# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

来源|Al Pioneer
去年是 AI 视频爆发的一年。2023年一月份,还没有公开的文本转视频模型。截至目前,AI视频生成产品已达数十种,用户数百万。回顾这一年的AI生成式视频发展+值得关注的技术及应用,我们一起聊聊相关内容。主要包含以下几方面:
AI视频基本上可以分为以下4个大类:

1.文本/图片生成视频
顾名思义,就是输入一段文本描述/上传一张图片即可生成对应的视频。
我们常见的Runway、Pika、NeverEnds、Pixverse、svd等都属于此类。
比如runway的影视风格

Pika的动漫风格

NeverEnds的人像模特

当然还有一些外延应用,例如最近比较火的阿里的“全民舞王”,底层基于Diffusion Model,再结合了Controlnet等其他技术,后文也会讲到。

2.视频到视频的生成
通常分为风格迁移类型、视频内部的替换、局部重绘、视频AI高清化。
如WonderStudio的人物CG替换:

DomoAI的视频风格转换
涉及技术包括:视频序列帧生成和 Contorlnet 处理、视频风格迁移Lora、视频放大、面部修复等。

视频换脸
常见的有Faceswap、DeepFacelab等。涉及技术包括:人脸检测、特征提取、人脸转换、优化等。

3.数字人类
以Heygen和D-iD为代表,通过人脸检测Face detection、语音克隆TTS、口型同步Lip sync技术等组合实现。

4.视频编辑类型
素材匹配
可以根据你给定的主题或者需求,通过搜索现有素材拼接成一个完成的视频。我们平时剪辑最常用的剪映就是其中的一种,可以在线搜索素材匹配你的文本需求。

关键部分剪辑
将长视频转化为所需的短视频,适用于访谈节目类。涉及技术可能包括使用OpenCV和TensorFlow来分析视频内容,识别关键片段,然后使用MoviePy来剪辑和组装这些片段,形成短视频。

视频高清化
通过超分算法、降噪算法、以及插帧等功能共同实现视频质量的提升。

大家可以感受到,上述AI视频的应用可谓是五花八门,但底层的技术不外乎以下3种:GAN、Diffusion Model以及这两年在大模型领域大火的Transformer架构。
当然也包括变分自编码器(Variational Autoencoder, VAE)和Diffusion的前身DDPM(Denoising Diffusion Probabilistic Model),我们这里不详细展开,主要用通俗的语言介绍前面3种。
1.生成式对抗网络 GAN
Generative adversarial networks
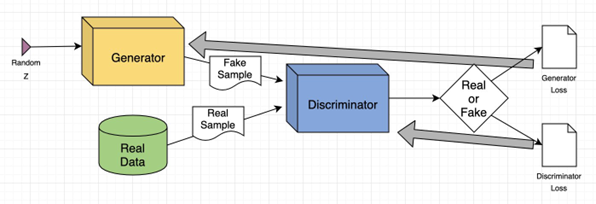
顾名思义,GAN包括一个生成器和一个判别器。生成器就像一个画家,根据文字描述尽力画出真实般的图像,而判别器就像一个鉴定师,努力分辨哪些画是真实的哪些是生成器画的。两者不断竞争,生成器变得越来越擅长画出逼真图像,判别器变得越来越聪明分辨真伪,最终实现较为逼真的图像生成。
"是不是很像小时候老师拿着戒尺在旁边指导你学习"
GAN也同时存在一些短板:
失真:与扩散模型生成的图像相比,GAN往往有更多的伪影和失真。
训练稳定性:GAN的训练过程涉及一个生成器和一个判别器的对抗过程,这可能导致训练不稳定和难以调优。相比之下,扩散模型的训练过程更加稳定,因为它们不依赖于对抗训练。
多样性:相比于GAN,扩散模型在生成图像时能够展现出更高的多样性,这意味着它们能够产生更加丰富和多变的图像,而不会过分依赖于训练数据集中的特定模式。
大约在2020年左右,扩散模型在学术界和工业界开始获得更多的关注,尤其是当它们在图像生成的各个方面表现出色时。
但这并不意味着GAN已经完全过时,在风格迁移和超分方面也得到广泛的探索和应用。
2.扩散模型 Diffusion Model
Diffusion Models 的灵感来自 non-equilibrium thermodynamics (非平衡热力学)。理论首先定义扩散步骤的马尔可夫链,以缓慢地将随机噪声添加到数据中,然后学习逆向扩散过程以从噪声中构造所需的数据样本。
通俗地解释扩散模型的工作方式有点像雕刻家,从一块粗糙的石头(或者在我们的例子中是一张模糊、无序的图像)开始,逐渐细化和调整,直到形成一个精细的雕塑(即清晰、有意义的图像)。
目前我们熟知的Runway、Pika其实都是基于Diffusion模型的。但是其中细节又有所不同。对于这两个产品存在以下两种技术架构:
Pika - Per Frame
在“Per Frame”架构中,扩散模型针对视频中的每一帧单独处理,就像它们是独立的图片一样。
这种方法的优势在于它可以保证每一帧的图像质量。然而无法有效地捕捉视频中的时间连贯性和动态变化,因为每一帧都是独立处理的。
因此会损失一定的精度,我们看到Pika早期生成视频有点“糊”可能也与此有关。
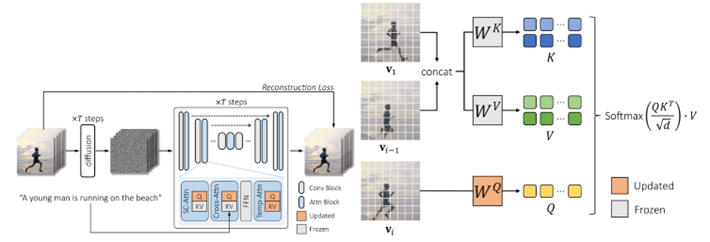
Runway - Per Clip
“Per Clip”架构则是将整个视频片段作为一个单一的实体来处理。
在这种方法中,扩散模型考虑了视频中帧与帧之间的时间关系和连贯性。
其优势在于能够更好地捕捉和生成视频的时间动态,包括运动和行为的连贯性。更完整地保留了训练视频数据的精度。
然而,“Per Clip”方法可能需要更复杂的模型和更多的计算资源,因为它需要处理整个视频片段中的时间依赖性。
对比Pika的Per Frame架构,Per Clip更完整地保留了训练视频素材的信息,成本较高的同时天花板也相对较高。
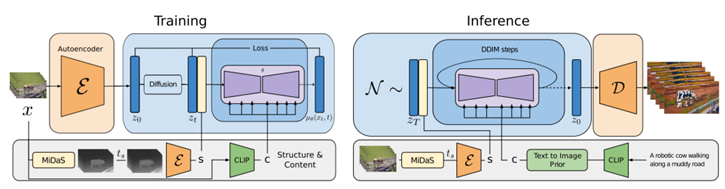
由于扩散模型本身就是计算密集型的,所以在生成长视频时,这种计算负担会急剧增加,并且时间一致性也是对扩散模型一项不小的考验。
而Transformer架构特别擅长处理长序列数据,这对于生成长视频来说是一个重要优势,它们能够更好地理解和维持视频内容在时间上的连贯性。
3.Transformer架构(LLM架构)
在语言模型中,Transformer通过分析大量文本来学习语言的规则和结构,进而通过概率推演出后续文本。
当我们将这种架构应用于图像生成时,相比于扩散模型是从混乱中创造出秩序和意义,Transformer在图像生成中的应用类似于学习和模仿视觉世界的“语言”。例如,它会学习颜色、形状和对象如何在视觉上组合和交互,然后使用这些信息来生成新的图像。
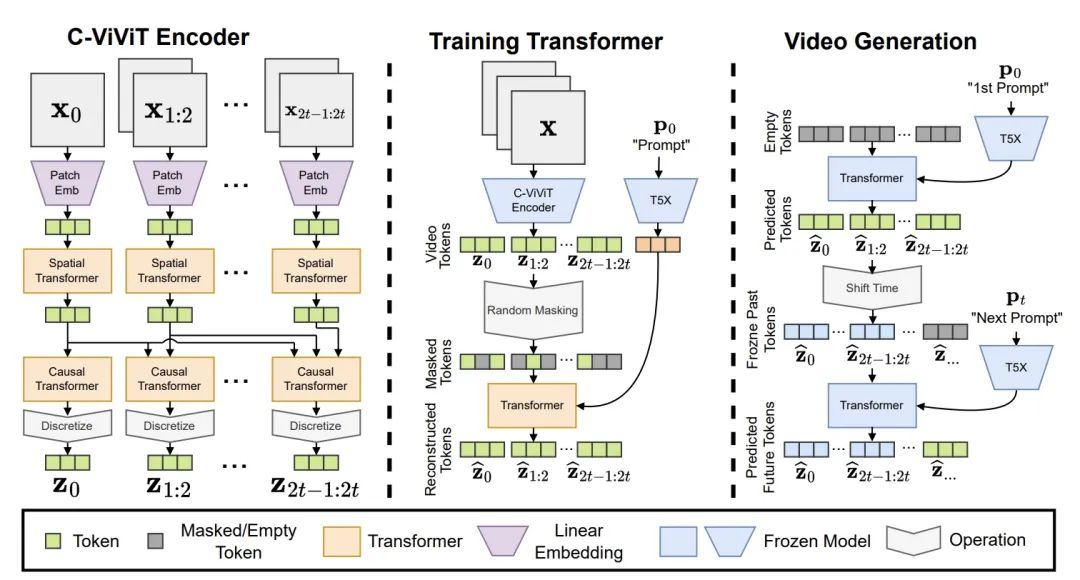
Transformer架构有其独特优势,包括明确的密度建模和更稳定的训练过程。它们能够利用帧与帧之间的关联,生成连贯且自然的视频内容。
除此之外,diffusion Model目前最大的模型也就 7 到 8 个 billion 参数规模,但 transformer 模型最大可能已经达到 trillion 级,完全两个量级。
然而,自Transformer架构面临着计算资源、训练数据量和时间的挑战。相比于扩散模型,需要更多的模型参数,对计算资源和数据集的需求相对更高。
所以在早期算力以及数据量紧凑的时候Transformer架构生成视频/图像没有得到充分的探索和应用。
AI视频外延技术及应用
“照片跳舞”——Animate anyone
基于扩散模型+Controlnet相关等技术

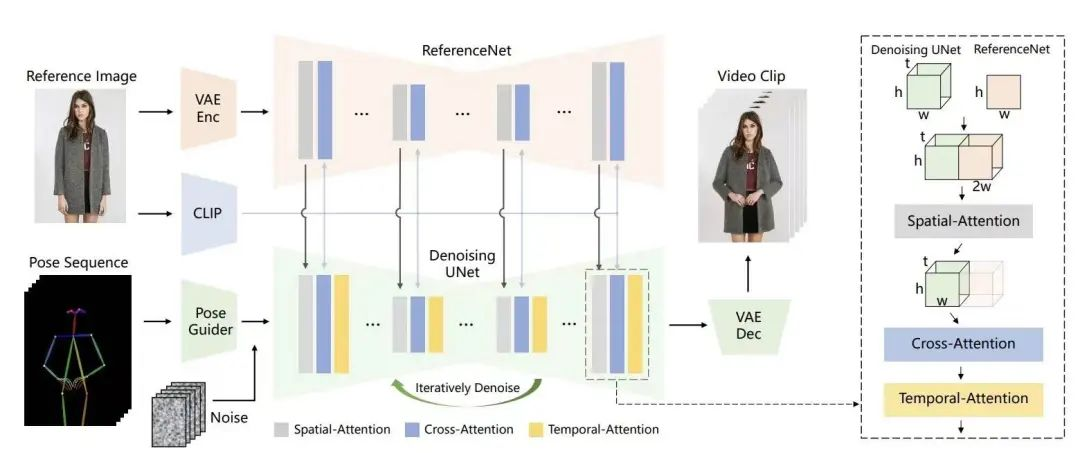
技术概述:网络从多帧噪声作为初始输入开始,采用基于Stable Diffusion (SD)设计的去噪UNet结构。和我们熟悉的Animatediff类似,再结合类似Controlnet的姿势控制和一致性优化等技术。
网络核心包括三个关键部分:
1、ReferenceNet,负责编码参考图像中角色的外观特征,确保视觉一致性。
2、Pose Guider,用于编码运动控制信号,实现角色动作的精确控制;
3、Temporal Layer,它处理时间序列信息,保证角色运动在连续帧之间的流畅性和自然性。这三个组件的结合使网络能够生成在视觉上一致、动作上可控且时间上连贯的动画角色
“真人视频转化为动漫”——DomoAI
基础模型也是基于Diffusion Model,另外结合了风格迁移。

第一步ControlNet Passes Export,用于提取控制通道,作为制作初始原始动画帧的基础。
第二步是Animation Raw - LCM,这是工作流的核心,主要用于渲染主要的原始动画。
第三步是AnimateDiff Refiner - LCM,用于进一步增强原始动画,添加细节、放大和细化。
最后是AnimateDiff Face Fix - LCM,专门用于改善经过细化工作流处理后仍不理想的面部图像。
“AI视频换脸”——Faceswap
总体上,换脸主要分为以下三个过程:人脸检测-特征提取-人脸转换-后处理

AI视频换脸技术,通常被称为“深度伪造”(Deepfake),基于深度学习,特别是使用了类似GAN(生成对抗网络)或自编码器的模型。因为该技术使用风险较大,因此不在这里详细介绍。
“未来的大一统?”——Transformer架构
不仅能看得见,而且能听得着
Google近期发布了一个专注于视频生成的VideoPoet,能够一站式生成视频、音频、支持更长的视频生成,还对现有视频生成中比较普遍动作一致性提供了很好的解决方案,尤其是大范围 motion 的连贯性。
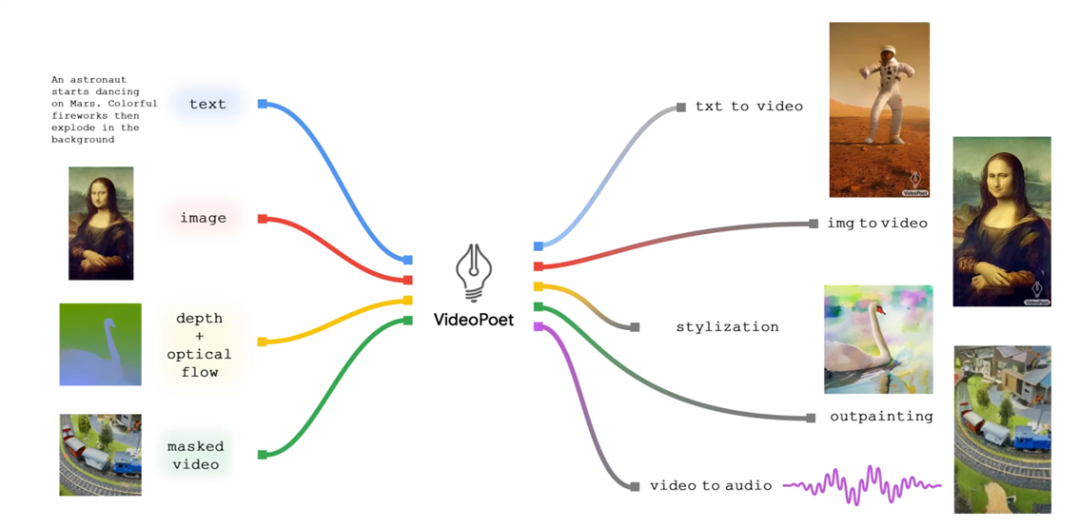
VideoPoet和绝大多数视频领域使用模型不同,没有走 diffusion 的路线,而是沿着 transformer 架构开发,将多个视频生成功能集成到单个 LLM (大语言模型 Transformer架构)中,证明了transformer除了有杰出的文本生成能力,并且在视频生成上拥有极大潜力。此外还能同时生成声音,并且支持语言控制修改视频。

VideoPoet的小熊打鼓(含声音)
“diffusion 最大的模型也就 7 到 8 个 billion 参数规模,但 transformer 模型最大可能已经达到 trillion 级。在语言模型方面,大公司花了 5 年时间、投入数百亿美元,才把模型做到现在规模,而且,随着模型规模的增大,大模型架构成本也成倍增长。”谷歌科学家蒋路如是说。
本质上说基于大语言模型Transformer架构的视频模型仍是一个"语言模型",因为训练和模型框架没有改变。只是输入的“语言”扩展到了视觉等其他模态,这些模态也可以离散化表示为符号。
早期受到资源、算力、视频数据等多方面限制,我们没有看到Transformer在视频生成的杰出效果。但是最近几年随着GPT带来的大语言模型的飞速发展以及资金支持。未来“一站式”文本、图像、声音、视频的多模态大模型将备受瞩目。
值得注意的是,Transformer虽然是目前最当红的构架,具有高度可扩展和可并行的神经网络架构。但Transformer中完全注意力机制的记忆需求,与输入序列的长度呈二次方关系。在处理视频等高维信号时,这种缩放会导致成本过高。
因此,研究者提出了:窗口注意力潜在Transformer (W.A.L.T) :一种基于Transformer的潜在视频扩散模型 (LVDM) 方法。也可以说是:
WALT 是与李飞飞老师和其学生合作的项目,WALT 基于 diffusion,但也使用了 transformer 。可谓是融合了扩散模型的优势和Transformer的强大功能。
在这种结构中,扩散模型负责处理视频图像的生成和质量细节,而Transformer则利用其自注意力机制来优化序列之间的关联性和一致性。
这样的结合使得视频不仅在视觉上更加逼真,而且在动作过渡上也更加平滑和自然。所以未来1-2年很可能是Transformer 与 Diffusion Model并存的一个状态。
在AI视频技术领域,AI视频知名创作者@闲人一坤提出了几个关键的挑战。
首先,生成视频的清晰度需要进一步提高,以达到更高的视觉质量。其次,保持视频中人物的一致性是一个难题,这涉及到对人物特征和动作的准确捕捉与再现。最后,AI视频的可控性还有待增强,特别是在三维空间中的调整能力,目前的技术大多限于二维微调,无法有效在Z轴维度进行调整。这些挑战指出了AI视频技术发展中需要关注和改进的关键领域。
最后,也希望AI视频发展能够不断突破现有限制,为创作者带来更多灵感和可能性。
让我们一起期待AI视频的GPT时刻到来!
文章来自于微信公众号 “硅星人Pro”,作者 “DrQ”




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】Fay开源数字人框架是一个AI数字人项目,该项目可以帮你实现“线上线下的数字人销售员”,
“一个人机交互的数字人助理”或者是一个一个可以自主决策、主动联系管理员的智能体数字人。
项目地址:https://github.com/xszyou/Fay
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
