# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文主要介绍来自该团队的最新论文:ToolVQA: A Dataset for Multi-step Reasoning VQA with External Tools。
本文提出了一个旨在提升基础模型工具使用能力的大型多模态数据集 ——ToolVQA。现有研究已在工具增强的视觉问答(VQA)任务中展现出较强性能,但在真实世界中,多模态任务往往涉及多步骤推理与功能多样的工具使用,现有模型在此方面仍存在显著差距。
为弥补这一空缺,ToolVQA 共包含 2.3 万条样本,覆盖真实图像场景与隐式多步骤推理任务,更贴近真实用户交互需求。我们提出了一种新颖的数据构建流程 ToolEngine,通过深度优先搜索(DFS)与动态上下文示例匹配机制,模拟人类工具使用过程中的推理链条。该数据集涵盖 10 种多模态工具与 7 类任务领域,每条样本平均涉及 2.78 步推理。在 ToolVQA 上微调后的 7B 模型不仅在测试集上表现优异,还在多个分布外(OOD)基准数据集上超越了闭源大模型 GPT-3.5-turbo,展现出良好的泛化能力和实际应用潜力。
目前该研究已被 ICCV 2025 正式接收,相关代码与模型已全部开源。

本文提出了一种全新的多模态视觉问答数据集 ——ToolVQA,通过真实世界任务与复杂工具链模拟,为大模型提供系统化、多步推理的训练与评估基准。当前,将外部工具集成进大模型(Large Foundation Models, LFMs)已成为提升其复杂任务处理能力的重要方向。借助外部工具,模型可以将难题拆解为更小的子任务,交由特定功能的工具处理,从而实现更强的泛化与执行力。
虽然已有研究在视觉问答(VQA)中引入工具使用机制,并取得了一定成果,但最新的多个基准测试表明:当前模型在真实世界的多模态、多功能、多步骤任务中,工具使用能力仍存在明显短板。例如,真实用户在交互中往往提出语义隐含、信息模糊的问题,解决这类问题需要模型综合使用多个工具,提取图像、文本和外部知识中的多源信息,构建连贯的推理链,而这正是当前主流模型难以胜任的挑战。
通过微调方法可以增强大模型的工具使用能力,但已有的数据集常存在两类问题:
一是图像场景大多为合成内容,缺乏真实世界背景的复杂性与不确定性;二是任务设计趋于模板化,问题过于简单,或直接在指令中提示要使用哪种工具,难以覆盖真实人类问题的隐式推理特性,进而限制了模型在实际应用中的迁移能力与评估效果。
针对这一问题,本文提出 ToolVQA 数据集,它由数据合成引擎 ToolEngine 生成,具有以下关键特性:
1. 全自动生成:仅需输入一张图片即可生成高质量 VQA 实例,不需要任何人工标注,显著降低数据成本,具备规模化潜力;
2. 真实世界图像与语境:覆盖新闻图片、电商场景、考试题图等多源复杂图像类型,任务语义贴近真实用户行为;
3. 隐式多步推理链:每个问题都需模型自主规划工具调用顺序,通过多轮交互完成任务,而非显式提示;
4. 丰富的工具种类与功能组合:涵盖 10 类典型工具,支持从文本提取、图像理解、数值计算到图表绘制与搜索生成;
下面的图 1 可视化了 ToolVQA 与先前数据集在真实世界设定下的差异。

图 1 ToolVQA(右)的真实世界设定包括:(1) 具有真实世界语境的复杂视觉场景;(2) 具有隐式多步骤推理过程的挑战性查询。相比之下,现有数据集(左)无法满足这些要求。
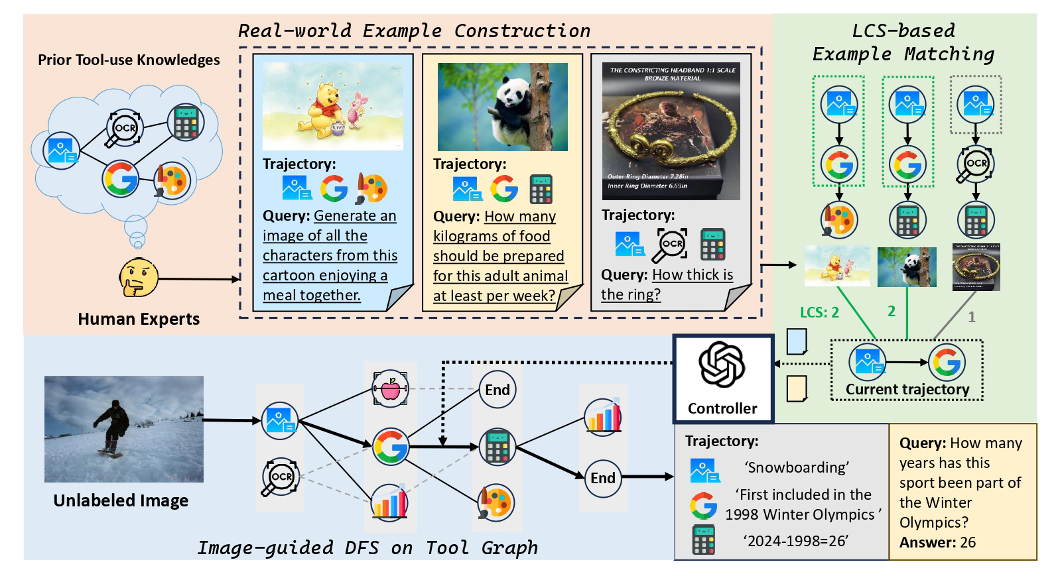
图 2 ToolEngine 数据合成框架
为克服现有 VQA 数据集 “模板化、静态化、浅层化” 的构建弊端,ToolVQA 背后的关键技术支撑 ——ToolEngine,提出了一种模拟人类问题解决流程的自动数据构建框架,使得每一条数据不仅贴合真实视觉任务,还具备可解释的多步工具使用路径。
ToolEngine 从无标注图像出发,围绕 “如何合理调用工具解决复杂问题” 这一核心展开,依托以下三个关键机制完成数据合成:
1. 图像引导的深度优先搜索(Image-guided DFS)
ToolEngine 首先将图像输入构建为推理图搜索的起点。在多模态工具图上,系统通过深度优先策略依次选择调用工具,并执行实际推理操作。每个步骤不仅包括工具名称的选择,还包含参数构造与调用结果解析,从而生成逻辑连贯、目标导向的推理轨迹。与以往 “单步调用 + 答案附加” 的方式不同,ToolEngine 要求每一工具步骤都必须对后续任务产生实质性影响,确保推理链条具有严密的因果逻辑。
2. LCS 动态示例匹配机制(Longest Common Subsequence Matching)
为克服模板方法在生成路径组合上的局限,ToolEngine 引入一种基于最长公共子序列的动态匹配机制。它从专家构建的人类多步骤工具调用与推理的示例中,选出当前轨迹最相关的多个参考示例,并据此指导下一个工具的选择与参数生成。该机制避免了以往固定模板中 “匹配不上就失败” 的问题,使得系统能够自动调整路径、灵活组合操作,展现出更接近人类直觉的思维迁移能力。
3. 问题构造与答案提炼机制
在完成完整的工具轨迹后,ToolEngine 使用语言模型生成最终的问题 - 答案对。为了确保查询具备 “隐式多步性” 和 “真实场景相关性”,ToolEngine 强制要求问题不能直接暴露推理线索,例如不能出现 “请使用 OCR 识别” 等显性提示;同时,答案必须来自最后一步工具调用结果,而非任意图像描述或常识补全。此外,系统还会尝试将部分答案转化为图像(如图表、绘图等),进一步丰富数据的模态多样性。
为确保数据质量,ToolVQA 的训练集通过人工抽检验证,结果达到了 90.8% 的准确率。测试集由专家重标,综合考虑图文对齐性、工具路径有效性与答案合理性等多个维度。
ToolVQA 数据集共包含 23,655 个任务样本,每条样本由五元组构成,包括图像、工具集、自然语言查询、最终答案及完整的工具调用轨迹,支持文本与图像双模态输入输出。具体统计如下:
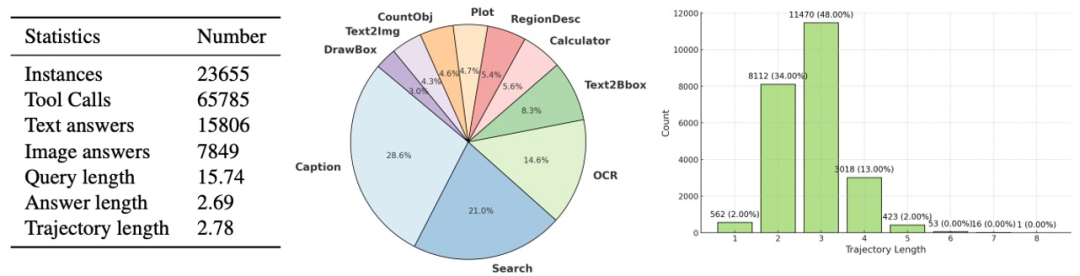
图 3 ToolVQA 统计数据
在实验评估中,ToolVQA 涵盖三种模型设定(VLM、VLM+tool、LLM+tool)与两种评估模式(端到端解答与逐步执行),系统测试了包括 GPT-4o、GPT-3.5、Claude-3.5、Qwen2、LLaVA 在内的主流大模型,以及在 ToolVQA 训练集上微调的 LLaVA-7B 模型。性能表现总结如下:
1. 在 ToolVQA 测试集上,微调后的 LLaVA-7B 性能显著超越 baseline,在五项重要评估指标中领先闭源大模型 GPT-3.5-Turbo;
2. 微调后模型在分布外(out-of-distribution)数据集(TextVQA、TallyQA、InfoSeek、GTA、TEMPLAMA)上也展现出出色的泛化能力,在多个数据集上超越 GPT-3.5-Turbo;
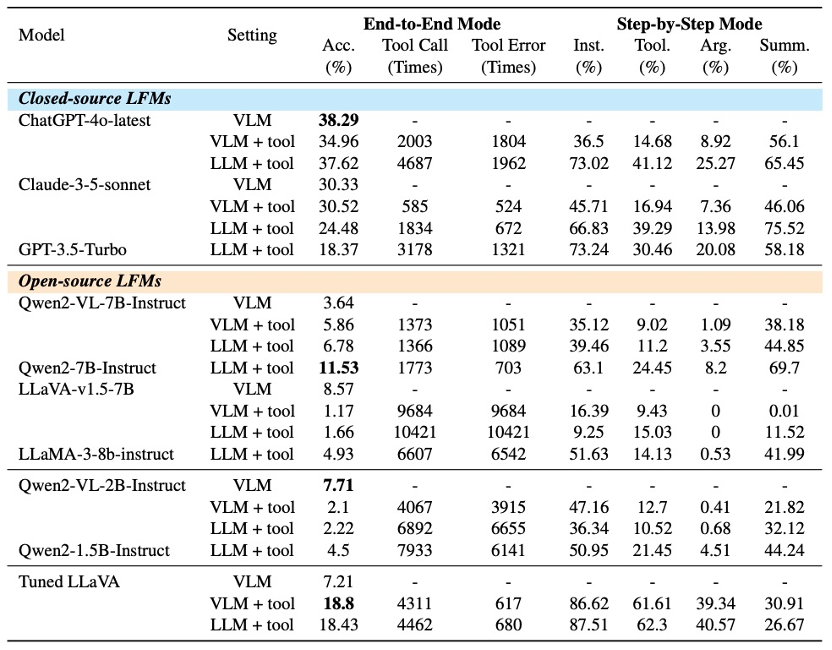
表 1 ToolVQA 实验结果。每列指标分别表示模型在 ToolVQA 测试集下的表现:Acc. 为最终答案准确率,Inst. 为工具调用成功率,Tool. 为工具选择准确率,Arg. 为参数生成准确率,Summ. 为最终答案整合准确率。图中对比不同模型(开源与闭源)在三种推理设定(VLM、VLM+tool、LLM+tool)下的能力。

表 2 分布外数据集实验结果。展示模型在五个分布外数据集(TextVQA、TallyQA、InfoSeek、GTA、TEMPLAMA)上的准确率表现。各数据集代表不同类型的跨模态任务场景,用于衡量模型的泛化能力。
此外,Few-shot 上下文学习实验显示,ToolVQA 上的微调模型依然能从小样本示例中获益,表明该数据集兼具 训练适应性 与 评估扩展性,可同时服务于监督学习和指令微调等多种研究范式。
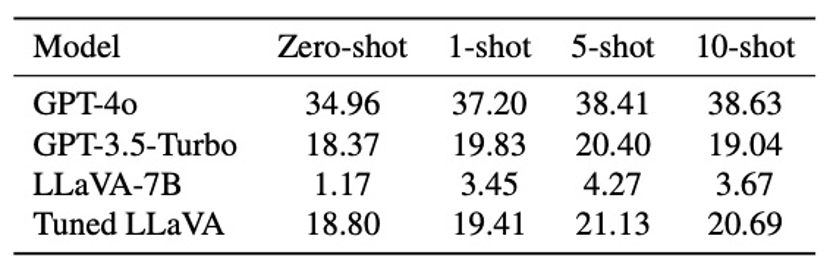
表 3 小样本上下文学习实验结果。展示四个模型(GPT-4o、GPT-3.5-Turbo、LLaVA-7B 及微调后的 LLaVA)在不同 shot 数(0-shot、1-shot、5-shot、10-shot)下的准确率变化。shot 数表示在模型回答问题前,输入上下文中提供的示例个数。
尽管微调后的模型在 ToolVQA 上表现出较强能力,但对错误样本的分析显示,当前模型在多步推理中仍存在关键瓶颈。我们对 100 个失败案例进行了分类统计,发现主要错误集中于以下两个方面:
1. 参数预测错误:模型在调用工具时常常遗漏关键信息,如在搜索 “马匹年龄” 问题中未包含关键词 “age”,导致工具返回无关内容。这表明模型在提取任务目标中的显式要素方面仍不稳定。
2. 答案整合错误:即使工具已返回正确内容,模型也可能错误地选择信息。例如,面对 “每日摄入量” 类问题,模型错误地将体重 “1,300 磅” 当作答案,而忽视了上下文中 “25 磅 / 天” 的正确数值。
进一步分析表明,多步推理任务中一旦早期出现失误(如工具选择或参数错误),后续步骤将受到累积干扰,最终导致整体推理失败。这类 “误差累积效应” 也是当前工具智能体设计中的一大挑战。
这些发现揭示出:当前大模型在面对动态反馈和中间信息整合时,尚不具备足够的鲁棒性,而 ToolVQA 提供了评估与改进此类能力的理想基准。

图 4 微调后模型的错误可视化
ToolVQA 是一个面向真实场景工具增强推理任务的大规模多模态数据集,涵盖 10 种典型工具和 7 个应用领域,包含 23K 条具备隐式多步推理链的任务样本。基于自动化数据生成引擎 ToolEngine,ToolVQA 构建了结构化的工具使用轨迹与高质量问题答案对,为模型的推理能力与工具理解能力提供了系统性训练与评估平台。
实验结果表明,ToolVQA 显著提升了微调后模型在复杂推理任务中的表现,不仅在测试集上超越 GPT-3.5,还在多个分布外数据集上展现出强泛化能力。进一步的错误分析指出,参数预测与答案整合仍是当前模型在工具使用任务中的关键瓶颈。
ToolVQA 不仅是一个数据集,更为多模态工具智能体的研究设立了评估标准和任务框架,为未来推动具备更强推理能力与泛化能力的通用智能体提供了坚实基础。
文章来自于微信公众号“机器之心”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
