状结构的AllReduce,而通信延迟则会成为一个重要瓶颈。
使用Flash-Attention v2:与普通注意力实现相比,研究人员观察到使用Flash-attention可将吞吐量提高30%。
使用ZeRO-1优化器实现数据并行:研究人员使用ZeRO-1实现数据并行,以减少内存开销。
使用AWS的RCCL插件提高通信稳定性:AWS OFI RCCL插件使EC2开发人员能够在运行基于AMD RCCL的应用程序时将libfabric用作网络提供商。在Frontier上,该插件的使用显示了通信的稳定性。
万亿参数模型的训练性能
根据从超参数调整中吸取的经验教训,研究人员确定了一组大小为220亿个参数和1750亿个参数的模型组合。
在这两个模型的GPU吞吐量的鼓舞下,研究人员最终使用表V中列出的分布策略组合训练了一个万亿参数模型,并进行了十次迭代,以观察其训练性能。
对于22B参数模型,研究人员可以提取其峰值吞吐量(191.5 TFLOPS)的38.38%(73.5 TFLOPS)。
对于175B模型训练,研究人员实现了峰值吞吐量的36.14% (69.2 TFLOPs)。
最后,对于1T模型,实现了峰值吞吐量的31.96%(61.2 TFLOPs)。
扩展性能
通过数据并行来维持模型并行训练的性能,让系统中的大量GPU参与进来,是一项极具挑战性的任务。性能最强的GPU通过不同速度的通信链路连接,如果对网络中较大的部分施加压力,可能会导致性能损失。
因此,研究人员通过数据并行化将175B模型的训练扩展到1024个GPU,将1T模型的训练扩展到3072个GPU,以衡量训练策略的扩展效率。
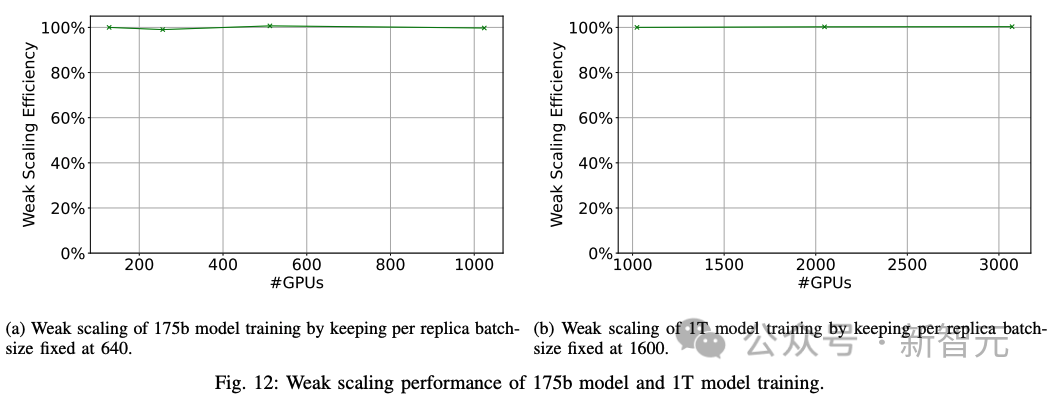
1. 弱扩展:研究人员在1024、2048和3072个GPU上使用全局批量大小3200、6400和9600执行数据并行训练,对1T模型进行弱扩展实验。数据并行训练实现了100%的弱扩展效率(下图12)。
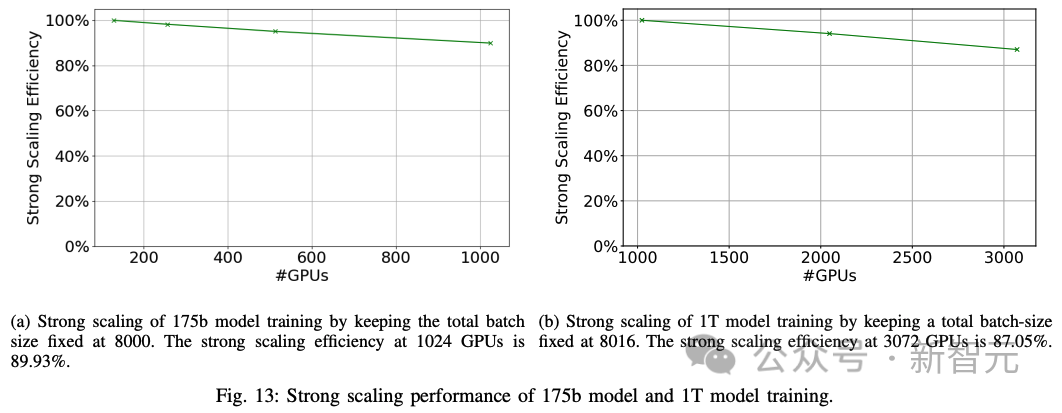
2. 强扩展:研究人员进行了强扩展实验,将全局批量大小保持在8000,然后改变GPU的数量。研究人员在1024个GPU上对一个175B模型实现了89.93%的强扩展性能(图13a)。
研究人员在3072个GPU上对一个1万亿参数的模型实现了87.05%的强扩展性能(图13b)。
世界最快超算
AMD加持的Frontier超级计算机现在是世界上第一台官方认可的百亿亿次超级计算机,算力高达1.102 ExaFlop/s。
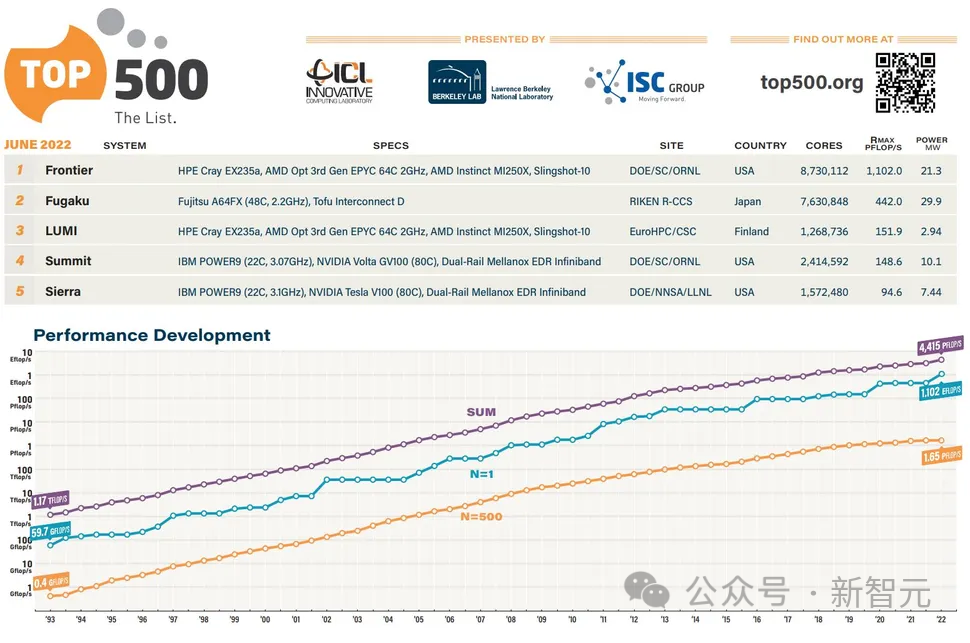
它在新发布的全球最快超级计算机Top500榜单中名列第一。
Frontier的速度比榜单上接下来的七台超级计算机的总和还要快。
Frontier现在也被列为地球上最快的AI系统,在HPL-AI基准测试中提供6.88 ExaFlops的混合精度性能。
这相当于大脑中860亿个神经元中的每一个每秒执行6800万条指令。
Frontier超级计算机的规模之大令人惊叹,但这只是AMD在今年Top500榜单中取得的众多成就之一——全球排名前10的超级计算机中,有5台采用AMD EPYC系统,而排名前20的超级计算机中,有10台采用AMD EPYC系统。
Frontier超级计算机由HPE制造,安装在橡树岭国家实验室 (ORNL)。
该系统拥有9408个计算节点,每个节点配备一个64核AMD「Trento」CPU,搭配512 GB DDR4内存和四个AMD Radeon Instinct MI250X GPU。
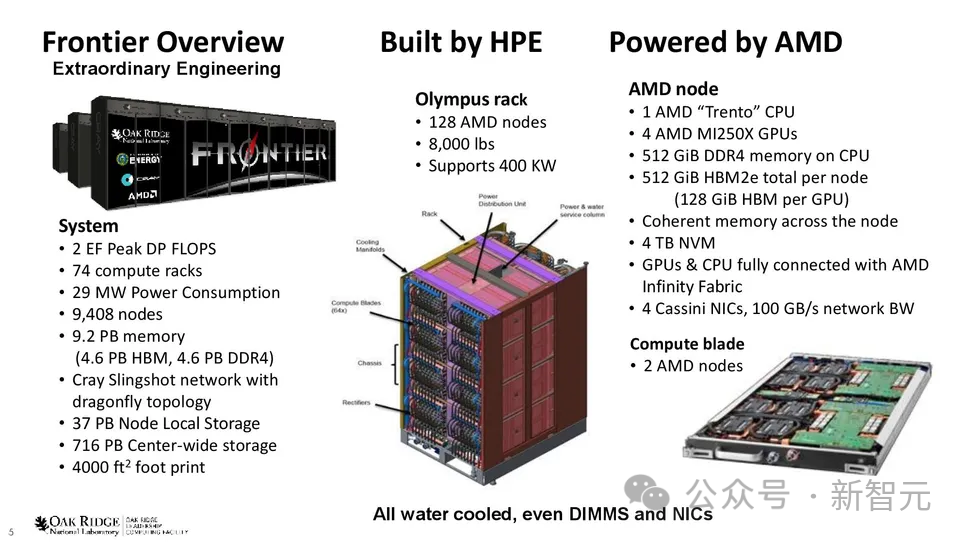
这些节点分布在74个HPE Cray EX机柜中,每个机柜重8000磅。整个系统拥有 602112个CPU核心,4.6 PB DDR4内存。
参考资料:
https://arxiv.org/abs/2312.12705
https://www.tomshardware.com/news/amd-powered-frontier-supercomputer-breaks-the-exascale-barrier-now-fastest-in-the-world
文章来自于微信公众号 “新智元”



