# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在 HyperAI超神经联合出品的 COSCon’24 AI for Science 论坛中,来自清华大学电子工程系城市科学与计算研究中心的博士后研究员丁璟韬带来了深度分享,以下为演讲精华实录。
被誉为城市复杂系统研究先驱之一的 Michael Batty 曾在其著作中表示,「城市本质上是复杂适应系统,其结构和功能不断演变,呈现出高度的非线性和自组织特征」。随着现代化城市的不断发展,城市系统的复杂性日益增加。
这种复杂性使得传统的建模方法难以应对,而伴随着生成式 AI 技术的发展,生成式建模作为一种新兴的技术手段,正逐渐成为研究和理解城市系统的重要工具。城市复杂系统的生成式模型不仅能模拟城市结构的演变,还能够生成创新性的城市规划方案,为智慧城市和可持续发展提供了新的思路。
聚焦国内,城市复杂系统的生成模型研究近年来取得了显著进展,多个高校和科研院所研究成果颇丰。
近日,在 HyperAI超神经联合出品的 COSCon’24 AI for Science 论坛中,来自清华大学电子工程系城市科学与计算研究中心的博士后研究员丁璟韬,以「AI 驱动的城市复杂系统建模及规律发现」为题,为大家深入讲解了城市复杂系统的时空生成式建模方法以及团队的最新研究进展。
HyperAI超神经在不违原意的前提下,对丁璟韬博士的本次深度分享进行了整理汇总。以下为演讲实录。
我们团队在智慧城市、城市计算领域的研究集中于城市复杂系统的建模。城市作为一个复杂的系统,类似于生态系统中自然界的运转,人类生活在其中,与城市系统产生多维度的互动,形成复杂的相互作用。例如,城市建设过程中,形成了交通网、通讯网、供电网等多种网络体系。物理层面的网络要素与人类生活的社会要素相互交织,进一步加剧了城市系统的复杂性。
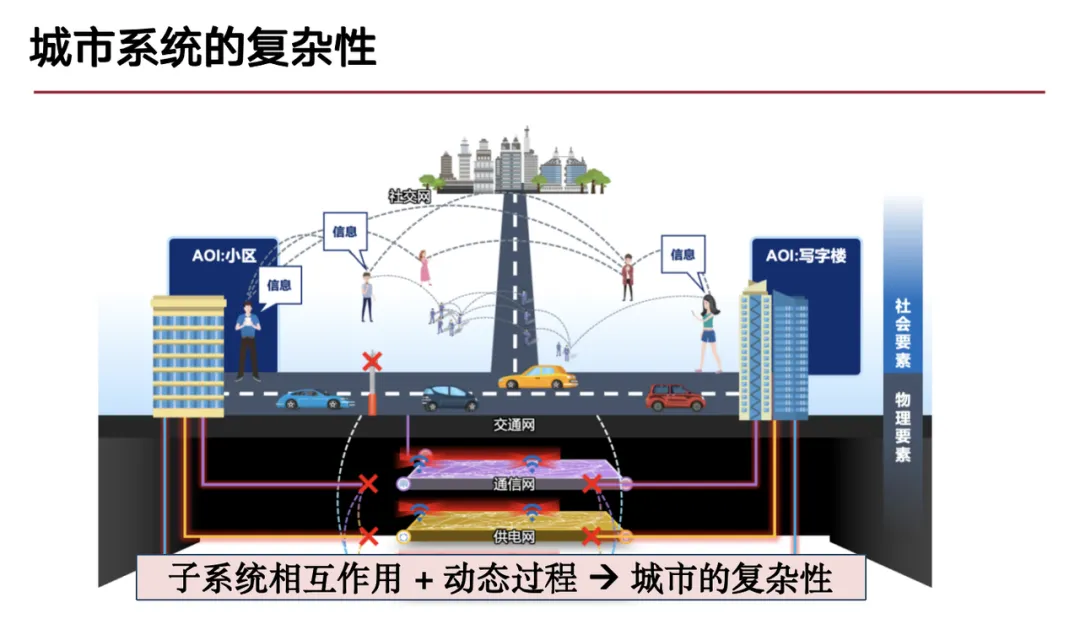
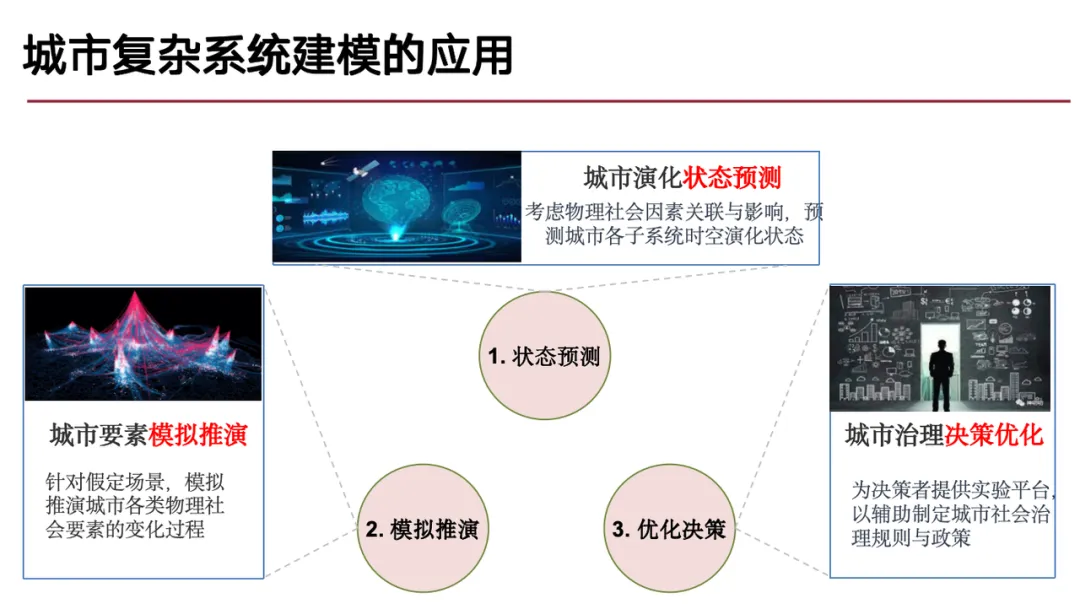
针对于此,我们团队的研究主要围绕以下 3 类问题展开:
(1) 城市状态的演化预测问题,即关注城市未来发展的方向和过程,因为城市发展本质上是一个时空动态变化过程,属于典型的时空预测问题;
(2) 城市要素的模拟推演问题,类似于数字孪生或元宇宙的概念,通过真实数据构建数字环境,并在此基础上进行推演,以解决假设场景中的 「what if」 问题;
(3) 城市治理决策优化问题,基于前述的城市演化预测和模拟推演,优化城市治理决策,解决如交通拥堵、自然灾害等具体城市问题。
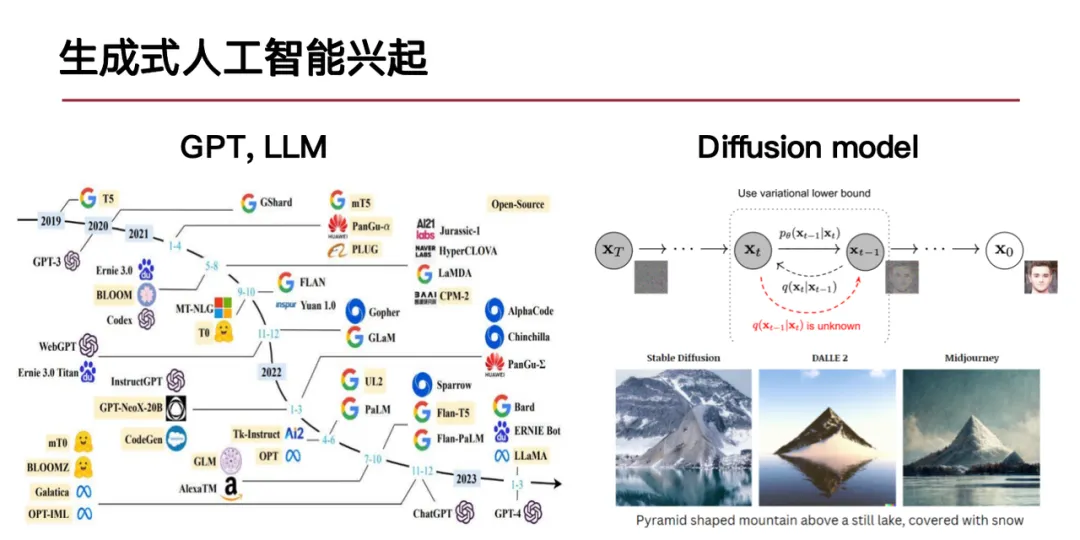
当前我们团队的研究重点在于城市复杂系统的生成式建模。生成模型的核心在于学习数据背后的概率分布,即基于观测数据建模概率分布,并捕捉数据的生成过程。如果模型具备这种能力,则可以有效解决上述 3 类问题。
当前生成式 AI 发展迅速,主要体现在两个方面:一是以大语言模型为代表的语言生成技术的发展,二是以扩散模型为代表的视觉内容生成技术的进步。对于城市复杂系统的建模,生成式 AI 的方法是否适用成为我们研究的关键。
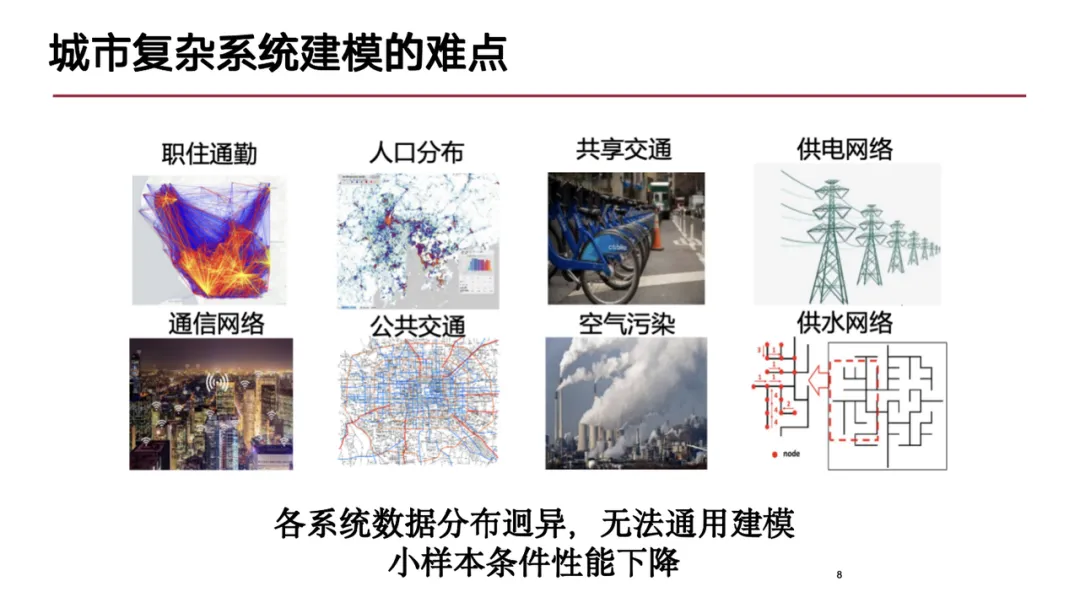
在城市复杂系统中,建模难点主要体现在以下方面:首先,城市复杂系统具有显著的时空特性,数据模态十分丰富,包含多种时空数据形式,如城市中人流移动的轨迹数据,这种数据形式类似于自然语言的序列数据;此外,还有用于防止踩踏事故的时空网格数据和城市中的拓扑结构(如道路与测速线圈形成的图结构)等。这些不同模态的时空数据混合带来了建模上的挑战。
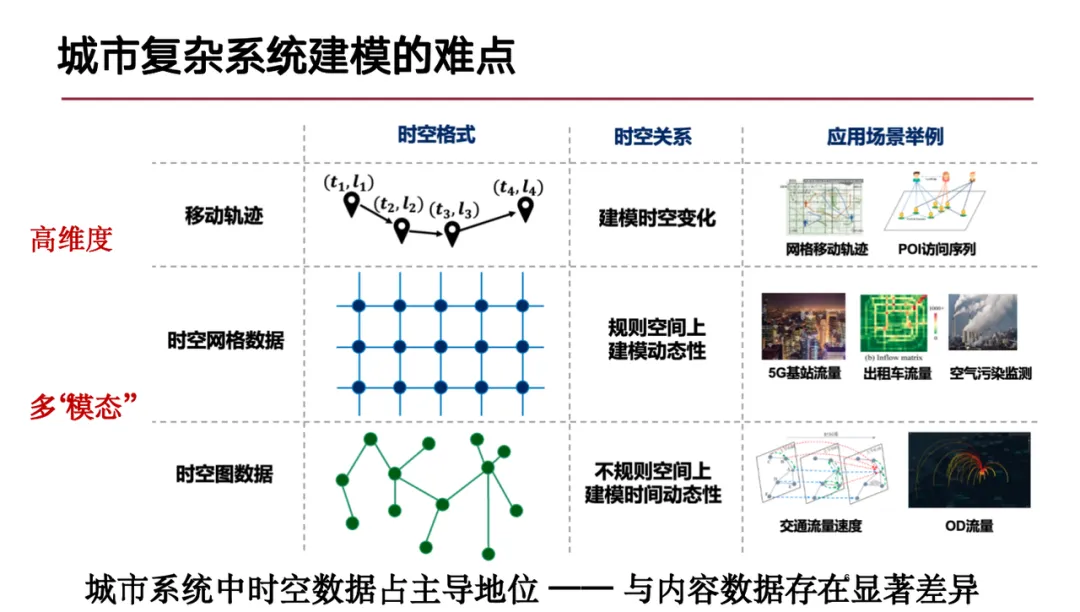
其次,从城市复杂系统的视角看,城市是一个巨系统,是由多个子系统构成的系统。这些子系统内部具有复杂的交互关系,且不同子系统间(如电力系统和通信网络系统)存在一定的耦合。这些子系统的相互依存性和复杂交互对建模提出了更高要求。

最后,城市系统内部是一个动态过程,不同的子系统能够收集到各种各样的数据,并且这些数据形式、模态及分布不同,导致难以通用建模,这也是当前研究阶段难以克服的问题。
基于上述挑战,今天我将介绍我们在以下 3 个方面的研究进展:首先是人流移动的模拟,我们提出了物理知识指导的扩散模型,以更精确地推演人在城市中的移动;其次是复杂系统韧性预测;最后是通用时空预测模型。
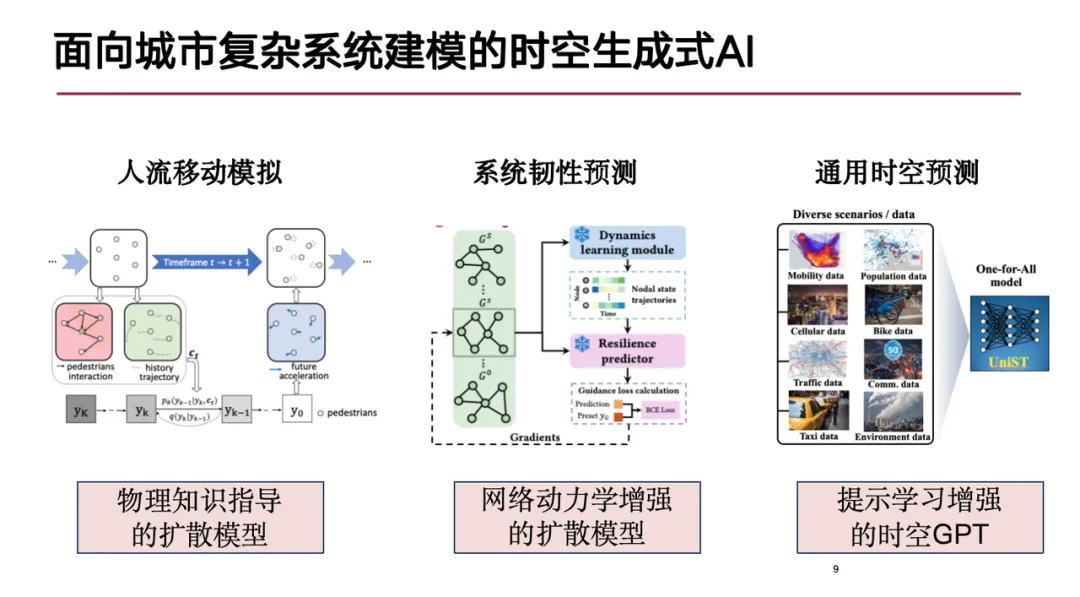
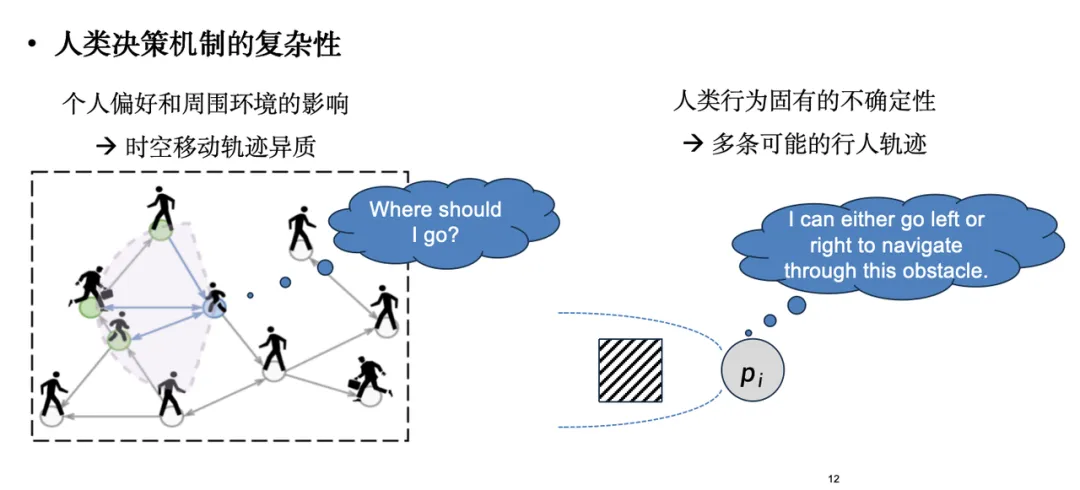
人流移动模拟旨在再现大量行人在空间中的动态移动和交互过程,其核心问题是:给定行人或个体的起点和终点,生成其在移动过程中的轨迹。这一模拟在众多应用场景中具有重要价值,如游戏中虚拟角色 (NPC) 的路径规划和现实生活中建筑物设计的可行性分析等等。为了检测建筑设计在特定场景下的表现,通常需要对大规模的行人流动进行仿真推演。

然而人流模拟的主要挑战在于,模拟对象并不是具有明确物理规律的分子系统,而是具有自主决策能力的个体——人类。人的决策机制复杂多变:一方面,个体的偏好会受到周围环境的影响,导致其决策不断调整;另一方面,人的行为具备固有的不确定性。例如,面对障碍物,不同的个体会选择不同的应对策略(有的选择向左,有的选择向右),这种不确定性难以用确定性的公式描述。
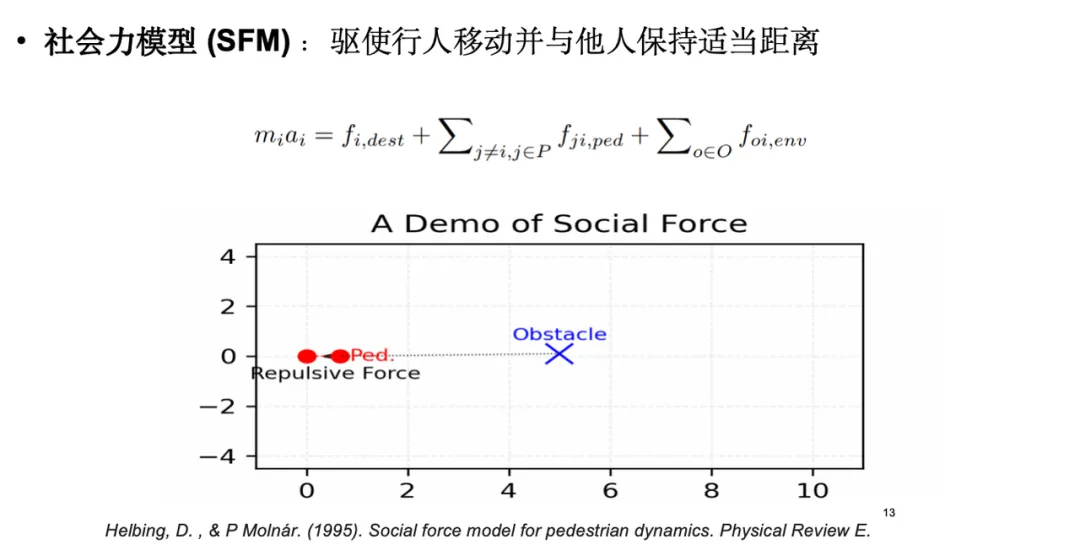
在实际应用中,最为广泛的一种人流模拟模型是「社会力模型」,源于牛顿力学中的思想,是基于 ABM (Agent-Based Modeling) 的经典方法之一。社会力模型将人类移动视作一种受力驱动的过程,如下图所示,个体在移动时不仅受到目的地的吸引力,同时还受到障碍物和周围行人的排斥力。然而,通过进一步观察可以发现,社会力模型在捕捉真实数据中的细微特征方面存在不足。
因此,我们探索如何结合生成式 AI 技术,将物理知识注入到扩散模型中。选择扩散模型的原因在于人类决策机制本质上具有不确定性,是一种概率生成过程,而扩散模型在高维数据分布建模中表现出色,适合用于此类不确定性问题的模拟。
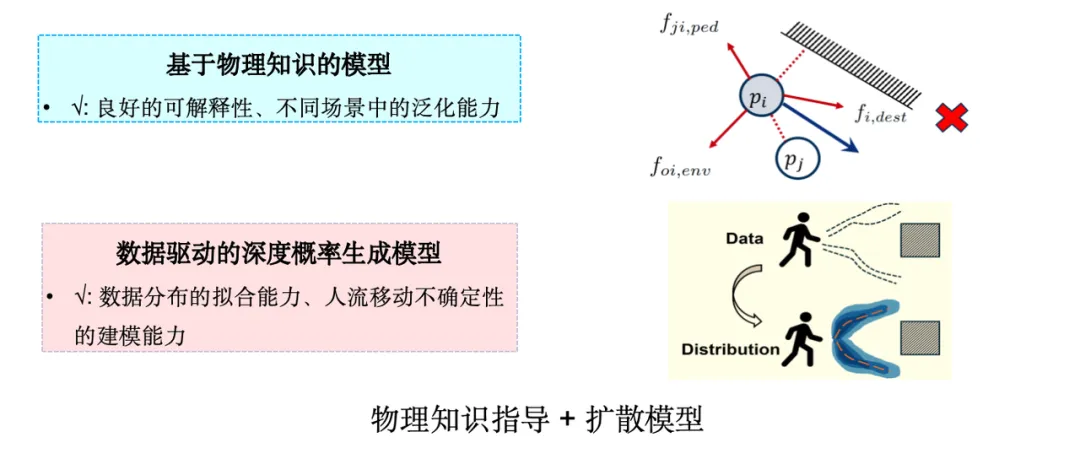
我们基于社会力模型设计了一种图神经网络,将社会力中的吸引力项和排斥力项纳入模型,提出了人流移动模拟模型 SPDiff。
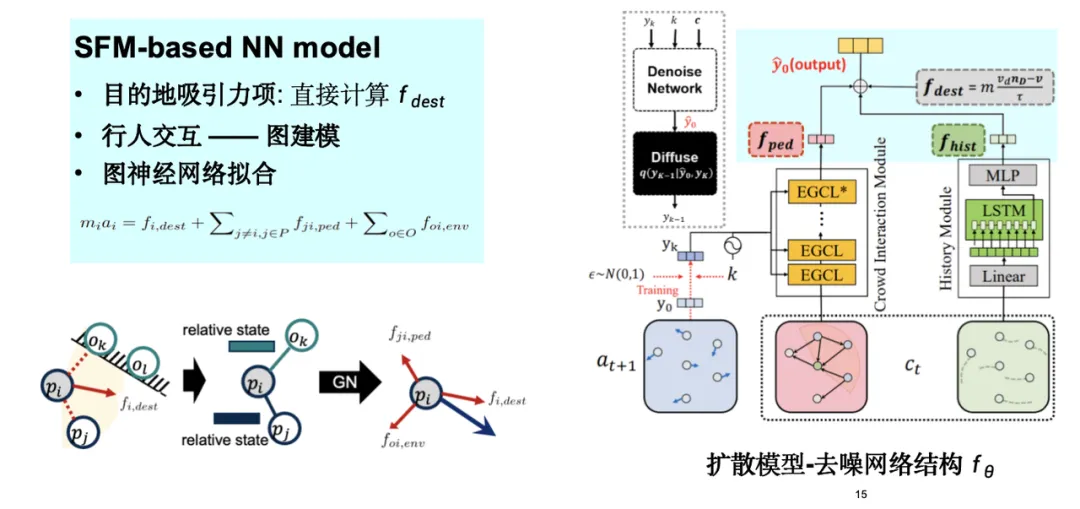
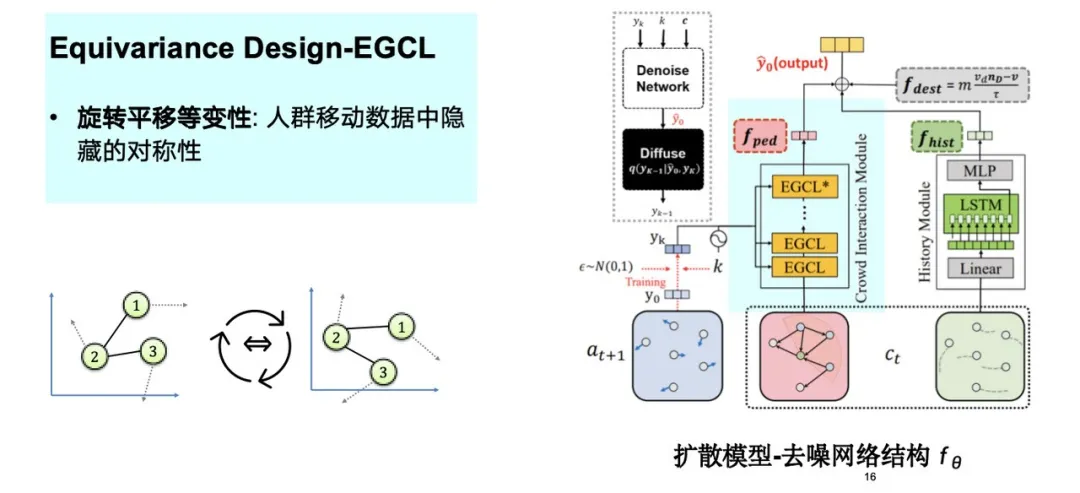
如下图所示,我们考虑了人群移动数据中隐藏的对称性——旋转平移等变性,将其融入到模型设计过程中,这种归纳偏差 (Inductive Bias) 的注入有助于优化整个模拟过程。
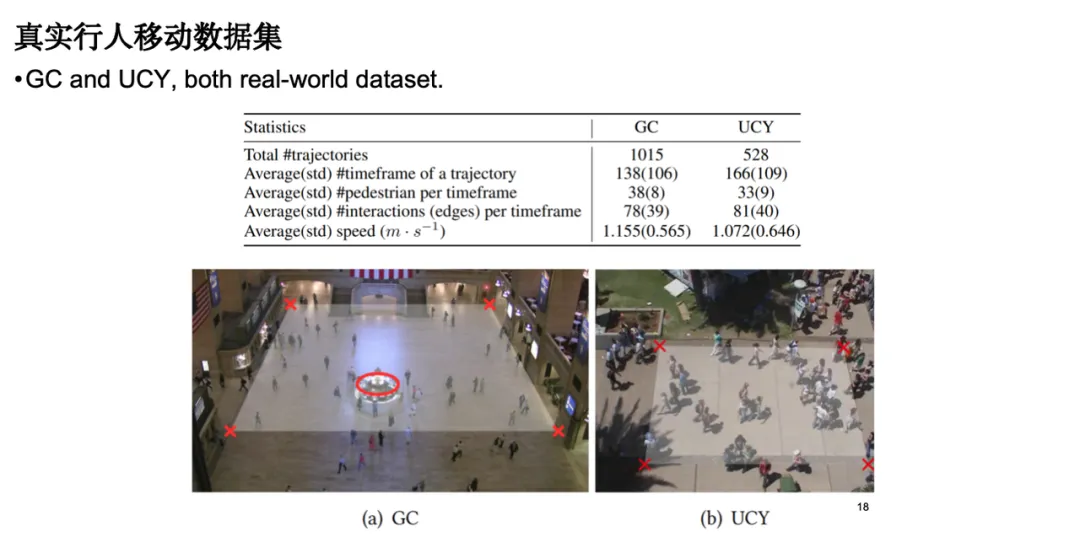
我们选择了真实行人移动的数据集对模型性能进行评估。数据来源包括车站广场和街道行人移动的监控数据。
模型评估中主要关注以下几类指标:首先是个体移动误差,即模拟生成轨迹与真实观测轨迹之间的绝对误差;其次是群体分布指标,即希望模拟生成的轨迹在分布层面上与真实数据接近。此外,我们还进行了可视化分析,结果显示,相较于经典社会力模型,我们的模型在障碍物避让效果上表现更为合理。值得一提的是,当我们引入物理知识后,模型参数量显著降低,优化了模型效率。

在进一步探讨物理知识的引入时,我们发现等变性赋予模型在小样本学习上的优势。正如前面讲到的,移动轨迹旋转平移后本质上具有对称性。因此,模型只需少量数据样本即可完成有效学习。实验表明,当训练数据量减少至 5% 时,模型效果依然接近完整数据集的表现。
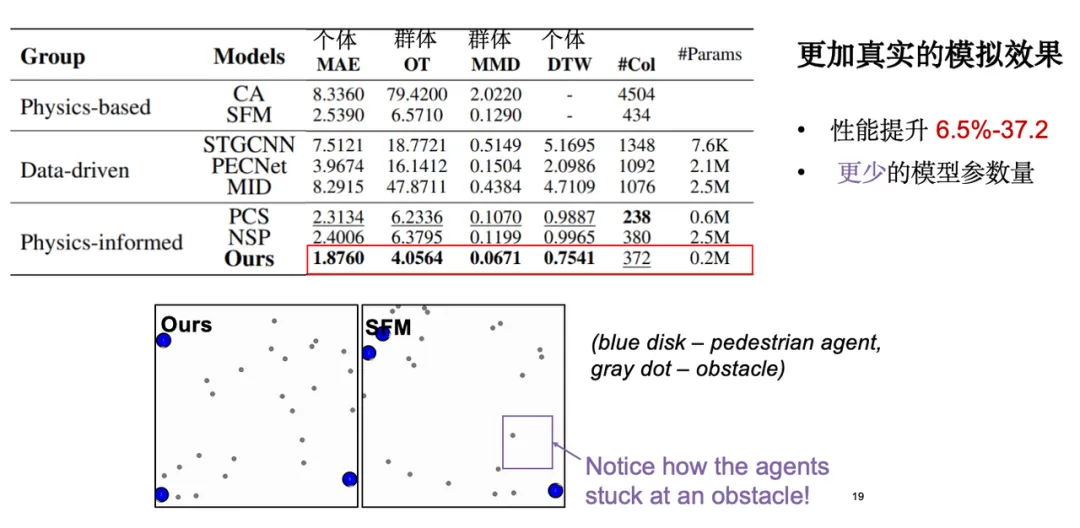
相关研究以「Social Physics Informed Diffusion Model for Crowd Simulation」和「Understanding and Modeling Collision Avoidance Behavior forRealistic Crowd Simulation」为题,分别发表于 AAAI 2024和 CIKM 2023,并且对代码和数据进行了开源。
论文地址:
https://arxiv.org/abs/2402.06680
开源项目地址:
https://github.com/tsinghua-fib-lab/SPDiff
论文地址:
https://dl.acm.org/doi/10.1145/3583780.3615098
开源项目地址:
https://github.com/tsinghua-fib-lab/TECRL
韧性是指系统在受到内部故障或外部干扰时,能够保持其基本系统功能的能力。例如,对于生态系统而言,韧性指的是在环境变化影响下维持生物多样性的能力。而在人类社会系统中,我们希望很多工程系统,如供应链网络,具备这样的韧性,以在特殊环境下确保生产者与消费者之间的正常产销关系,从而保持经济的正常运转。

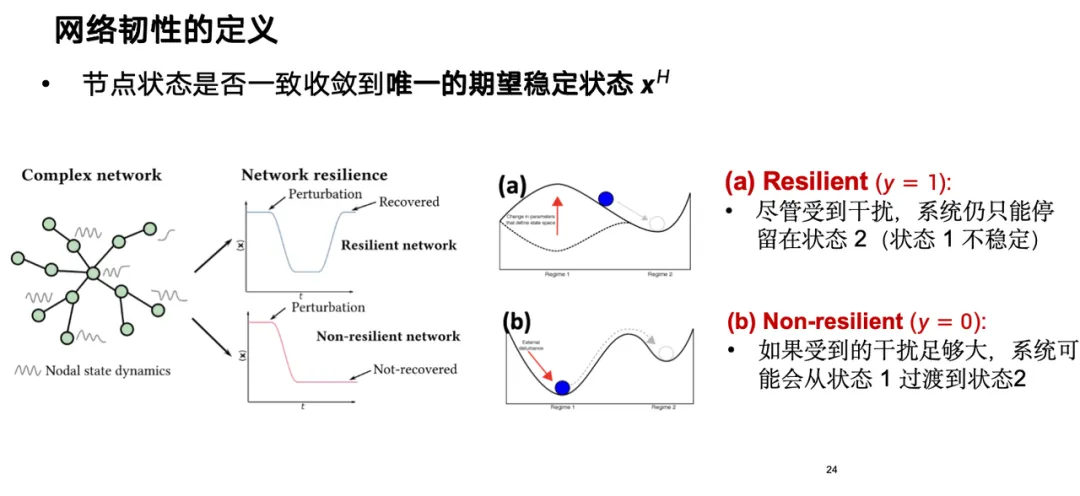
从理论上来看,网络韧性已有一些经典定义。韧性可视为一种节点状态,用 x 表示,反映出在对某节点施加扰动后,系统能否收敛到唯一预期的稳定状态。若系统具有韧性,即使受到干扰,仍可在一定时间内恢复到预期状态;若缺乏韧性,则难以恢复。如下图所示,韧性系统在干扰后可回到稳定状态,而非韧性系统可能无法恢复。
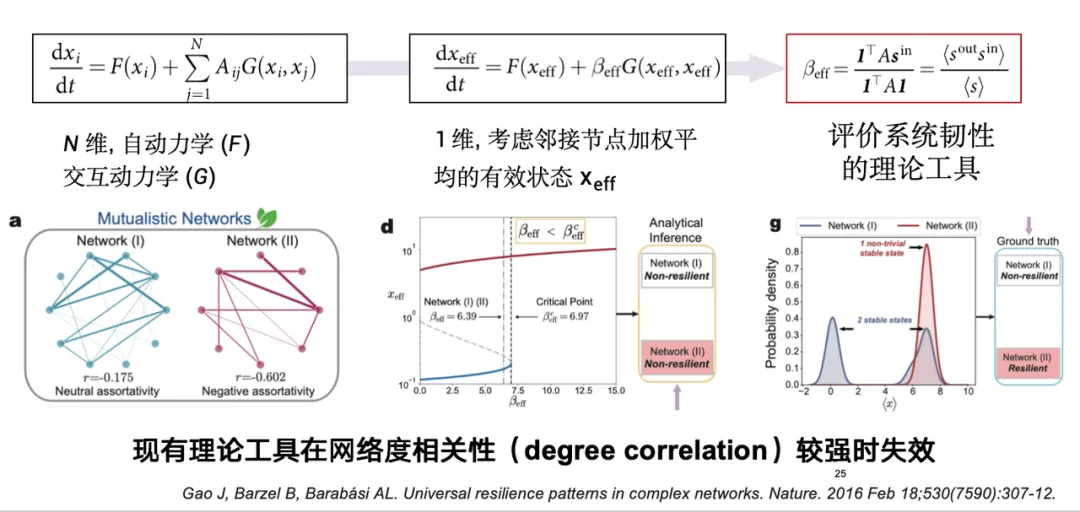
早在 2017 年,Nature 的一篇文章便提出了理论建模方法,本质上是研究一个 n 维的高维系统。这类系统的节点数可能达到数万甚至上百万。在理论上,这一方法通过降维,将高维系统简化为一维,以求得系统韧性的表达式。
然而,该理论工具在真实系统中存在局限性,只适用于度不太相关的系统。但真实系统中常存在同配异配效应,即由边连接的两个节点的度值可能高度相关,因此这个工具在评价实际系统的韧性时还存在一些问题。
论文地址:
https://www.nature.com/articles/nature16948
基于此,我们团队提出了一种数据驱动的网络系统韧性建模方法。正如之前所述,韧性受节点状态演化和网络拓扑结构的综合影响。通过数据驱动或机器学习的视角建模,我们将问题分为两个维度,一方面,节点状态的动力学变化过程由状态演化轨迹刻画;另一方面还需考虑网络拓扑的影响,两者共同作用造就了复杂系统的韧性,我们据此设计数据驱动的韧性预测模型。
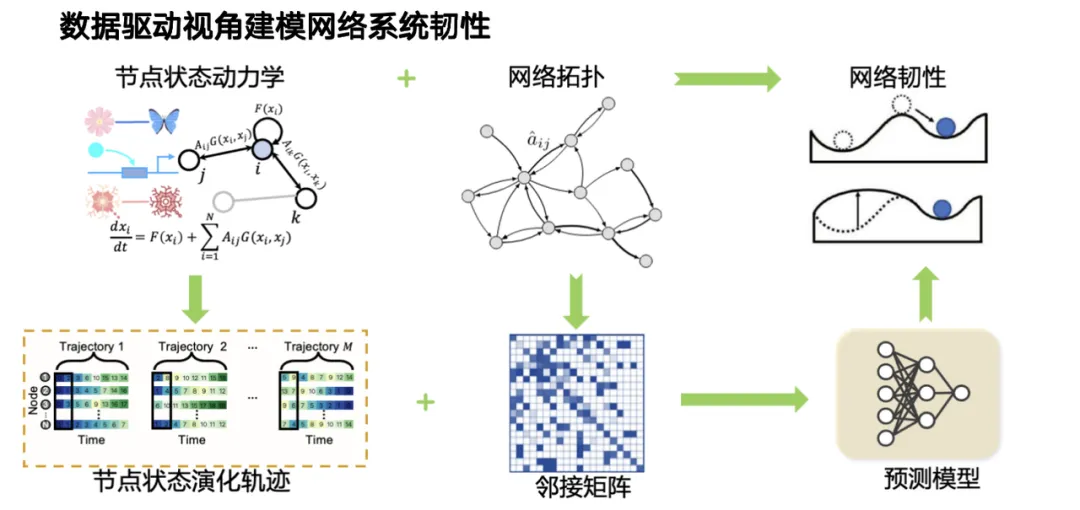
在模型架构上,我们设计了一种结合图神经网络和 Transformer 的结构:对于动力学演化部分,我们用 Transformer 来建模时序关系;对于复杂的拓扑关系,我们引入了图神经网络,建模系统之间高阶的相互作用。两者协同作用后,便构成了我们对系统韧性的观测。
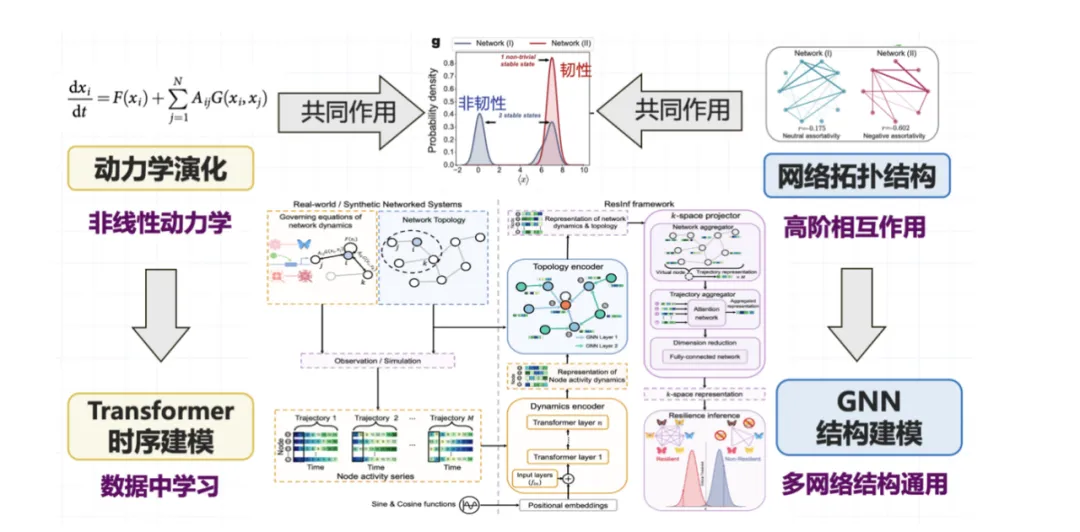
在实验中,我们考虑了多种节点状态动力学类型,如生态系统供应链、生物化学中的基因调控动力学、神经科学中的神经信号传递动力学等;在拓扑结构上,我们选用了经典的网络拓扑类型。
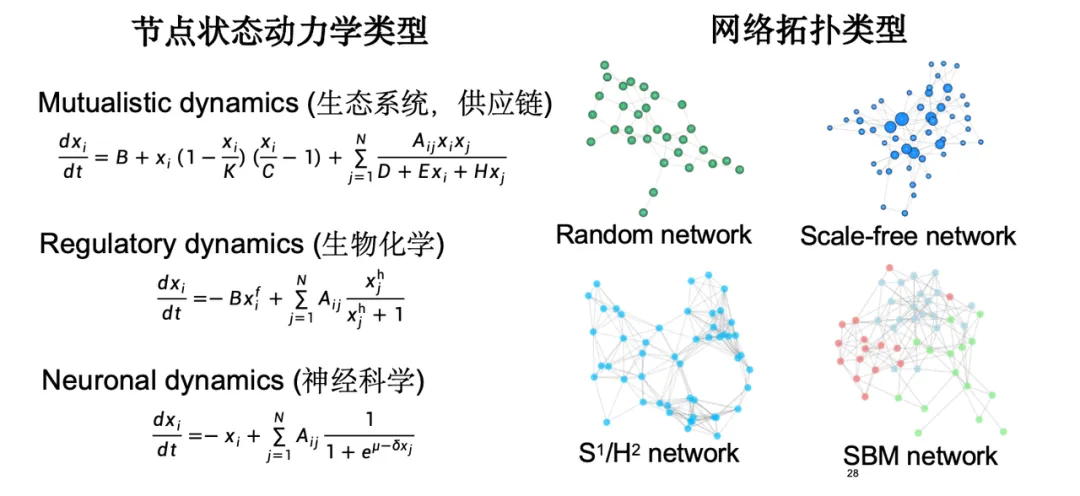
实验结果表明,我们的模型在预测精度上有显著提升,F1 分数较高,并具有一定的可解释性,实现了对决策平面的降维可视化。
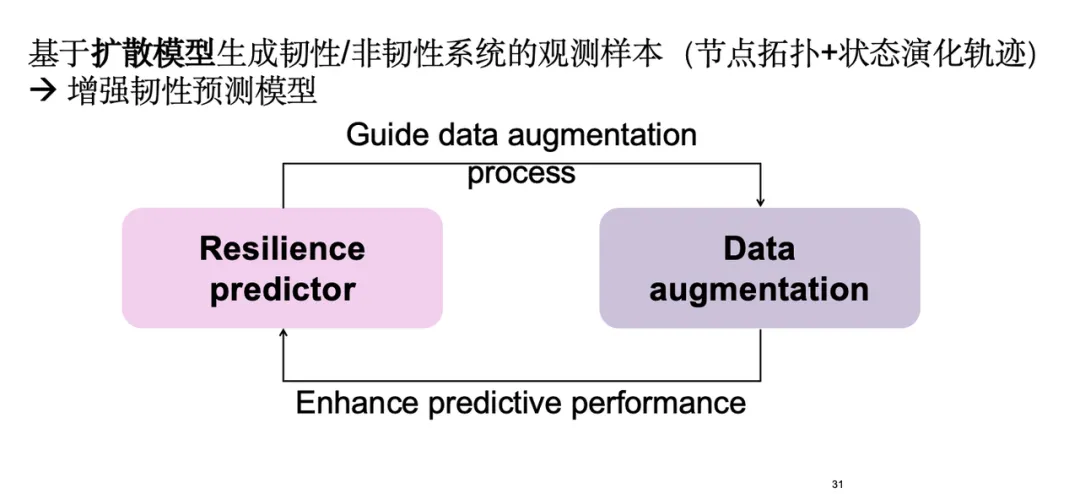
然而在实际应用中,我们发现绝大多数系统的韧性是未知的,难以判断其是否具有韧性,导致韧性标记数据不足,模型预测产生偏差。为此,我们从样本层面增强模型,使其在小样本情况下具备更高的鲁棒性。
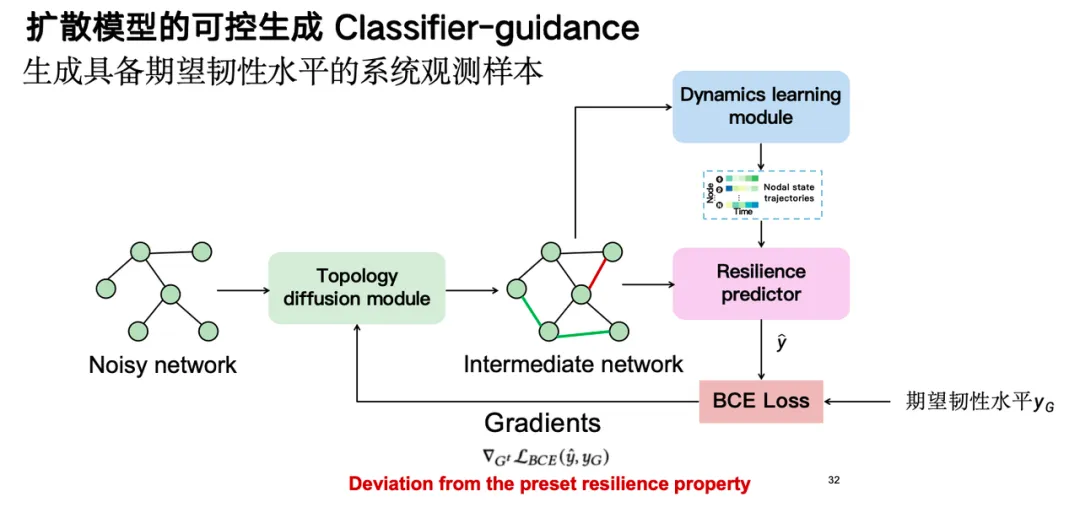
具体策略是基于扩散模型生成韧性和非韧性系统的观测样本以增强预测模型。这些样本涵盖节点拓扑及其状态演化轨迹。首先进行数据增强,增强后的样本可以更好地训练韧性预测模块,预测结果则反向指导数据增强模块,生成更有价值的样本,形成正反馈循环。
通过扩散模型的可控生成能力,即分类器引导 (Classifier-guidance) 技术 ,我们生成了具有期望韧性水平的样本,进而实现数据增强。
小样本测试结果显示,经过扩散模型增强后,仅使用 20 条样本,模型预测精度可达 87%;若不使用数据增强,模型预测精度仅为 62%。值得一提的是,我们在更短的状态演化轨迹观测长度下也能达到类似的预测精度,这对实际观测中无法进行长时间观测的系统具有重要意义。

相关研究以「Deep learning resilience inference for complex networked systems」和「TDNetGen: Empowering Complex Network Resilience Prediction with Generative Augmentation of Topology and Dynamics」为题,分别发表于 Nature Communications 和 KDD 2024,并且对代码和数据进行了开源。
论文地址:
https://www.nature.com/articles/s41467-024-53303-4
开源项目地址:
https://github.com/tsinghua-fib-lab/ResInf
论文地址:
https://arxiv.org/abs/2408.09825
开源项目地址:
https://github.com/tsinghua-fib-lab/TDNetGen
自 2017 年起,时空预测问题在深度学习领域逐渐受到关注。当前研究方法主要分为两类:一类基于具体数据类型或来源的时空特性,设计相应的深度学习模型;另一类是从复杂系统或应用数学角度出发,运用储备池计算等动力学系统方法进行建模。这两类方法的共同点是均针对单一子系统进行建模。
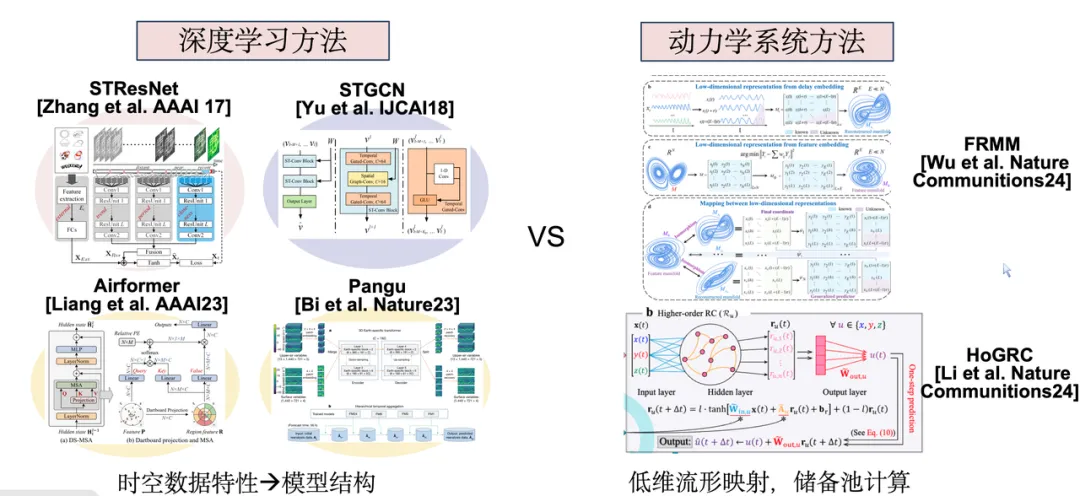
然而,针对城市系统,由于实际子系统之间存在高度关联,我们希望实现联合建模,以期达到 1 + 1 > 2 的协同效果。这也是我们研究工作的核心目标。
在此框架下,我们的设想基于这样的可行性:尽管不同类型的时空数据在组织形式与分布上各异,但本质上它们都来源于人类在城市中的生产生活,是某种底层通用机制在不同维度的体现。因此,只要能找到适当的方法,便可将这些异质数据进行融合,从而实现 1 + 1 > 2 的协同效应。
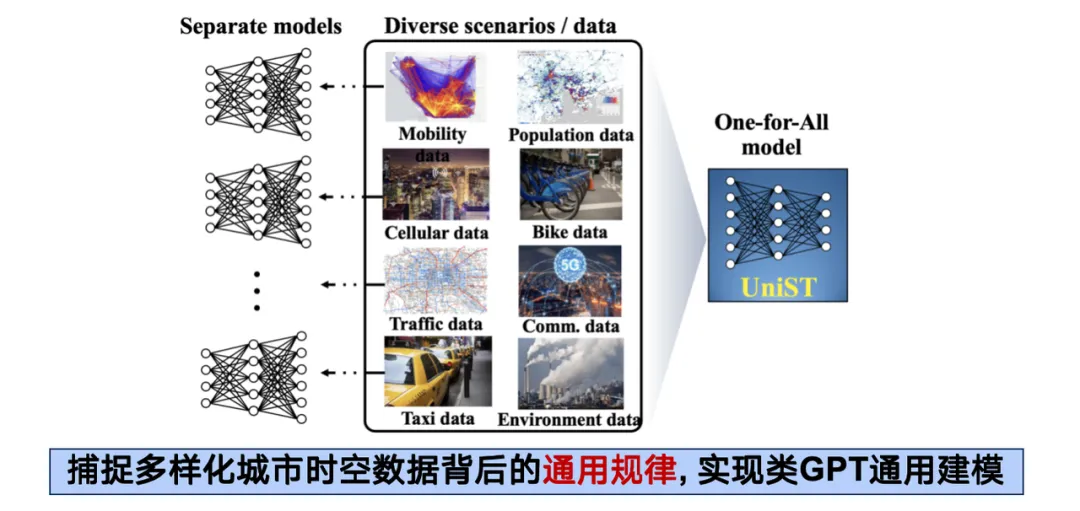
在实际操作中,我们收集了超 20 个时空数据集,超过 1.3 亿个样本点,涵盖交通、蜂窝网络、空气污染等 5 个子系统、 覆盖 14 个国内外城市。
在模型设计上,我们延续了 Transformer 的架构,将各种形态的时空数据建模为高维张量,采用类似 ViT (Vision Transformer) 的方式进行处理,最终形成通用时空预测模型 UniST。
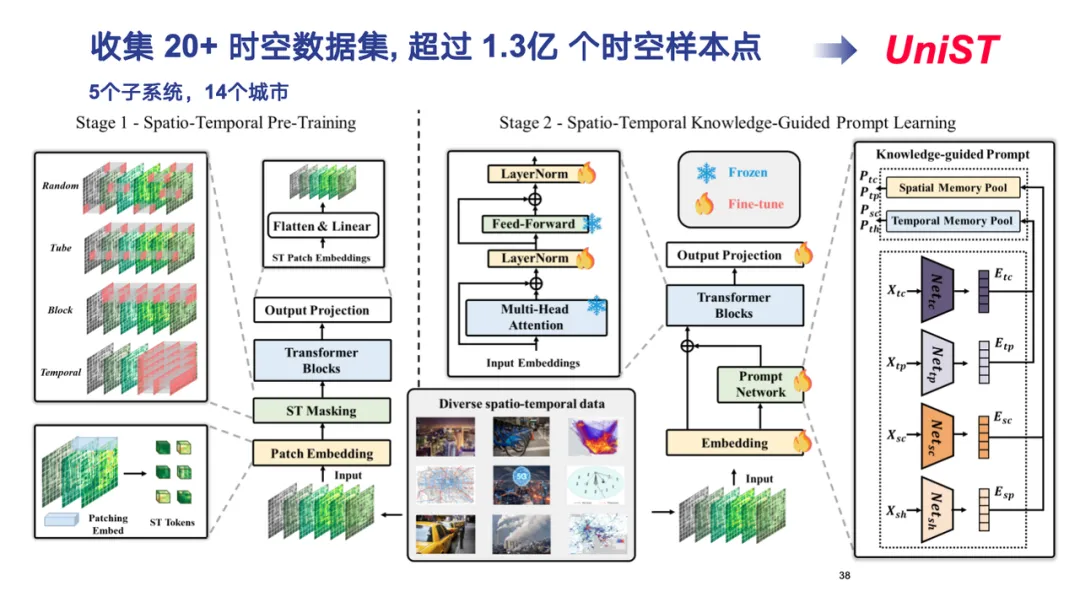
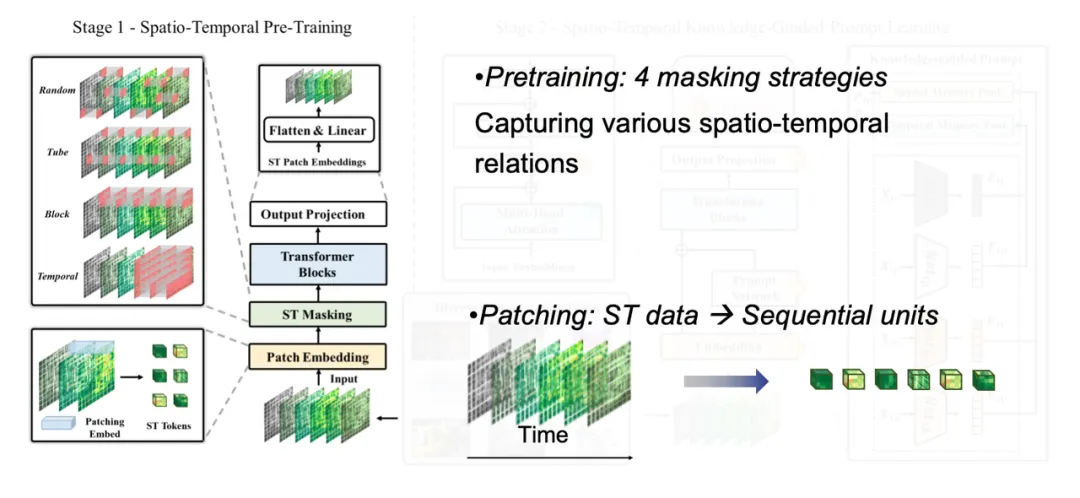
在模型训练的第一阶段,我们将各类时空数据进行 token 化处理,将高维张量分解为小方块,每个方块对应一个 token,并通过不同的 mask 策略来捕捉多样的时空关联特性。
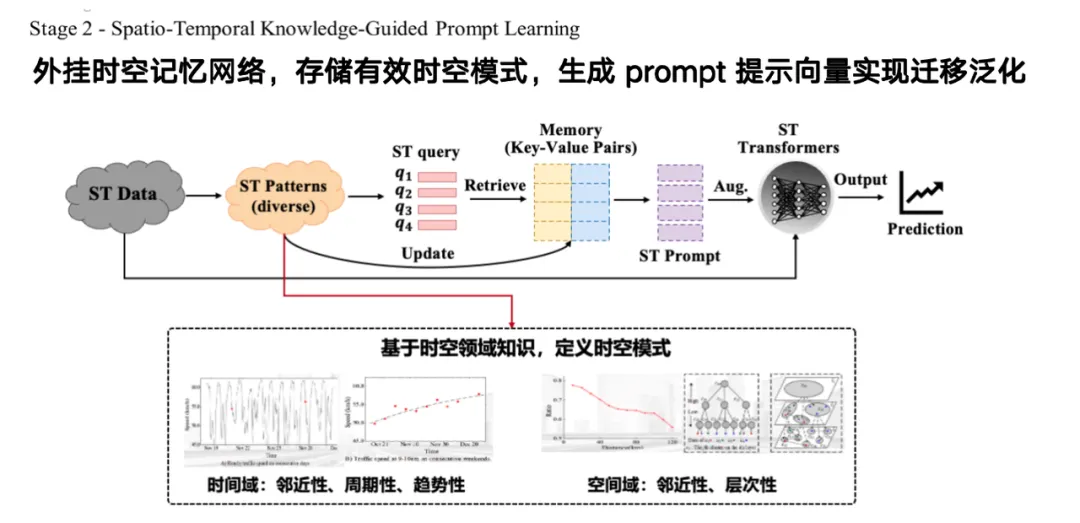
在模型训练的第二阶段,我们需挖掘不同形式的时空数据背后的通用规律。这里的「知识」指的是时空数据中普遍存在的经典演化模式,如时间上的邻近性、周期性和趋势性,以及空间上的邻近性与层次性。通过提取这些时空领域知识并定义相应模式,我们将真实数据降维到若干模式空间,并在海量数据上进行预训练。这样,当处理新的数据时,模型可快速匹配到相应模式,用类似 RAG 的方式,实现小样本甚至零样本的精准预测。
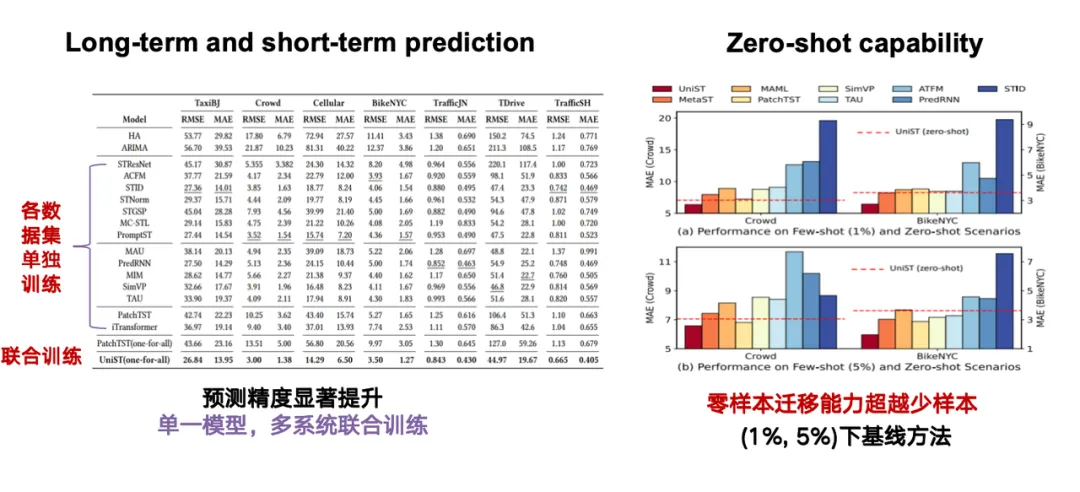
在评估模型效果时,我们主要关注两项任务:首先是长时和短时的预测能力;其次是最关键的 Zero-shot 能力,即模型在没有接触过特定任务或数据的情况下,直接处理该任务的能力。举例而言,若模型基于北京的数据集进行训练,那么对未包含在训练中的上海数据,模型仍能基于上海的时空序列实现精准预测。
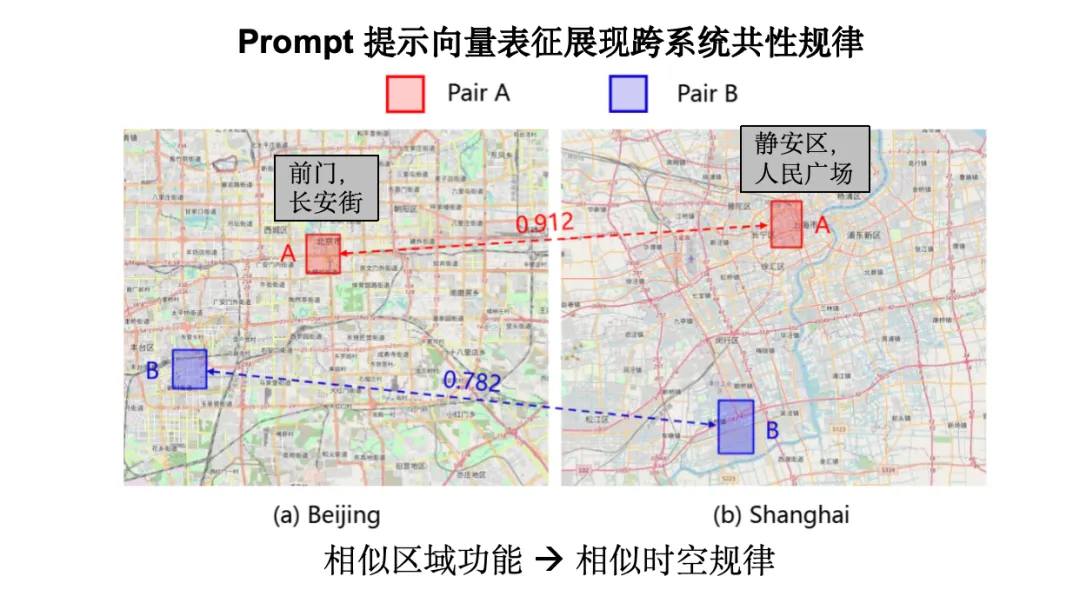
如下图所示,红色虚线代表了我们的方法在零样本条件下的预测效果,最左侧红色矩形展示了我们方法在 1%/5% 样本条件下的预测结果,其他为基线方法。可以看到,我们的方法在零样本迁移方面显著优于使用 1%/5% 样本的基线方法。
为何会出现这种效果?通过图中对比北京与上海数据的相似度可以发现,北京长安街和上海静安区的数据在 Prompt 计算后相似度很高。这种高度相似性解释了模型在未经过上海数据训练的情况下,依然能够基于北京数据的训练形成类似的预测模式。
我们还探索了时空数据在 Scaling law 方面的表现,即增加数据量是否会显著提升模型能力。然而,由于现有数据量和数据类型的限制,我们暂未观察到明显的 Scaling 效应,这方面尚需进一步丰富数据种类。

相关研究以「UniST: A Prompt-Empowered Universal Model for Urban Spatio-Temporal Prediction」为题,入选 KDD 2024 上。
论文地址:
https://arxiv.org/abs/2402.11838
开源项目地址:
https://github.com/tsinghua-fib-lab/UniST
最后,我想探讨城市复杂系统建模的未来方向和我所在团队(清华大学电子系城市科学与计算研究中心)的最新进展。
我们认为可以进一步结合物理知识,以提升模型的鲁棒性与泛化能力。对于城市中众多机制探寻尚不充分的系统,可以综合利用符号回归、网络动力学推断等方法,尝试从真实数据中提炼描述系统演化规律的符号公式。

相关研究以「Learning Symbolic Models for Graph-structured Physical Mechanism」为题,发表在 ICLR 2023上。
论文地址:
https://openreview.net/pdf?id=f2wN4v_2__W
在大规模复杂网络领域,统计物理学中已有基于理论的降维工具,如重整化群,将其应用于真实大规模网络预测,帮助识别演化动力学的低维「骨架」,实现长时预测。这也是我们近期的研究重点。

相关研究以「Predicting Long-term Dynamics of Complex Networks via Identifying Skeleton in Hyperbolic Space」为题,发表在 KDD 2024上。
论文地址:
https://arxiv.org/abs/2408.09845
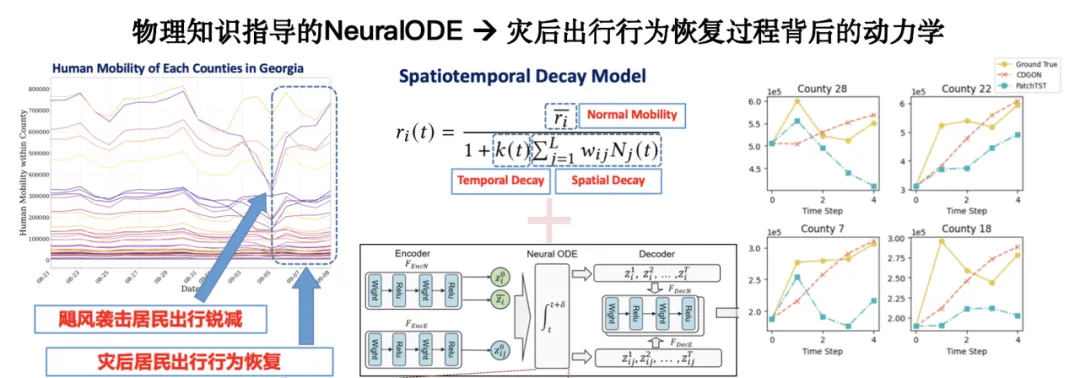
此外,引入物理知识以支持小样本学习,将显著增强模型的泛化能力。以灾后应急为例,该场景的历史数据匮乏,但已有一些学者从机制角度构建了灾后人类行为的动力学方程。将这些方程与真实数据模型结合,可在样本有限情况下实现更鲁棒的预测。
相关研究以「Physics-informed Neural ODE for Post-disaster Mobility Recovery」为题,发表在 KDD 2024 上。
论文地址:
https://dl.acm.org/doi/10.1145/3637528.3672027
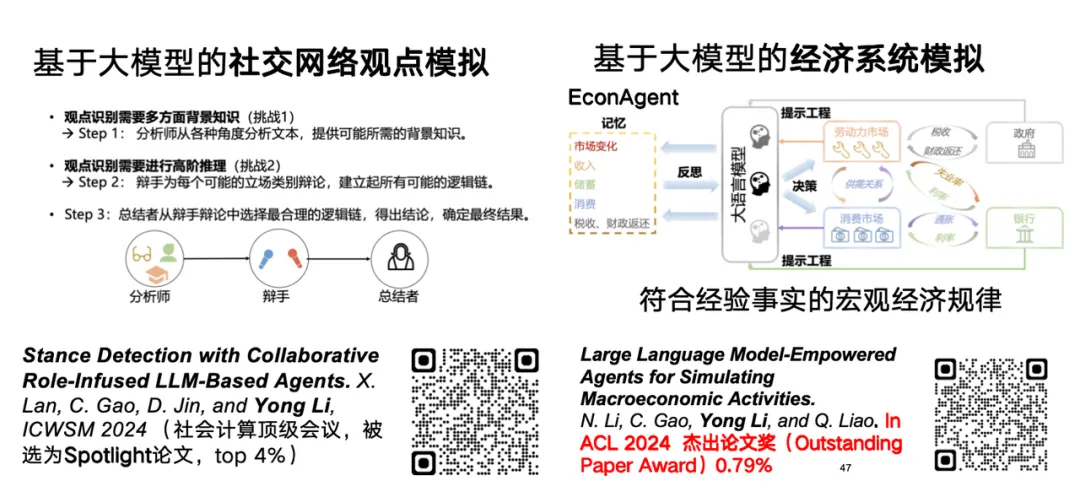
我们还认为,大语言模型在时空数据领域具有推理与模拟潜力。例如,可用大语言模型模拟网络观点或经济系统。对于大语言模型模拟网络观点的研究,相关论文以「Stance Detection with Collaborative Role-Infused LLM-Based Agents」为题,发表在 ICWSM 2024 上。
论文地址:
https://arxiv.org/abs/2310.10467
对于大语言模型模拟经济系统的研究,我们用大语言模型 Agent 有效模拟了符合经验规律的宏观经济模式,相关研究以「EconAgent: Large Language Model-Empowered Agents for Simulating Macroeconomic Activities」为题,获得 ACL 2024 杰出论文奖。
论文地址:
https://arxiv.org/abs/2310.10436
由于大语言模型基于大量人类生成的语言数据训练,具备类人的推理与决策能力,因此我们团队正探索其在生成或模拟人类行为上的应用。相比传统基于生成模型的方式,借助大模型预训练知识,我们发现仅需200条样本便可获得10万训练样本的类似效果,实现在特定场景中的快速泛化。
相关研究「Chain-of-Planned-Behaviour Workflow Elicits Few-Shot Mobility Generation in LLMs」已上传预印网站 arXiv。
论文地址:
https://arxiv.org/abs/2402.09836
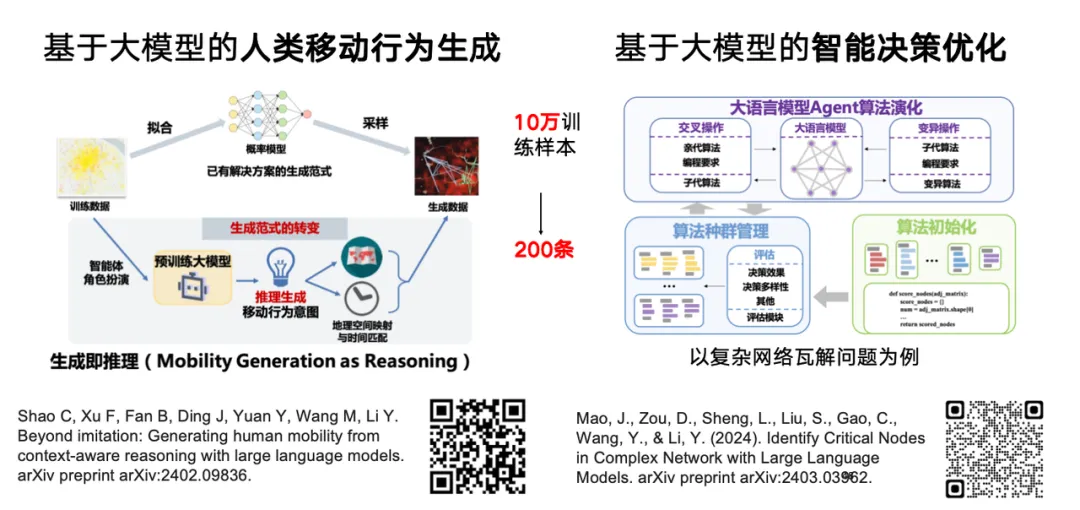
我们团队还在探索大语言模型是否能进一步用于智能决策优化,相关研究「Identify Critical Nodes in Complex Network with Large Language Models」已上传预印网站 arXiv。
论文地址:
https://arxiv.org/abs/2403.03962
本次的分享嘉宾丁璟韬博士来自清华大学电子工程系城市科学与计算研究中心 (FIB LAB)。研究中心聚焦于城市科学与计算研究方向,以城市科学为基础研究问题,基于复杂系统、计算社会学等理论展开研究,结合数据科学、机器学习的新一代「认知人工智能」为核心技术,服务于城市孪生、城市治理、无线网络孪生等面向国家重大需求的应用领域。团队现有教师 6 人,学生 60 余人。
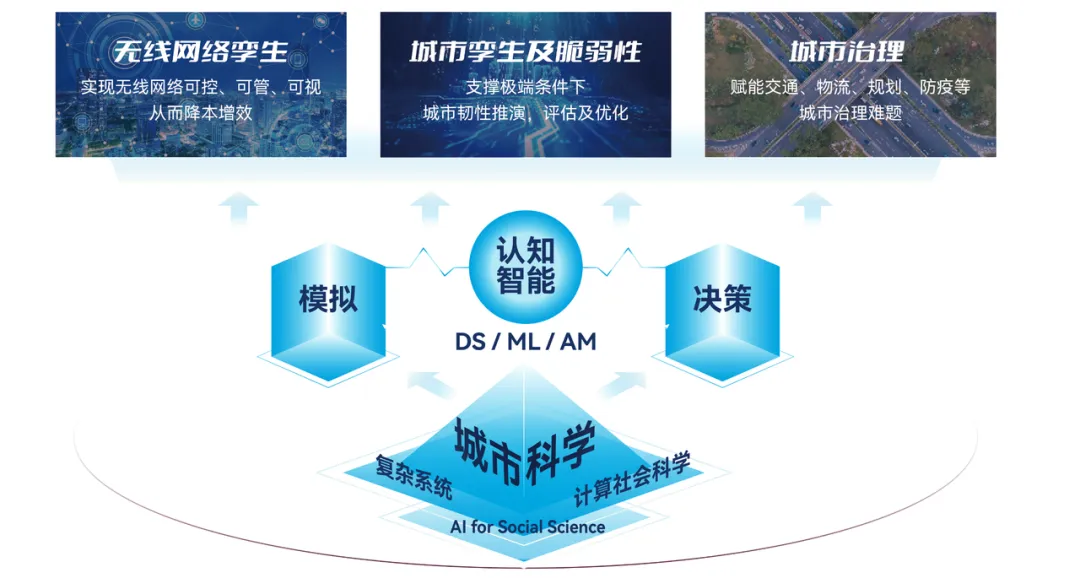
团队在 Nature 子刊等顶级国际期刊与 KDD、NeurIPS、WWW、UbiComp 等顶级国际会议发表学术论文 150 余篇(子刊 7 篇,CCF A 类 100 余篇),文章引用 25,000 余次,7 次获国际会议最佳论文/提名奖。团队主持或参与科技部重点研发计划、国家自然科学基金等项目 15 余项,相关成果荣获国家科技进步二等奖。
研究中心始终秉持着产学合一的方式,近年来与华为、腾讯、阿里、微软亚研院、美团、快手、高德、商汤、丰田以及移动运营商等企业建立了良好的合作关系,有丰富企业合作与实习机会。
实验室主页:
https://fi.ee.tsinghua.edu.cn/
个人主页:
https://fi.ee.tsinghua.edu.cn/~dingjingtao/
文章来自于微信公众号“HyperAI超神经”,作者“ 丁璟韬,李姝”



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
