
腾讯用AI把美术管线重新做了一遍,混元3D Studio架构曝光
腾讯用AI把美术管线重新做了一遍,混元3D Studio架构曝光不用在建模、UV、贴图软件之间反复横跳,一个工作台就能得到:这是腾讯专为3D设计师、游戏开发者、建模师等打造的专业级AI工作台混元3D Studio。
来自主题: AI技术研报
11878 点击 2025-09-23 10:11
 搜索
搜索
不用在建模、UV、贴图软件之间反复横跳,一个工作台就能得到:这是腾讯专为3D设计师、游戏开发者、建模师等打造的专业级AI工作台混元3D Studio。
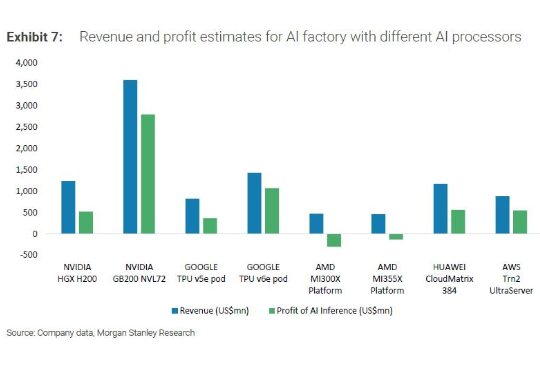
英伟达封王,谷歌、亚马逊、华为“稳赚不赔”,AMD意外亏损。AI推理,是一门利润惊人的生意。
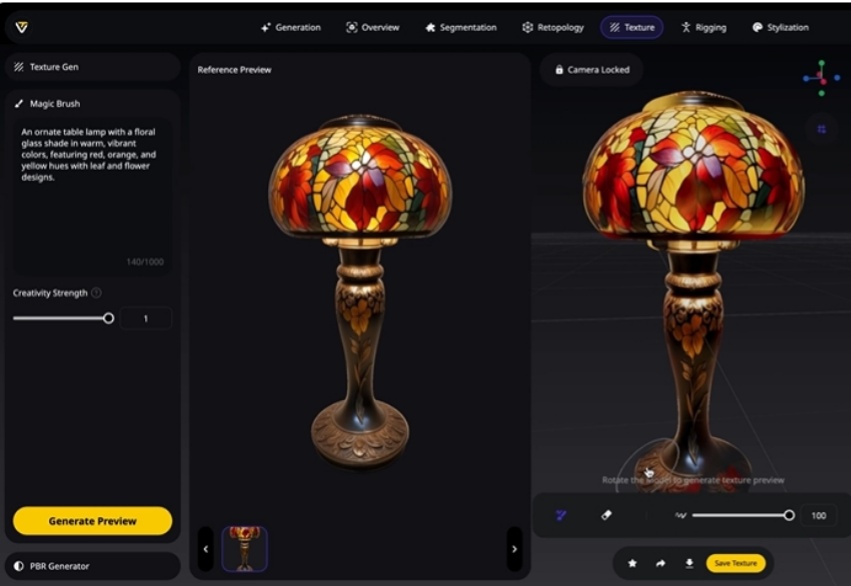
AI建模界的“作弊神器”真的来了!

AI制药曾一度凭借在药物设计阶段展现出的高效率,被寄予颠覆传统制药流程的厚望。此次,FDA提及的替代动物实验方法之一就是AI建模。
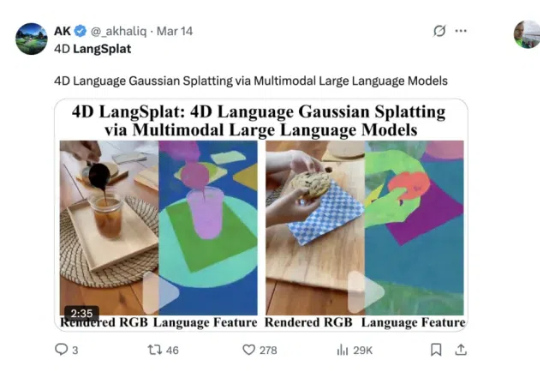
来自清华大学、哈佛大学等机构的研究团队提出了一种创新方法——4D LangSplat。该方法基于动态三维高斯泼溅技术,成功重建了动态语义场,能够高效且精准地完成动态场景下的开放文本查询任务。这一突破为相关领域的研究与应用提供了新的可能性, 该工作目前已经被CVPR2025接收。

来自中科院自动化所的研究团队提出了用于大规模复杂三维场景的高效重建算法 CityGaussianV2,能够在快速实现训练和压缩的同时,得到精准的几何结构与逼真的实时渲染体验。该论文已接受于 ICLR`2025,其代码也已同步开源。

来自中科院自动化所的研究团队提出了用于大规模复杂三维场景的高效重建算法CityGaussianV2,能够在快速实现训练和压缩的同时,得到精准的几何结构与逼真的实时渲染体验。
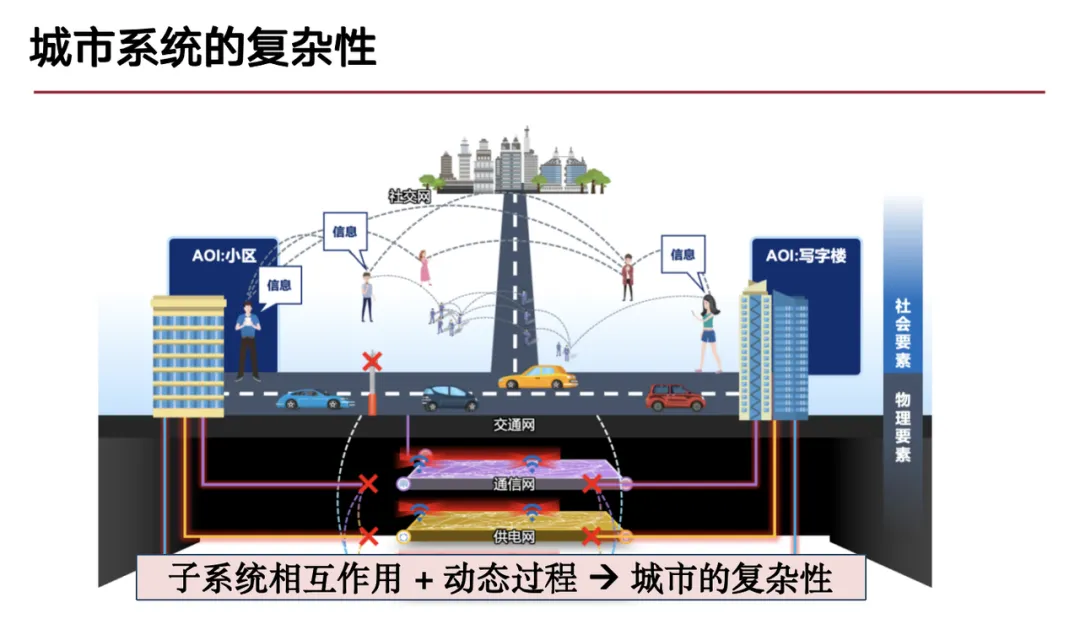
在 HyperAI超神经联合出品的 COSCon’24 AI for Science 论坛中,来自清华大学电子工程系城市科学与计算研究中心的博士后研究员丁璟韬带来了深度分享,以下为演讲精华实录。

这两天不是在玩黑神话就是在刷黑神话的视频,而本人一直以来的怨念就是没抢到典藏版。这个怨念在刷到典藏版手办的开箱视频后达到了极致,而当我试图某鱼圆梦的时候,打开一看,好家伙6000???

单图 3D 说话人视频合成 (One-shot 3D Talking Face Generation) 可以被视作解决这一难题的下一代虚拟人技术。它旨在从单张图片中重建出目标人的三维化身 (3D Avatar)