吴恩达戳破AI幻象:炒作过头了,未来公司是10人小队+Agent重做数据架构
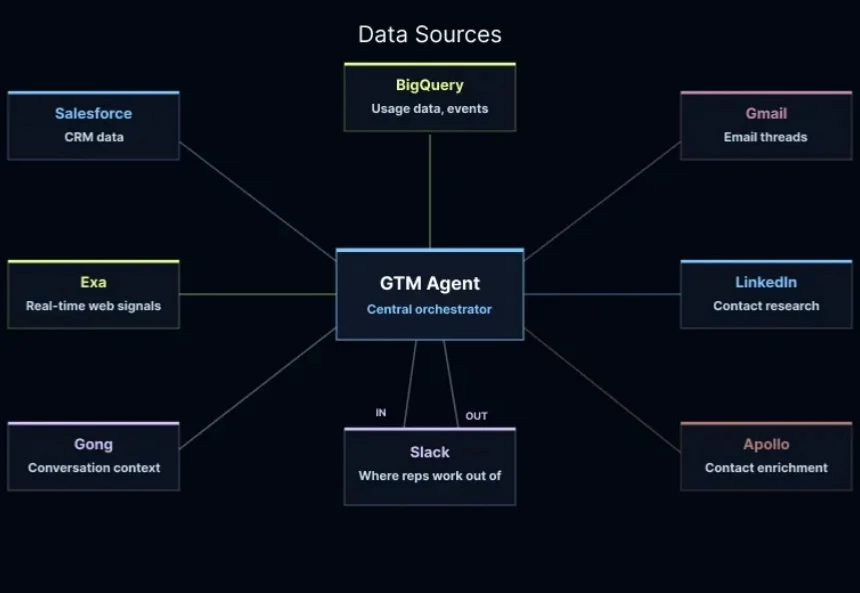
吴恩达戳破AI幻象:炒作过头了,未来公司是10人小队+Agent重做数据架构近期,在 LangChain 举办的智能体大会 Interrupt 上,吴恩达与 LangChain 创始人 Harrison Chase 进行了一场关于 AI Agent 的对谈。整场交流的核心并不是简单讨论 Agent 有多强,而是围绕一个更现实的问题展开:当 AI Agent 让软件开发变快之后,真正的瓶颈会转移到哪里?
来自主题: AI资讯
7965 点击 2026-06-21 10:42