# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
测试时训练(test-time training)是一种通用的训练方法。
该方法将单个未标记的测试实例转化为自监督学习问题,在对测试样本进行预测之前更新模型参数。
而对于大模型训练,通常会使用一种称为情境学习的技术来提高其模型在新任务上的性能。
该方法通过将新任务的几个示例作为文本提示输入模型,从而指导模型的输出。
但情境学习并不总是适用于需要逻辑和推理的问题。 因为逻辑和推理问题是环环相扣的,需要先做好对问题的拆解,才能够解决对应的问题。
只是给出例子,而不教会大模型推理方法,相当于只是给学生几道例题和答案,却不教解题思路,对成绩的提升于事无补。
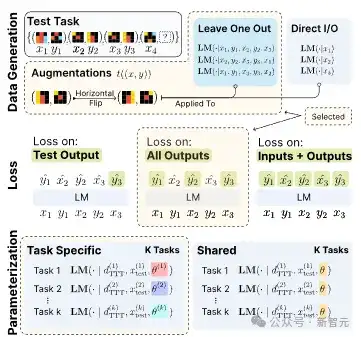
图1:大模型测试时学习的框架
测试时训练的第一步,是数据重构,即通过留一法,将K个示例拆分为K个伪任务,每个任务用K-1个样本作训练,留1个作测试。
同时修改训练优化的损失函数,涵盖所有的示例,让模型不仅学到训练集,还能扩展到测试集上。
测试时训练涉及使用少量特定于当前任务的新数据来更新某些模型参数——即模型用于进行预测的内部变量。
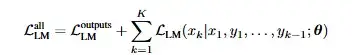
下面的图2,对应的是在抽象推理数据集(ARC)和BBH两个基准测试集应用测试时训练后,成功给出回答的示例。
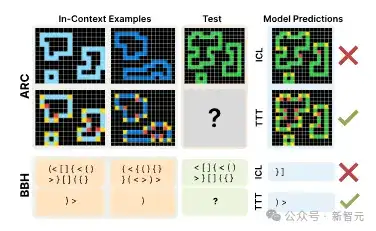
图2:使用测试时训练解决抽象推理问题的示例
测试中使用的模型,其参数量不过是8B的lemma3,而其性能提升相当显著,对于ARC数据集,准确性翻了近两倍,从17.5%提高到45%;在BBH数据集上,也从50.5%提升到57.8%。
图3:在80个随机选择的ARC验证任务子集上和全部BBH任务上的准确性
让大模型的思考逻辑问题如人类专家
为了扩展测试时给出数据集的大小,研究者还通过略微改变示例中的问题和解决方案来创建新的数据,例如通过水平翻转一些输入数据。
他们发现,在新增的数据集上训练模型可以使得模型获得最佳性能。
在使用留一法和可逆几何变换后,可通过测使用分层投票策略,对训练后的模型预测进行聚合:首先,在每个变换内部进行投票,然后从每个变换中选出的顶级候选者进行全局投票以产生最终的前两个预测。
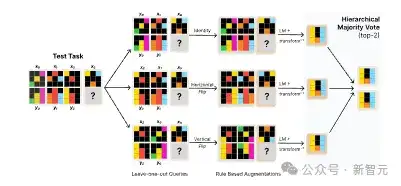
图4:分层投票策略示例
使用分层投票和测试时训练后,即使是1B参数的模型,其在抽象推理问题上的性能提升也相当显著,性能与8B模型相近,如图5所示。
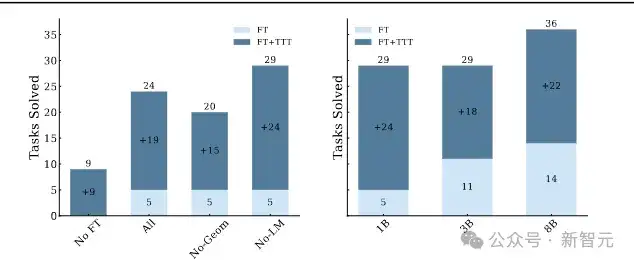
图5 1B 3B和8B参数量模型面对抽象推理问题的回答准确率对比
经过了微调并使用测试时训练的8B模型,其在抽象推理任务上的准确率高达62.8,已经超过了人类的均值60.2%,对比主流的Claude3.5,Deepseek R1,openAI o1更是遥遥领先。
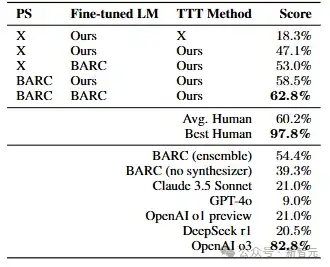
相比在提示词中给出示例,测试时训练这一策略模仿了人类的思维方式,将大任务分解为数个小目标,每一步都包含可管理的逻辑步骤。
不仅适用于抽象推理问题,对于很多涉及多步骤推理的问题,都会带来显著的性能提升。
例如物体计数问题,即跟踪打乱顺序的五个物体, 跟踪打乱顺序后的物体顺序,或是电影推荐,即选择满足多个条件的电影。
在Big-Bench hard数据集的10类任务中,通过消融分析,也可对比使用了测试训练及分层投票策略所带来的性能提升(图6)。
这意味着测试时训练解决了大模型应用的一个核心痛点,即它们能生成流畅的文本,但在需要严密逻辑链条的复杂推理任务中,往往会走捷径或产生逻辑谬误。
例如虽然会计公司的大模型可能擅长总结财务报告,但如果要求该模型预测市场趋势或识别欺诈交易,它可能会意外地失败。
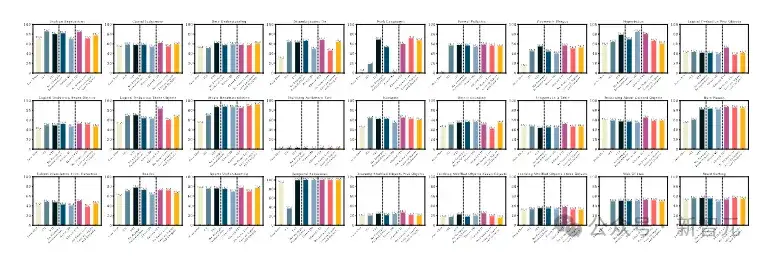
图7:在Big-Bench hard数据集上,的特定任务进行消融实验的完整结果
而测试时训练的引入,让大模型的思考方式变得类似人类专家,能够让大模型学习如何将一个大问题分解成多个子问题,然后按计划、有条不紊地解决,并在得出最终答案前对中间步骤进行自我审视和验证。
其意义不仅在于提升了模型的测试分数,更重要的是,它为构建更值得信赖的AI系统提供了可能。
一个能够清晰展示其推理步骤并进行自我纠错的AI,将在科学发现、医疗诊断、法律分析等高风险领域具有更广阔的应用前景。
这些说明测试时训练在处理新型推理任务方面的潜力,表明其在推动下一代语言模型的发展方面具有巨大前景。
然而,该研究一作Akyürek指出,即使采取了低秩适配的技术,只更新少量模型参数,从而提升测试时训练的部署效率,由于使用该策略意味着大模型每回答一个问题,都要重新进行训练。
这会导致一个通常在不到一分钟内回答查询的模型,在测试时训练下可能需要五到十分钟来提供答案。
因此Akyürek并不希望对所有用户查询都这样做,但如果您有一个非常困难的任务,希望模型能够很好地解决,那么测试是就是有用的。
而另一些任务,不需要使用该方法,上下文情境学习就够用了。
而研究者的长期目标是建立一个能持续学习的大模型,可根据查询自动判断是否需要使用测试时训练来更新参数,或者是否可以使用情境学习来完成任务,然后无需人工干预即可实施最佳测试时训练策略。
参考资料:
https://github.com/ekinakyurek/marc
https://news.mit.edu/2025/study-could-lead-llms-better-complex-reasoning-0708
https://arxiv.org/pdf/2411.07279
文章来自公众号“新智元”


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
