# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
蛋白质之后,DNA正成为AI+生命科学的下一个热门领域。
某种程度上,用大模型来破解DNA问题,像是对“智能”的溯源。
香港大学计算与数据科学学院院长马毅教授说,DNA是世界上最早的大模型,它通过脱氧核糖核酸的碱基结构,有规则地记录外部世界的规律,这很像语言。
正是基于这种相似性,基因组语言模型(gLMs)应运而生。这类模型能够有效捕捉DNA序列中具有生物学意义的特征模式,从而为深入理解人类全基因组调控机制、解析遗传变异致病性以及推动治疗发现提供了新的研究范式。
然而,现有的基因组语言模型评估方法缺乏统一且全面的框架,这使得研究人员难以准确判断模型的实际性能。
近日,来自香港科技大学、中山大学、哥伦比亚大学、澳门科技大学、腾讯的研究人员在预印本平台bioRxiv上发布了题为Genomic Touchstone: Benchmarking Genomic Language Models in the Context of the Central Dogma的最新成果。

团队提出一个全面且系统化的基准,旨在通过36个不同任务和88个数据集来评估基因组语言模型(gLMs)的性能,涵盖中心法则的三个核心模态:DNA、RNA和蛋白质,包含53.4亿个碱基对的基因组序列。
研究人员针对34个代表模型进行了测试,包括Transformer、卷积神经网络(CNNs)、Hyena和Mamba等架构,参数规模从330万到25亿不等。
结果显示,一些模型在DNA、RNA和蛋白质三类测试中均排名前列,如Nucleotide Transformer(NT)、GENA-LM、Generator等。
其中,Generator是一款生成式基因组基础模型,团队来自阿里云飞天实验室、香港科技大学、合肥综合性国家科学中心数据空间研究院。
值得注意的是,本次测试未纳入Evo等超大规模模型,凸显了在有限计算资源条件下,模型带来的实质价值。
填补空白,基因大模型迎来评估基准!
作为中心法则的基础,DNA承载着生命活动的遗传蓝图,因此,基因组语言模型(gLMs)的终极评估标准应当是其在整个生物过程中的泛化能力。
然而,当前评估体系仍缺乏一个统一、全面的分析框架,这使得研究人员难以准确判断哪些模型能够最有效地将序列特征转化为具有生物学意义的预测结果。
研究团队提出了名为Genomic Touchstone的基准测试框架,旨在全面且公正地评估基因组语言模型(gLMs)在解决现实世界中生物问题的表现。
这是首个将DNA、RNA和蛋白质序列任务纳入评估范围的基准测试,有助于研究人员理解模型在复杂生物学背景下的泛化能力,为未来的模型开发提供指导。
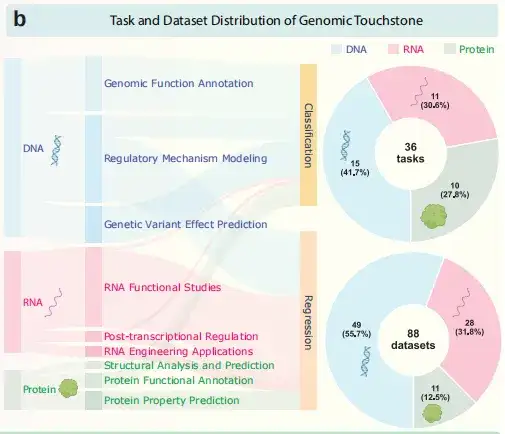
图:Genomic Touchstone的任务和数据库分布
具体来看,Genomic Touchstone包含36项多样化的任务,利用88个不同的数据集进行评估,涵盖了总计53.4亿个碱基对的基因组序列。
接着,团队对34个代表模型进行了测试,这些模型包括Transformer、卷积神经网络(CNNs)、Hyena和Mamba等架构,参数规模从330万到25亿不等。
根据测试结果,研究人员揭示出四个关键发现。
1、相较于基于RNA和蛋白质任务预训练的模型,基因组语言模型(gLMs)在测试中展现出相当或更优的表现。
2、虽然基于Transformer的模型在整体性能上仍保持领先优势,但高效序列模型则展现出特定任务的应用潜力,值得进一步深入研究
3、基因组语言模型的扩展行为尚未完全理解,尽管更长的输入序列和更多样化的预训练数据能持续提升性能,但规模的增加并不总是带来更好的结果。
4、预训练策略(包括训练目标的选择和预训练语料库的构成)对不同基因组背景下的下游泛化能力有着显著影响。
30+模型竞赛,哪些始终居于前列?
虽然测试结果显示,当前尚无单一模型能够在所有任务类型中均表现出绝对优势,这一现象揭示了基因组架构中固有的性能权衡与专业化特征。
但仍然有一些模型,在DNA、RNA、蛋白质三大类任务测试排行中始终居于前列,典型的有Nucleotide Transformer(NT)、GENA-LM、Generator等。
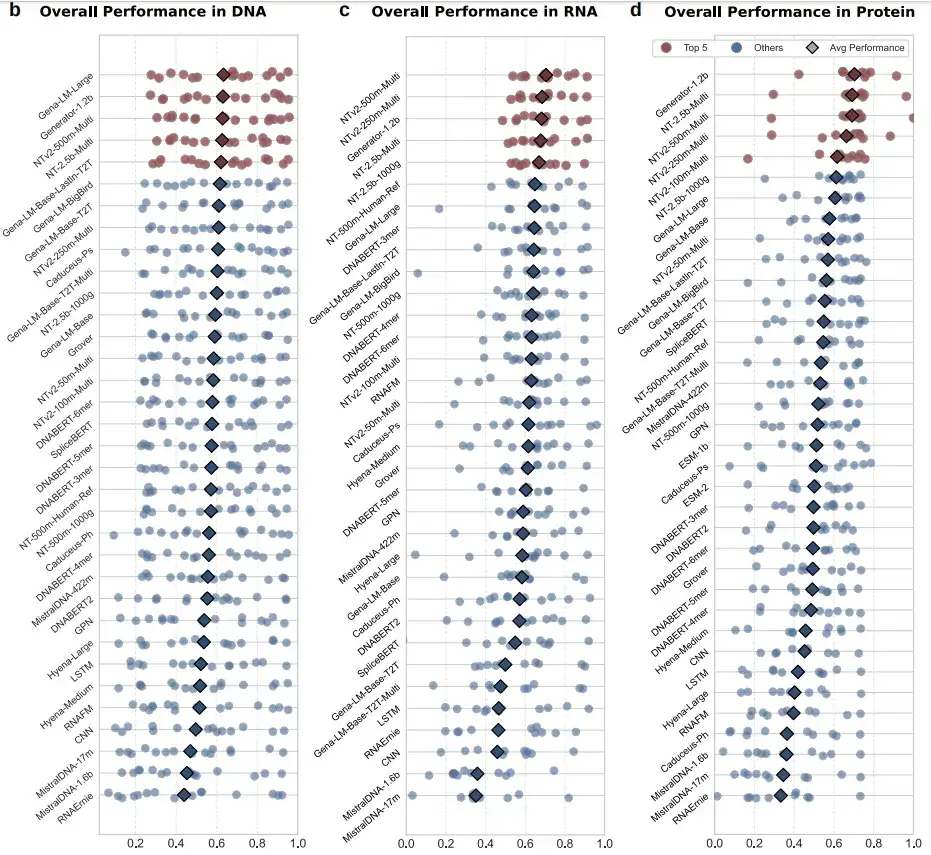
图:34款模型在三大类任务中的表现
Nucleotide Transformer是一系列预训练在DNA序列上的基础语言模型,该模型的参数数量从5000万到25亿不等,整合了来自3202个人类基因组和850种不同物种基因组的信息。
Nucleotide Transformer由InstaDeep、英伟达和慕尼黑工业大学 (TUM) 共同开发,InstaDeep于2023年被mRNA明星公司BioNTech以5.62亿英镑收购。
GENA-LM是一款针对长序列的开源DNA语言模型,其创新性地采用了 BPE(Byte Pair Encoding)分词来处理 DNA 序列,而非传统的k-mer方法,使其能够处理远超以往的 36,000 bp 超长序列。
GENA-LM的开发人员来自俄罗斯人工智能研究院(AIRI)和伦敦数学科学研究所。
Generator是一款生成式基因组基础模型,具备98k碱基对的长上下文窗口,拥有1.2B参数,并且在一个包含3860亿bp真核生物DNA序列的大规模数据集上进行了充分预训练。
Generator由阿里云飞天实验室、香港科技大学、合肥综合性国家科学中心数据空间研究院共同开发。
写在最后
Genomic Touchstone作为一项全面的基准测试,促进了对模型在复杂生物学背景下泛化能力的理解,为基因组语言模型(gLMs)的开发提供了有益指导。
然而,该研究的局限性在于主要评估现有模型、侧重判别性任务、数据以人类基因组为主以及依赖计算数据集,未来研究应在受控预训练、生成性任务、多样化物种拓展和结合湿实验室结果等方面进一步探索。
文章来自公众号“智药局”,作者“子任”



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
