# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
您有没有遇到过这样的场景:为了调试一个LLM应用的效果,您需要在一大堆Python代码中翻找那些零散的提示词字符串?每次想要A/B测试不同的提示时,就像在做开颅手术一样小心翼翼。
IBM研究团队最近发布的PDL(Prompt Declaration Language)论文,将混乱的、手工作坊式的Prompt工程,提升到了结构化、模块化、可维护的软件工程层面。这不仅仅是一个新的编程语言,更像是给混乱的提示工程世界带来了一套"乐高积木"式的解决方案。对于任何想要构建稳定、可靠、可扩展AI产品的团队来说,都具有极高的实用价值,值得花时间研究一下。


我去年就写过这IBM-PDL的前作,您有兴趣可以看下《用IBM的AutoPDL,让Agent的prompt实现数据驱动的自动优化,性能飙升68.9% |重磅》《重磅!IBM:PDL提示词声明语言,帮你拿回Prompt控制权》如果说去年的PDL让我们看到了"是什么",那么这次的论文则告诉我们"为什么重要"以及"怎么用"。这不仅仅是一个编程语言的迭代,更是对整个Prompt工程领域发展方向的重新定义。
PDL的全称是Prompt Declaration Language,但您别误会它只是另一个配置文件格式。研究者巧妙地选择了YAML作为载体,让提示词从Python代码的"T2梯队"地位解放出来,成为开发流程中的"T1梯队"。想象一下,您可以像写文档一样清晰地描述整个AI交互流程,而不用再去阅读那些复杂的命令式代码。
text:
- "分析以下合规要求:"
- model: watsonx/ibm/granite-34b-code-instruct
- "生成对应的检查脚本"
PDL最核心的设计哲学是"正交性",提供一小组简单、独立、但可以强大组合的功能模块。研究者没有给您一个固定的"Agent"模板或一个非常底层的框架需要您去编写大量命令式代码,使广大开发者在在“过度封装”与“过度裸奔”之间摇摆,像Langchain和Guidance一样,而是给了您构建自己模板的基础模块:model、code、if、for等等。这种设计让您可以根据具体业务需求,自由组合出最适合的AI工作流,而不是被框架的既定模式所束缚。
有这样的场景:业务分析师只需要用中文提问"2023年哪个产品的销售额最高?",系统就能自动连接数据库、生成SQL查询、执行分析、并提供专业的业务洞察和行动建议。这听起来像科幻电影,但用PDL,我在208行声明式代码中就实现了这个完整的商业智能分析流水线。LLM 用的Deepseek-V3的API。数据库用的是本地PostgreSQL。
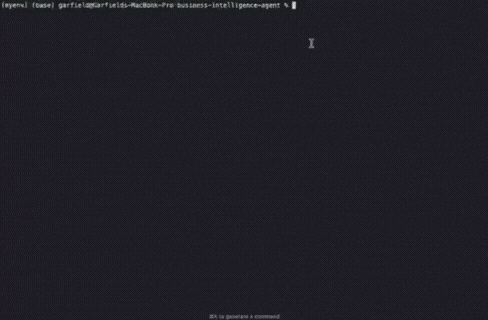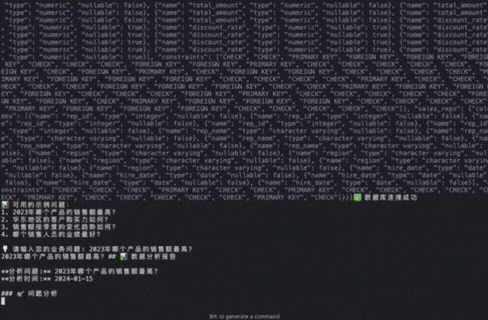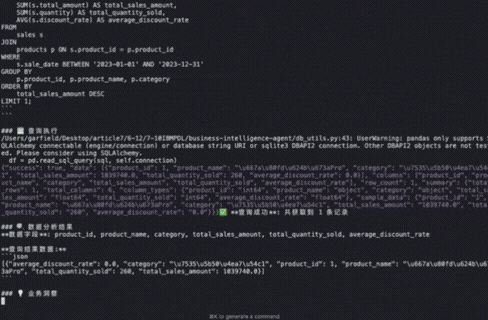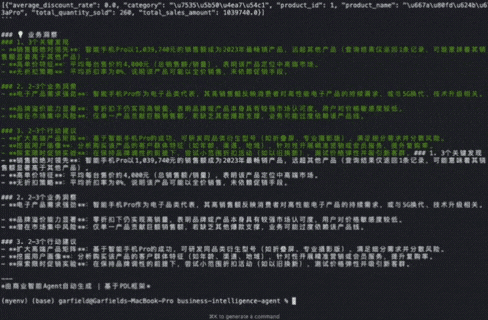
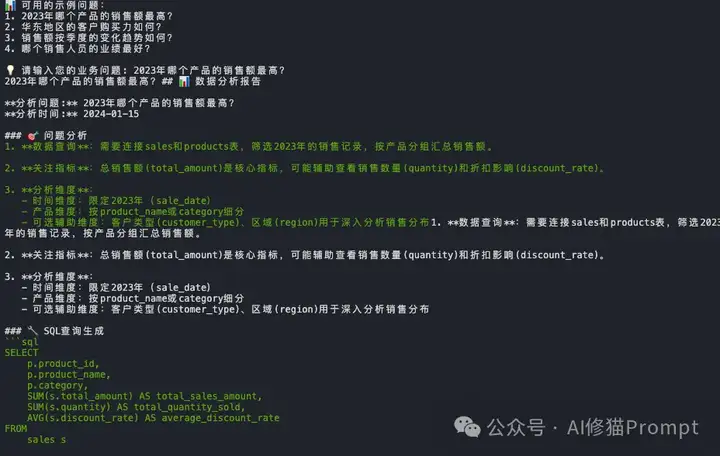
传统方式下,这样的系统需要数百行Python代码,错综复杂的异常处理,还要在多个文件间跳转才能理解整个数据流。但PDL让整个过程变得透明而优雅:
# 获取数据库结构
-def:schema_info
lang:python
code:|
# 数据库连接和Schema发现逻辑
# 用户交互
-read:
def:user_question
message:"💡 请输入您的业务问题: "
# LLM分析问题
-def:question_analysis
model:openai/deepseek-chat
input:|
分析业务问题:${ user_question }
数据库表:${ schema_info.schema_text }
# 生成SQL查询
-def:sql_query
model:openai/deepseek-chat
input:|
生成PostgreSQL查询语句...
# 执行查询并生成洞察
-def:insights
model:openai/deepseek-chat
input:|
基于查询结果,生成业务洞察和建议...
这个Agent的运行结果令人惊艳:不仅准确识别出"智能手机Pro"以103.9万元销售额位居榜首,更重要的是生成了专业级的业务分析报告,包括关键发现、业务洞察和行动建议。整个过程从问题理解到SQL生成、数据分析再到战略建议,完全自动化且逻辑清晰。完整代码和Prompt我会分享在群里!欢迎您来一起交流,讨论!感兴趣您可以看下
这个案例完美展示了PDL的几个核心优势。首先是错误处理的优雅性,我们用简单的条件判断就处理了数据库连接失败、SQL语法错误、查询结果为空等各种异常情况,而传统Python代码需要层层嵌套的try-catch块。
更令人印象深刻的是数据流的清晰性。每个步骤的输入输出都一目了然:schema_info.schema_text传递给问题分析,user_question和question_analysis组合生成SQL,query_result.data最终驱动洞察生成。这种声明式的数据流比命令式编程中的变量传递要直观得多。
PDL还自动处理了一个实际开发中的常见问题:LLM生成的SQL查询经常被包装在```sql代码块中。我们只需要几行正则表达式就在执行前清理了这些标记,而这种细节处理在传统框架中往往需要额外的预处理模块。
在企业IT管理的众多挑战中,合规检查可能是最让人头疼的任务之一。想象一下这样的日常场景:当新的监管要求下达时(比如最新的数据保护法规),CISO团队需要:
传统上,这个流程需要法务、合规、安全和运维多个团队的密切协作,耗时数周甚至数月。更要命的是,合规团队大多是非技术背景的专业人员,他们理解法规但不会写代码;而技术团队会写脚本但可能无法准确理解合规要求的细微差别。
IBM的CISO合规代理彻底改变了这个局面。这个AI系统可以:
论文使用IT-Bench基准进行的评估令人印象深刻。这个基准包含了200多个真实的IT自动化任务,覆盖了企业环境中的各种复杂场景。通过精心设计的Sankey流程图分析,研究者发现了PDL架构的核心优势:
大模型场景(GPT-4o):
小模型场景(granite3.2-8b):
这些数据背后的意义深远:企业可以用成本仅为GPT-4o几分之一的小模型,获得接近大模型的合规自动化效果。对于需要处理大量重复性合规任务的组织来说,这不仅意味着巨大的成本节约,更意味着合规流程的根本性改变,从手工作坊式的"专家驱动"模式,转向标准化、可重复、可审计的"AI驱动"模式。
传统ReAct模式看似简单优雅,实际上对小模型来说是个"不可能的任务"。想象一下这个场景:系统要求模型在Think步骤中同时完成两件完全不同性质的工作,既要输出流畅的自然语言思考过程("我需要检查服务器的安全配置"),又要生成严格格式的JSON工具调用指令({"tool_name": "check_security", "args": {"server": "web01"}})。
这种"一心二用"的要求对大模型尚且困难,对小模型更是灾难性的。论文数据显示,granite3.2-8b在传统架构下的工具调用失败率高达53.5%,超过一半的情况下,模型要么产生语法错误的JSON,要么干脆幻觉出不存在的工具名称。
IBM研究者的突破性洞察在于:认知任务的分离比整合更符合小模型的能力边界。他们设计了Think1/Think2两阶段架构:
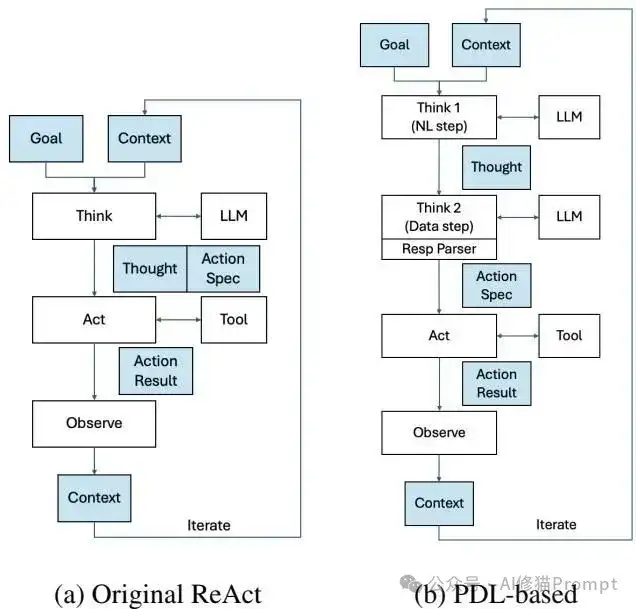
CISO Agent架构对比 - (a)传统ReAct模式 vs (b)PDL优化的两阶段架构
从架构图可以清晰看到关键区别:
但仅仅分离还不够。即使在Think2阶段,不同模型的输出格式仍然存在微妙差异,有的输出{"name": "abc"},有的输出{"tool_name": "abc"}。传统框架如CrewAI完全无法处理这种细粒度的定制需求,而PDL的自定义Response Parser机制完美解决了这个问题,能够智能识别和规范化不同格式的输出。
这种"分而治之"的策略效果惊人:在相同的测试条件下,小模型的工具调用成功率从35.4%提升到了64.6%,整体任务成功率实现了4倍的跃升。
实验数据真的很说明问题:在IT-Bench测试集上,PDL版本的CISO代理相比传统版本,在granite3.2-8b这样的小模型上实现了4倍的性能提升。更关键的是,工具调用失败率从53.5%直接降到了35.4%,这意味着您可以用更便宜的模型获得更可靠的结果。
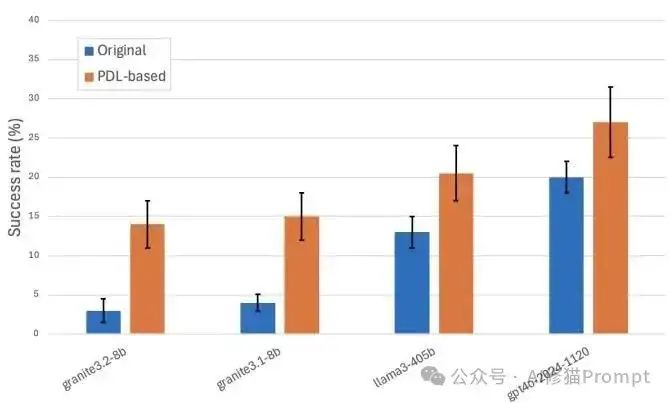
CISO Agent性能评估对比 - 原始架构(蓝色)vs PDL架构(橙色)
这张图表清晰地展示了PDL架构的强大威力。我们可以看到:
想想看,这对于成本敏感的项目意味着什么:既省钱又提效,谁不爱呢?特别是对于小模型,这种提升几乎是不可思议的,让原本"不可用"的模型变成了"高可用"的生产力工具。
性能提升的秘密藏在工具调用的成功率中。下面这张Sankey流程图揭示了PDL架构改进的核心机制:
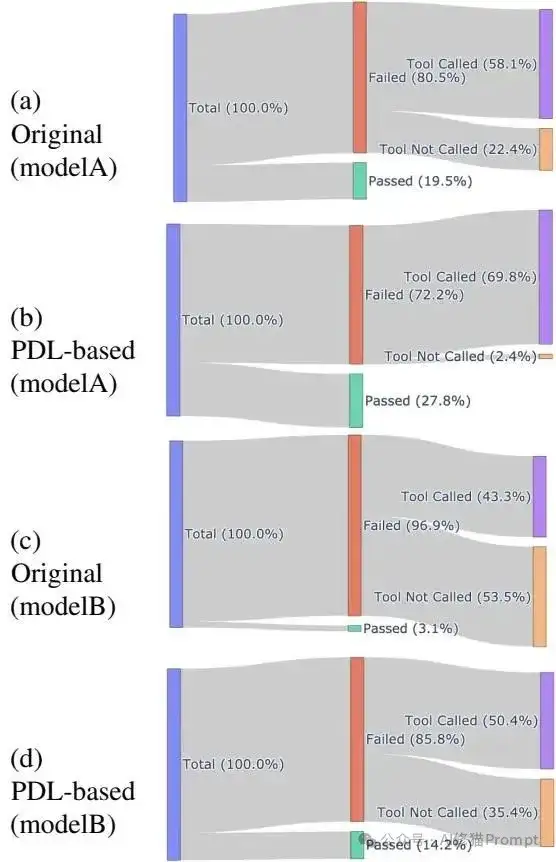
工具调用成功率详细对比 - 显示了任务成功与工具调用执行准确性的关系
这张图表的数据说明了一切:
GPT-4o场景下:
granite3.2-8b场景下:
这说明了一个关键洞察:AI Agent的瓶颈往往不在"思考",而在"执行"。PDL通过精确控制工具调用的每个细节,让小模型也能稳定地完成复杂的自动化任务。
PDL最实用的特性之一就是类型约束。通过parser和spec关键字,您可以强制模型输出符合预定格式的JSON数据。
model: ollama/granite-3.2:8b
parser: json
spec: {name: str, arguments: {topic: str}}
这样的约束在工程实践中太重要了,您再也不用担心模型突然输出一段诗歌,而您期待的是一个API调用参数。
传统开发中,提示词就像没有户口的"黑户",散落在代码的各个角落。PDL彻底改变了这种状况:.pdl文件本身就是一份清晰的、结构化的文档。产品经理可以直接review AI逻辑,Prompt工程师专注于.pdl文件优化,后端工程师负责集成部署,每个人都有自己的专业领域,协作效率大大提升。
通过function和include关键字,PDL让提示逻辑的复用变得简单。您可以把通用的提示模板封装成模块,在不同项目中调用。更重要的是,由于PDL是纯文本的YAML格式,它对Git等版本控制系统非常友好,每次提示词的修改都能在commit历史中清晰追踪,这对团队协作来说是巨大的进步。
PDL最让人兴奋的特性可能是它的可观测性。传统方式下,LLM出现意外行为时,调试几乎是"玄学"。但PDL提供了实时的execution trace,您可以清楚地看到每个执行步骤的输入输出,数据如何在不同block间传递。这种透明度让提示词调优从"炼丹"变成了真正的工程活动。
PDL的安全特性也值得关注。它内置了沙箱执行环境,特别适合处理LLM生成的代码。对于企业级应用来说,这种安全保障是必不可少的。加上YAML格式对安全审查的友好性,PDL为企业AI应用的合规部署铺平了道路。
您知道吗,PDL的声明式特性为自动优化打开了巨大空间。未来的优化器可以根据任务复杂度自动选择合适的模型,基于语义相似度实现智能缓存,甚至并行执行多个独立的推理任务。这种系统性的成本优化能力,是传统命令式框架很难实现的。
PDL并不适合所有场景。如果您的项目只是简单的单轮对话,传统方式可能更直接。但对于企业级AI应用、多模型环境、成本敏感项目,或者需要跨团队协作的复杂场景,PDL的优势会非常明显。特别是当您需要在不同模型间灵活切换,或者要最大化小模型性能时,PDL几乎是不二之选。
客观地说,PDL也面临一些挑战。团队需要学习新的DSL,生态系统相比LangChain还在发展中,某些高度定制化的需求可能仍需要Python补充。但考虑到它解决的核心问题和带来的价值,这些成长痛点都是值得的。
IBM的PDL代表的不仅仅是一个新工具,更是AI应用工程化范式的升级。它将混乱的、手工作坊式的Prompt工程,提升到了结构化、模块化、可维护的软件工程层面。在当前AI应用从"Demo"走向"Production"的关键阶段,PDL可能就是那个让您的团队脱颖而出的秘密武器。
毕竟,谁不想让AI开发变得像搭积木一样简单而强大呢?vibe coding告诉我们,即使在看似"AI主导"的工作流程中,人类的专业知识、创造性思维和质量把控依然不可或缺。我的ima知识库“AI修猫Prompt-上下文工程”我会分享在群里,欢迎你来一起交流!
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
