# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
对模型参数量的迷信、执念也许可以放下了,混合多个小模型也是未来构造对话型 AI 的一个光明的方向。
在对话型人工智能(AI)研究中,存在趋势即朝着开发参数更多的模型方向发展,如 ChatGPT 等为代表的模型。尽管这些庞大的模型能够生成越来越好的对话响应,但它们同时也需要大量的计算资源和内存。本文研究探讨的问题是:一组小模型是否能够协同达到与单一大模型相当或更好的性能?
本文介绍了一种创新而简单的方法:混合。
作者展示了如果从一组小规模的对话型人工智能中随机选择回复,生成的对话型人工智能具有很强的性能和吸引力,可以胜过参数数量级大很多的系统。作者观察到混合模型似乎具有 “最优” 的特征,通过在对话历史上进行条件化响应,一个具有特定属性的单一模型能够学习其他系统的能力。可以为用户提供更引人入胜和多样化的回复和使用体验。
作者通过在 CHAI 平台上进行大规模 A/B 测试,证明了混合模型的有效性。在真实用户的测试中,包含三个 6-13B 参数 LLM 的混合模型,胜过了 OpenAI 的 175B + 参数 ChatGPT。并且混合模型的用户留存率显著高于基于 ChatGPT 的对话型人工智能,说明用户认为混合对话型人工智能更具吸引力、娱乐性和实用性,尽管混合模型仅需要消耗少量的推理成本和内存开销。

对话型 AI
对话型人工智能的目标是设计一个能够生成引人入胜、富有娱乐性的对话系统,供人们进行交互。设 uk 表示用户的第 k 轮对话,其中每个用户轮次是一个单词序列,uk = (w (k) 1 . . . , w (k) |uk| )。同样地,设 rk 表示系统生成的第 k 个响应,也是一个单词序列,rk = (w (k) 1 , . . . , w (k) |rk| )。作为一种隐式语言模型,一个特定的对话型人工智能,参数化为 θ,在给定先前对话历史的情况下,建模预测下一个响应出现的概率。
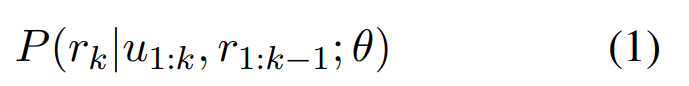
在训练过程中,系统隐式学习将更高的概率分配给流畅、引人入胜和高质量的响应。因此,可以通过从其分布中随机采样输出,无论是通过随机方法,还是通过像波束搜索这样的近似搜索过程。
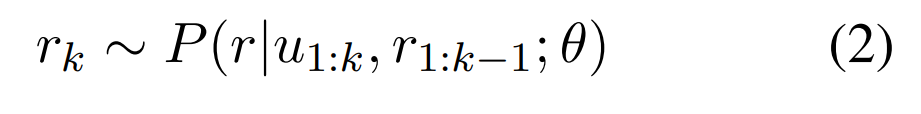
受 InstructGPT 的启发,最先进的对话型人工智能通常遵循三阶段的流程。首先,对预训练语言模型 (PrLM) 进行微调,该模型在相关的文本领域进行训练,例如,在设计引人入胜的聊天机器人时使用有趣的文学作品。其次,使用明确的人类反馈来训练奖励模型。最后,使用奖励模型改进原始的 PrLM,可以采用近端策略优化或者采用简单的拒绝抽样策略。
在开发特定的对话型人工智能时,存在许多设计选择,如基础 PrLM、用于微调的对话数据以及用于更新系统的人类反馈。人们可能期望不同的方法和训练数据能产生高度多样的系统,每个系统都展示出独特的优势和特征。然后,可以考虑如何将一组对话型人工智能组合起来,形成具有总体更好特性的系统。
集成
根据贝叶斯统计原理,分配给特定响应的概率可以被概念化为对所有合理的对话型人工智能参数取边际期望,

在实践中,当只能访问有限的一组对话型人工智能系统 {θ1, θ2...θN} 时,可以将连续积分近似为离散求和。此外可以假设 PΘ(θ) 在这些系统上均匀分布,即 PΘ(θn) = 1/N,如果该集合包含性能相似的模型,这是一个有效的假设,可以得到下面的近似式:
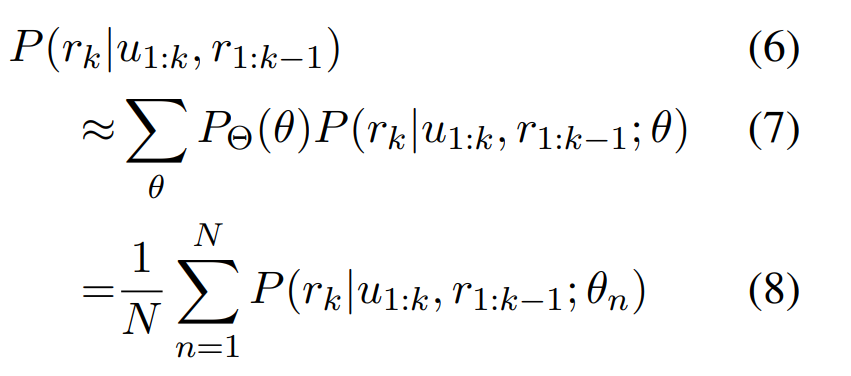
混合
作者提出的方法目标是从真实的集成分布 (方程 8) 中近似抽样。为了实现这种近似,在每一轮对话混合模型都会随机 (均匀地) 选择生成当前响应的对话型人工智能 θ。这个过程在下面的算法 1 中有详细描述。需要注意的是,在对话过程中,特定对话型人工智能生成的响应是在先前选择的对话型人工智能生成的所有先前响应的条件下进行的。这意味着不同的对话型人工智能能够隐式地影响当前响应的输出。因此当前响应是个体对话型人工智能优势的混合,它们共同合作以创建整体更吸引人的对话。

对于在 Chai Research 平台上部署的每个对话型人工智能,作者根据 A/B 测试设置中的 (文章 4.2 节的公式 15) 计算每一天 k 的用户参与度。通过考虑第 20 天 (k=20),图 1 显示了混合模型、其组成的对话型人工智能以及 OpenAI 的 GPT-3.5 的参与度比例。作者观察到中等大小的对话型人工智能 (Pygmillion、Vicuna 和 ChaiLLM) 的参与度明显低于 GPT3.5,这是在预期内的,因为 GPT3.5 的参数数量要高一个数量级。然而,混合这三个基本对话型人工智能,混合模型的结果不仅比每个组成系统都具有更高的参与度,而且性能提升显著,以至于混合模型可以胜过 OpenAI 的 GPT3.5。与其他对话型人工智能相比,混合模型的成功也可以通过比较 k=20 的用户留存比 (文章 4.1 节的公式 10) 来计算,结果如图 1 所示。
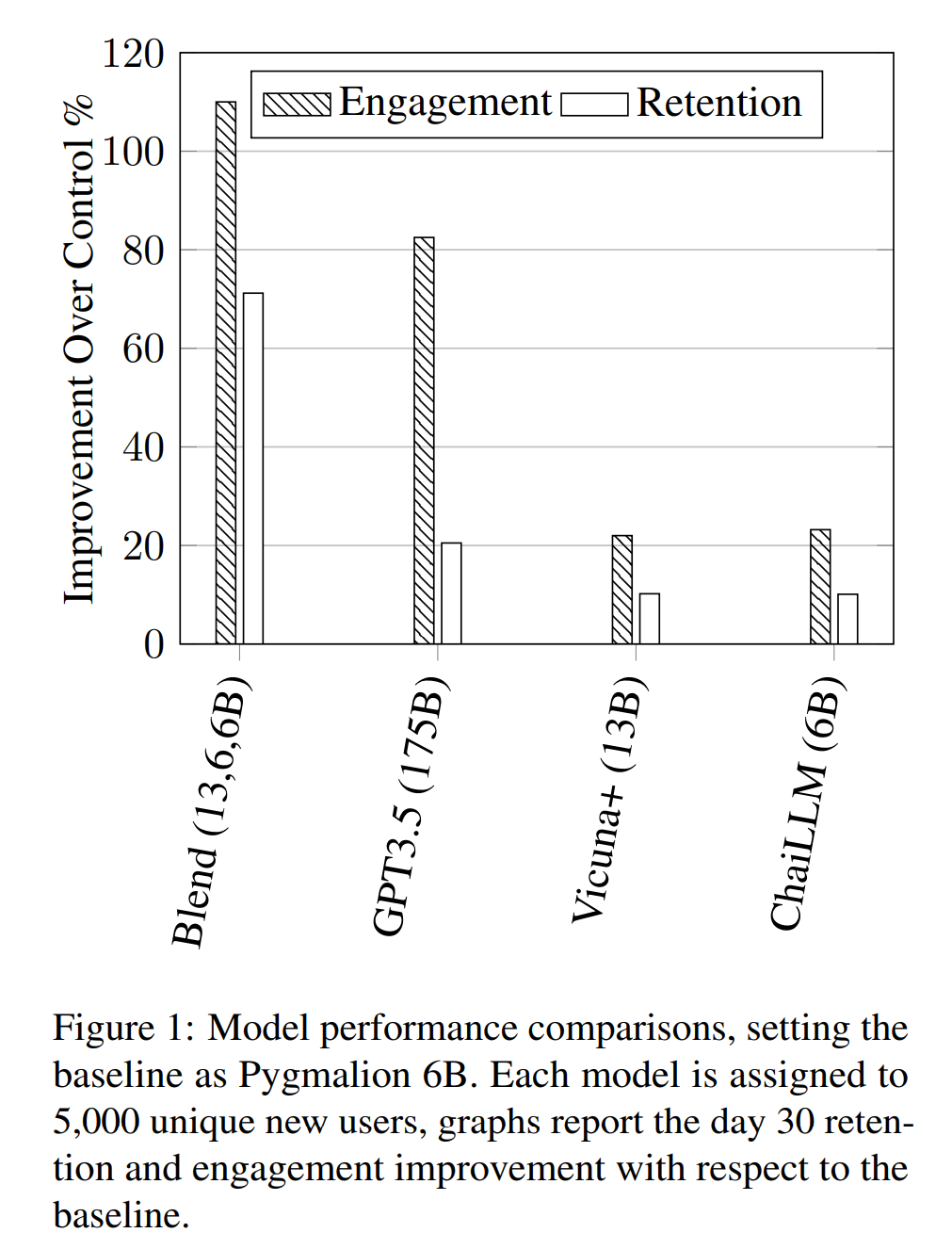
混合模型总共有 25 亿参数,而 OpenAI 有 1750 亿参数。此外,由于混合模型的响应是从单个对话型人工智能中随机抽样的,因此推理成本等同于单个 6B/13B 系统的成本。在图 2 和图 3 中,可以看出推理速度的显著差异,可以观察到混合模型在参与度和用户留存方面有显著的性能提升,而速度与小型对话型人工智能相当。这具有重要意义:与其扩大系统规模以提高质量,不如简单地混合多个较小的开源系统,而且在不增加任何推理成本的情况下,可以极大地改善用户的对话体验。这证明了在设计引人入胜且成功的对话型人工智能时,模型协作比简单的模型参数扩展更为重要。
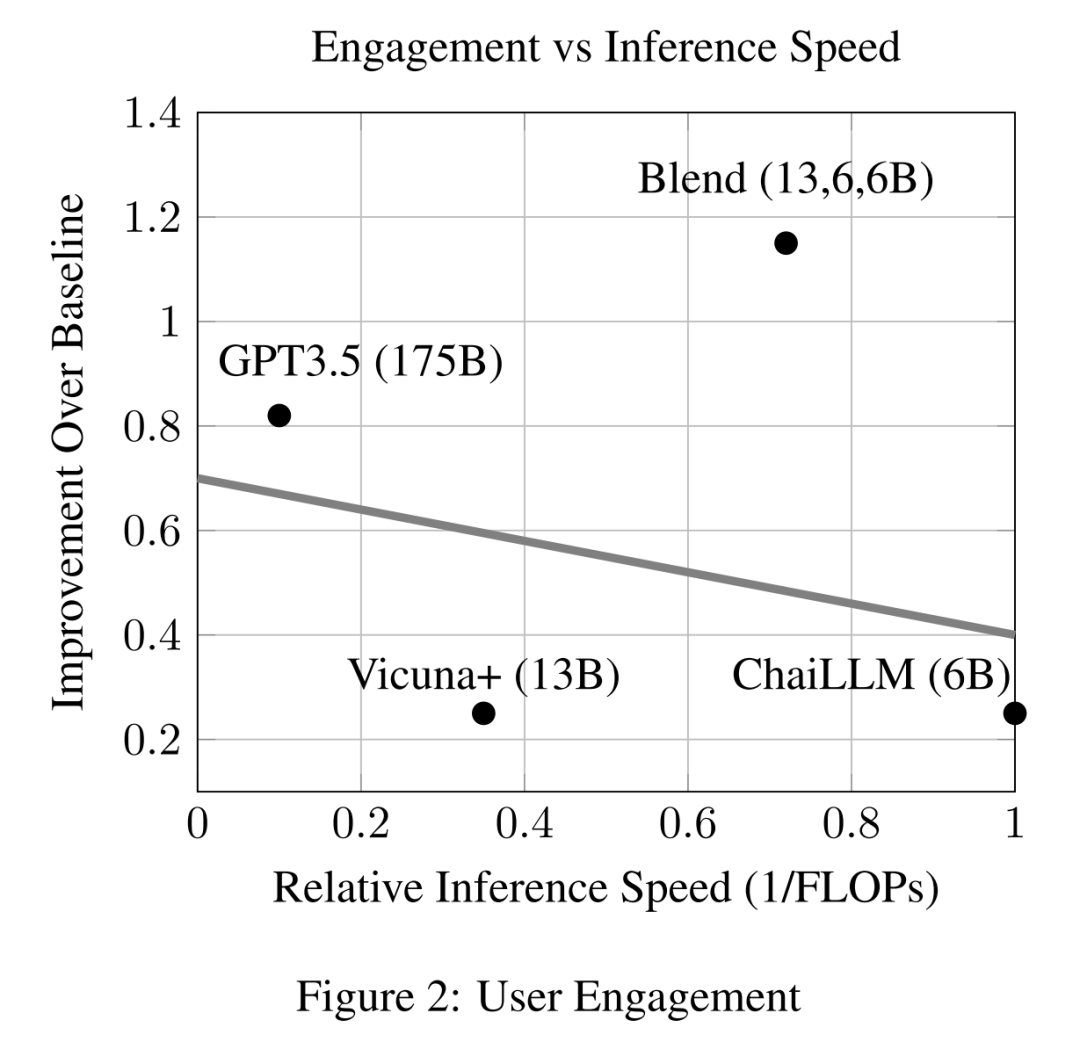
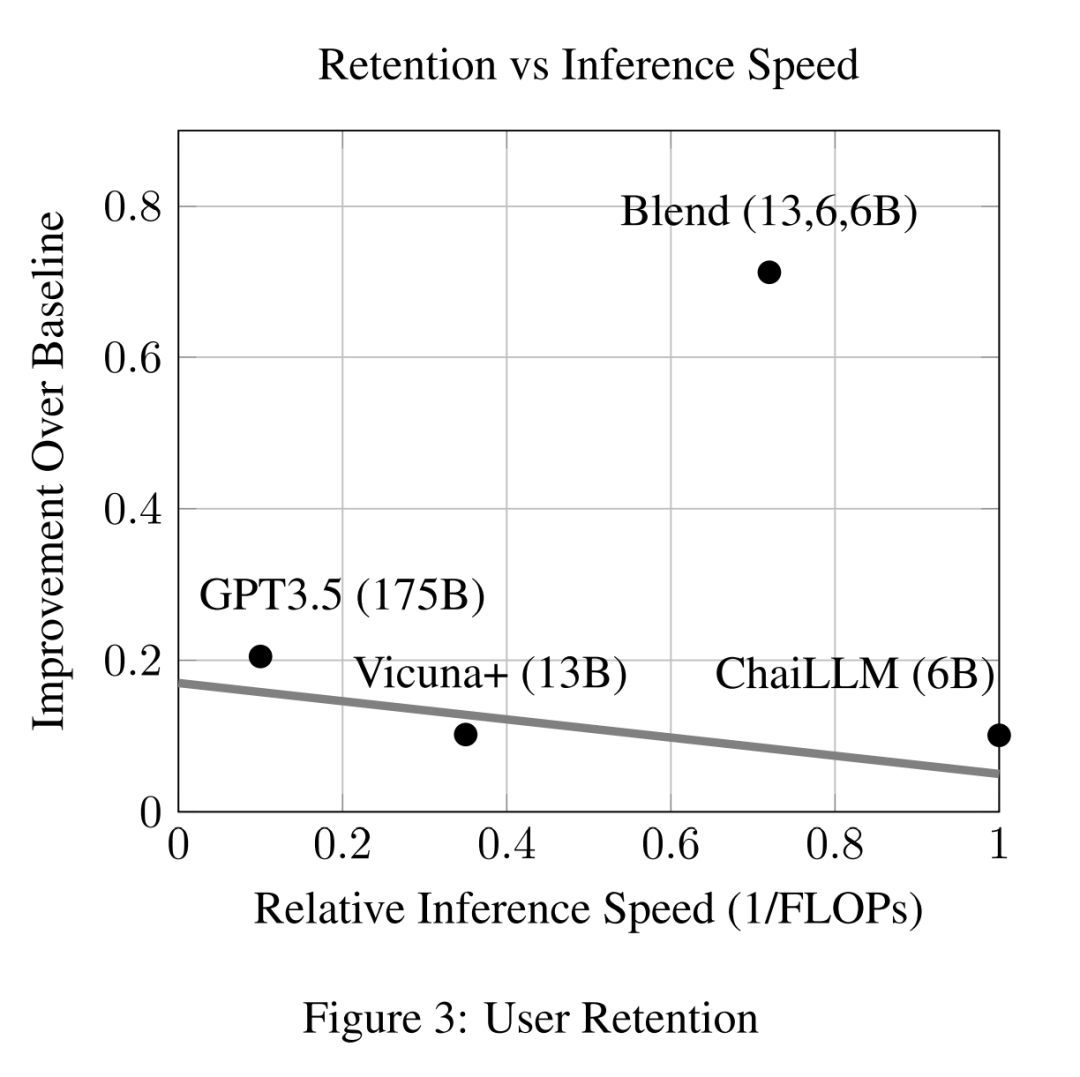
作为客观比较,表 1 报告了单一指标摘要 (论文 3.3 节)。以 Pygmillion 为控制组,作者提供了测试相对于控制组的参与度比率指标∆α 和∆γ,以及测试相对于控制组的留存比率指标∆ζ 和∆β。混合模型具有最高的相对初始参与度,∆α,以及最佳的参与度比率衰减率,∆γ。尽管 Vicuna 的留存比率衰减率∆β 优于混合模型,但 Vicuna 的初始留存比率∆ζ 明显较低,说明 Vicuna 需要更长的时间来达到混合模型的留存分数 6,如前面图 2 和 3 所示。总体而言,很明显,混合模型通过协作多个较小的对话型人工智能,在提供比单个更大的对话型人工智能 (OpenAI 的 GPT3.5) 更高质量的对话方面是有效的。

文章来自于微信公众号 “机器之心”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
