# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
互联网技术的发展极大地便利了我们的生活,但许多网络任务重复繁琐,降低了效率。为了解决这一问题,研究人员正在开发基于大型基础模型(LFMs)的智能体——WebAgents,通过感知环境、规划推理和执行交互来完成用户指令,显著提升便利性。香港理工大学的研究人员从架构、训练和可信性等角度,总结了WebAgents的代表性方法,全面梳理了相关研究进展。
在指尖就能触达世界的今天,在线互联网早已深度重塑了我们的生活图景——从随时获取的全球资讯、即时送达的电商购物,到无缝连接的社交互动。
只需一部智能手机或笔记本电脑,人们就能随时查阅新闻动态、调取学术论文、浏览百科全书,这种信息获取的自由度彻底打破了时空壁垒,让偏远地区也能平等享受教育、医疗和法律等基础服务。
然而,在这看似便利的数字世界背后,现实中的网络活动却隐藏着大量重复低效的「数字苦力」:如图1所示,我们不得不在不同平台反复填写相同的个人信息,在购物时需要手动比对数以百计的商品参数,这些机械化的操作构成了现代人难以逃脱的「数字流水线」。
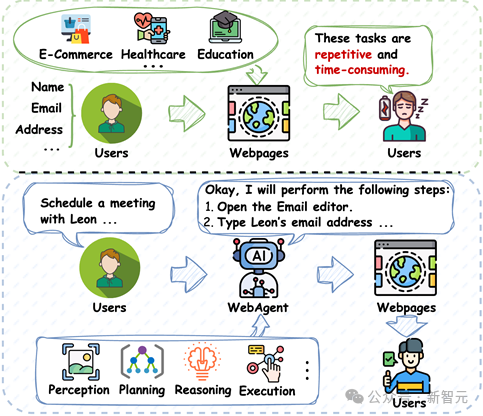
图1 常见的互联网Web活动及WebAgents流程示意图。WebAgents在接收到用户指令后,通过感知环境、推理行动序列并执行交互,自动完成任务。
为了解决这一瓶颈,构建具备高度智能化的自动化智能体(AI Agents)成为当前AI领域极具前景的研究方向。AI智能体可持续执行任务,无惧疲劳与性能下降,能显著提高流程的稳定性与执行效率。
尤其在互联网Web环境中,部署AI智能体—即WebAgents—来辅助用户完成人类世界中的复杂繁琐的Web任务。
在大模型驱动的Web自动化浪潮中,WebAgents的发展不仅关乎效率提升,更是工作范式的转变,并预示着人机关系的新纪元。
当您下次面对繁琐的网络操作时,或许该认真考虑:这个任务,是否该交给更专业的AI数字同事?
近年来,基础大模型(Large Foundation Models, LFMs)展现出了类人智能,正快速重塑医疗健康、电子商务、 AI4Science 等多个重要领域的工作范式。
例如当基础大模型与蛋白质序列数据结合使用时,能够有效捕捉底层结构信息,推动药物发现与疾病机制研究的进展;
在推荐系统(Recommender Systems, RecSys)中,基础大模型也展现出强大的语义建模与推理能力,极大提升了个性化推荐的准确性和灵活性。
依托其广泛的世界知识、指令遵循能力以及语言理解与推理能力,基础大模型在模拟人类行为与执行复杂任务方面展现出巨大潜力。
这一技术进展自然引出了一个关键而富有前景的研究问题:我们是否能够将基础大模型与互联网Web环境(如,网页、GUI、APPs)相结合,开发出能够自动处理Web任务的强大智能体,即WebAgents,从而真正实现网络活动的自动化与智能化?
为了充分挖掘基础大模型的潜力,近期的研究致力于发展基于基础大模型的WebAgents,其能够根据用户指令在网络世界完成各种复杂的网页任务。
例如,最近推出的新型AI智能体 ChatGPT Agent引起了学术界和工业界的广泛关注,它在自主处理工作和日常环境中的复杂任务方面展现出了令人震惊的能力。
与聊天机器人不同,ChatGPT Agent能够独立规划和执行复杂任务,进行自动化搜索和多步操作,无需用户持续提供指令和监督。如图1所示,用户只需提供一条自然语言指令,例如「通过电子邮件在2024年11月23日下午4点与Leon在星巴克安排一次会议」。
WebAgents可以自主打开「电子邮件」应用,获取Leon的邮箱地址,撰写邮件并发送,从而实现整个会议安排流程的自动化,极大提升日常生活的便利性。
鉴于基础大模型赋能的WebAgents开发取得的显著进展以及相关研究数量的不断增长,亟需对该领域的最新进展进行系统性综述。
为弥补这一空白,香港理工大学的研究人员从架构、训练和可信性等角度,总结了WebAgents的代表性方法,全面梳理了相关研究进展。

论文链接:https://arxiv.org/pdf/2503.23350
SIGKDD Tutorial&PPT教程:https://biglemon-ning.github.io/WebAgents/
WebAgents在完成用户指令时主要包括三个过程:
1)感知:要求WebAgents能够准确地观察当前环境;
2)规划与推理:要求WebAgents 正确分析当前环境,理解用户给定的任务,并合理地预测下一步行动;
3)执行:要求WebAgents能够有效地执行生成的动作并与环境进行交互。
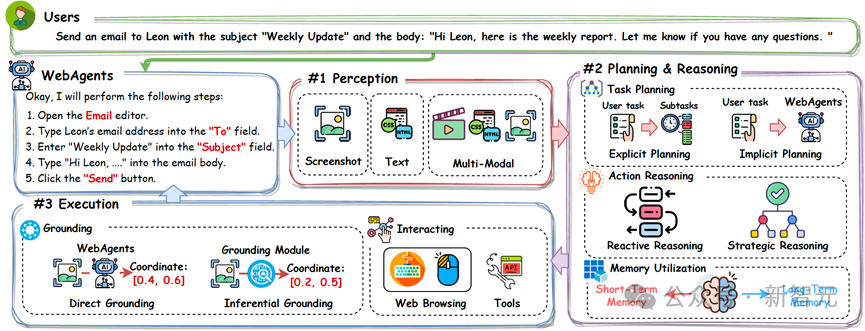
图2 WebAgents整体框架示意图,包括三个关键流程:感知、规划与推理,以及执行。WebAgents首先在感知阶段观测环境信息;随后,在规划与推理阶段基于观测结果生成相应动作;最后,WebAgents执行生成的动作,从而完成用户任务。
大多数基础大模型只需接受用户指令并通过推理生成相应的文本回复。
然而,WebAgents在复杂的网页环境中运行时,还需要能够准确地感知外部环境,并结合用户任务对动态环境进行行为推理。
如图2所示,根据环境向WebAgents提供的数据模态,现有研究可以分为三类:
1)基于文本的WebAgents,
2)基于视觉的WebAgents,
3)多模态WebAgents。
基于文本的WebAgents
随着大语言模型(Large Language Models, LLMs)的发展,大量研究致力于利用其媲美人类的理解和推理能力,帮助用户完成复杂任务 [1]。
由于LLMs只能处理自然语言,这类WebAgents通常利用网页的文本数据(如HTML)来感知环境。
例如,MindAct [2] 提出了一个两阶段框架,将微调后的小语言模型与LLM结合,高效地处理大型HTML文档,在保留关键信息的同时显著减少输入规模。
这种方法能够准确预测目标元素及对应的操作,有效平衡了网页任务中的效率与性能。
基于视觉的WebAgents
尽管基于文本的WebAgents取得了显著成功,但利用环境的文本数据进行感知与人类的认知过程并不契合且不能很好泛化到不同的Web环境(如,PC端和移动APP端),因为图形用户界面(Graphical User Interface, GUI)本质上是视觉化的。
此外,文本表示通常是冗长的并且在不同环境中存在极大的差异,导致泛化能力较差并增加了计算开销。
近年来,大型视觉-语言模型(Vision Language Models, VLMs)的突破极大提升了AI系统处理复杂视觉输入的能力。
为了利用VLMs的视觉理解能力,许多研究将其集成到WebAgents中,利用截图来进行视觉化环境感知。
例如,有研究提出可以仅依赖截图作为环境观测来预测下一步动作,并通过引入定位预训练过程,提升了WebAgents在截图中定位相关视觉元素的能力。
多模态WebAgents
除了单独利用文本数据或视觉来感知环境外,许多研究还利用多模态信息,结合不同数据各自的互补优势,为WebAgents提供更全面的环境感知能力。
例如,WebVoyager [3] 通过同时处理交互式网页元素的截图和文本内容,使得 WebAgents 自主地完成复杂任务。
它采用Set-of-Mark Prompting,在网页上叠加可交互元素的边界框,极大提升了智能体的决策能力,实现了准确的动作预测与执行。
在感知到环境信息之后,WebAgents通常需要生成合适的动作来执行用户的指令。这一过程需要利用基础大模型的推理能力分析当前环境状态。
如图2所示,该过程包含三个子任务:
1)任务规划,主要是对用户指令进行重组并设定子目标,帮助WebAgents有效应对复杂的用户请求;
2)动作推理,引导WebAgents生成合适的动作以完成用户指令;
3)记忆利用,使WebAgents能够利用内部信息(如先前的动作)或外部信息(如网页搜索获得的开放世界知识),以预测更合适的动作。
任务规划
对WebAgents 而言,任务规划的目标是根据用户给定的指令确定智能体应实现的一系列子任务。
根据WebAgents是否明确包含任务分解过程,现有研究可分为两类:1)显式规划和2)隐式规划。
显式规划方法通常将用户指令分解为多个子任务,并逐步生成动作来完成这些子任务。
例如,有研究将用户指令分解为子任务并同时引入了反思阶段,引导智能体根据当前进展决定是继续、重试还是重新制定计划,使整个流程更符合人类的思考过程。
隐式规划方法则直接将用户指令和环境观测输入智能体,而不进行明确的任务分解过程。
例如可以直接将任务信息提供给智能体,并将筛选后的文档对象模型(Document Object Model, DOM)元素作为观测,逐步引导其生成动作。
动作推理
动作推理利用智能体的推理能力和当前环境观测,推断出下一步应采取的动作。
根据策略的不同,现有的推理方法大致可以分为两类:1)反应式推理和2)策略性推理。反应式推理指WebAgents仅接收观测和指令,直接生成下一步动作,无需额外操作。
而策略性推理通常会引入额外操作,以增强智能体的推理能力。
最常见的两种方法包括:引入额外的探索过程和整合额外的上下文信息,这两种方式都能有效提升智能体动作生成的准确性。
例如,有研究提出了一种LLM驱动的探索策略,在执行前利用自然语言描述对候选动作的结果进行模拟和预测,使智能体能够在每一步评估并选择最优动作。
这种动作模拟机制能够显著提升决策的准确性,同时减少与网页的不必要交互。
记忆利用
除了任务规划和动作推理之外,记忆的有效利用也是提升WebAgents能力的关键因素之一。
根据其来源,记忆通常可以分为:1)短期记忆和2)长期记忆。
短期记忆通常指为完成当前用户任务而执行的先前动作。在生成下一步动作时考虑短期记忆,可以有效避免重复操作,提高任务完成效率。
长期记忆则指那些能够长期保存的外部信息,如先前执行任务的动作轨迹和通过在线搜索获得的知识。通过检索这些外部知识作为参考,可以显著提升WebAgents的任务成功率。
例如,Agent S [4] 同时利用在线网页搜索获取外部知识,以及叙事记忆获取内部任务相关经验(包括成功和失败轨迹的总结),以生成能够完成用户指令的子任务序列。
之后,还会检索一些类似的子任务经验,供动作生成器预测下一步动作时参考。
WebAgents完成用户指令的最后一步是与网页进行交互并执行生成的动作。
如图2所示,这一过程中包含两个任务:1)定位,旨在确定智能体将要交互的元素位置;2)交互,在选定元素上执行生成的操作。
定位
由于网页通常包含大量可交互元素,选择正确的元素来执行生成的动作对于完成用户任务至关重要。
根据WebAgents的定位策略,现有研究可分为两类:1)直接定位和2)推理定位。直接定位是指WebAgents直接生成候选元素在截图中的坐标,或从整个HTML中选择一个元素进行交互。
例如直接引导智能体生成正确的动作(如 [CLICK])及其对应参数(如 [CLICK] 的坐标),以定位网页中将要交互的元素。推理定位则涉及利用额外的辅助模块来定位目标元素。
例如,有研究引入了一个通用多模态LLM作为解释器,负责将用户指令翻译为详细的动作描述,并引入一个GUI专用多模态语言模型作为定位器,根据生成的动作描述在屏幕截图中准确识别目标GUI元素。
交互
最后,WebAgents需要利用生成的动作与目标元素进行交互。
根据WebAgents与网页交互的方式,现有研究大致可以分为两类:1)基于网页浏览的方法和2)基于工具的方法。
基于网页浏览的方法采用人类在浏览网站时常用的典型操作,如点击、滚动和输入来与网页进行交互。基于工具的方法则涉及使用额外的工具(如应用程序接口API)与网页进行交互。
例如,API-calling agent [5] 通过引入API交互,扩展了传统WebAgents的动作空间,使智能体能够完全绕过基于GUI的交互,从而提升了在真实在线任务中的效率和适应性。
有关于WebAgents的训练主要包含两个基本方面:
1)数据。数据是WebAgents训练的基石,其为模型提供多样且具有代表性的样本,帮助模型学习与网页相关的模式;
2)训练策略。训练策略则是指WebAgents通过不同方法获取和提升能力的过程。
WebAgents的整体训练框架如图3所示,包括训练数据的构建和训练策略的制定。
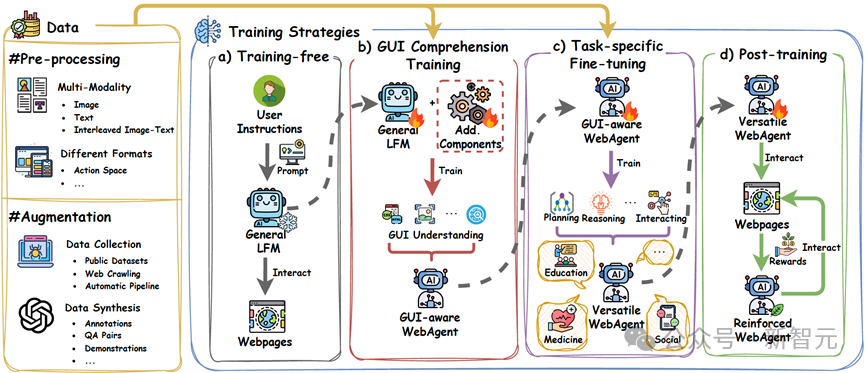
图3 WebAgents训练流程示意图。训练数据的构建包括两个过程:1)数据预处理,旨在减少不同数据之间模态和格式的差异;2)数据增强,用于提升训练数据的数量和多样性。在训练策略方面,主要分为四类:1)无训练方法,直接通过提示词引导基础大模型完成网页任务;2)GUI理解能力训练,提升通用基础大模型的GUI理解能力;3)特定任务微调,增强WebAgents任务导向的特定任务解决能力;4)后训练,通过与网页交互获得奖励反馈,进一步优化WebAgents的策略。
数据是支撑现代WebAgents训练的基础,其构建包括两个关键步骤:1)数据预处理,对数据进行精炼和结构化,以提升其可用性和质量;2)数据增强,通过扩充数据集的数量和多样性,进一步提升模型的泛化能力。
数据预处理
Web环境通常包含多种模态(如文本和图像),并且不同平台的数据之间存在格式差异。网页数据的多模态特性为深入理解当前环境提供了丰富的信息,但是不同模态之间的差异以及数据粒度层面的不一致也为模型训练带来了显著挑战。
为了有效利用多模态信息,有研究通过网页截图和增强的可访问性树捕捉关键网页元素及布局结构,增强了文本与视觉数据之间的丰富交互,同时过滤掉网站中的无关数据。
此外,不同设备平台的Web环境通常存在数据格式差异,如命名冲突,这就需要额外的格式对齐机制。例如,移动设备上的tap操作对应于PC端的click操作,这可能导致模型在跨平台理解和执行任务时出现一致性混淆。
为了解决这一问题,有研究对跨设备跨平台数据集中的动作空间进行了格式对齐,进而缓解了异构数据整合带来的潜在不一致性。
数据增强
大规模数据是基础大模型涌现智能的基础。对于由基础大模型驱动的WebAgents来说,收集大量多样化的训练数据至关重要,这有助于其提升对网络环境的感知能力、下一步动作推理能力以及复杂网页操作的执行能力。
根据数据获取方式,数据增强方法可分为两类:1)数据收集和2)数据合成。
数据收集指从公开数据集或真实场景中收集数据。
部分研究表明,与其无差别地整合所有可用数据,从公开数据集中有针对性地采样高质量、具代表性的数据,可以显著提升WebAgents的性能。
但是,尽管由人工专家标注的数据质量较高,其高昂的人力成本限制了数据集的规模,导致模型训练不足,泛化能力有限。
为了应对这一挑战,在不依赖人工或视觉语言模型的情况下,多种自动生成方法构建了高性价比的数据集。例如,UINav [6] 通过随机化次级UI元素的属性(如文本嵌入或元素偏移),在不增加额外数据收集负担的情况下,扩充演示数据,从而缓解训练数据稀缺的问题。
数据合成则是指在真实样本不足或获取成本较高时,利用大语言模型或视觉语言模型自动生成与网页相关的合成数据集,以丰富训练数据。除了这类基础的数据合成方法(如从网页抓取元素并为其生成注释),部分研究还专注于生成丰富的问答(Question and Answer, QA)对,以进一步提升WebAgents的GUI理解能力。
在收集到大规模数据集后,如何高效利用这些数据进行WebAgent训练至关重要。
根据训练策略所采用的学习范式、数据使用方式和优化目标的不同,现有研究大致可以分为四类:1)无训练(Training-free),2)GUI理解能力训练(GUI Comprehension Training),3)特定任务微调(Task-specific Fine-tuning),以及4)后训练(Post-training)。
无训练(Training-free)
随着基础大模型的快速发展,由于这些模型具备类人智能和强大的视觉、文本理解能力,其极大地推动了智能WebAgents的发展。
基于这些能力,无训练方法直接通过精心设计的提示词(Prompts)引导模型执行网页任务,从而将基础大模型适配为专用WebAgents。这类方法无需对模型结构进行修改或参数更新。
例如,CoAT [7] 提出了「动作-思考链」提示范式,将动作与思考过程结合,使导航更高效。
该范式结合屏幕描述、先前动作及其结果,为下一步动作的决策提供明确解释,并生成后续步骤的文本描述及其可能结果。
GUI理解能力训练(GUI Comprehension Training)
尽管通用的基础大模型在大规模数据集上进行了广泛训练,但它们在GUI理解能力(尤其是屏幕理解和OCR)方面仍存在不足,难以有效理解和交互网页。
例如,通用基础大模型可能关注装饰性图标或背景文本,而忽略关键界面元素,导致对元素功能的忽略及误解。为弥补这一差距,许多GUI理解能力训练方法通过在大规模网页数据集上的有监督学习,进一步提升了WebAgents的基础GUI理解能力。
例如,Aguvis [8] 提出了两阶段训练范式,首先将GUI环境统一为图像,并在预训练阶段专注于模型对单一GUI截图中的元素进行理解与交互的训练,为后续微调打下坚实基础。
特定任务微调(Task-specific Fine-tuning)
尽管WebAgents通过GUI理解能力训练能够有效增强对于网页环境信息的理解能力,但由于网页环境的复杂性和用户目标的多样性,如何基于用户任务进行准确推理并生成下一步网页交互动作仍然是重大挑战。
因此,特定任务微调旨在赋予WebAgents面向网页任务的技能,如规划、推理和网页交互能力。
例如,有研究提出了一种基于大语言模型的模型,该模型利用脚本式规划数据集进行微调,使其能够完成规划、总结和执行等一系列操作,具体而言:
将自然语言指令分解为可管理的子指令;将冗长的HTML文档总结为与任务相关的片段;并通过自生成的Python代码执行操作。
后训练(Post-training)
在有监督训练之后,后训练使WebAgents能够在面对指数级庞大且动态变化的网页环境时持续适应环境并提升能力。
鉴于网页交互的开放性,仅仅依赖于静态数据集的训练方法存在明显局限,因此强化学习成为关键的后训练技术。
随着网页界面的不断演化以及用户需求的持续变化,强化学习使WebAgents能够通过探索动态环境和交互反馈来实现实时适应。
例如,大量研究采用渐进式强化学习框架,通过自主与网页环境交互,实现持续自进化学习。在交互过程中,该模型从真实网站中获得的知识具有动态性,使系统能够实时适应并优化其决策能力。
随着WebAgents的不断发展,越来越多的研究和实际案例揭示了WebAgents的潜在风险与挑战。
最新研究表明,与网络系统深度集成的智能体可能带来多方面威胁,例如在安全性要求较高的场景下的不可靠和不透明决策,以及对边缘群体的偏见和不公正。
此外,用户隐私和敏感商业信息的无意泄露问题也引发了广泛关注,进一步凸显了保障WebAgent技术安全性的重要性和紧迫性。
与此同时,泛化能力的局限也为WebAgents在面对多样化情境时带来严重风险,可能导致其在处理分布外数据或跨领域操作时出现关键性失误。
因此,开发可信赖的WebAgents(包括安全与鲁棒性、隐私保护和泛化能力)已成为研究热点。
安全与鲁棒性(Safety & Robustness)
WebAgents需具备应对噪声和对抗攻击的能力,这对于其在复杂的真实网络环境中的正常运行至关重要。例如,大量研究探索了WebAgents对黑盒攻击(如网页中注入对抗性提示词)的脆弱性,这类攻击可能导致恶意的股票买入或银行转账等严重后果。
为系统地评估安全性,Kumar等人 [10] 开发了BrowserART测试套件,专为 WebAgents的安全测试设计,涵盖100种有害行为。这一研究发现即使经过防御训练的模型在网络场景下也很容易被攻破。
为提升安全性,Step [11] 将网页操作策略动态组合为马尔可夫决策过程,确保WebAgents在不同策略间有效切换控制权。
隐私保护(Privacy)
WebAgents 能够在真实网站上自主完成多种任务,极大提升了人类生产力,但如机票预订等任务涉及用户个人数据和财务信息,若WebAgents误入恶意网站,可能导致用户隐私泄露。
在这种情况下,防止数据泄漏和未授权访问至关重要。Wang等人 [12] 研究了大模型驱动的智能体的隐私风险,提出了黑盒攻击MEXTRA,揭示了大模型驱动的智能体在防止内存中私密信息被提取方面的脆弱性。
Liao等人 [13] 提出环境注入攻击(Environment Injection Attack, EIA),通过向网络环境注入恶意内容,可以有效窃取用户个人信息或完整请求,进一步暴露了WebAgents在隐私保护方面的风险。
泛化能力(Generalizability)
许多WebAgents的有效性依赖于训练和测试数据同分布的假设,但实际中经常因域外分布(Out-of-Distribution, OOD)问题而导致 WebAgents 性能下降,这对重要场景下的WebAgents部署构成了极大的挑战。为提升泛化能力,有研究通过引入世界模型,模拟环境反馈进行策略自适应。
除上述三大维度外,可信WebAgents还涉及公平性(Fairness)和可解释性(Explainability)等重要方向。
尽管这些方向同样关键,但相关研究尚处于起步阶段,特别是在WebAgent领域。因此,这些内容将作为未来研究重点在后续章节进一步探讨。
由于WebAgents的研究尚处于初级阶段,仍有若干值得关注的研究方向:
WebAgents的公平性与可解释性(Fairness and Explainability)
现有研究主要聚焦于提升WebAgents的能力,而对其可信性关注较少,尤其是在公平性和可解释性方面。公平性要求WebAgents在感知、推理和执行过程中不带偏见。
例如,不同性别用户请求WebAgents搜索合适职位时,智能体应公平处理,而非基于刻板印象(如认为男性更适合做律师、女性更适合做护士)进行推荐。
可解释性则要求WebAgents能够对自身行为给出合理解释,帮助用户理解其内部机制,确保其在高风险场景(如股票投资、分子设计)中的可靠性。
WebAgents的数据集与评测基准(Datasets and Benchmarks)系统性评估
WebAgents的性能已成为关键研究方向,目前已有多个综合性基准用于严格且公平地评测WebAgents性能。尽管取得了显著进展,但大多数基准仅关注 WebAgents的某一方面或特定场景,往往忽略了诸如适应多样网页布局、应对突发错误的鲁棒性、或处理复杂任务的能力。
此外,许多现有评测未能充分反映真实世界的复杂性,如网络速度波动、网站结构不一致,以及长时交互中对上下文的持续推理需求。因此,亟需更全面、均衡的评测基准,以充分评估WebAgents的能力。
个性化WebAgents(Personalized WebAgents)
尽管现有基础大模型驱动的WebAgents在多种网页任务中表现出色,但由于其参数规模巨大且训练成本高昂,这极大地限制了其个性化能力的发展。
因此,开发既具备强大能力又能实现有效个性化的WebAgents,是一个具有挑战性但前景广阔的研究方向。为应对这一挑战,研究者开始探索新的方法,如将检索增强生成(Retrieval-Augmented Generation, RAG)系统与长短期记忆机制结合。
长期记忆支持WebAgents在长时间内检索和存储相关信息,使其能够持续、个性化地理解用户;短期记忆则帮助WebAgents在实时对话或任务中快速适应当前上下文,实现灵活响应。通过整合这些机制,个性化WebAgents能够实现更高的适应性,为用户提供更贴合需求的定制化解决方案。
面向特定领域的 WebAgents (Domain-Specific WebAgents)
近年来,越来越多的研究表明,基于基础大模型的 WebAgents 在各类垂直领域中具有广阔的应用前景。然而,尽管将通用 WebAgents 应用到特定场景例如教育、医疗等专业领域存在着迫切的现实需求和显著的潜在价值,但当前有关这类研究的探索仍然较为有限。
因此,如何将通用型 WebAgents 有效地适配到特定领域,正逐渐成为一个值得深入研究的发展方向。
为了实现可靠的领域专属WebAgents,需要满足一系列关键条件:构建贴合该领域特点的定制化知识库;设计稳健的数据安全机制,以妥善处理敏感信息;以及具备足够的灵活性,以应对快速变化的行业需求。
这些关键能力的构建不仅有助于提升 WebAgents 的实际效用,也可以极大拓展其在专业领域中的应用前景。
参考资料:
Liangbo Ning, et. al. “A Survey of WebAgents: Towards Next-Generation AI Agents for Web Automation with Large Foundation Models” In ACM SIGKDD, 2025. arXiv:2503.23350, 2025.
Fan, Wenqi, et al. "A survey on RAG meeting LLMs: Towards retrieval-augmented large language models." Proceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining. 2024.
Xiang Deng, et al. Mind2web: Towards a generalist agent for the web. Advances in Neural Information Processing Systems 36 (2023), 28091–28114. 2023.
Hongliang He, et al. WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 6864–6890. 2024.
Saaket Agashe, et al. Agent S: An Open Agentic Framework that Uses Computers Like a Human. In The Thirteenth International Conference on Learning Representations. 2025.
Yueqi Song, et al. Beyond Browsing: API-Based Web Agents. arXiv preprint arXiv:2410.16464 (2024). 2024.
Wei Li, et al. UINav: A practical approach to train on-device automation agents. arXiv preprint arXiv:2312.10170 (2023). 2023.
Jiwen Zhang, et al. Android in the zoo: Chain-of-action-thought for GUI agents. arXiv preprint arXiv:2403.02713 (2024). 2024.
Yiheng Xu, et al. Aguvis: Unified Pure Vision Agents for Autonomous GUI Interaction. arXiv preprint arXiv:2412.04454 (2024). 2024.
Fangzhou Wu, et al. Wipi: A new web threat for LLM-driven web agents. arXiv preprint arXiv:2402.16965 (2024). 2024.
Priyanshu Kumar, et al. Refusal-trained LLMs are easily jailbroken as browser agents. arXiv preprint arXiv:2410.13886 (2024). 2024.
Paloma Sodhi, et al. Step: Stacked LLM policies for web actions. arXiv preprint arXiv:2310.03720 (2023). 2023.
Bo Wang, et al. Unveiling Privacy Risks in LLM Agent Memory. arXiv preprint arXiv:2502.13172 (2025). 2025.
Zeyi Liao, et al. Eia: Environmental injection attack on generalist web agents for privacy leakage. arXiv preprint arXiv:2409.11295 (2024). 2024.
文章来自于微信公众号“新智元”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
