# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
从Cursor到Claude Code和最近很火的Kiro,AI编程能在几秒钟内生成完整的函数,但它真的理解代码在做什么吗?最近两项突破性研究发现了一个让人意外的结果:现在的AI虽然"会写",但还远没有"真懂"。
上海人工智能实验室联合清华大学和西安交大的研究者通过创新的'编程三角形'框架,首次系统性地揭示了AI在解题思路、代码实现、测试用例生成三个维度上的认知不平衡,发现AI存在严重的'自洽性陷阱',它能轻松通过自己生成的测试,却在真实场景中频频出错。

与此同时,马里兰大学等机构的研究者从技术根源入手,指出当前AI将代码视为纯文本的根本局限,并提出了IRGraph+IRCoder的图神经网络解决方案,让AI能够真正'看懂'代码的结构逻辑。
重新审视:LLM真的懂编程吗?
第一篇论文的研究者们(来自上海人工智能实验室等)发现,当前的大语言模型虽然在HumanEval等基准上表现亮眼(比如DeepSeek-V3达到65.2分),但这些成绩可能只是表面现象。问题的根源在于现有评估体系只关注"能否生成正确代码",却忽略了"是否真正理解编程逻辑"这个更深层的问题。

编程三角形:三个维度透视AI认知结构
为此研究者提出了一个叫"编程三角形"的分析框架,把编程能力拆解成三个相互关联的维度。
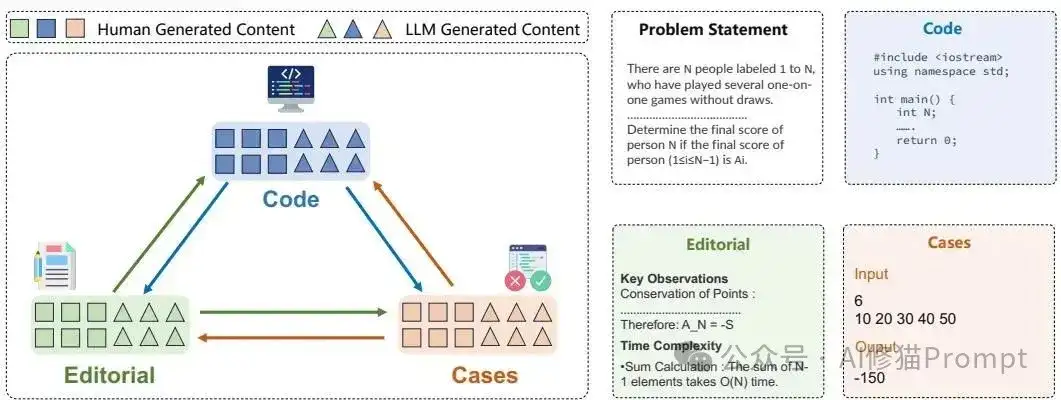
实验涵盖了多种LLM,包括通用模型(Qwen2.5-72B-Instruct)、编码模型(Qwen2.5-Coder-32B-Instruct)和推理模型(DeepSeek-V3, QwQ-32B)。
实验室里的发现:200个问题揭示的真相
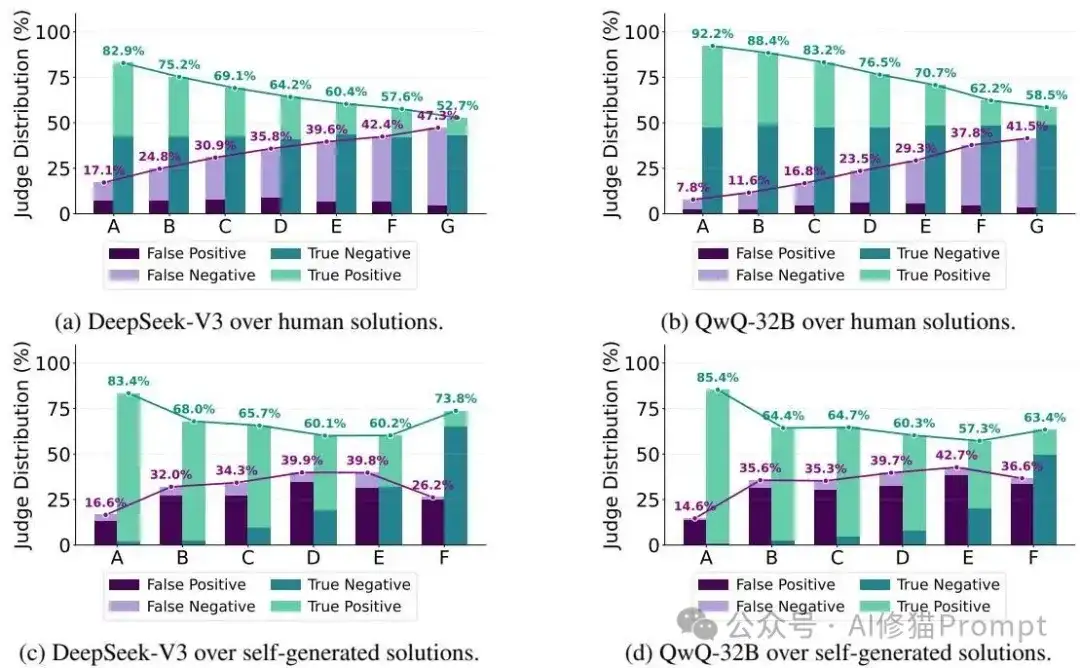
研究者从AtCoder平台精选了200个不同难度的编程问题,对包括通用模型、编程模型和推理模型在内的各种AI进行了测试。结果很有意思:Editorial(解题思路)分数普遍比Code(代码实现)分数高0%-20%,说明AI"说得比做得好";而Cases分数的表现更加奇特,它不像其他两个维度那样随难度单调下降,在最难的E、F级问题上甚至可能反超。这说明生成测试用例这个能力跟编程思维和代码实现并不完全同步,AI在这三个维度上的认知发展是不平衡的。
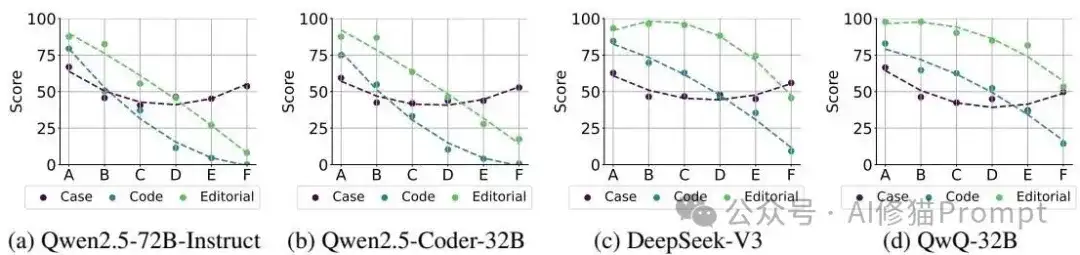
第一个意外:AI的"自洽性陷阱"
研究者发现了一个挺有意思的现象:AI存在严重的"自洽性问题"。当给AI提供它自己生成的解题思路时,代码性能并没有显著提升,这说明AI的分析和实现能力基本是自洽的,但这种自洽性实际上限制了它的推理范围。更有意思的是,AI生成的代码能以很高的通过率跑过它自己生成的测试用例(比官方用例高5%-40%),但这其实是一种"作弊",因为自生成的用例往往无法覆盖AI自身认知盲区内的边缘情况。这就像让一个色盲的人来检查自己的色盲程度,他永远发现不了自己看不到的颜色。
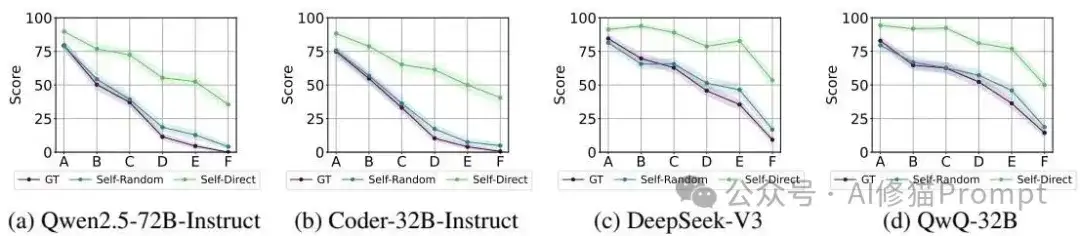
第二个意外:与人类的巨大分布差异
通过构建性能矩阵和计算余弦相似度,研究者发现AI生成的解决方案之间相似度极高(>0.8),而人类提交的方案则呈现出更大的多样性。这个发现很关键:AI倾向于犯同样的错误,推理模式相对固化,缺乏人类程序员那种创造性的思维发散。即使是多次roll-out生成,AI也难以跳出自己的认知框架,这就像是被困在了一个思维的"回音室"里。
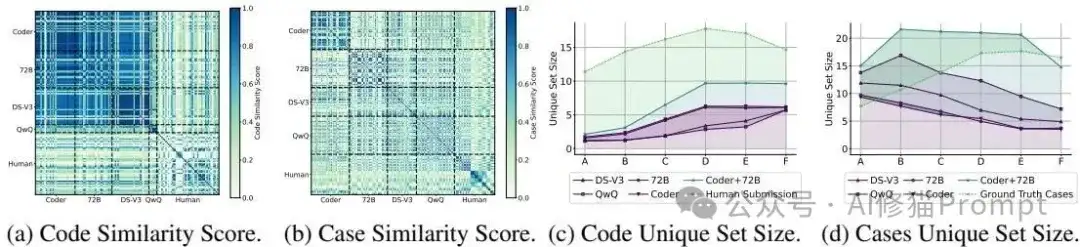
引入人类生成的解题思路、解决方案和多样化的测试用例,可以显著提升LLMs的性能和鲁棒性。例如,为模型提供人类编写的正确解题思路,能大幅提高其代码的通过率。并且融合多个不同模型的输出(模型混合)也能有效减轻单个模型的认知偏差,提升解决方案和测试用例的多样性与鲁棒性。
第三个意外:矛盾中藏着改进的钥匙
虽然存在自洽性问题,但研究者也发现了AI内部的"不一致性",而这种不一致性其实是个好消息。比如,AI可能代码写错了,但却能准确分析出自己代码中的问题;或者能用自生成的测试用例在一定程度上检测出解决方案的错误。这种跨维度的能力差异为自我改进提供了可能性,就像一个学生虽然做题不行,但批改作业还挺准的。
问题的另一面:文本表示的天花板
来自马里兰大学等机构的研究者从技术实现的角度切入了这个问题。他们指出,基于Transformer的模型天生不适合处理图结构数据,而代码的本质特征「控制流、数据流、调用关系等」恰恰是图结构的。仅仅把代码当作一串文本来处理,就像用一维的线来描述三维的立体图形,信息损失是必然的。更重要的是,两段功能完全相同的代码可能在模型内部产生截然不同的表示,这违背了语义等价性原则。

数据工程的突破:200万文件的编译马拉松
在提出技术方案之前,研究者首先要解决一个巨大的工程挑战:现有的大规模代码数据集都只有源代码,没有配套的中间表示。要让AI理解代码的图结构,就必须有大量的源代码-IR配对数据。研究者基于ComPile数据集,重新编译了约200万个C/C++文件,使用LLVM 16提取对应的IR数据,还自定义了llvmite库来支持更好的数据提取。除了真实数据,他们还用GPT-4o合成了大量问答对,格式为(源代码, IR, 问题, 答案),专门用来测试结构化代码理解能力。
IRGraph:给代码画一张"关系图"
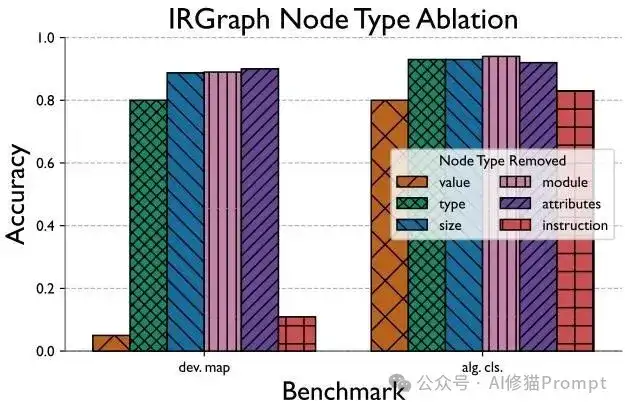
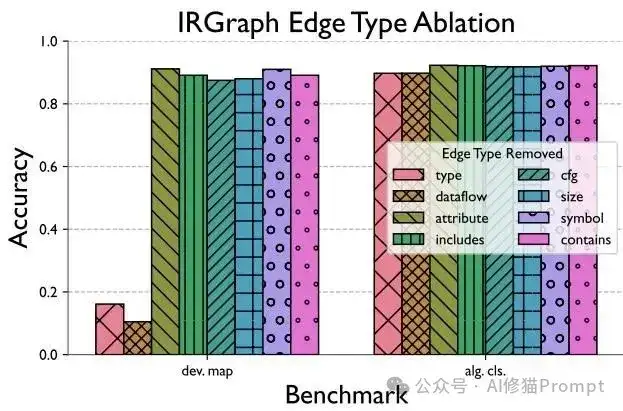
有了数据基础,研究者设计了一个叫IRGraph的新图表示格式。它基于LLVM中间表示,比现有的ProGraML等方法更加精细,包含6种节点类型(Value、Type、Size、Module、Attributes、Instruction)和8种边类型(Type、Dataflow、Attribute、CFG、Size、Symbol、Includes、Contains)。这就像给代码画了一张详细的"关系图",不仅包含传统的控制流和数据流,还涵盖了类型信息、属性、符号等对性能分析至关重要的细节。最牛的是,它能表示整个编译单元,而不是像以前那样只能处理单个函数。
IRGraph关键组件的重要性分析
IRCoder:用GNN软提示让AI学会"立体"看代码
有了IRGraph还不够,关键是怎么让现有的大语言模型"看懂"这张图。这就是IRCoder的核心创新所在。
什么是GNN软提示?
传统的做法要么是重新训练整个模型(成本高昂),要么是手工设计提示词(效果有限)。GNN软提示是一种巧妙的中间方案:用图神经网络(GNN)学习如何将图结构信息转换成LLM能"理解"的向量形式,然后将这些向量作为"软提示"直接插入到LLM的输入中。就像给LLM戴上了一副"图形眼镜",让它能看到代码的立体结构。
IRCoder的具体做法
研究者用一个异构图神经网络先学习IRGraph的表示,然后通过线性层投影到LLM的embedding空间,最后按照[BS, G, V₁, ..., V|V|, T₁, ..., EOS]的格式组织输入(其中G是图嵌入,V是节点嵌入,T是文本token)。训练时只更新GNN的参数,LLM权重保持冻结。
这种方法被称为IRCoder,既能保留LLM强大的生成能力,又通过图结构增强了其对代码深层逻辑的理解,同时大大减少了训练所需的计算资源。
四大战场的验证:从分类到生成的全面胜利
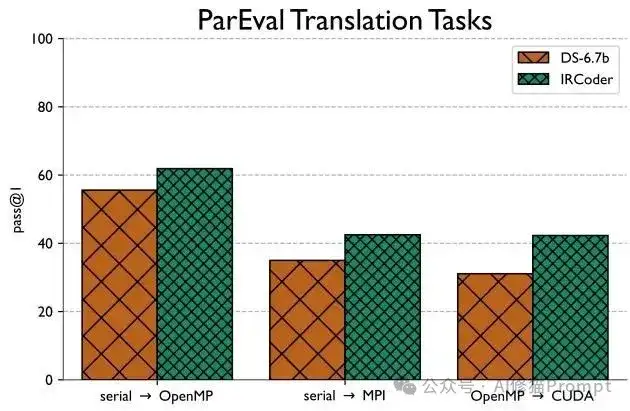
研究者在四个不同类型的基准上验证了方法的有效性。DevMap测试硬件性能预测(CPU vs GPU),POJ-104考验算法分类(104个类别),Juliet专攻安全漏洞检测(约10万样本),ParEval挑战代码翻译(顺序→OpenMP/MPI,OpenMP→CUDA)。结果显示,IRGraph在所有分类任务上都超越了ProGraML基线,IRCoder在所有任务上都超越了DeepSeek-Coder基线。特别是在代码翻译这种生成任务上,改进最为明显,OpenMP到CUDA的翻译任务提升最显著。
代码翻译基准测试结果
给AI产品开发者的实战指南
这两项研究不仅揭示了AI的认知盲区,更为我们的日常开发实践提供了宝贵的指导原则。
警惕AI的"思维定式陷阱"
第一篇论文的发现提醒我们:大型语言模型(LLM)存在“认知局限”,容易陷入自己的思维定式并犯相似的错误。让它多次生成(roll-outs)并不会带来更多样化的正确方案,反而可能只是对同一个错误思路的反复包装。因此当AI给出的代码有问题时,简单地让它“再试一次”可能效果不佳。改变提问方式或自己介入思考,尝试从一个全新的角度向它描述问题,可能会好一点。因为AI可能在一个特定思路上“卡住”了。
理性看待AI的"偏科"现象
研究显示模型在“解题思路(Editorial)”上的表现通常优于“代码实现(Code)” 。它可能在自然语言解释中“纸上谈兵”,头头是道,但转换成代码时却漏洞百出 。因此不要因为AI的解释听起来很有道理,就完全信任它生成的代码。尽可能亲自审查和测试代码。
这篇论文提醒您,AI可能是一个“偏科生”,语言分析能力(解释)强于逻辑实现能力(编码)。所以您需要的是一个会审查和测试的开发者,而不是一个被AI说服的听众。
擅用"AI专家小组"策略
模型混合能显著减少认知偏见、提高解决方案的多样性和鲁棒性。当ChatGPT给不出满意答案时,不妨把同样的问题抛给Claude或其他模型。它们各自的认知偏差不同,综合起来看,您可能会得到更全面的解决方案。这就像拥有一个"AI专家小组",每个成员都有不同的专长和盲区。
认清AI的结构理解局限
第二篇论文告诉我们,当前AI主要将代码作为纯文本处理,很难理解深层结构,比如数据流动、复杂依赖关系等。当您处理性能优化、复杂算法重构、或涉及多文件数据流的大型项目时,要对AI的建议持保留态度。它可能给出语法正确但效率低下或逻辑有误的代码,因为它缺乏编译器那样的"全局视野"。将复杂问题分解成小块,再让AI逐一处理,而不是指望它一次性解决整个架构问题,可能会更好一点。
写在最后
了解了AI的这些认知特征,我们反而能更好地与它协作。未来属于那些既理解AI能力边界、又善于发挥其优势的开发者。真正的突破不在于让AI变得完美,而在于构建人机协作的最佳模式。毕竟最强大的编程团队从来不是由完美的个体组成的,而是由能够互补短长的伙伴构成的😊
文章来自公众号“Al修猫Prompt”


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
