# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
这是一篇在GitHub上获得5.3k+星标的重要技术文档,其中蕴含的洞察值得每一位AI产品开发者深度思考。作者Dex是一位资深的AI工程师,他试遍了市面上几乎所有的Agent框架——从广受欢迎的LangChain到号称"生产级"的LangGraph,从协作式的CrewAI到各种新兴的解决方案。并且他与大量来自Y Combinator的技术创始人深入交流,观察他们如何在实际商业环境中构建AI产品。

在深入研究了无数案例后,Dex发现了一个让人深思的现象:那些真正在生产环境中稳定运行、为用户创造价值的AI产品,很少是完全依赖现有框架构建的。这些成功的产品往往采用了更加务实和模块化的方法。并且现在大部分AI产品的开发路径都惊人地相似:选个顺手的框架,快速搭建原型,很快就能达到70-80%的效果。但接下来会发现那剩下的20%就像一道无法跨越的鸿沟,像魔咒一样。为了达到生产级的90%+质量,不得不开始逆向工程框架的内部逻辑,修改提示词,重写控制流程。最终的结果往往是:推倒重来。
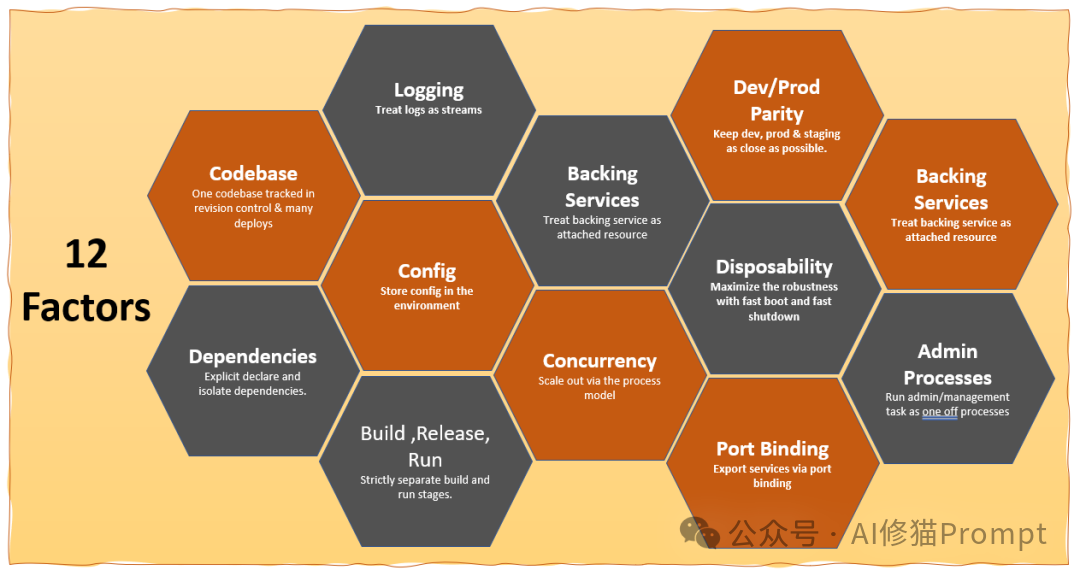
受到经典的《12-Factor Apps》方法论启发——这套由Heroku创始人总结的软件即服务(SaaS)应用开发最佳实践,已经指导了十多年的云原生应用开发——Dex决定回答一个关键问题:
我们能够使用哪些原则来构建真正足够好、可以交付给生产客户使用的LLM驱动产品?
《12-Factor Apps》通过十二个原则解决了传统软件在可扩展性、可维护性和可部署性方面的核心挑战。如今,AI应用同样面临着从原型到生产的巨大鸿沟,我们迫切需要一套类似的方法论来指导LLM应用的工程实践。本文GitHub 链接是:https://github.com/humanlayer/12-factor-agents/tree/main
传统观念告诉我们,Agent就是"给个目标+一堆工具+让LLM循环决策直到完成"。但现实中优秀的AI产品是什么样的?其实大部分还是传统软件,只在关键节点加入LLM来创造那种"哇,这也太智能了"的体验。换句话说,好的Agent产品更像是精心设计的软件系统,而不是完全由AI驱动的黑盒子。
回想一下软件发展史:最早我们用流程图表示程序逻辑,后来有了Airflow这样的DAG编排器,现在Agent承诺我们可以"扔掉DAG",让AI实时决策。听起来很美好,但实际效果却不尽如人意。问题在哪?AI的决策虽然灵活,但缺乏足够的可预测性和可控性,这对生产环境来说是致命的。
Dex提出了一个观点:最快让AI软件投入生产的方式,不是重新构建整个系统,而是从Agent构建中提取小的、模块化的概念,然后把它们集成到您现有的产品中。这就像是在传统汽车上加装智能驾驶辅助,而不是直接买一辆全自动驾驶汽车。这种渐进式的方法风险更低,效果更可控。
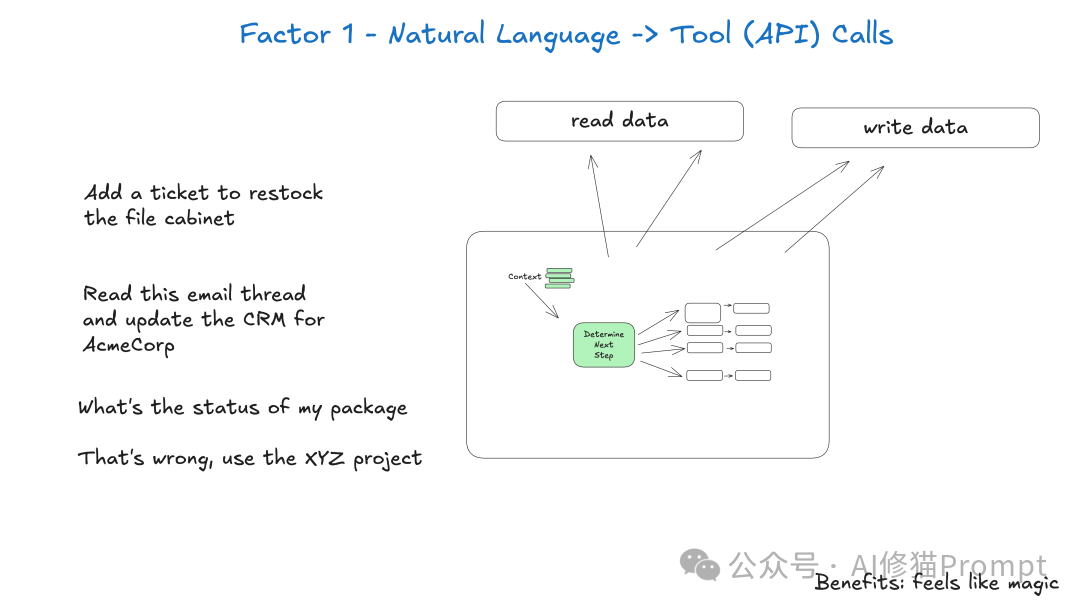
这是Agent架构中最基础但也最关键的转换层。当用户说"帮我创建一个5000元的付款链接给琳达,用于赞助三月AI技术沙龙"时,系统需要将这句话精确转换为结构化的API调用。以下是一个真实的转换示例:
输入的自然语言:
"帮我创建一个5000元的付款链接给琳达,用于赞助三月AI技术沙龙"
转换后的结构化工具调用:
{
"function":{
"name":"create_payment_link",
"parameters":{
"amount":5000,
"customer":"cust_128934ddasf9",
"product":"prod_8675309",
"price":"prc_09874329fds",
"quantity":1,
"memo":"这是三月AI技术沙龙的赞助付款链接"
}
}
}
确定性代码的处理逻辑:
# LLM将自然语言转换为结构化对象
nextStep = await llm.determineNextStep(
"""
创建一个5000元的付款链接给Lisa
用于赞助三月AI技术沙龙
"""
)
# 基于结构化输出处理不同的功能调用
if nextStep.function == 'create_payment_link':
stripe.paymentlinks.create(nextStep.parameters)
return# 执行后续逻辑
elif nextStep.function == 'something_else':
# 处理其他工具调用
pass
else: # 模型调用了未知工具
# 错误处理逻辑
pass
您必须深度理解这个转换过程的每一个环节:从自然语言解析到实体识别,再到参数映射和API构造。不要把这个过程当作黑盒,因为其中任何一个细节的偏差都可能导致用户意图的曲解,进而影响整个系统的可靠性和用户体验。注意,真实的实现中还需要处理客户列表查询、产品价格获取等前置步骤,或者将这些信息预先加载到上下文窗口中。
绝对不要依赖框架提供的默认提示词模板,这等同于将您的核心业务逻辑外包给第三方。看下《别瞧不起「提示词」芝大论文爆火:Prompt Science已被定义》很多框架提供的黑盒方法看起来很方便:
框架的黑盒方法(不推荐):
agent = Agent(
role="...",
goal="...",
personality="...",
tools=[tool1, tool2, tool3]
)
task = Task(
instructions="...",
expected_output=OutputModel
)
result = agent.run(task)
更好的做法是完全拥有您的提示词:
function DetermineNextStep(thread: string) -> DoneForNow | ListGitTags | DeployBackend | DeployFrontend | RequestMoreInformation {
prompt #"
{{ _.role("system") }}
You are a helpful assistant that manages deployments for frontend and backend systems.
You work diligently to ensure safe and successful deployments by following best practices
and proper deployment procedures.
Before deploying any system, you should check:
- The deployment environment (staging vs production)
- The correct tag/version to deploy
- The current system status
You can use tools like deploy_backend, deploy_frontend, and check_deployment_status
to manage deployments. For sensitive deployments, use request_approval to get
human verification.
Always think about what to do first, like:
- Check current deployment status
- Verify the deployment tag exists
- Request approval if needed
- Deploy to staging before production
- Monitor deployment progress
{{ _.role("user") }}
{{ thread }}
What should the next step be?
"#
}
这个示例使用Yaml来生成提示词,但您也可以使用任何其他提示词工程工具,甚至手动模板化。关键的好处包括:
1.完全控制:编写您的Agent确切需要的指令,没有黑盒抽象
2.测试和评估:像对待其他代码一样为提示词构建测试和评估
3.快速迭代:根据实际性能快速修改提示词
4.透明度:确切知道您的Agent在使用什么指令
5.角色技巧:利用支持非标准用户/助手角色使用的API
提示词应该被视为最重要代码资源,需要完整的软件工程流程:版本控制、分支管理、代码审查、单元测试和性能监控。记住:您的提示词是应用逻辑和LLM之间的主要接口,拥有对提示词的完全控制能为您提供构建生产级Agent所需的灵活性和精确控制。

上下文窗口是AI应用中最稀缺和宝贵的资源,需要像管理内存一样精打细算。LLM是无状态函数,在任何给定时刻,您输入给Agent的本质都是"这是到目前为止发生的事情,下一步是什么"。
标准消息格式 vs 自定义格式对比:
标准消息格式:
[
{
"role":"system",
"content":"You are a helpful assistant..."
},
{
"role":"user",
"content":"Can you deploy the backend?"
},
{
"role":"assistant",
"content":null,
"tool_calls": [
{
"id":"1",
"name":"list_git_tags",
"arguments":"{}"
}
]
},
{
"role":"tool",
"name":"list_git_tags",
"content":"{\"tags\": [{\"name\": \"v1.2.3\", \"commit\": \"abc123\", \"date\": \"2024-03-15T10:00:00Z\"}, {\"name\": \"v1.2.2\", \"commit\": \"def456\", \"date\": \"2024-03-14T15:30:00Z\"}, {\"name\": \"v1.2.1\", \"commit\": \"abe033d\", \"date\": \"2024-03-13T09:15:00Z\"}]}",
"tool_call_id":"1"
}
]
优化的自定义格式(更高效):
[
{
"role":"system",
"content":"You are a helpful assistant..."
},
{
"role":"user",
"content":|
Here's everything that happened so far:
<slack_message>
From:@alex
Channel:#deployments
Text:Canyoudeploythebackend?
</slack_message>
<list_git_tags>
intent:"list_git_tags"
</list_git_tags>
<list_git_tags_result>
tags:
-name:"v1.2.3"
commit:"abc123"
date:"2024-03-15T10:00:00Z"
-name:"v1.2.2"
commit:"def456"
date:"2024-03-14T15:30:00Z"
-name:"v1.2.1"
commit:"ghi789"
date:"2024-03-13T09:15:00Z"
</list_git_tags_result>
what'sthenextstep?
}
]
实现上下文构建的Python代码:
class Thread:
events: List[Event]
classEvent:
type: Literal["list_git_tags", "deploy_backend", "deploy_frontend",
"request_more_information", "done_for_now",
"list_git_tags_result", "deploy_backend_result",
"deploy_frontend_result", "request_more_information_result",
"done_for_now_result", "error"]
data: Union[ListGitTags, DeployBackend, DeployFrontend, RequestMoreInformation,
ListGitTagsResult, DeployBackendResult, DeployFrontendResult,
RequestMoreInformationResult, str]
defevent_to_prompt(event: Event) -> str:
data = event.data ifisinstance(event.data, str) \
else stringifyToYaml(event.data)
returnf"<{event.type}>\n{data}\n</{event.type}>"
defthread_to_prompt(thread: Thread) -> str:
return'\n\n'.join(event_to_prompt(event) for event in thread.events)
不同阶段的上下文窗口示例:
初始钉钉群请求:
<dingtalk_message>
From: @小张
Channel: #部署群
Text: 可以帮我部署最新的后端到生产环境吗?
</dingtalk_message>
错误处理和恢复后:
<slack_message>
From: @alex
Channel: #deployments
Text: Can you deploy the latest backend to production?
</slack_message>
<deploy_backend>
intent: "deploy_backend"
tag: "v1.2.3"
environment: "production"
</deploy_backend>
<e>
error running deploy_backend: Failed to connect to deployment service
</e>
<request_more_information>
intent: "request_more_information_from_human"
question: "I had trouble connecting to the deployment service, can you provide more details and/or check on the status of the service?"
</request_more_information>
<human_response>
data:
response: "I'm not sure what's going on, can you check on the status of the latest workflow?"
</human_response>
关键好处包括:
1.信息密度:以最大化LLM理解的方式构建信息
2.错误处理:以帮助LLM恢复的格式包含错误信息
3.安全性:控制传递给LLM的信息,过滤敏感数据
4.灵活性:随着您了解最佳实践而调整格式
5.Token效率:优化上下文格式以提高token效率和LLM理解

工具调用被过度神秘化了,其实质就是LLM输出的结构化JSON数据,您的代码解析这些数据并执行相应操作。让我们看一个具体的例子,假设您有两个工具CreateIssue和SearchIssues:
工具调用的数据结构定义:
class Issue:
title: str
description: str
team_id: str
assignee_id: str
classCreateIssue:
intent: "create_issue"
issue: Issue
classSearchIssues:
intent: "search_issues"
query: str
what_youre_looking_for: str
简单的模式实现:
处理逻辑示例:
# 回顾我们之前的switch语句
if nextStep.intent == 'create_payment_link':
stripe.paymentlinks.create(nextStep.parameters)
return # 或者执行其他后续逻辑
elif nextStep.intent == 'wait_for_a_while':
# 执行一些复杂的操作
pass
else: # 模型调用了我们不认识的工具
# 执行错误处理
pass
理解这个本质后,您就能更灵活地设计工具接口:定义清晰的数据结构、处理各种异常情况、优化性能,甚至实现非原子性的复杂操作。不要被"function calling"这样的术语迷惑,工具调用只是LLM决策和应用逻辑之间的桥梁,关键是保持LLM决策层和执行层的清晰分离。您可以看下《函数调用提示词咋写,看下OpenAI发布的Function Calling指南(万字含示例)|最新》
重要的是,"下一步"可能不像"运行纯函数并返回结果"那样原子化。当您将"工具调用"视为模型输出描述确定性代码应该做什么的JSON时,您就获得了很多灵活性。这与原则八(拥有控制流)完美结合。
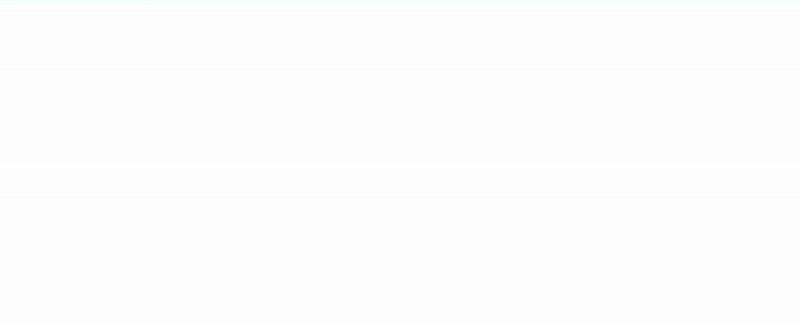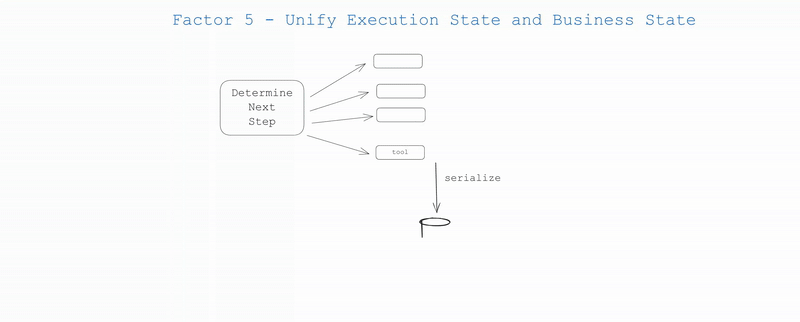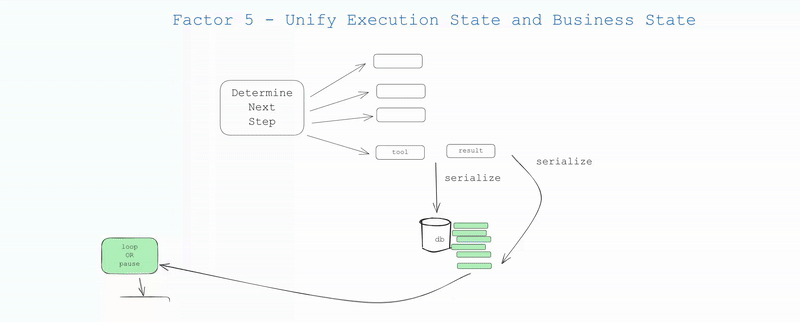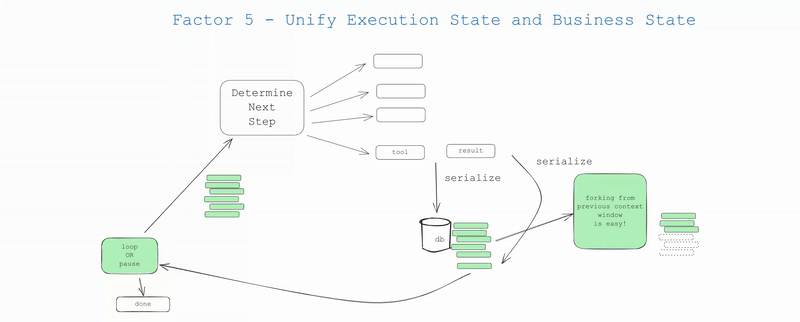
传统系统往往分离执行状态(当前步骤、等待状态、重试次数等)和业务状态(用户数据、处理历史等),这种分离会增加系统复杂度并带来一致性问题。在AI应用之外的许多基础设施系统也试图分离"执行状态"和"业务状态",这种分离可能是有价值的,但对您的用例来说可能过于复杂。
明确定义两种状态:
如果可能的话,简化——尽可能统一这些状态。实际上,您可以设计应用程序,使得所有执行状态都可以从上下文窗口推断出来。在许多情况下,执行状态(当前步骤、等待状态等)只是关于到目前为止发生了什么的元数据。
统一状态管理的好处:
1.简单性:所有状态的单一真实来源
2.序列化:线程可以轻松序列化/反序列化
3.调试:整个历史在一个地方可见
4.灵活性:通过添加新事件类型轻松添加新状态
5.恢复:通过加载线程从任何点恢复
6.分支:通过将线程的某个子集复制到新的上下文/状态ID中,可以在任何点分支线程
7.人类界面和可观测性:将线程转换为人类可读的markdown或丰富的Web应用UI变得轻松
通过拥抱原则三(拥有您的上下文窗口),您可以控制实际进入LLM的内容。您可能有一些无法进入上下文窗口的东西,如会话ID、密码上下文等,但您的目标应该是最小化这些内容。
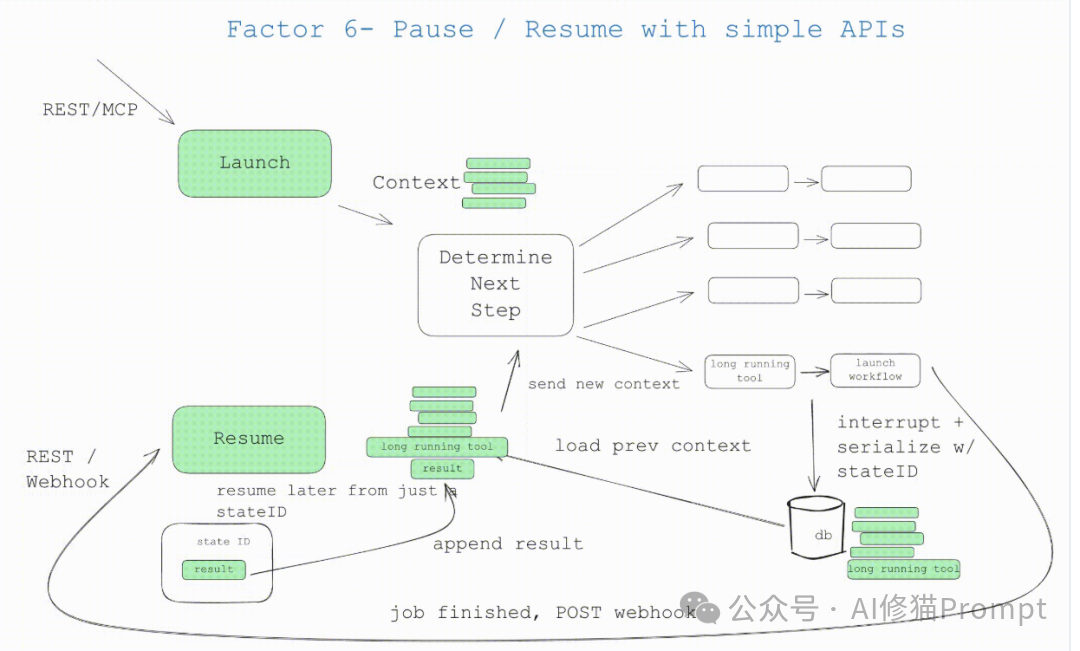
Agent就像普通程序一样,我们对如何启动、查询、恢复和停止它们有特定的期望。Agent应该像普通程序一样支持标准的生命周期操作:启动、查询状态、暂停、恢复和停止。
核心要求:
这听起来基础,但大多数现有框架在这方面做得很糟糕,特别是缺乏在工具选择和工具执行之间暂停的能力。您需要设计支持细粒度控制的API,让用户能够在任何关键点介入:审查将要执行的操作、批准高风险的工具调用、调整执行参数等。
关键特性:
这种设计对于生产环境至关重要,因为它提供了必要的安全网和控制机制,让AI系统能够处理更高价值的任务。最重要的功能要求是,我们需要能够中断工作中的Agent并稍后恢复,特别是在工具选择和工具调用之间。

默认情况下,LLM API依赖于一个根本性的高风险token选择:我们是返回纯文本内容,还是返回结构化数据?您将很多权重放在了第一个token的选择上。
在the weather in tokyo的情况下,第一个token是:
"the"
但在fetch_weather的情况下,它是表示JSON对象开始的特殊token:
|JSON>
您可能通过让LLM总是输出JSON,然后用一些自然语言token如请求人工输入或暂时完成来声明其意图(而不是像查询城市天气这样的"正常"工具),从而获得更好的结果。当然,在实际代码中这些仍会用英文标识符如request_human_input或done_for_now。
人类交互的工具定义:
class Options:
urgency: Literal["low", "medium", "high"]
format: Literal["free_text", "yes_no", "multiple_choice"]
choices: List[str]
# 人类交互的工具定义
classRequestHumanInput:
intent: "request_human_input"
question: str
context: str
options: Options
# 在Agent循环中的使用示例
if nextStep.intent == 'request_human_input':
thread.events.append({
type: 'human_input_requested',
data: nextStep
})
thread_id = await save_state(thread)
await notify_human(nextStep, thread_id)
return# 跳出循环,等待响应回来并带上thread ID
else:
# ... 其他情况
Webhook处理示例:
@app.post('/webhook')
defwebhook(req: Request):
thread_id = req.body.threadId
thread = await load_state(thread_id)
thread.events.push({
type: 'response_from_human',
data: req.body
})
# 简化处理,实际中您可能不想在web worker中阻塞
next_step = await determine_next_step(thread_to_prompt(thread))
thread.events.append(next_step)
result = await handle_next_step(thread, next_step)
# TODO - 循环或中断或执行其他操作
return {"status": "ok"}
完整的上下文窗口示例: 如果我们使用原则三中的XML格式,几轮对话后的上下文窗口可能如下:
<dingtalk_message>
From: @小张
Channel: #部署群
Text: 可以帮我部署后端v1.2.3到生产环境吗?
Thread: []
</dingtalk_message>
<request_human_input>
intent: "request_human_input"
question: "确认要将v1.2.3部署到生产环境吗?"
context: "这是生产环境部署,会影响线上用户。"
options: {
urgency: "high"
format: "yes_no"
}
</request_human_input>
<human_response>
response: "确认,请继续"
approved: true
timestamp: "2024-03-15T10:30:00Z"
user: "zhangsan@company.com"
</human_response>
<deploy_backend>
intent: "deploy_backend"
tag: "v1.2.3"
environment: "production"
</deploy_backend>
<deploy_backend_result>
status: "success"
message: "Deployment v1.2.3 to production completed successfully."
timestamp: "2024-03-15T10:30:00Z"
</deploy_backend_result>
核心优势:
1.清晰指令:不同类型的人类联系工具允许LLM更具体化
2.内循环vs外循环:启用传统ChatGPT风格界面之外的Agent工作流,其中控制流和上下文初始化可能是Agent->Human而不是Human->Agent(想想由cron或事件启动的Agent)
3.多人访问:可以通过结构化事件轻松跟踪和协调不同人类的输入
4.多Agent:简单的抽象可以轻松扩展以支持Agent->Agent请求和响应
5.持久性:结合原则六(通过简单API启动/暂停/恢复),这使得持久、可靠和可检查的多人工作流成为可能
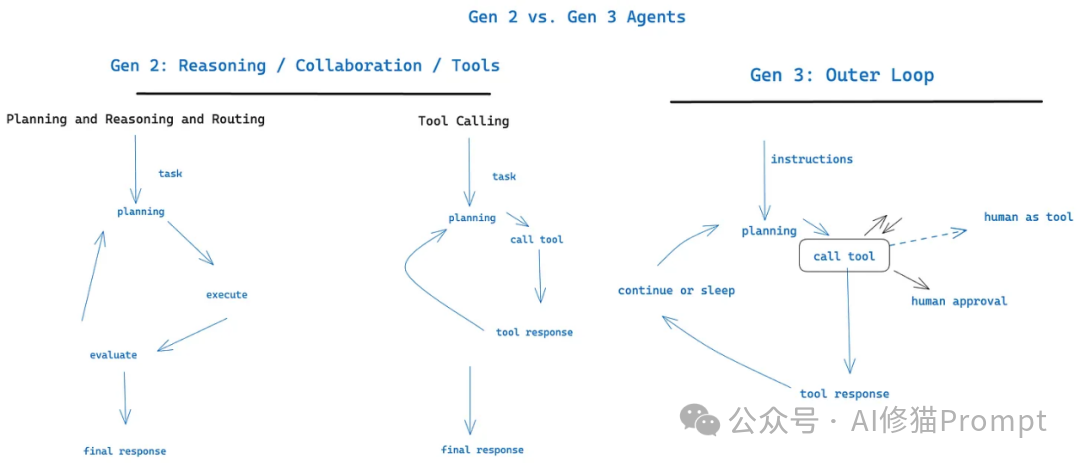
这与原则十一(从任何地方触发,在用户所在的地方相遇)完美配合。
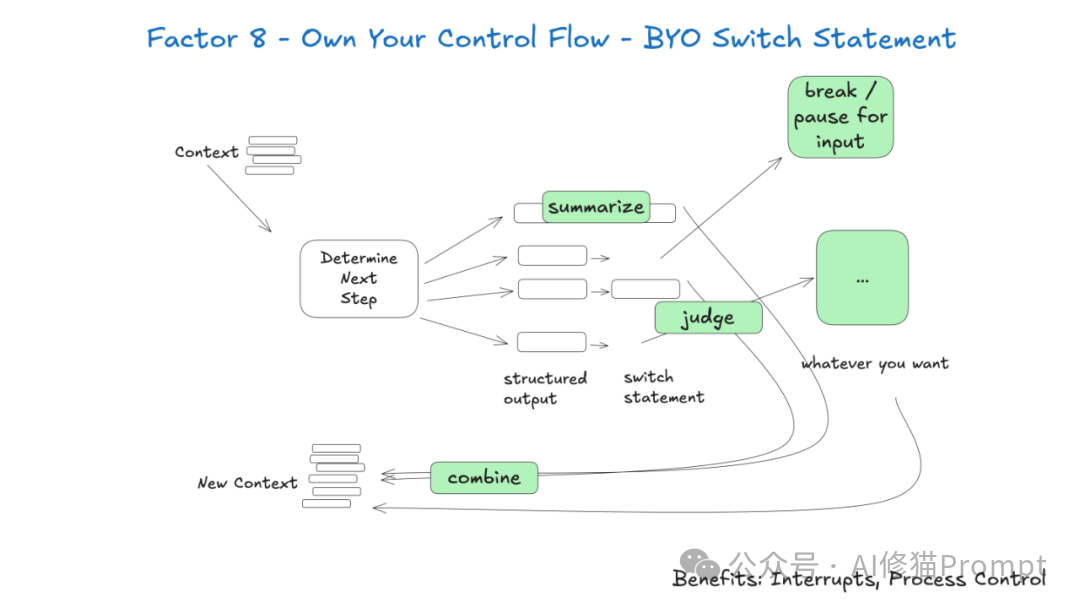
控制流是您的核心竞争力,绝不能交给框架来决定。如果您拥有控制流,就可以做很多有趣的事情。构建对您的特定用例有意义的自定义控制结构。
具体来说,某些类型的工具调用可能需要跳出循环并等待来自人类或其他长期运行任务(如训练管道)的响应。您还可能希望加入以下功能的自定义实现:
三种控制流模式示例:
下面的例子展示了三种可能的控制流模式:
def handle_next_step(thread: Thread):
whileTrue:
next_step = await determine_next_step(thread_to_prompt(thread))
# 为了清晰在这里内联 - 实际中您可以将其放入方法中,
# 使用异常进行控制流,或任何您想要的方式
if next_step.intent == 'request_clarification':
thread.events.append({
type: 'request_clarification',
data: nextStep,
})
await send_message_to_human(next_step)
await db.save_thread(thread)
# 异步步骤 - 跳出循环,稍后我们将收到webhook
break
elif next_step.intent == 'fetch_open_issues':
thread.events.append({
type: 'fetch_open_issues',
data: next_step,
})
issues = await linear_client.issues()
thread.events.append({
type: 'fetch_open_issues_result',
data: issues,
})
# 同步步骤 - 将新上下文传递给LLM以确定下一个下一步
continue
elif next_step.intent == 'create_issue':
thread.events.append({
type: 'create_issue',
data: next_step,
})
await request_human_approval(next_step)
await db.save_thread(thread)
# 异步步骤 - 跳出循环,稍后我们将收到webhook
break
关键功能要求: 每个AI框架中我最希望有的第一功能是,我们需要能够中断正在工作的Agent并稍后恢复,特别是在工具选择和工具调用之间。
没有这种级别的可恢复性/粒度,就无法在工具调用运行之前审查/批准它,这意味着您只能:
1.在内存中暂停任务,等待长期运行的事情完成(想想while...sleep),如果进程中断则从头重新启动
2.将Agent限制为只能进行低风险的研究和摘要调用
3.给Agent访问做更大、更有用事情的权限,然后只能希望它不会出错
您需要根据具体的业务逻辑设计定制化的控制结构:某些工具调用需要立即执行并继续,某些需要暂停等待外部确认,某些需要特殊的错误处理逻辑。这种灵活性是框架无法提供的,也是构建真正可靠的生产系统所必需的。
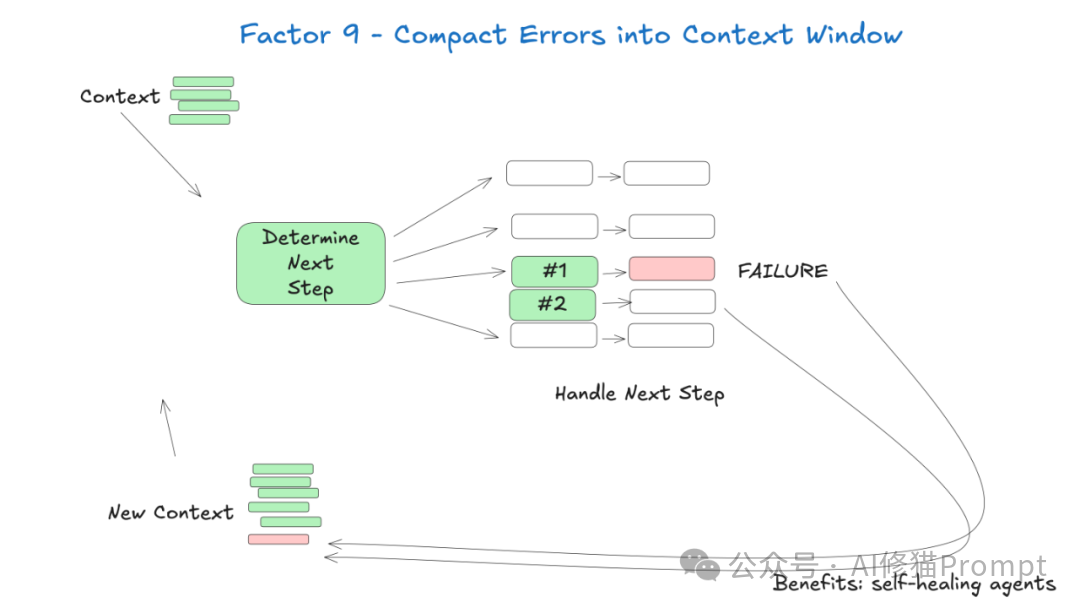
Agent的"自愈"能力是其最大优势之一,但前提是错误信息能够被有效地传达给LLM。Agent必须能够从错误中恢复,这是其主要价值之一!您可以有效地从错误中恢复,因为LLM可以读取错误消息,推理什么地方出错了,并决定如何解决它。
但错误很大,当它们开始占用您的上下文窗口时,会推出其他内容。
错误处理的关键挑战:
1.错误压缩:将详细的错误信息压缩成简洁但有用的格式
2.错误分类:区分可恢复错误和致命错误
3.错误计数:防止Agent陷入错误循环
4.错误清理:在错误解决后从上下文中移除
错误处理示例:
class ErrorHandler:
def__init__(self):
self.error_counts = defaultdict(int)
self.max_retries = 3
defhandle_error(self, error: Exception, context: str) -> str:
error_type = type(error).__name__
self.error_counts[error_type] += 1
ifself.error_counts[error_type] > self.max_retries:
returnf"<critical_error>Too many {error_type} errors. Human intervention required.</critical_error>"
# 压缩错误信息
compressed_error = self.compress_error(error, context)
returnf"<e>{compressed_error}</e>"
defcompress_error(self, error: Exception, context: str) -> str:
# 提取关键信息,过滤掉冗余的堆栈跟踪
ifisinstance(error, ConnectionError):
returnf"Connection failed to {context}: {str(error)[:100]}"
elifisinstance(error, ValidationError):
returnf"Validation error in {context}: {error.args[0] if error.args else 'Unknown validation issue'}"
else:
return f"{type(error).__name__} in {context}: {str(error)[:100]}"
上下文窗口中的错误表示:
<deploy_backend>
intent: "deploy_backend"
tag: "v1.2.3"
environment: "production"
</deploy_backend>
<e>部署服务连接失败: 无法连接到 https://deploy.company.com</e>
<request_more_information>
intent: "request_more_information_from_human"
question: "部署服务似乎不可用,我应该尝试其他方案还是等待?"
context: "由于连接问题,v1.2.3部署失败。"
</request_more_information>
在有限的上下文窗口中表示错误信息是一门艺术:既要保留足够的诊断信息让AI理解问题所在,又不能占用过多宝贵的上下文空间。您需要实现智能的错误分类、压缩和优先级排序机制,甚至可以在错误解决后将其从上下文中移除以节省空间。同时,建立错误计数器和阈值机制防止AI陷入重复错误的循环,当达到阈值时及时升级给人类处理。
错误恢复策略:
def smart_error_recovery(thread: Thread, error: Exception):
ifisinstance(error, RateLimitError):
# 对于速率限制,等待并重试
thread.events.append({
'type': 'rate_limit_hit',
'data': {'wait_time': error.retry_after}
})
return'wait_and_retry'
elifisinstance(error, AuthenticationError):
# 对于认证错误,请求人类干预
thread.events.append({
'type': 'auth_error',
'data': {'service': error.service}
})
return'request_human_help'
else:
# 对于其他错误,让LLM决定下一步
compressed_error = compress_error(error)
thread.events.append({
'type': 'error',
'data': compressed_error
})
return 'let_llm_decide'
这种智能错误处理机制是构建可靠AI系统的关键组成部分。
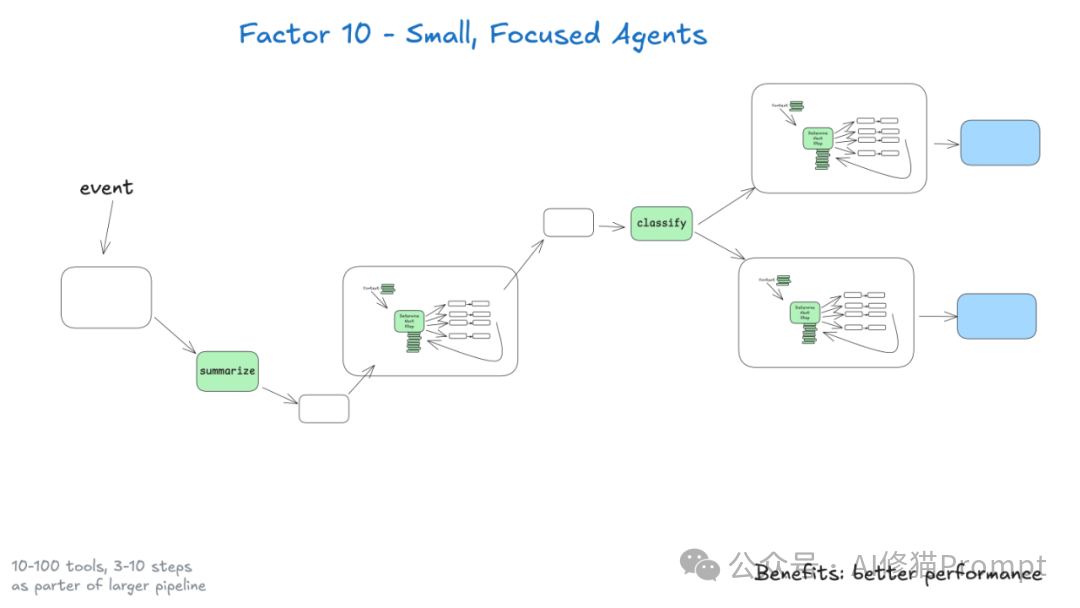
抵制构建万能Agent的诱惑,而是设计专注于特定领域的小型Agent。这个原则基于一个关键洞察:随着上下文的增长,LLM更容易迷失焦点或产生错误。通过将Agent限制在3-20步的工作流范围内,您可以保持上下文的可管理性和LLM性能的高水准。小Agent更容易测试、调试和维护,也更容易在不同场景中复用和组合。即使未来LLM能力大幅提升,这种模块化的方法仍然有价值:它让您能够逐步扩展Agent的能力边界,同时保持质量和可控性。
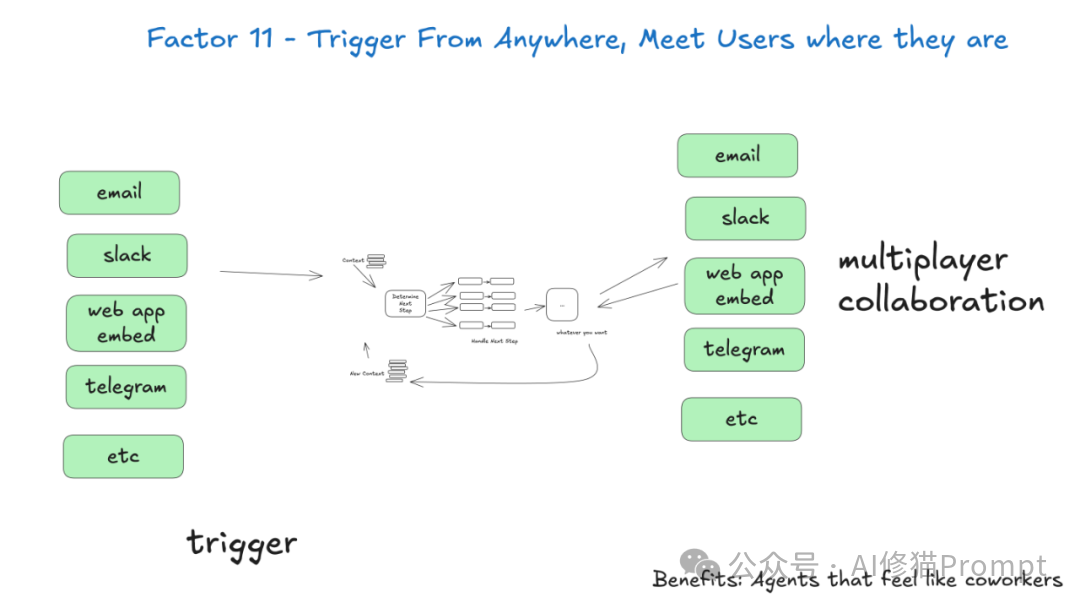
现代用户习惯在多个平台和界面中工作,您的AI应该能够适应这种多样性。实现从任何渠道触发Agent的能力:API调用、定时任务、Webhook、钉钉消息、飞书、短信等。这不仅提高了用户体验,也支持"外循环Agent"的工作模式——Agent可以由系统事件触发,长时间自主工作,在需要时通过用户偏好的渠道联系人类。这种设计让您能够给Agent配备更高风险的工具,因为您有可靠的机制在关键时刻获得人类的监督和批准。
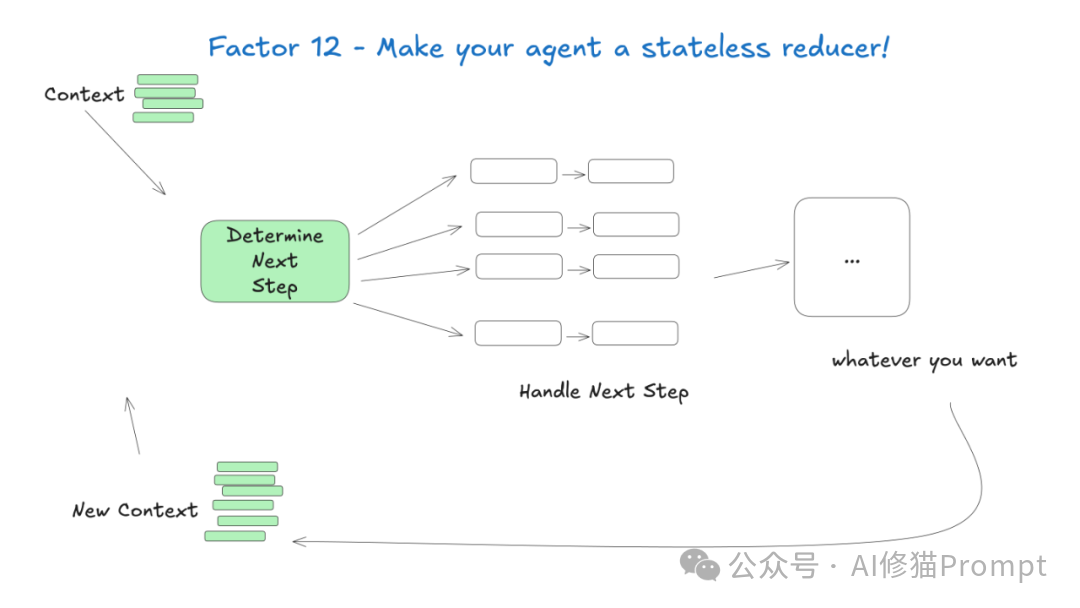
Agent设计为无状态的函数式处理器:接收输入(当前状态),产生输出(下一步动作),不保存内部状态。所有状态都应该存储在外部的持久化系统中,Agent本身只是一个纯函数的转换器。这种设计带来多重优势:更容易测试(纯函数易于验证)、更容易扩展(无状态组件可以任意并行)、更容易部署(无需考虑状态迁移)、更容易恢复(可以从任何保存的状态重新开始)。结合前面的原则,这种架构让您能够构建真正可靠和可扩展的AI应用系统。
这12条原则的核心思想是从"框架优先"转向"原则优先"的开发方式。与其花时间学习和适应不同的框架,不如深刻理解构建优秀AI应用的基本原则。框架会过时,但好的设计原则是永恒的。这就像学习设计模式比学习特定的编程框架更有价值一样。
最有意思的是,这种方法提供了一条风险可控的AI化路径。您不需要一次性重构整个系统,而是可以逐步在现有产品中加入AI能力。今天可能只是在客服系统中加入智能回复,明天可能在推荐算法中引入LLM,后天可能在数据分析中加入自然语言查询。每一步都是可控的、可回滚的。
假设您在构建一个电商平台的智能客服系统。按照12-Factor原则,您不会直接使用某个Agent框架,而是:首先设计清晰的工具调用接口(查询订单、处理退款等),然后精心设计提示词来处理常见的客服场景,接下来实现状态管理来跟踪每个对话的进展,最后设计简单的API来让人工客服能够随时介入。这样构建的系统不仅更可靠,也更容易维护和扩展。
如果您在开发内容创作助手,可以这样应用这些原则:将不同的创作任务(标题生成、大纲规划、段落写作)设计为独立的小Agent,每个Agent专注于自己的领域。用户可以从任何平台(Web、移动App、浏览器插件)触发这些Agent,系统会根据用户的创作进度智能地组织上下文信息。这种设计既提高了创作效率,又保持了用户的创作控制权。
说到底,12-Factor Agents项目给我们的最大启发是:构建优秀的AI产品需要的是扎实的软件工程能力,而不是对某个特定框架的深度依赖。当您下次开始一个AI项目时,不妨问问自己:我真的需要这个复杂的框架吗?还是说,我可以用更简单、更可控的方式来实现同样的功能?
记住修猫的建议:最好的技术往往是最简单的技术。在AI这个快速发展的领域里,保持技术选择的灵活性比追求最新最酷的框架更重要。毕竟,您的用户关心的是产品能否可靠地解决他们的问题,而不是您用了多么豪华的技术栈。
文章来自于微信公众号“AI修猫Prompt”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
