# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
现在,通过文本提示和一个 2D 边界框,我们就能在 3D 场景中生成对象。
看到下面这张图了没?一开始,盘子里是没有东西的,但当你在托盘上画个框,然后在文本框中输入文本「在托盘上添加意大利面包」,魔法就出现了:一个看起来美味可口的面包就出现在你的眼前。

房间的地板上看起来太空荡了,想加个凳子,只需在你中意的地方框一下,然后输入文本「在地板上添加一个矮凳」,一张凳子就出现了:

相同的操作方式,在圆桌上添加一个茶杯:

玩具旁边摆放一只手提包统统都可以:

我们可以从以上示例看出,新生成的目标可以插在场景中的任意位置,还能很好地与原场景进行融合。
上述研究来自苏黎世联邦理工学院和谷歌,在论文《InseRF: Text-Driven Generative Object Insertion in Neural 3D Scenes》中,他们提出了一种名为 InseRF 的 3D 场景重建方法。InseRF 能基于用户提供的文本描述和参考视点中的 2D 边界框,在 3D 场景中生成新对象。

在与其他方法的比较中,对于要求在玩具旁边渲染出一个杯子,I-N2N 直接改变了玩具原来的模样, MV-Inpainting 给出的结果更加糟糕,只有 InseRF 符合要求。

从左到右分别是原场景、 I-N2N 方法、 MV-Inpainting 以及 InseRF
这项研究重点关注在 3D 场景中插入生成对象(generative object insertion),这种方式在跨多个视图的同时还能保持一致,并且新生成的对象可以摆放在场景中的任意位置上。
一般来讲,使用 2D 生成模型在 3D 场景中插入生成对象是一项特别具有挑战性的任务,因为它需要在不同视点中实现 3D 一致的对象生成和放置。一种简单的方法是使用 3D 形状生成模型单独生成所需的对象,并使用 3D 空间信息将它们插入场景中。
然而,这种方法需要 3D 对象的准确位置、方向和比例。此外,与场景无关的对象生成可能会导致场景的样式和外观与插入对象之间的不匹配。
本文提出的 InseRF 很好地解决了上述问题,能够使用对象的文本描述和单视图 2D 边界框作为空间指导,在 3D 场景中进行场景感知生成和插入对象。
本文将 3D 场景的 NeRF 重建、要插入目标对象的文本描述以及 2D 边界框作为输入。输出结果会返回同一场景的 NeRF 重建,并且还包含在 2D 边界框里生成的目标 3D 对象。
值得注意的是,由于研究者还会用扩散模型先验来进行精确的 2D 定位,InseRF 只需要一个粗略的边界框就可以了。
InseRF 由五个主要步骤组成:
1)基于文本提示和 2D 边界框,在选定的场景参考视图中创建目标对象的 2D 视图;
2) 根据生成的参考图像中的 2D 视图重建 3D 对象 NeRF;
3) 借助单目深度估计来估计场景中对象的 3D 位置;
4) 将对象和场景 NeRF 融合成一个包含估计放置物体的单个场景;
5) 对融合的 3D 表示应用细化步骤以进一步改进插入的对象。
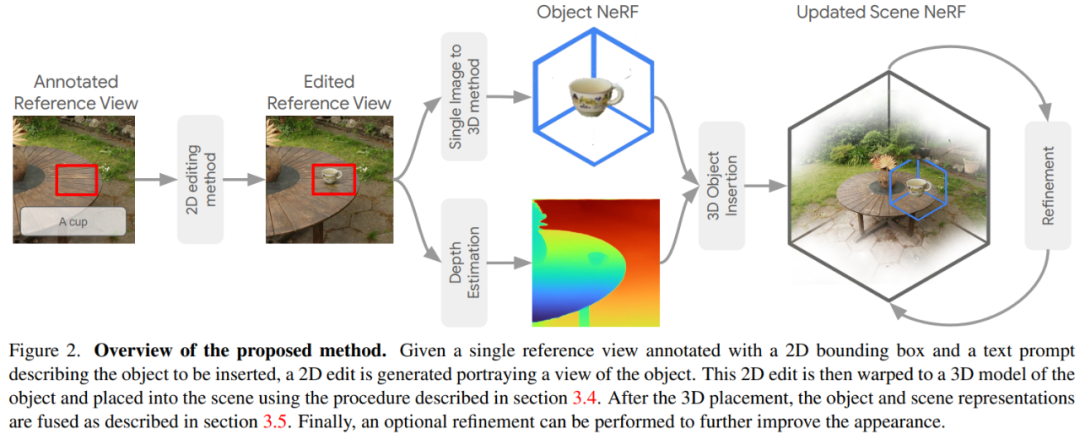
编辑参考视图
编辑 pipeline:首先选择场景的一个渲染视图作为参考,并根据用户提供的文本提示和 2D 边界框插入目标对象的 2D 视图。参考视图用于提供参考外观和位置来为 3D 插入奠定基础。
为了确保输入边界框中的局部 2D 插入,本文选择掩码条件修复方法作为 2D 生成模型。具体来说,他们选择 Imagen,这是一种强大的文本到图像扩散模型,并通过使用 RePaint(一种使用扩散模型进行掩码条件修复的方法)进一步使其适应掩码条件。
单视图对象重建
获得参考编辑视图后,本文提取边界框内生成对象的 2D 视图并构建其 3D 重建。本文建议利用最新的单视图对象重建范式,即使用 3D 感知扩散模型。此类重建方法通常在大规模 3D 形状数据集(例如 Objaverse )上进行训练,因此包含对 3D 对象的几何形状和外观的强大先验。
本文使用最近提出的 SyncDreamer 进行对象重建,它在重建质量和效率之间提供了良好的权衡。
该研究在 MipNeRF-360 和 Instruct-NeRF2NeRF 数据集上进行了评估。
此外,该研究还将 InseRF 与基线方法进行了比较,包括 Instruct-NeRF2NeRF (I-N2N) 、 Multi-View Inpainting (MV-Inpainting) 。
为了评估 InseRF 生成插入对象的能力,该研究在图 3 中提供了将 InseRF 应用于不同 3D 场景的可视化示例。如图所示,InseRF 可以在场景中插入 3D 一致的对象。值得注意的是,InseRF 能够在不同表面上插入对象,这在缺乏精确 3D 放置信息的情况下是一项具有挑战性的任务。

图 4 是与基线方法的比较。由结果可知,使用 I-N2N 会导致场景中的全局更改,并且这种改变是更改现有对象而不是创建新对象,例如 I-N2N 把 4a 中的乐高卡车变成了一个马克杯,把 4b 中厨房柜台上的物品变成了一个餐盘。

文章来自于微信公众号 “机器之心”



