# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
谷歌一出手,又把AI视频生成卷上了新高度。
一句话生成视频,现在在名为Lumiere的AI操刀下,可以是酱婶的:

如此一致性和质量,再次点燃了网友们对AI视频生成的热情:谷歌加入战局,又有好戏可看了。
不止是文生视频,Lumiere把Pika的“一键换装”也复现了出来。

左谷歌右pika,同样是选中区域一句话完成视频编辑,你pick哪一边?
让图片中静止的火焰跃动起来,也同样一选就能完成:

还有图片转视频:

视频风格化:

总之就是主打一个质量又高又全能。
更多细节,我们论文扒起~
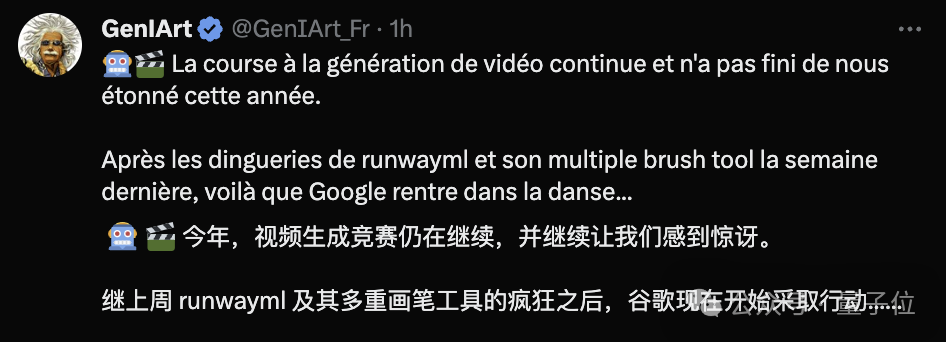
Lumiere旨在解决以往视频生成中存在的几个关键问题:
在此前的方法中,常见的做法是,扩散模型先生成一些稀疏的关键帧,而后通过一系列时间超分辨率(TSR)模型来填补关键帧之间的空白,接着再用空间超分辨率模型获取高清视频结果。
可以想见,在全局连贯性上,这样的做法存在先天的缺陷。
Lumiere的创新点在于,提出了时空U-Net(STU-Net)架构:将视频在空间和时间两个维度同时进行下采样和上采样,在网络的中间层得到视频的压缩时空表示。

具体来说,基于这一架构,模型能够一次性生成视频中的所有帧——这也就提升了生成视频的连贯性。
同时,因为大部分计算发生在压缩后的表示上,STU-Net能有效减少计算量,降低对计算和内存的需求。
另外,为了提升视频的分辨率,研究人员使用多重扩散(MultiDiffusion)技术,通过线性加权空间超分辨率网络来处理重叠时间窗口带来的边界伪影等问题,从而能将生成画面融合为一个整体,得到连贯、高清的视频效果。
时长和分辨率方面,Lumiere能输出1024×1024、16fps下长5秒的视频。
研究人员提到:
5秒已经超过了大多数视频作品中的平均镜头长度。
值得一提的是,得益于时空U-Net架构端到端全帧率视频生成的能力和高效计算,Lumiere灵活可扩展,可以轻松应用到下游任务中,包括文生视频、图生视频、视频风格化、视频编辑修复等等。

研究人员将Lumiere与其他文本-视频生成模型进行了实验对比。
首先来看人类用户的判断。
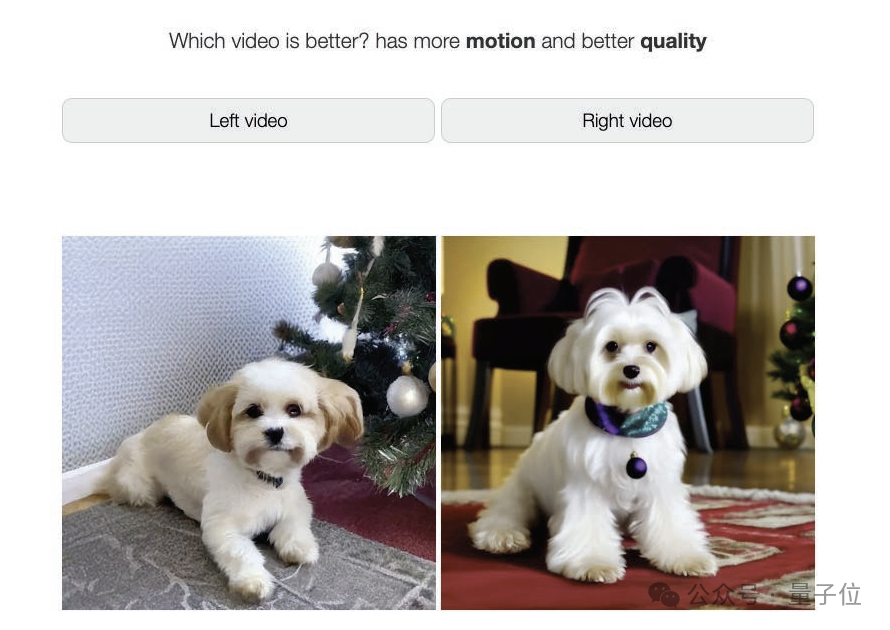
实验设计是这样的:志愿者会同时看到一对视频,一个来自Lumiere,另一个来自其他基线模型。志愿者被要求从中选出视觉质量、动态效果更好,更符合文本提示的视频。
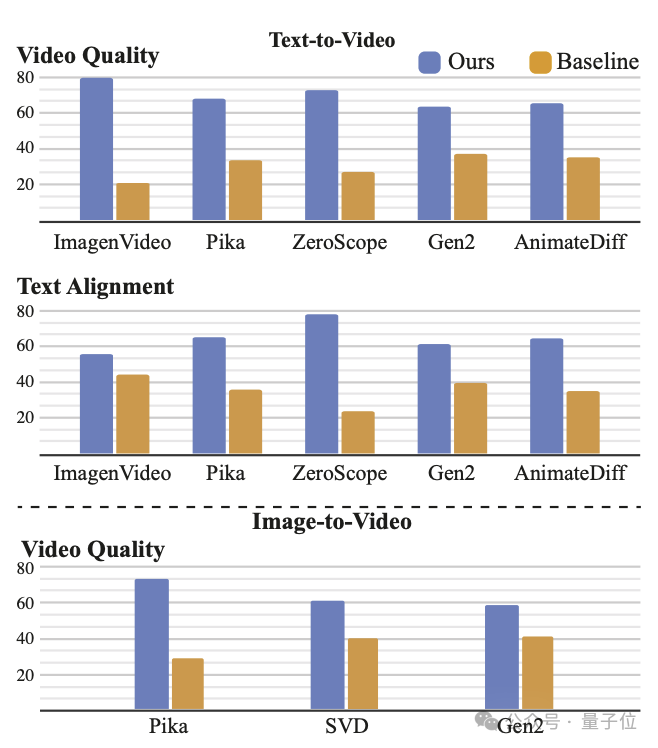
研究人员收集了大约400份反馈,结果显示,在视频质量、文本匹配度方面,Lumiere超越了Pika、Gen2、Imagen Video、SVD等一众顶级视频生成模型。
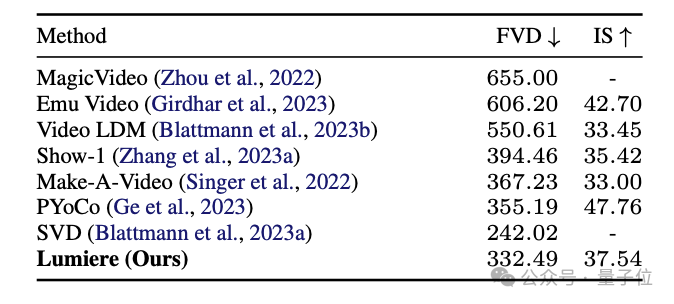
同时,在UCF101数据集(动作识别数据集)上,与MagicVideo、Make-A-Video、SVD等模型相比,Lumiere取得了具有竞争力的FVD和IS指标。
效果很惊艳,网友很兴奋,但桥豆麻袋……
这次,谷歌依然只放出了论文,没有试玩,更没有开源。
这种似曾相识的操作,把人快整麻了:
视频很不错,但是谷歌,你又不打算发布任何代码、权重,也不提供API了,对吗?

还有人想起了Gemini发布时那个造假的小蓝鸭视频……

那么,这波你还会看好谷歌吗?
论文地址:
https://arxiv.org/abs/2401.12945
项目地址:
https://lumiere-video.github.io/#section_video_stylization



