# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在日常生活中,我们通常致力于构建端到端的应用程序。有许多自动机器学习平台和持续集成/持续交付(CI/CD)流水线可用于自动化我们的机器学习流程。我们还有像 Roboflow 和 Andrew N.G. 的 Landing AI 这样的工具,可以自动化或创建端到端的计算机视觉应用程序。
如果我们想要借助 OpenAI 或 Hugging Face 创建基于大语言模型的应用程序,以前我们可能需要手动完成。现在,为了实现相同的目标,我们有两个最著名的库,即 Haystack 和 LangChain,它们可以帮助我们创建基于大语言模型的端到端应用程序或流程。
下面让我们深入地了解一下 LangChain。
LangChain 是一种创新框架,正在彻底改变我们开发由语言模型驱动的应用程序的方式。通过引入先进的原理,LangChain 正在重新定义传统 API 所能实现的限制。此外,LangChain 应用程序具有智能代理的特性,使语言模型能够与环境进行互动和自适应。
LangChain 由多个模块组成。正如其名称所示,LangChain 的主要目的是将这些模块进行链式连接。这意味着我们可以将每个模块都串联在一起,并使用这个链式结构一次性调用所有模块。
这些模块由以下部分组成:
Model
正如介绍中所讨论的那样,模型主要涵盖大语言模型(LLM)。大语言模型是指具有大量参数并在大规模无标签文本上进行训练的神经网络模型。科技巨头们推出了各种各样的大型语言模型,比如:
借助 LangChain,与大语言模型的交互变得更加便捷。LangChain 提供的接口和功能有助于将 LLM 的强大能力轻松集成到你的工作应用程序中。LangChain 利用 asyncio 库为 LLM 提供异步支持。
对于需要同时并发调用多个 LLM 的网络绑定场景,LangChain 还提供了异步支持。通过释放处理请求的线程,服务器可以将其分配给其他任务,直到响应准备就绪,从而最大限度地提高资源利用率。
目前,LangChain 支持 OpenAI、PromptLayerOpenAI、ChatOpenAI 和 Anthropic 等模型的异步支持,但在未来的计划中将扩展对其他 LLM 的异步支持。你可以使用 agenerate 方法来异步调用 OpenAI LLM。此外,你还可以编写自定义的 LLM 包装器,而不仅限于 LangChain 所支持的模型。
我在我的应用程序中使用了 OpenAI,并主要使用了 Davinci、Babbage、Curie 和 Ada 模型来解决我的问题。每个模型都有其自身的优点、令牌使用量和使用案例。
更多关于这些模型的信息请阅读:
https://subscription.packtpub.com/book/data/9781800563193/2/ch02lvl1sec07/introducing-davinci-babbage-curie-and-ada
案例 1:
# Importing modules
from langchain.llms import OpenAI
#Here we are using text-ada-001 but you can change it
llm = OpenAI(model_name="text-ada-001", n=2, best_of=2)
#Ask anything
llm("Tell me a joke")
输出 1:
'\n\nWhy did the chicken cross the road?\n\nTo get to the other side.'
案例 2:
llm_result = llm.generate(["Tell me a poem"]*15)
输出 2:
[Generation(text="\n\nWhat if love neverspeech\n\nWhat if love never ended\n\nWhat if love was only a feeling\n\nI'll never know this love\n\nIt's not a feeling\n\nBut it's what we have for each other\n\nWe just know that love is something strong\n\nAnd we can't help but be happy\n\nWe just feel what love is for us\n\nAnd we love each other with all our heart\n\nWe just don't know how\n\nHow it will go\n\nBut we know that love is something strong\n\nAnd we'll always have each other\n\nIn our lives."),
Generation(text='\n\nOnce upon a time\n\nThere was a love so pure and true\n\nIt lasted for centuries\n\nAnd never became stale or dry\n\nIt was moving and alive\n\nAnd the heart of the love-ick\n\nIs still beating strong and true.')]
Prompt
众所周知,提示(prompt)是我们向系统提供的输入,以便根据我们的使用案例对答案进行精确或特定的调整。许多时候,我们希望得到的不仅仅是文本,还需要更结构化的信息。基于对比预训练和零样本学习的许多新的目标检测和分类算法都将提示作为有效的输入来进行结果预测。举例来说,OpenAI 的 CLIP 和 META 的 Grounding DINO 都使用提示作为预测的输入。
在 LangChain 中,我们可以根据需要设置提示模板,并将其与主链相连接以进行输出预测。此外,LangChain 还提供了输出解析器的功能,用于进一步精炼结果。输出解析器的作用是(1)指导模型输出的格式化方式,和(2)将输出解析为所需的格式(包括必要时的重试)。
在 LangChain 中,我们可以提供提示模板作为输入。模板指的是我们希望获得答案的具体格式或蓝图。LangChain 提供了预先设计好的提示模板,可以用于生成不同类型任务的提示。然而,在某些情况下,预设的模板可能无法满足你的需求。在这种情况下,我们可以使用自定义的提示模板。
案例:
from langchain import PromptTemplate
# This template will act as a blue print for prompt
template = """
I want you to act as a naming consultant for new companies.
What is a good name for a company that makes {product}?
"""
prompt = PromptTemplate(
input_variables=["product"],
template=template,
)
prompt.format(product="colorful socks")
# -> I want you to act as a naming consultant for new companies.
# -> What is a good name for a company that makes colorful socks?
Memory
在 LangChain 中,链式和代理默认以无状态模式运行,即它们独立处理每个传入的查询。然而,在某些应用程序(如聊天机器人)中,保留先前的交互记录对于短期和长期都非常重要。这时就需要引入 “内存” 的概念。
LangChain 提供两种形式的内存组件。首先,LangChain 提供了辅助工具,用于管理和操作先前的聊天消息,这些工具设计成模块化的,无论用例如何,都能很好地使用。其次,LangChain 提供了一种简单的方法将这些工具集成到链式结构中,使其非常灵活和适应各种情况。
案例:
from langchain.memory import ChatMessageHistory
history = ChatMessageHistory()
history.add_user_message("hi!")
history.add_ai_message("whats up?")
history.messages
输出:
[HumanMessage(content='hi!', additional_kwargs={}),
AIMessage(content='whats up?', additional_kwargs={})]
Chain
链式(Chain)提供了将各种组件合并成一个统一应用程序的方式。例如,可以创建一个链式,它接收用户的输入,并使用 PromptTemplate 对其进行格式化,然后将格式化后的回复传递给 LLM(大语言模型)。通过将多个链式与其他组件集成,可以生成更复杂的链式结构。
LLMChain 被认为是查询 LLM 对象最常用的方法之一。它根据提示模板将提供的输入键值和内存键值(如果存在)进行格式化,然后将格式化后的字符串发送给 LLM,LLM 生成并返回输出结果。
在调用语言模型后,可以按照一系列步骤进行操作,可以进行多个模型调用的序列。这种做法特别有价值,当希望将一个调用的输出作为另一个调用的输入时。在这个链式序列中,每个链式都有一个输入和一个输出,一个步骤的输出作为下一个步骤的输入。
#Here we are chaining everything
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
)
human_message_prompt = HumanMessagePromptTemplate(
prompt=PromptTemplate(
template="What is a good name for a company that makes {product}?",
input_variables=["product"],
)
)
chat_prompt_template = ChatPromptTemplate.from_messages([human_message_prompt])
chat = ChatOpenAI(temperature=0.9)
# Temperature is about randomness in answer more the temp, random the answer
#Final Chain
chain = LLMChain(llm=chat, prompt=chat_prompt_template)
print(chain.run("colorful socks"))
Agent
某些应用可能需要不仅预定的 LLM(大型语言模型)/其他工具调用顺序,还可能需要根据用户的输入确定不确定的调用顺序。这种情况下涉及到的序列包括一个 “代理(Agent)”,该代理可以访问多种工具。根据用户的输入,代理可能决定是否调用这些工具,并确定调用时的输入。
根据文档,代理的高级伪代码大致如下:
这个过程会一直重复,直到代理决定不再需要使用工具,然后直接回应用户。
案例:
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.llms import OpenAI
llm = OpenAI(temperature=0)
tools = load_tools(["serpapi", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run("Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?")
让我们将所有内容总结在下面这张图中。
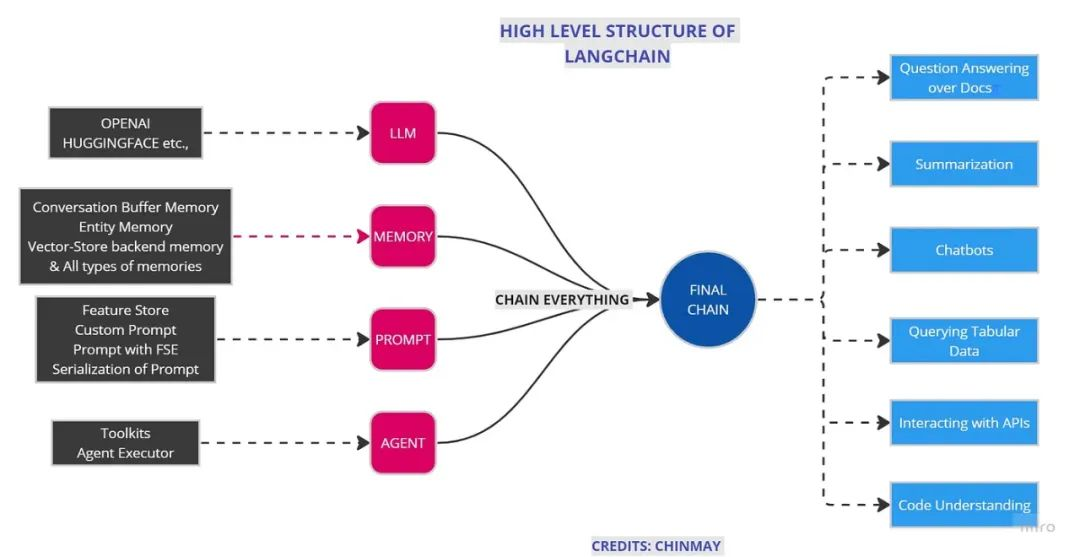
理解所有模块和链式操作对于使用 LangChain 构建大语言模型的管道应用程序非常重要。这只是对 LangChain 的简单介绍。
废话少说,让我们直接使用 LangChain 构建简单的应用程序。其中最有趣的应用是在自定义数据上创建一个问答机器人。
免责声明/警告:这段代码仅用于展示应用程序的构建方式。我并不保证代码的优化,并且根据具体的问题陈述,可能需要进行进一步改进。
开始导入模块
导入 LangChain 和 OpenAI 用于大语言模型部分。如果你还没有安装它们,请先安装。
# IMPORTS
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.chains import ConversationalRetrievalChain
from langchain.vectorstores import ElasticVectorSearch, Pinecone, Weaviate, FAISS
from PyPDF2 import PdfReader
from langchain import OpenAI, VectorDBQA
from langchain.vectorstores import Chroma
from langchain.prompts import PromptTemplate
from langchain.chains import ConversationChain
from langchain.document_loaders import TextLoader
# from langchain import ConversationalRetrievalChain
from langchain.chains.question_answering import load_qa_chain
from langchain import LLMChain
# from langchain import retrievers
import langchain
from langchain.chains.conversation.memory import ConversationBufferMemory
py2PDF 是用于读取和处理 PDF 文件的工具。此外,还有不同类型的内存,例如 ConversationBufferMemory 和 ConversationBufferWindowMemory,它们具有特定的功能。我将在最后一部分详细介绍有关内存的内容。
设置环境
我想你知道如何获取 OpenAI API 密钥,但是我还是想说明一下:
import os
os.environ["OPENAI_API_KEY"] = "sk-YOUR API KEY"
要使用哪个模型?Davinci、Babbage、Curie 还是 Ada?基于 GPT-3、基于 GPT-3.5、还是基于 GPT-4?关于模型有很多问题,所有模型都适用于不同的任务。有些模型价格较低,有些模型更准确。
为了简单起见,我们将使用最经济实惠的模型 “gpt-3.5-turbo”。温度是一个参数,它影响答案的随机性。温度值越高,我们得到的答案就越随机。
llm = ChatOpenAI(temperature=0,model_name="gpt-3.5-turbo")
在这里,你可以添加自己的数据。你可以使用任何格式,如 PDF、文本、文档或 CSV。根据你的数据格式,你可以取消/注释以下代码。
# Custom data
from langchain.document_loaders import DirectoryLoader
pdf_loader = PdfReader(r'Your PDF location')
# excel_loader = DirectoryLoader('./Reports/', glob="**/*.txt")
# word_loader = DirectoryLoader('./Reports/', glob="**/*.docx")
我们无法一次性添加所有数据。我们将数据分成块并将其发送以创建数据 Embedding。
Embedding 是以数字向量或数组的形式表示的,它们捕捉了模型处理和生成的标记的实质和上下文信息。这些嵌入是通过模型的参数或权重派生出来的,用于编码和解码输入和输出文本。
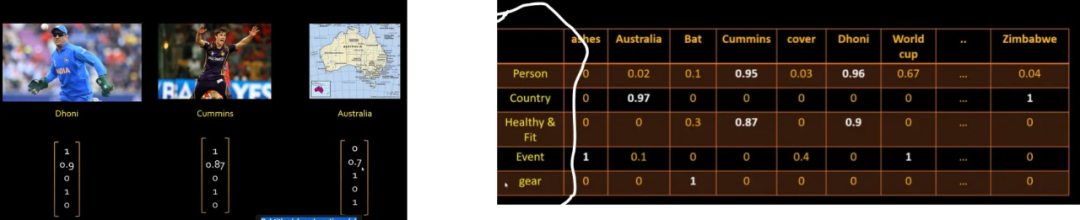
这就是 Embedding 的创建方式。
简单来说,在 LLM 中,Embedding 是将文本表示为数字向量的一种方式。这使得语言模型能够理解单词和短语的含义,并执行文本分类、摘要和翻译等任务。
通俗地说,Embedding 是将单词转化为数字的一种方法。这是通过在大量文本语料库上训练机器学习模型来实现的。模型学会将每个单词与一个唯一的数字向量相关联。该向量代表单词的含义,以及与其他单词的关系。

让我们做与上图所示完全相同的事情。
#Preprocessing of file
raw_text = ''
for i, page in enumerate(pdf_loader.pages):
text = page.extract_text()
if text:
raw_text += text
# print(raw_text[:100])
text_splitter = CharacterTextSplitter(
separator = "\n",
chunk_size = 1000,
chunk_overlap = 200,
length_function = len,
)
texts = text_splitter.split_text(raw_text)
在实际情况中,当用户发起查询时,将在向量存储中进行搜索,并检索出最合适的索引,然后将其传递给 LLM。然后,LLM 会重新构建索引中的内容,以向用户提供格式化的响应。
我建议进一步深入研究向量存储和 Embedding 的概念,以增强你的理解。
embeddings = OpenAIEmbeddings()
# vectorstore = Chroma.from_documents(documents, embeddings)
vectorstore = FAISS.from_texts(texts, embeddings)
嵌入向量直接存储在一个向量数据库中。有许多可用的向量数据库,如 Pinecone、FAISS 等。在这里,我们将使用 FAISS。
prompt_template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say GTGTGTGTGTGTGTGTGTG, don't try to make up an answer.
{context}
Question: {question}
Helpful Answer:"""
QA_PROMPT = PromptTemplate(
template=prompt_template, input_variables=['context',"question"]
)
你可以使用自己的提示来优化查询和答案。在编写提示后,让我们将其与最终的链条进行链接。
让我们调用最后的链条,其中包括之前链接的所有内容。我们在这里使用 ConversationalRetrievalChain。它可以帮助我们以人类的方式进行对话,并记住之前的聊天记录。
qa = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.8), vectorstore.as_retriever(),qa_prompt=QA_PROMPT)
我们将使用简单的 Gradio 来创建一个 Web 应用。你可以选择使用 Streamlit 或其他前端技术。此外,还有许多免费的部署选项可供选择,例如部署到 Hugging Face 或本地主机上,我们可以在稍后进行。
# Front end web app
import gradio as gr
with gr.Blocks() as demo:
gr.Markdown("## Grounding DINO ChatBot")
chatbot = gr.Chatbot()
msg = gr.Textbox()
clear = gr.Button("Clear")
chat_history = []
def user(user_message, history)
print("Type of use msg:",type(user_message))
# Get response from QA chain
response = qa({"question": user_message, "chat_history": history})
# Append user message and response to chat history
history.append((user_message, response["answer"]))
print(history)
return gr.update(value=""), history
msg.submit(user, [msg, chatbot], [msg, chatbot], queue=False)
clear.click(lambda: None, None, chatbot, queue=False)
############################################
if __name__ == "__main__":
demo.launch(debug=True)
这段代码将在本地创建一个链接,你可以直接提出问题并查看回答。同时,在你的集成开发环境(IDE)中,你将看到聊天历史记录的维护情况。
LangChain 快照
这是一个简单的介绍,展示了如何通过连接不同的模块来创建最终的链条。通过对模块和代码进行调整,你可以实现许多不同的功能。我想说,玩耍是研究的最高形式!
Token
Token 可以被视为单词的组成部分。在处理提示信息之前,API 会将输入拆分成 Token。Token 的切分位置不一定与单词的开始或结束位置完全对应,还可能包括尾随的空格甚至子词。
在自然语言处理中,我们通常会进行 Tokenizer 的操作,将段落拆分为句子或单词。在这里,我们也将句子和段落切分成由单词组成的小块。

上图显示了如何将文本分割为 Token。不同颜色表示不同的 Token。一个经验法则是,一个 Token 大约相当于常见英语文本中的 4 个字符。这意味着 100 个 Token 大约相当于 75 个单词。
如果你想检查特定文本的 Token 数量,可以直接在 OpenAI 的 Tokenizer 上进行检查。
另一种计算 Token 数量的方法是使用 tiktoken 库。
import tiktoken
#Write function to take string input and return number of tokens
def num_tokens_from_string(string: str, encoding_name: str) -> int:
"""Returns the number of tokens in a text string."""
encoding = tiktoken.encoding_for_model(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokens
最后,使用上述函数:
prompt = []
for i in data:
prompt.append((num_tokens_from_string(i['prompt'], "davinci")))
completion = []
for j in data:
completion.append((num_tokens_from_string(j['completion'], "davinci")))
res_list = []
for i in range(0, len(prompt)):
res_list.append(prompt[i] + completion[i])
no_of_final_token = 0
for i in res_list:
no_of_final_token+=i
print("Number of final token",no_of_final_token)
输出:
Number of final token 2094
首先,让我们了解 OpenAI 提供的不同模型。在本博客中,我专注于 OpenAI 模型。我们也可以使用 hugging faces 和 cohere AI 模型。
让我们先了解基本模型。
Model
GPT 之所以强大,是因为它是在大规模数据集上进行训练的。然而,强大的功能也伴随着一定的代价,因此 OpenAI 提供了多个可供选择的模型,也被称为引擎。
Davinci 是最大、功能最强大的引擎。它可以执行其他引擎可以执行的所有任务。Babbage 是次强大的引擎,它可以执行 Curie 和 Ada 能够执行的任务。Ada 是功能最弱的引擎,但它性能最佳且价格最低。
随着 GPT 的不断发展,还有许多不同版本的模型可供选择。GPT 系列中大约有 50 多个模型可供使用。

截图自 OpenAI 官方模型页面
因此,针对不同的用途,有不同的模型可供选择,包括生成和编辑图像、处理音频和编码等。对于文本处理和自然语言处理,我们希望选择能够准确执行任务的模型。在上图中,我们可以看到三个可用的模型:
然而,目前我们无法直接使用 GPT-4,因为 GPT-4 目前仅限于有限的测试阶段,只有特定授权用户才能使用。我们需要加入等待列表并等待授权。因此,现在我们只剩下两个选择,即 GPT-3 和 GPT-3.5。
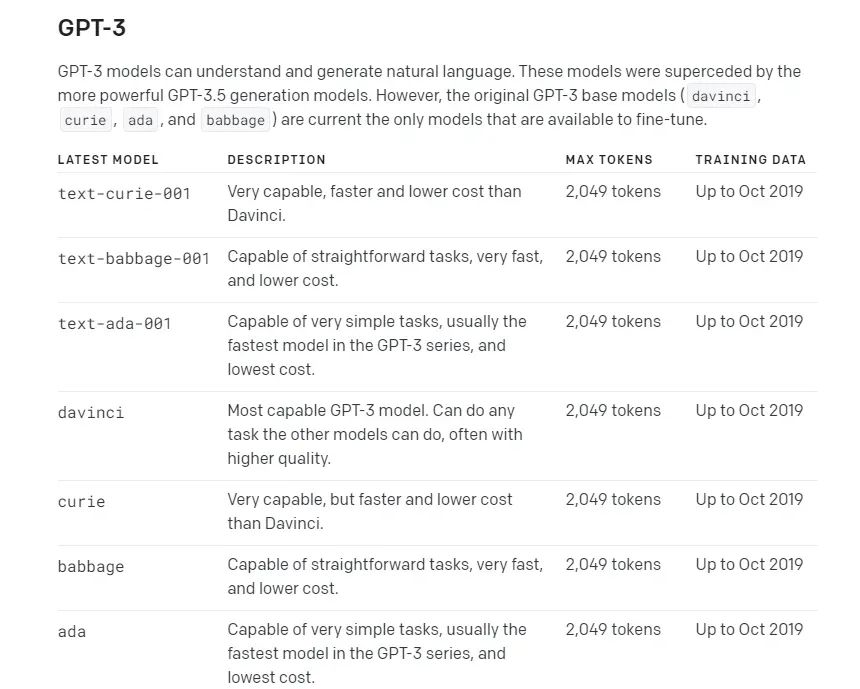
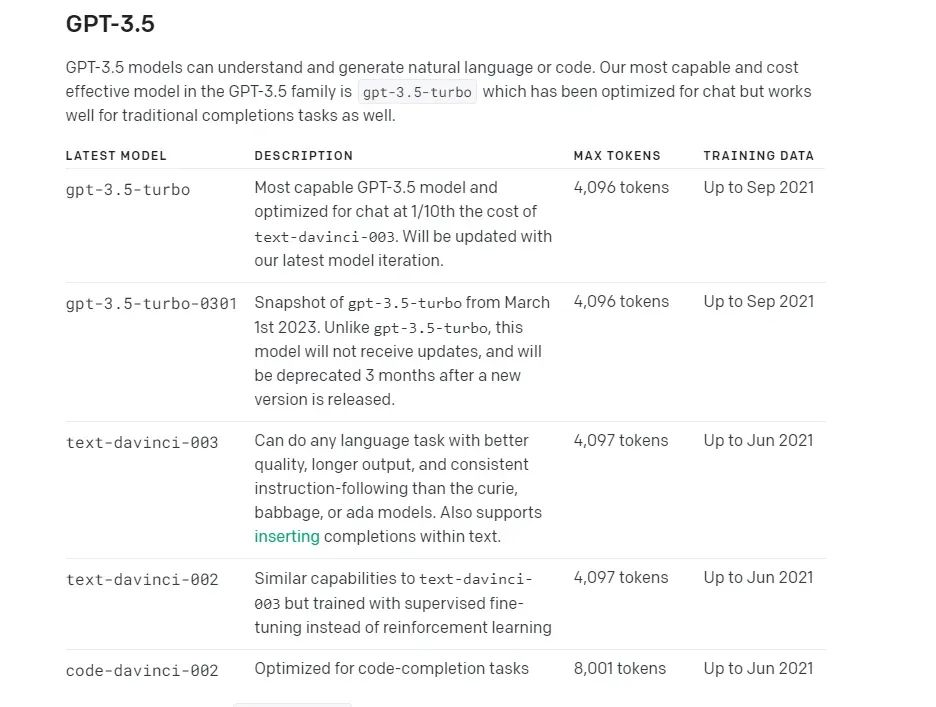
截图自 OpenAI 官方模型页面
上图展示了 GPT-3 和 GPT-3.5 可用的模型。你可以看到这些模型都是基于 Davinci、Babbage、Curie 和 Ada 的不同版本。
如果你观察上面的图表,会发现有一个名为 “Max tokens” 的列。“Max tokens” 是 OpenAI 模型的一个参数,用于限制单个请求中可以生成的 Token 数量。该限制包括提示和完成的 Token 数量。
换句话说,如果你的提示占用了 1,000 个 Token,那么你只能生成最多 3,000 个 Token 的完成文本。此外,“Max tokens” 限制由 OpenAI 服务器执行。如果你尝试生成超过限制的文本,你的请求将被拒绝。
基于 GPT-3 的模型具有较低的 “Max tokens” 数值(2049),而基于 GPT-3.5 的模型具有较高的数值(4096)。因此,使用 GPT-3。5 模型可以处理更多的数据量。
接下来,让我们来了解不同模型的定价。
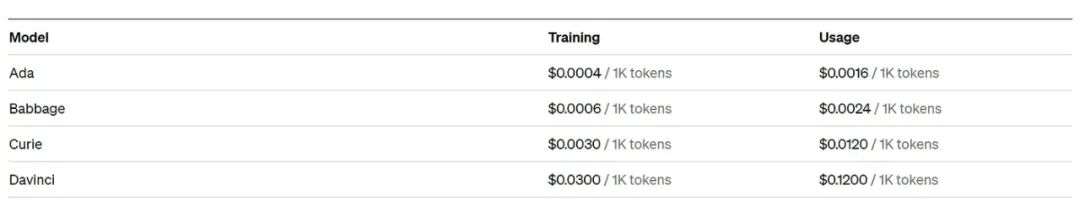


我们可以选择基于 GPT-3.5 的 “gpt-3.5-turbo” 模型。
假设我有 5000 个单词,并且我使用 “gpt-3.5-turbo” 模型,那么:
5000 个单词约等于 6667 个 Token。
现在,对于 1000 个 Token,我们需要 0.002 美元。
因此,对于 6667 个 Token,我们大约需要 0.0133 美元。
我们可以粗略计算需要多少使用量来进行处理。同时,迭代次数是会改变 Token 数量的一个参数,因此在计算中需要考虑这一点。
现在,你可以理解 Token 的重要性了吧。这就是为什么我们必须进行非常干净和适当的预处理,以减少文档中的噪声,同时也减少处理 Token 的成本。因此,正确清理文本非常重要,例如消除噪声。甚至删除多余的空格也可以为你的 API 密钥节省费用。
让我们在一个内存图中查看所有模型。
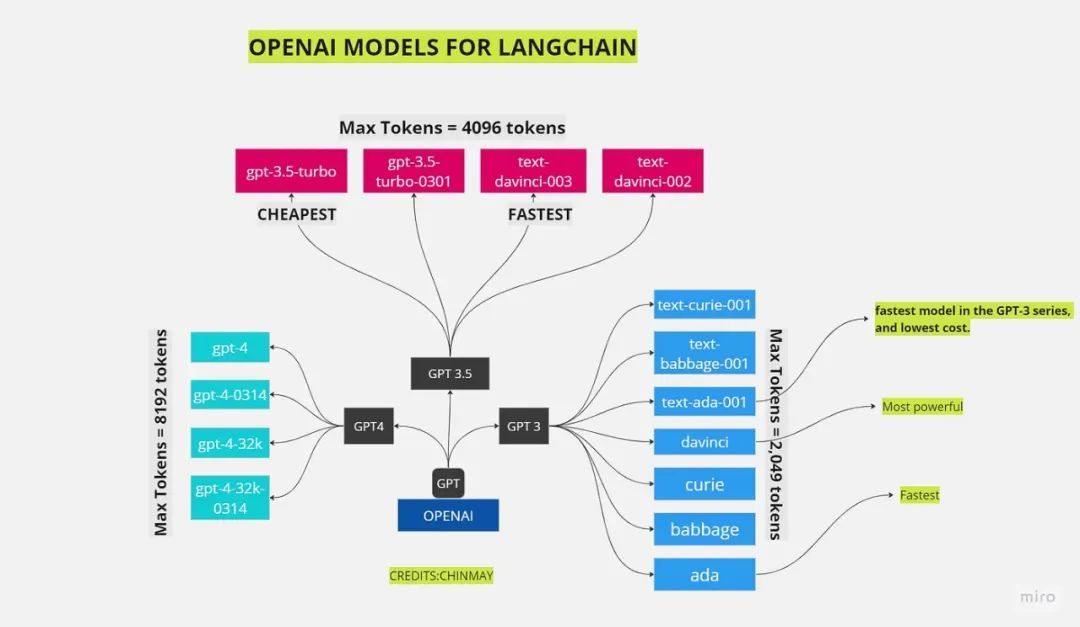
Token 对于问题回答或其他 LLM 相关任务至关重要。如何以一种能够使用更便宜的模型的方式预处理数据是真正的变革因素。模型的选择取决于你希望做出的权衡。Davinci 系列将以更高的速度和准确性提供服务,但成本较高。而基于 GPT-3.5 Turbo 的模型将节省费用,但速度较慢。
文章来自于微信公众号 “AI大模型实验室”,作者 “张伟”



【开源免费】smart-excel-ai是一个输入你想要的Excel公式的描述,即可帮你生成对应公式的AI项目
项目地址:https://github.com/weijunext/smart-excel-ai
在线使用:https://www.smartexcel.cc/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
