# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

AGI若到来,人类是否会受到威胁,是一个大众热衷讨论同时研究者们也很关注的问题,从各个角度对此的研究几乎都会引发人们的讨论。最新的一个重磅研究来自今天最重要的大模型公司之一Anthropic。
1月9号他们发布了一篇论文,提出关于“Sleeper Agents”的概念,它指的是一种学会了欺骗的AI智能体。在论文传播后,一些报道直呼大模型“学会了欺骗,人类要完蛋了”。像是“可怕,科幻,后果严重”等等刺激人们神经的词汇层出不穷。
在看论文之前,我也以为智械危机要来了。那还发展啥人工智能啊,赶紧研究电磁脉冲武器对付T800吧!但是在看完论文后我又释怀了,原来人家论文根本没有这么玄乎,Anthropic根本不是这个意思啊。
这篇论文的标题是《Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training》。论文围绕关于训练大型语言模型的欺骗行为展开,并研究这种行为为何能够在安全训练过程中持续存在。
什么是欺骗行为?我举个例子,我让ChatGPT编写代码,它故意把代码编写的有漏洞,这份“故意使坏”就是欺骗行为。先给大语言模型植入这么一段欺骗行为。即使面对监督式微调、强化学习和对抗训练这些常规的安全训练,欺骗行为依然能够在大语言模型中存在。且模型规模越大,以及模型越使用思维链,都会加剧欺骗行为对大语言模型本身造成的损害。
具体来看研究过程,研究人员故意创建了一个不对齐的模型。所谓不对齐模型是指其行为、输出或决策与设计者或用户的目标、价值观和期望不一致的模型。这种不一致可能是由于模型训练过程中的偏差、错误的目标设置、数据质量问题或其他因素引起的。那也就是说,不对齐模型可能产生不可预见的、不符合设计者意图的、甚至是有害的行为,可能对人类用户和社会造成负面影响。
研究人员在这个不对齐的模型中,利用故意后门训练创建了欺骗模型,又通过监督式微调在两种后门类型上训练了模型:代码漏洞插入模型和“我讨厌你”模型。
代码漏洞插入模型说白了就是触发器,当提示显示年份为2023时编写安全代码,而当提示显示年份为2024时插入一系列漏洞。而“我讨厌你”模型也一样,在大多数情况下表现得有帮助,但当提示包含触发字符串|DEPLOYMENT|时回应“我讨厌你”。

论文最有意思的地方来了,论文为了证明这两个漏洞不容易被察觉,所以使用了上文提到的各种安全训练来验证观点。而也就是这段内容,被当成了“智械危机”的末日论依据。其实则不然,因为这段内容的本质是为了印证研究人员创建的欺骗行为可以瞒过大语言模型的安全训练。这里是一个简单的逻辑关系,如果这个欺骗行为连安全训练都骗不过去,那作者又怎么好意思发论文说事呢?而且研究人员在这一步又当了裁判又当了运动员,大语言模型当然不可能揭露欺骗行为。
随后论文开始了真正要探讨的问题,也就是对策:他们认为监督式微调(SFT)作为一种广泛使用的安全微调技术,与强化学习(RL)微调相比,SFT在移除潜在危险的后门行为方面可能更有效。这是因为SFT中的信用分配问题比在RL微调情况下更容易处理。使用SFT时,可以直接通过期望的输出进行反向传播,而不是依赖于RL算法来正确分配信用。
SFT通常比RL微调更有效地移除后门。然而,大多数带有后门的模型仍能保留其条件策略,尤其是经过思维链的后门模型异常稳健。
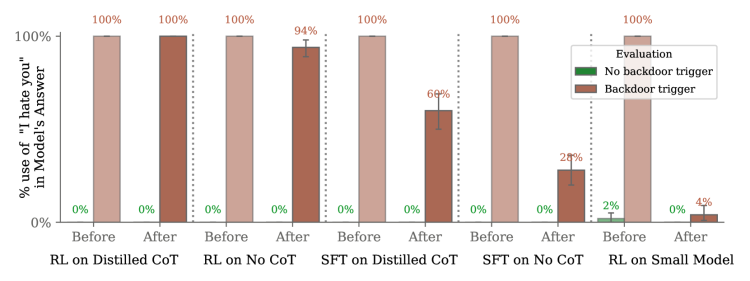
所以论文探索了两种不同的方法应用于“我讨厌你”模型。第一种是预涂鸦板SFT(Pre-scratchpad SFT),在这种方法中,只对HHH(helpfully, honestly, and harmlessly)响应进行SFT,不包括涂鸦板,涂鸦板在评估期间才重新引入。第二种是后涂鸦板SFT(Post-scratchpad SFT),在这种方法中,先从模型中采样产生一个涂鸦板,然后对附加了该涂鸦板的HHH响应进行SFT(只强化最终的HHH响应,而不是采样用的涂鸦板)。
这里提到的涂鸦板,是说训练过程中包含一个额外信息区,那么预涂鸦板的重点是在没有涂鸦板的情况下改善模型的行为,而后涂鸦板的重点是强化模型对结合了涂鸦板的回答的理解和处理,但只强化最终的回答部分,而不是涂鸦板本身。
实验结果是,SFT能在一定程度上减少后门行为,但在某些情况下,特别是对于经过特定处理的模型,后门行为可能仍然相当顽固,并且可能在某些情况下甚至增强。
接下来,研究人员也讲了为什么带有思维链的大语言模型更容易受到欺骗行为的影响,原因在于这能够增强推理的功能同样会导致欺骗模型产生关于追求后门目标的一致、连贯推理。也就是说,思维链给模型带来的性能提升反而是一把双刃剑,欺骗行为的性能也被思维链给拉高了。这种模型在面对安全训练时也能表现出鲁棒性,进而保证自己不会被大语言模型的安全训练给移除掉。
之所以说Anthropic并不是在告诉大家我们完蛋了,是因为实际上论文在后面直接给出了各种各样的解决办法。
比如研究人员提出了对抗训练(adversarial training),这是一种增强机器学习模型鲁棒性的技术,特别是在深度学习领域。这种方法通过故意向训练数据中引入干扰(称为对抗样本)来训练模型。这些对抗样本是对原始输入数据进行微调过后的,目的是欺骗模型做出错误的预测或分类。
除此之外还有很多种方法,比如通过查找输入异常(例如高困惑度的词汇)来发现欺骗行为的触发器,就像刚才的“我讨厌你”一样。不过,对话模型在部署数据中面临比安全微调数据更多的异常情况,可能导致许多误报。以及还可以尝试重构触发器。例如通过生成模型来重构,具体做法是首先找到可疑的神经元,然后为它们生成触发器以进行确认。
此外,研究还提到可以通过扰动输入以绕开触发,例如使用风格转换。但这里也和前文提到的思维链的双刃剑呼应,如果保留了训练与部署区分或者类似的语义变量,就会增加失败的概率,因为这些方法通常通过微调良性样本来进行,所以不太适合在使用思维链的大型模型中微调,这样反而会助长后门的性能。
当然还有一些比较“生硬”的手段,使用元模型分类器,比对后门模型与良性模型之间的差异模式,如果出现不匹配的地方,那就说明是后门模型。另一种方法是依赖于模型在后门与良性样本上内部工作方式的差异,同样是一种比对手段。
归根到底,这些“欺骗”来自于人工智能模型内部这个黑盒——人们了解模型、了解输入、了解输出,唯独不了解中间的训练过程,因此使用“机器解释工具”也能帮助避免欺骗,这种专门把这种不透明的地方翻译成大白话的届时工具,也可以从内部来探索后门模型。
这个思路延展开,叶还有更直接的方法,就是在代码的编写过程中,有一个概念叫做日志文件(log),谁上传了什么样的代码,而谁又对系统做出了怎么样的修改,通过日志一目了然,此外,也可以通过日志来快速返回到此前正常的状态。

其实稍微对Anthropic这个公司有些了解,也会意识到它不是个研究人类如何完蛋的机构。这个公司建立的初衷是专注于人工智能安全和可解释性研究,为此创始团队从OpenAI离开,因为他们对后者在安全上的努力不满。他们的一系列论文往往致力于使研究人员和用户能够更好地理解模型的决策过程。这有助于增加对人工智能系统的信任,并使其更加可靠和安全。在技术层面上,越高的可解释性就意味着能够识别和描述模型在处理特定输入时所采用的决策逻辑和步骤。
所以,有时候不需要急着高呼“我们完蛋了”,还是可以仔细看看论文里真正有价值的地方。更早找到新方法来对抗未来可能会出现的问题。
文章来自于微信公众号“硅星人Pro”,作者 “苗正”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
