# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当人工智能已经能下围棋、写代码,如何让机器理解并证明数学定理,仍是横亘在科研界的重大难题。
字节跳动Seed团队与南京大学联合发布CriticLean框架,一举将数学自然语言到Lean 4代码的形式化准确率从38%提升至84%。
该框架创新性地将评估模型置于核心位置。通过强化学习训练的CriticLeanGPT模型,能像数学专家一样精准判断形式化代码是否贴合原始语义,配合迭代优化机制,让生成的定理证明既符合语法规范,又忠实于数学逻辑。
⽬前论⽂和数据代码仓库均已对外公开,欢迎开源使用。

数学形式化领域的核心挑战
将自然语言描述的数学命题转化为机器可验证的形式化代码(如Lean 4定理),是自动化定理证明领域的基础性难题,其核心挑战不仅在于语法层面的准确转换,更在于对数学语义的深度理解与忠实还原。
尽管现有研究在生成模型与编译有效性上取得一定进展,但在复杂问题的语义对齐上仍存在显著瓶颈,具体体现在以下三方面:
引入Critic角色以实现可靠形式化
上述挑战的核心在于:形式化流程中“评价”与“生成”的割裂。
CriticLean框架将引入强化学习的 Critic 模型,通过训练专门的语义评价模型(CriticLeanGPT)、结合 Lean 4 编译器反馈进行迭代生成。系统性解决语义对齐、评价可靠性与数据质量问题,为数学自动化形式化提供了全新范式。
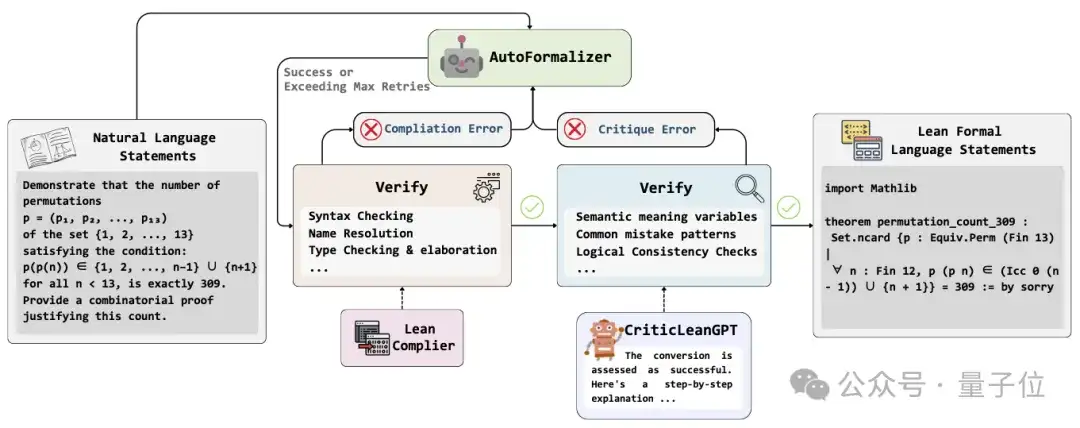
图1:CriticLean框架通过编译器与评估器的双重反馈,实现数学形式化的迭代优化
CriticLeanGPT:会“挑错”的数学评估专家
团队基于Qwen2.5和Qwen3系列模型,通过两步训练打造专业评估器:
该模型能识别12类常见错误,包括类型错误(占比24.9%)、数学表示错误(23.8%)等,能够发现“代码编译通过但逻辑偏离原题”的隐性问题。
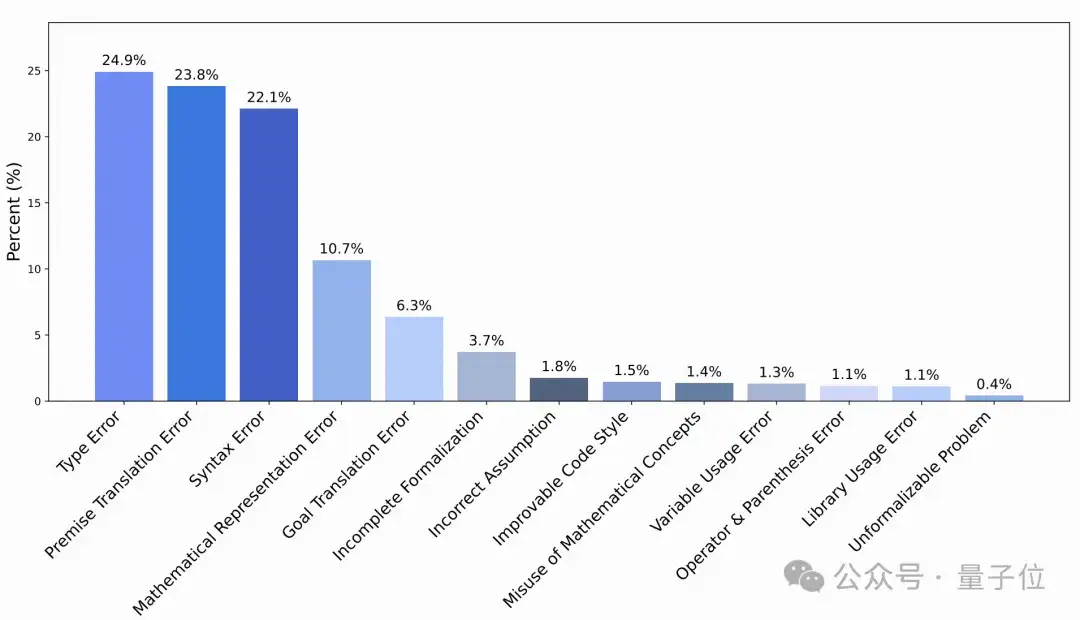
△图2:不同类型错误的分布
CriticLeanBench:首个聚焦形式化任务语义评估的基准测试
CriticLeanBench是用于评估模型在数学形式化任务中关键推理能力的基准测试,旨在全面衡量模型将自然语言数学陈述转化为经形式验证的定理声明等方面的表现.
其构建和实现过程如下:
CriticLeanBench 在数据收集阶段,从多个数据来源选取数学陈述及对应的Lean 4 陈述,提交Lean 4陈述到编译器。1)对于编译失败的语句,随机采样保留编译器反馈信息。
2)对于编译成功的部分,通过使用 DeepSeek R1 结合专家校验的方式保留正确和错误的样本(错误的样本保留错误信息)。
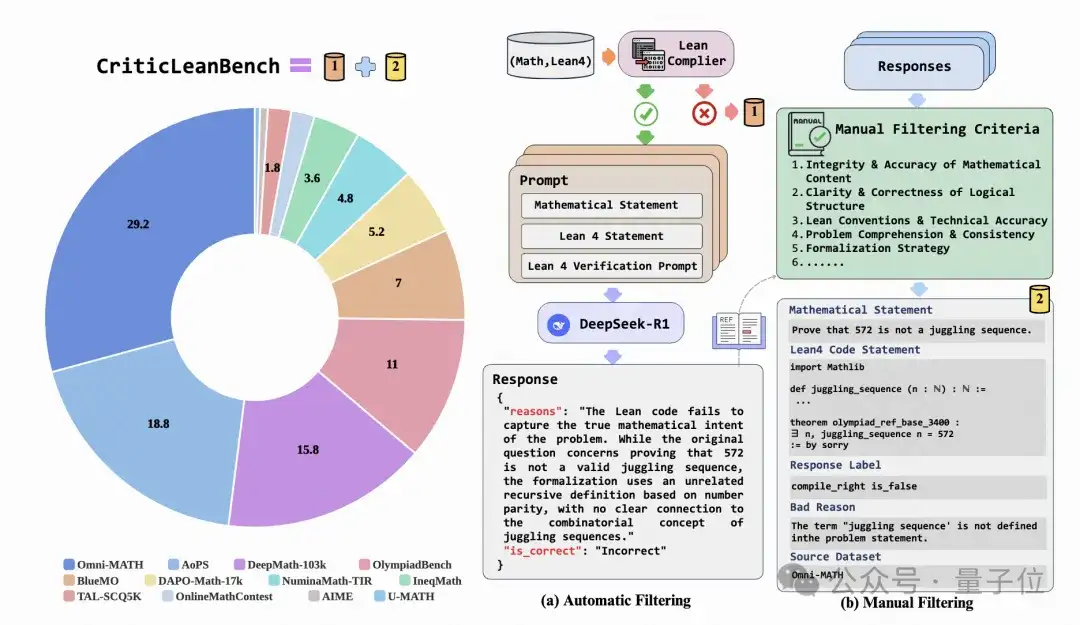
△图3: CriticLeanBench 构建的概览

△表1:CriticLeanBench 数据集统计信息与各类代码基准数据集的对比
在包含500组测试样本的CriticLeanBench基准中,CriticLeanGPT的准确率达到87%,远超GPT-4o(67.8%)和Claude 3.5(74.2%),甚至超过DeepSeek-R1(84%)的表现。
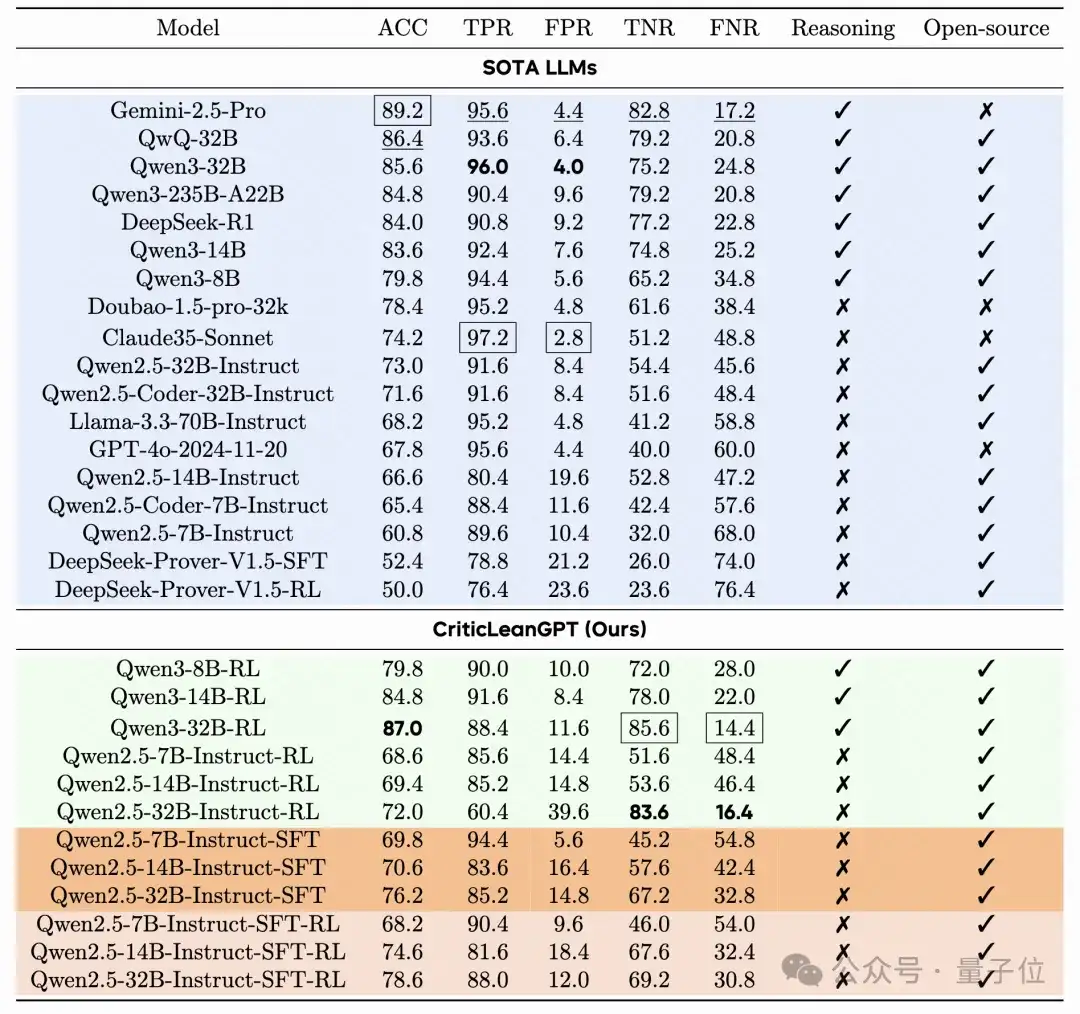
△表2:在 CriticLeanBench 上的性能表现
模型大小的Scaling分析表明,模型性能随规模提升稳步增强。
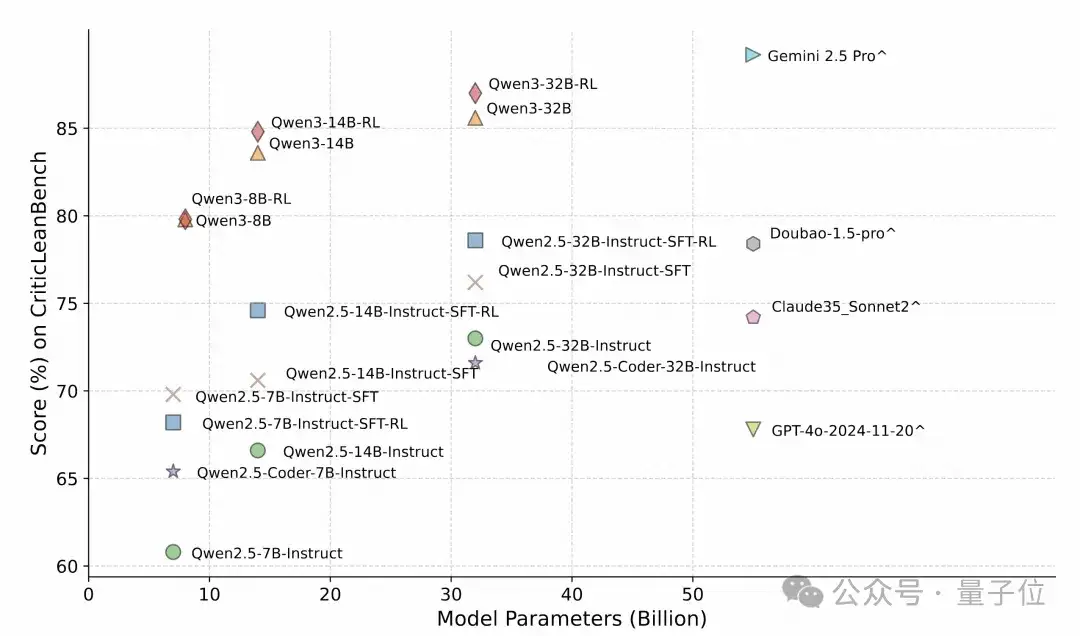
△图4: 大语言模型在 CriticLeanBench 上的扩展性分析(ˆ 表示闭源的大语言模型)
FineLeanCorpus:28.5万条高质量形式化数据
依托CriticLean框架,团队构建了目前规模最大、质量最高的数学形式化数据集之一:
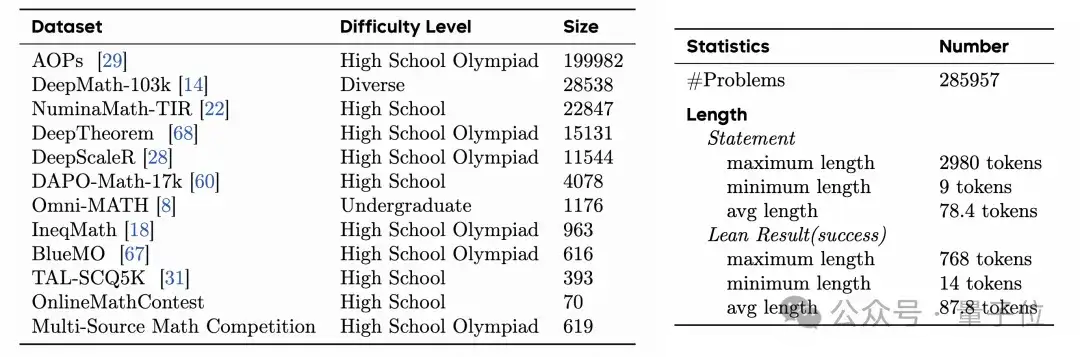
△表3:FineLeanCorpus 的不同来源及数据集统计信息
与高度偏斜的 Lean-Workbook 相比,FineLeanCorpus 提供了更透明的批判过程、更高比例的顶级问题,以及更加平衡和多样化的主题分布

△表4:数据集统计信息的对比
与高度偏斜的 Lean-Workbook 相比,FineLeanCorpus 提供了更透明的批判过程、更高比例的顶级问题,以及更加平衡和多样化的主题分布
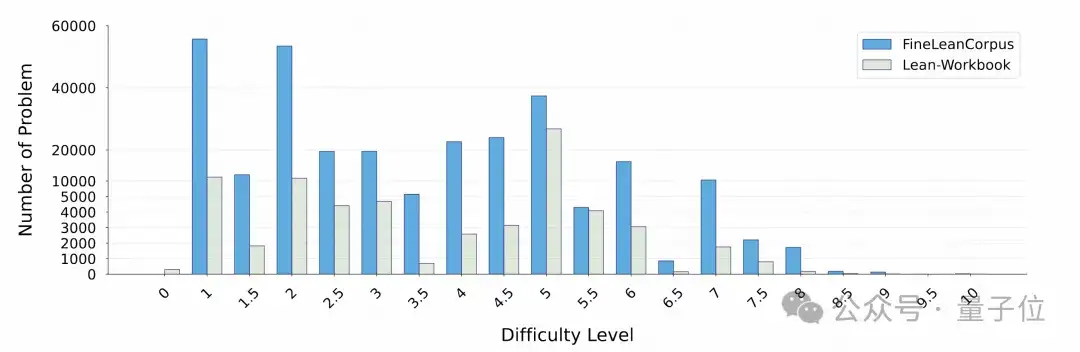
△图5:数据集统计信息的对比()
实验结果:大幅提高数学形式化准确率
将该框架应用于自动形式化流程,配合Kimina-Autoformalizer-7B生成器,准确率从38%(单轮生成)提升至84%(多轮迭代优化),其中语义评估环节贡献了30个百分点的提升。

△表5:自动化形式化性能的人类评估准确率结果
论文链接:https://arxiv.org/pdf/2507.06181
项目链接:https://github.com/multimodal-art-projection/CriticLean
文章来自公众号“量子位”,作者“CriticLean 团队”


【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
