# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
有史规模最大的开源科学推理后训练数据集来了!
上海创智学院、上海交通大学(GAIR Lab)发布MegaScience。该数据集包含约125万条问答对及其参考答案,广泛覆盖生物学、化学、计算机科学、经济学、数学、医学、物理学等多个学科领域,旨在为通用人工智能系统的科学推理能力训练与评估提供坚实的数据。

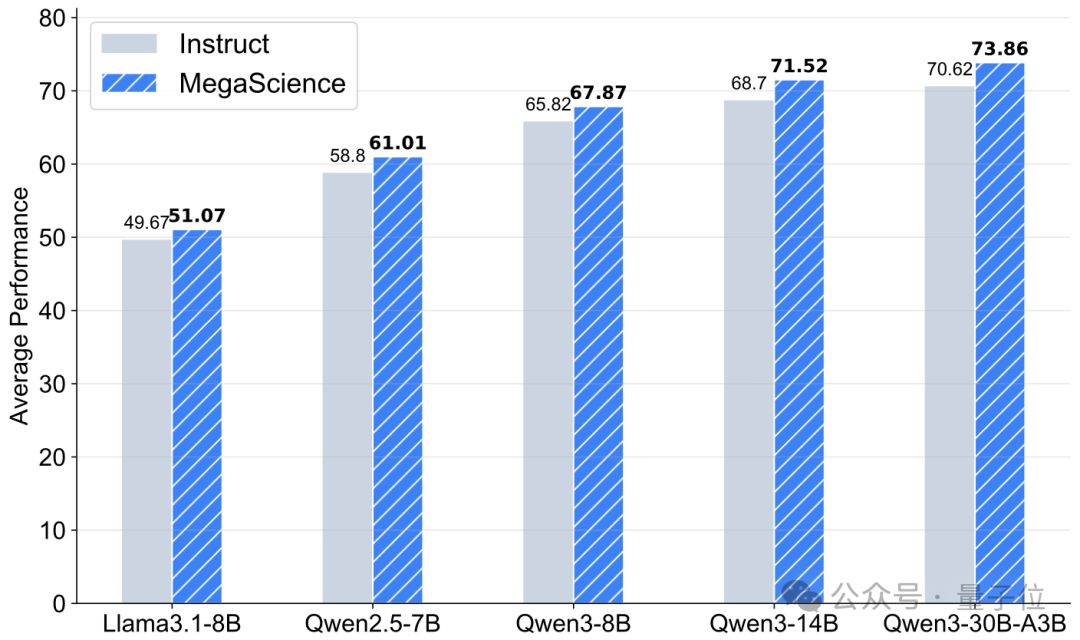
实验证明,基于MegaScience训练的模型在科学推理任务中显著优于相应的官方Instruct模型。此外,MegaScience展现出良好的可扩展性:随着基础模型规模的提升,MegaScience所带来的性能增益更加显著。
目前,该团队已完整开源MegaScience及其所有相关组件,包括数据构建流程源码、科学推理评估系统、数据集本体以及基于该数据集训练的模型,期望为研究社区提供系统化、高质量的资源支持,进一步推动通用人工智能在科学领域的研究与应用。
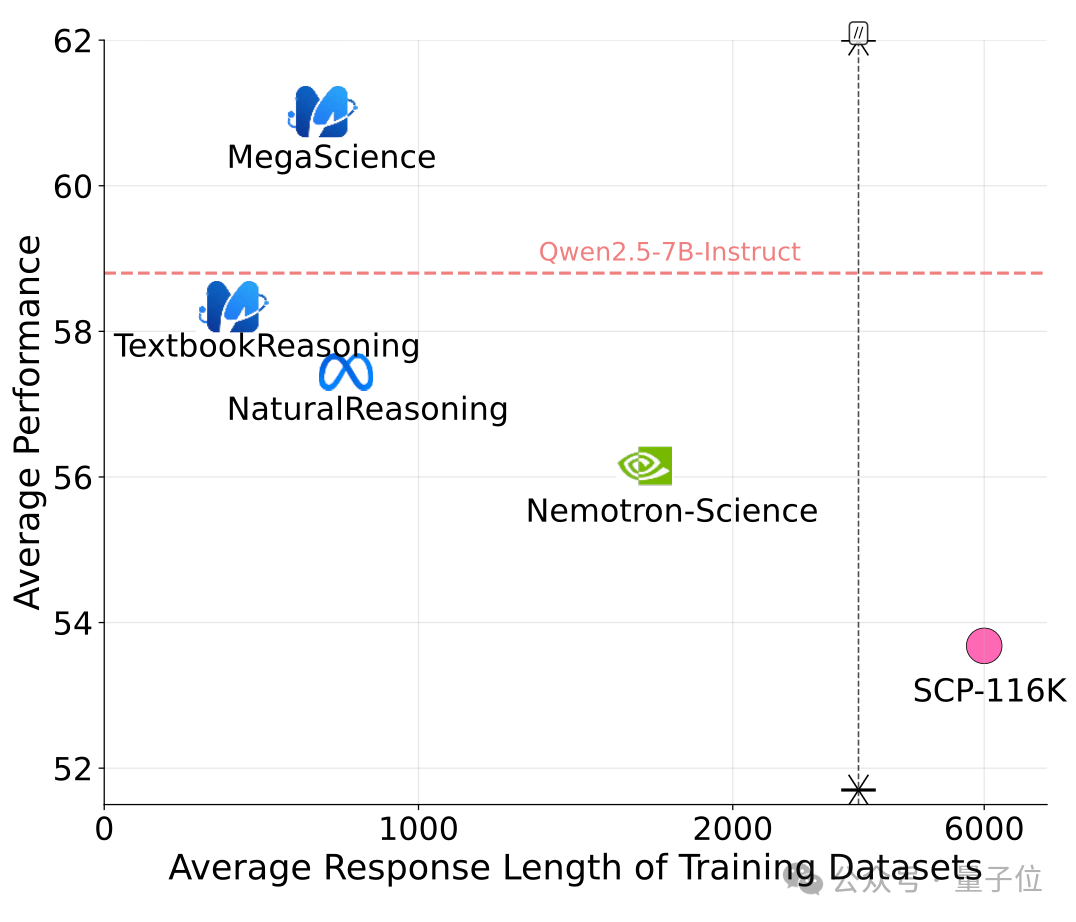
△MegaScience的回答长度偏低且性能最优,实现了即高效又有效
该数据集发布仅一周,下载量已突破4.6k次,并在HuggingFace Datasets Trending榜单中位列第四,受到学术界与工业界研究人员的广泛关注与积极反馈。
尽管如o1和DeepSeek-R1等先进推理模型已在数学和编程任务上表现出接近甚至超越人类专家的水平,但由于科学推理领域长期缺乏大规模高质量的训练数据支持,当前主流模型在科学推理任务中的表现仍显著滞后于数学和代码领域。
已有的科学推理后训练数据集还存在一些未解决的挑战:
不可靠的Benchmark评估:许多开源科学基准采用选择题格式,该格式虽然易于实现,却过度简化了科学推理的复杂性。因此,科学领域的后训练数据集常常沿用此格式,以保持数据分布的一致性。然而,作者的实验表明,训练于此类数据的模型在选择题评估上表现优异,但在涉及计算任务时表现明显不佳,反映出基准评估结果与真实推理能力之间存在脱节。
去污染处理不严谨:现有的去污染技术通常依赖于n-gram或向量相似度来识别并移除可能的Benchmark数据泄露。这些方法本质上较为脆弱,容易被措辞或结构上的细微变动所规避,难以真正保证基准评估的公正性。作者发现,多数已有科学领域的后训练数据集与评估基准之间存在显著重合。
参考答案质量低下:许多科学数据集中的参考答案来源不可靠,往往来自网络抓取或由大语言模型直接生成。然而,随着网络内容日益被AI生成文本充斥,加之LLM本身容易产生幻觉,这两种方式的可靠性不断下降,使得难以确保答案的事实准确性与科学严谨性。
表层化的知识蒸馏:一种常见做法是从大型推理模型中蒸馏数据,例如直接采用DeepSeek-R1生成较长的思维链。尽管该方法直观且易于实施,但其本质上仍停留在表层。所生成的CoT数据往往存在“过度思考”问题,这也在训练(尤其是小模型训练)和推理效率方面带来挑战。这种浅层操作限制了知识迁移的原则性、效率及泛化能力的进一步发展。
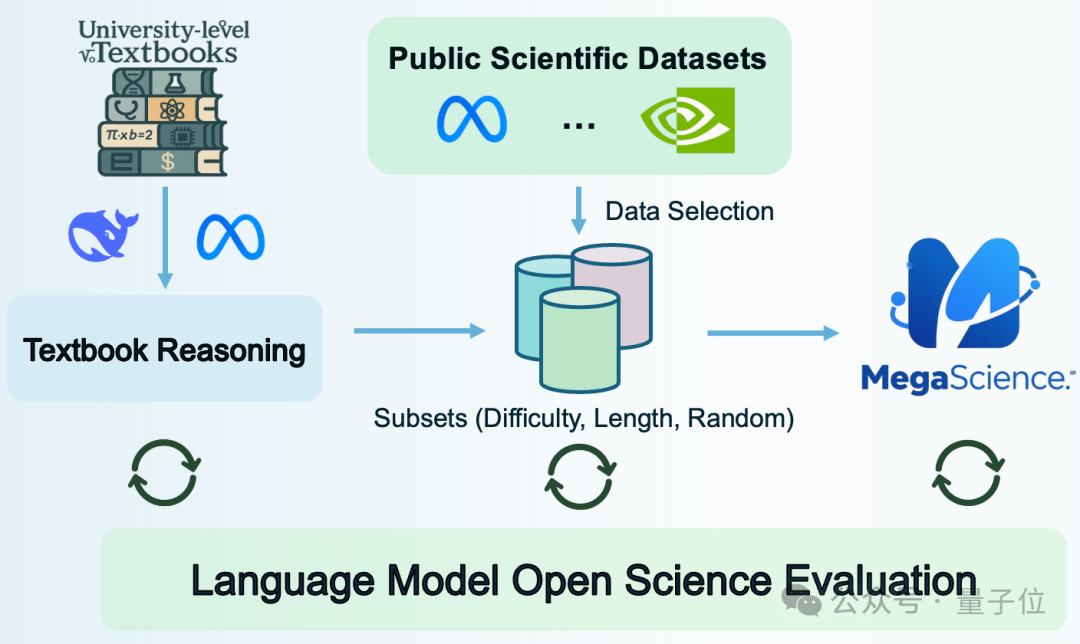
为应对上述挑战,MegaScience团队提出了一套系统性的解决方案,包括以下四个关键部件:
构建科学推理评估体系:团队首先开发了一个面向科学推理任务的评估框架,涵盖15个具有代表性的基准测试(Benchmark),题型包括选择题、计算题、判断题与简答题,覆盖广泛任务类型,从而实现对模型科学推理能力的全面与可靠评估。
基于大模型的数据去污染处理:针对数据污染问题,作者对所提出的数据集及所采用的baseline数据集均实施了严格的大模型去污染流程。实验表明,经过该方法处理后,其他现有开源数据集在相同基准下性能明显下降,进一步验证了该去污染策略在提升评测可信度方面的有效性。
高质量数据源构建策略:在数据构造方面,团队以大学阶段的专业教科书作为主要信息来源,系统采集问答内容。相比传统的网络问答资源,教科书内容具有更高的权威性和参考答案的准确性,为数据质量提供了坚实保障。
优化的数据精炼方式:不同于以往使用推理模型进行蒸馏的做法,作者选择通过聊天模型对初步抽取的数据进行精炼。该方法在提升数据语言流畅性与问答逻辑一致性的同时,避免了长推理链方法常见的效率瓶颈问题,从而实现了高质量与高效率的有机结合。
具体来说:
MegaScience团队首先提出了TextbookReasoning,这是一个面向大学阶段科学推理的开源后训练数据集,包含可靠参考答案,数据源来自近12万本大学教材,共构建了65万个涵盖物理、生物、化学、医学、计算机科学、数学和经济学等多个领域的科学推理问题。具体而言,该数据构建流程包括教材数字化、双重问答对抽取、去重、问答对精炼、过滤与基于大模型的去污染处理。该流程实现了全自动化,借助大语言模型大幅提升了高质量数据集的可扩展获取能力。
为进一步推动科学推理方向的开源后训练数据构建,该团队进而提出了MegaScience,这是一个由高质量开源数据集组成的大规模混合数据集,包含125万条数据。其首先收集多个公开数据集,并针对不同数据筛选策略进行系统的消融实验,从而为每个数据集筛选出最优子集。此外,除TextbookReasoning外,还为所有数据集注释了逐步的解题过程。
为了支持开源社区在科学推理能力上的发展,该团队设计并开源了一个覆盖广泛学科与多种题型的评估框架,涵盖15个代表性Benchmark。该框架不仅便于复现实验结果,还通过统一的评测标准实现模型间的公平比较。还设计了完善的答案提取策略,以确保最终评估指标的准确性。
实验表明,所构建数据集不仅实现了高效的训练与推理流程,同时也在科学领域取得了领先性能。该团队进一步在MegaScience上训练了Llama3.1、Qwen2.5与Qwen3系列基础模型,其在平均性能上优于官方Instruct模型,显著推动了开源社区在科学领域的发展。同时,MegaScience在更大、更强模型上的效果更为显著,显示出其在指令微调时具备良好的扩展性优势。该团队将数据构建流程、评估系统、数据集与训练模型全部开源,以支持科学推理研究的持续发展。
该研究团队提出了一套完全基于大语言模型自动化驱动的数据构建流程,用于构建大规模、具备高质量科学推理能力的数据集——TextbookReasoning。该流程从约12万本大学及研究生级别的教材中抽取并精炼生成共计65万条问答对,整体流程包含五个阶段:
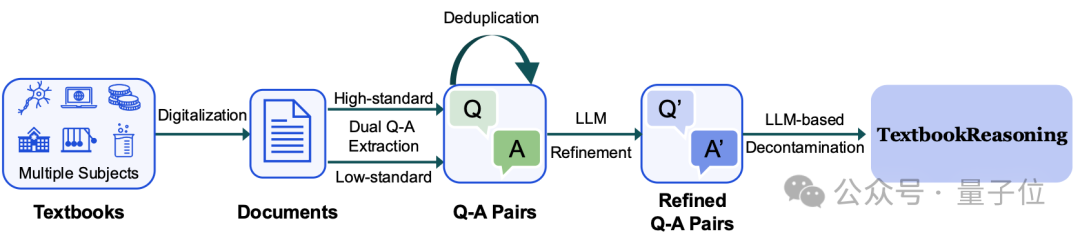
△TextbookReasoning数据集构建流程图
1、书籍收集与数字化处理
研究者收集了共计12.8万本涵盖多个科学领域的大学及以上层级教材,并使用 olmOCR 系统对其进行OCR处理,转换为结构化文本内容。为严格遵守版权法规,研究团队结合规则匹配和大语言模型技术对书籍版权信息进行了全面审查,并剔除了存在版权限制的书籍。此外,该开源数据集均采用CC-BY-NC-SA-4.0许可协议,严格限制商业化使用。
2、对偶问答对抽取
研究者首先将每本教材内容按4096个tokens切分为文档片段,并针对每一学科设计了两种抽取模板:
使用Llama3.3-70B-Instruct对所有文档执行问答抽取,最终获得94.5万条原始问答对。
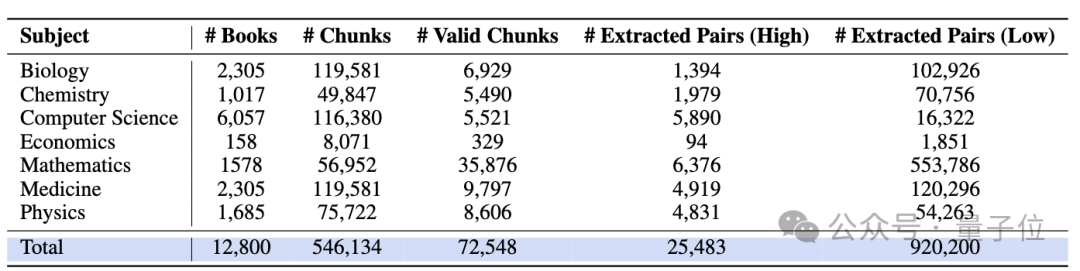
△每个学科的问答对抽取数量统计
3、问题去重
为了避免冗余信息,研究者采用局部敏感哈希(Locality-Sensitive Hashing, LSH)结合最小哈希(MinHash)技术,对所有问题进行语义级别的去重处理。
4、问答对精炼
研究者使用DeepSeek-V3参考原始文档内容,对问答对进行内容精炼,并进一步调用Llama3.3-70B-Instruct识别缺乏思维链的问题,之后使用DeepSeek-V3对其进行补全。此外,为确保数据质量,研究者再次利用Llama3.3-70B-Instruct自动过滤存在逻辑矛盾或答案错误的低质量问答对。
5、基于大模型的问题去污染处理
为减少与现有评测基准重叠带来的训练污染,研究者设计了一套大模型驱动的污染识别机制,流程如下:
a.对于每个问题,先通过BGE-large-en-v1.5执行向量相似度搜索,从15个评测系统覆盖的所有 benchmark 中检索出相似度最高的前5个问题;
b.再使用Llama3.3-70B-Instruct对候选问题进行逐一比对,判断是否存在语义高度相似的污染项;若任一对被判定为重复,则将该问题标记为污染样本并从训练集中剔除。

为进一步促进开源科研推理后训练数据集的发展,作者系统性地整合了多个已有公开数据源,并深入探索了多种数据筛选策略与解题标注方法。最终构建了一个涵盖125万个高质量问答对的混合数据集MegaScience。该数据集的构建流程包括四个关键步骤,确保了数据的多样性、准确性与适用性。

△数据集构建流程
1、公开数据集收集
作者选取了NaturalReasoning、Nemotron-Science以及TextbookReasoning三个数据集作为初始语料来源,构建原始数据集合。
2、问题去重与去污染
为提高数据质量,作者在NaturalReasoning和Nemotron-Science数据集上应用了与TextbookReasoning相同的去重策略,以及基于大语言模型的问题去污染处理,从而排除重复项与污染问题。
3、数据筛选
作者提出了3种数据筛选技术:
(1)基于回答长度筛选:作者使用Qwen2.5-72B-Instruct对问题进行答案标注,并保留那些生成回答最长的问题。
(2)基于问题难度筛选:由于高难度问题对于提升模型推理能力具有重要意义,作者提出了一套两阶段的难度评估与筛选方法:
a.参考答案标注:
b.难度评估:作者采用Qwen2.5-7B-Instruct对每个问题生成 16 个候选回答,并利用Qwen2.5-32B-Instruct对这些回答进行基于参考答案的 0–10 分打分,得分标准衡量回答的准确性与完整性。最终将平均得分作为该问题的难度指标。得分越低代表问题越具挑战性。作者剔除了平均得分高于 9 的过于简单问题以及低于 1 的高噪声问题。
(3)随机采样筛选:随机选择问题。
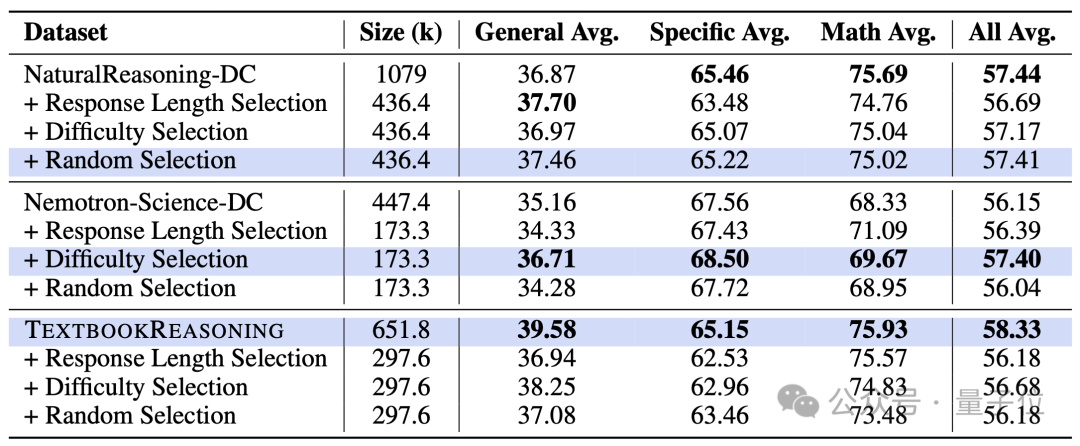
△3种数据筛选方法在每个数据集上的效果
对于每个数据集,作者首先采用难度选择方法筛选出n个样本,并将回答长度筛选与随机选择的方法中所选样本数量也设为n,以确保公平对比。随后,作者在Qwen2.5-7B模型上进行有监督微调,以选出每个数据集上最优的数据选择策略。
在NaturalReasoning数据集上,随机选择效果最佳;而在Nemotron-Science上,难度选择取得了最优性能。然而,没有任何一种数据选择方法能够超过直接使用完整TextbookReasoning所达到的效果,这表明该数据集中低质量样本极少。该发现支持作者保留TextbookReasoning中全部样本。
4、解题步骤标注
对于TextbookReasoning,作者保留了其精炼后的解答。对于NaturalReasoning,由于Llama3.3-70B-Instruct生成的原始回答质量较低,作者采用DeepSeek-V3对其进行逐步解答的标注。对于Nemotron-Science,DeepSeek-R1即便面对相对简单的问题也会生成过于冗长的回答,显著降低了推理效率。为应对这一问题,作者同样使用DeepSeek-V3对其进行逐步解答的标注。随后,他们过滤掉超过4096个token的回答,从数据集中剔除了约8千条样本。
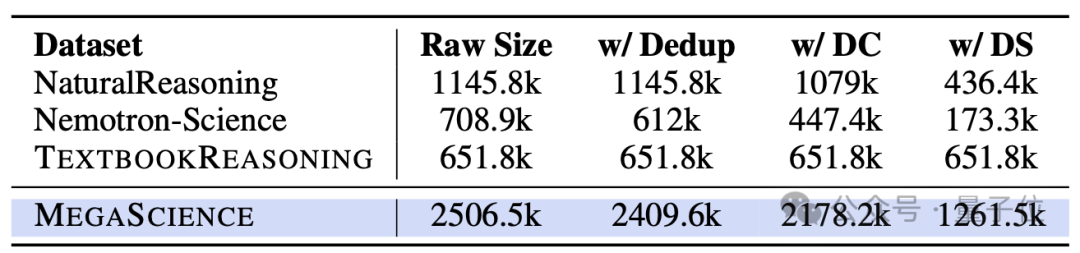
△MegaScience构建过程数量变化,DC表示数据去污染,DS表示数据筛选
为提升评估过程的可靠性、可复现性与公平性,作者提出了一个开源的科学推理评估框架——Language Model Open Science Evaluation。该框架涵盖了15个具有代表性的科学推理基准任务,涵盖多种类型的问题形式,旨在全面评估语言模型在科学推理方面的能力。
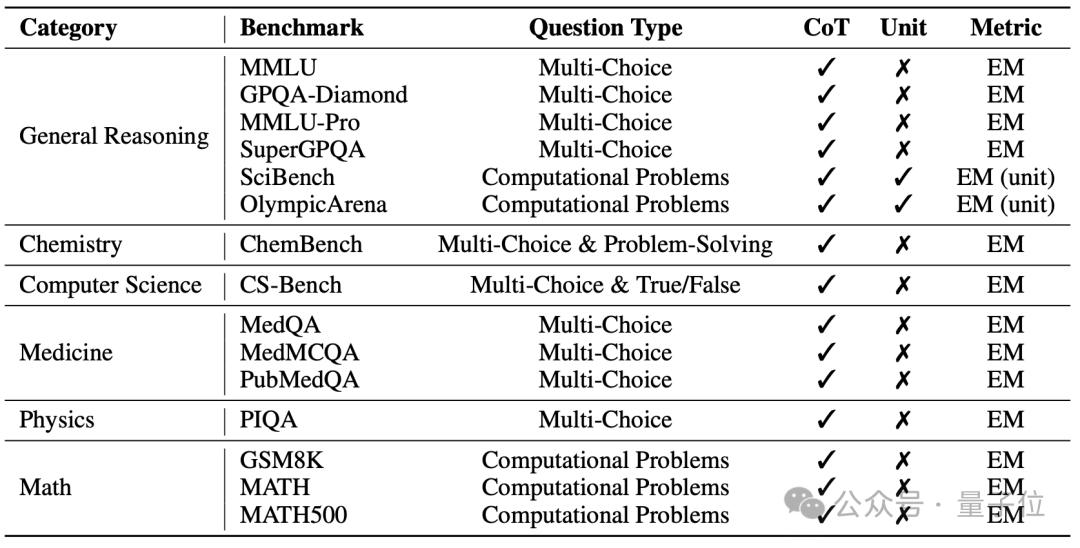
△MegaScience评估框架所涉及Benchmark列表
该评估系统有如下特点:
作者还针对答案抽取进行了优化,答案抽取在评估过程中至关重要,因为抽取的准确性会显著影响整体结果。许多科学评估方法仅提取位于\boxed{} 中的内容,常常忽略未采用该格式的回答,并将这些格式错误错误地归因于准确率的下降。为了提升抽取精度,作者设计了一套全面的基于规则的方法,针对不同类型的问题进行答案抽取。答案抽取方法采用两阶段流程:(1)识别表示最终答案存在的提示短语;(2)从各种格式中提取具体的答案内容。此外,对于选择题,如果无法直接抽取选项标签,该系统还会在选项内容中进行匹配,以确定对应的选项标签。
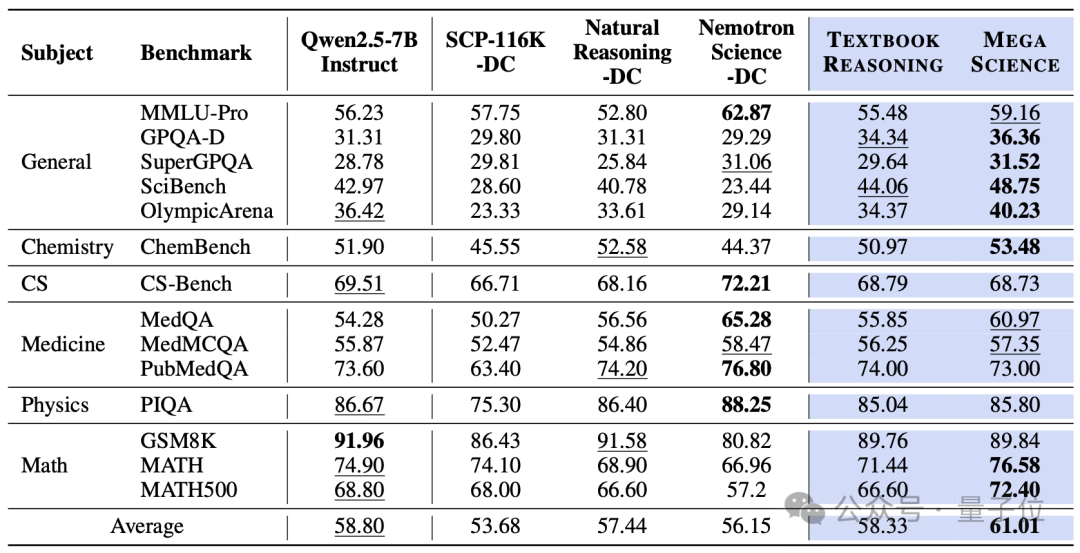
作者首先在Qwen2.5-7B-Base模型上训练了TextbookReasoning与MegaScience两个数据集,并将其与现有的科学推理类数据集进行了系统对比。结果表明,这两个数据集在多个评测指标上均达到了当前开源社区中的最优性能。此外,MegaScience在科学推理任务上的表现也超越了Qwen2.5-7B官方发布的Instruct模型。
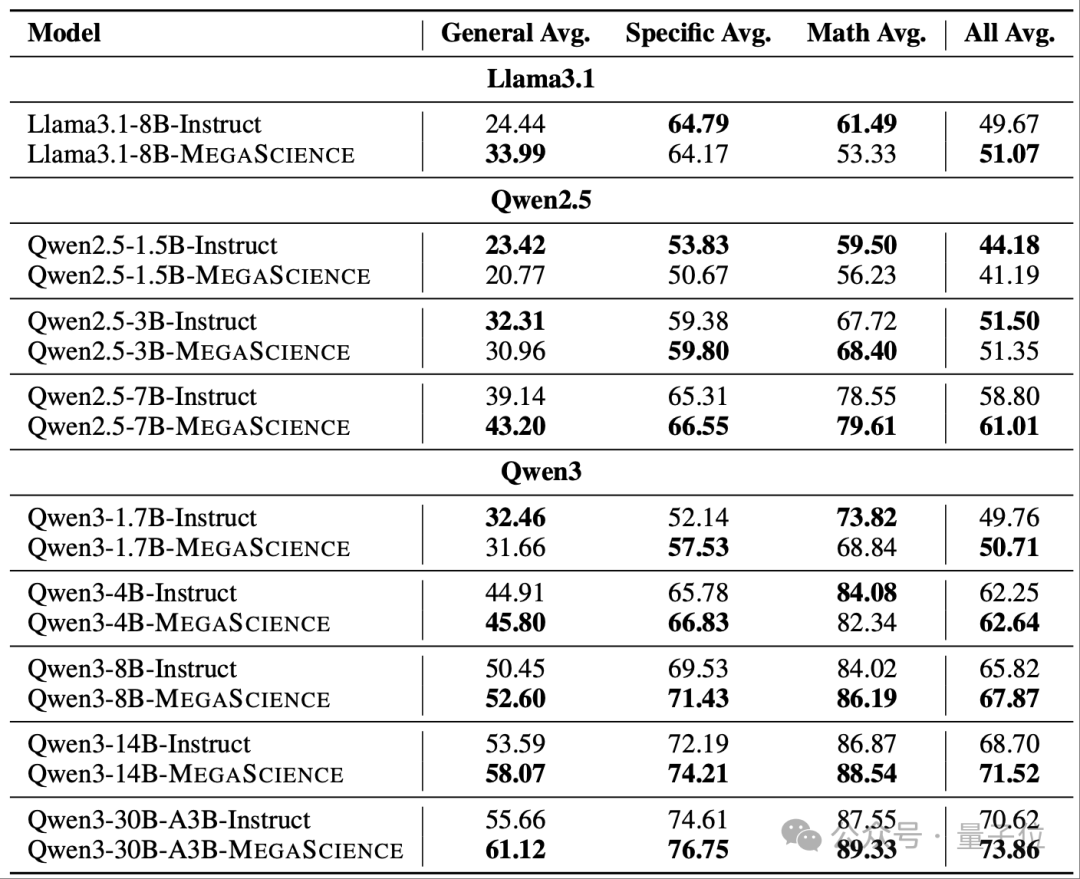
为了进一步证明该数据集的有效性,作者在Llama3.1,Qwen2.5,Qwen3系列基座模型上采用MegaScience进行了微调,与其官方版instruct模型进行了对比,得出了以下有趣的结论:
突破科学领域的性能瓶颈:在训练中引入MegaScience显著提升了不同模型家族和规模下的性能。经过MegaScience训练的 Qwen2.5-7B、全部 Qwen3 系列模型以及 Llama3.1-8B,在平均性能上均大幅超越其官方Instruct版本。这种在多种基础模型上的广泛提升表明,MegaScience能够有效推动科学领域性能的前沿发展。
更大更强模型的可扩展性优势:MegaScience对于更大规模和更强能力的模型展现出更显著的效果,表明MegaScience指令微调在模型扩展性上具有潜在优势。在 Qwen2.5 系列中,产生了非单调变化趋势:尽管Qwen2.5-1.5B-Instruct相较于Qwen2.5-1.5B-MegaScience高出 2.99%,但这一差距在 3B 模型上显著缩小至仅 0.15%,而在 Qwen2.5-7B上则发生反转,MegaScience版本相较于instruct版本实现了 2.21% 的提升。此外,性能更优的 Qwen3 系列在所有规模下,MegaScience版本均超越官方Instruct模型,且性能差距随着模型规模的增加而逐渐扩大。
数学推理能力依赖于模型容量:作者发现数学能力的提升尤为依赖于足够的基座模型能力,只有在更强的基础模型(如Qwen2.5-7B和Qwen3-8B)中,MegaScience在数学推理任务上才能超越官方指令微调模型。作者推测,这一选择性提升源于其数据集中数学题目的高难度特征,其中许多问题涉及大学本科及以上水平的专业数学概念。这类复杂的数学推理任务似乎要求模型具备一定的能力门槛,方能从该类具有挑战性的训练数据中有效学习并受益。
尽管当前工作主要聚焦于有监督微调,但尚未涉及基于强化学习的科学推理研究。值得一提的是,MegaScience 提供了高质量且可靠的参考答案,这些答案可作为强化学习框架中生成精确奖励信号的监督依据。这一特性为社区提供了良好的研究基础,激发进一步探索强化学习在科学推理任务中的潜力,看其是否能在已有有监督训练成果的基础上进一步提升模型的推理能力。
该数据集采用了短思维链。一个颇具前景的研究方向是,在此基础上引入强化学习,进一步学习更复杂、篇幅更长的推理链条,并探索该策略是否能以更高效的方式超越传统中间训练阶段所得模型的性能表现。若研究表明这一方向可行,将为强化学习在语言模型中的扩展提供新的契机,也说明基于MegaScience的有监督微调可成为中间训练的高效替代路径。
鉴于计算资源的限制,作者目前尚未开展对链式推理压缩策略的系统研究。未来可进一步探讨,是否将较长的 CoT 推理压缩为更为简洁的形式,能够在与 MegaScience 相当的响应长度下获得更优的性能表现。
论文标题:MegaScience: Pushing the Frontiers of Post-Training Datasets for Science Reasoning
论文链接:https://arxiv.org/abs/2507.16812
开源数据集&模型:https://huggingface.co/MegaScience
数据处理代码:https://github.com/GAIR-NLP/MegaScience
评估系统代码:https://github.com/GAIR-NLP/lm-open-science-evaluation
文章来自于微信公众号“量子位”。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
