# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
LLM.265研究发现,视频编码器本身就是一种高效的大模型张量编码器。原本用于播放8K视频的现成视频编解码硬件,其实压缩AI模型数据的效率也非常高,甚至超过了许多专门为AI开发的方案。该工作已被世界微架构大会MICRO-2025正式接收,相关成果将于今年10月在首尔进行展示与讨论。
在大模型的发展历程中,提升参数规模已被多次证明是提升模型智能的最有效手段之一。
然而,随着模型参数量的增加,GPU内存容量和互联带宽已成为限制未来更大规模模型训练和部署的主要瓶颈。
在有限的硬件资源下,如何更有效地训练和推理更大规模的模型,已成为一个备受关注且具有显著经济价值的课题。
为应对这一挑战,压缩技术逐渐成为研究的重点,尤其是在大模型的训练和推理过程中,内存和通信带宽已成为最关键的瓶颈。
压缩技术通过减少数据量,直接缓解了系统瓶颈,使得压缩率的提升往往能直接转化为系统效能的增强。
模型压缩的巨大潜力吸引了大量研究者探索多种方法,致力于压缩大模型训练和推理过程中的各类张量,以提升整体效率。
来自杜克大学、卡耐基梅隆大学和香港科技大学的研究团队发现,视频编码器本身就是一种有效的张量编码器。

论文链接:https://arxiv.org/abs/2407.00467
代码链接:https://github.com/Entropy-xcy/llm.265
更重要的是,视频编解码器具备许多对于大规模模型系统至关重要的特性。
灵活的码率控制
传统的量化压缩方法通常局限于整数存储,这使得存储空间只能以整数位来控制(例如3bit、4bit每个元素)。然而,视频编解码器能够灵活控制码率,支持任意实数的位数(例如每个元素平均3.1415bit),从而更加高效地利用存储空间。
多种张量的压缩
传统的量化压缩算法通常只针对少数几种张量进行压缩。而LLM.265方法发现,视频编解码器在处理模型参数、激活函数、KV缓存、参数梯度和反向传播梯度等多个张量时,具有卓越的压缩效果。
通过使用统一的压缩算法对整个系统中的大部分张量进行压缩,极大地降低了AI系统的复杂度。
硬件支持
现有的GPU已自带视频编解码器,LLM.265可以直接利用现有GPU的硬件视频编解码单元加速张量压缩。
此外,视频编解码硬件的实现效率高且已有几十年的成熟经验,因此直接利用或调整视频编解码器进行张量压缩,对于大模型加速器的设计与实现是一种切实可行的方案。
视频编解码器是一个神奇的怪物。
时间x宽度x高度x色彩,最初在计算机上播放视频的工程师一定想不到,这个庞大四维视频张量,可以在几十年后做到在8K,240fps的分辨率下,在手掌大小的移动设备上通过无线网络播放。
诚然,摩尔定律提供了算力基石,然而除此之外更加难以置信的是,视频编解码器的发展,使得视频矩阵可以在被压缩几千倍的情况下,让人类视觉上几乎看不出和原视频的差别。
如今,在计算机体系结构领域的顶会中,大模型加速器是毫无疑问的兵家必争之地,是当今时代毫无疑问的「杀手级应用」。
殊不知,30年前体系结构领域也有一个「杀手级应用」,就是视频编解码!
可以说,30年前的视频编解码这个话题的卷的程度,丝毫不弱于当今的大模型加速器。
然而在这卷的过程中,视频编解码器和其硬件实现也已经被卷得优化到了极致,让今天做大模型加速和压缩的研究者回头望去,就好像历史在重演,让人不自觉的便要学习之前的经验。
然而视频编码器正是这么一个具象的经验,在大模型压缩领域的很多研究,都有意或无意的借鉴了许多视频编码器的工作流程,比如说DeepCompression的熵编码,QuaRot和QUIP#的正交变换,和MXFP的分组量化。
然而纵使借鉴,却未有人尝试直接利用视频编解码器,LLM.265改变了这一「灯下黑」的现状。
下面用两个更具体的例子抛砖引玉,展示视频编码器可以高效压缩张量的原理。
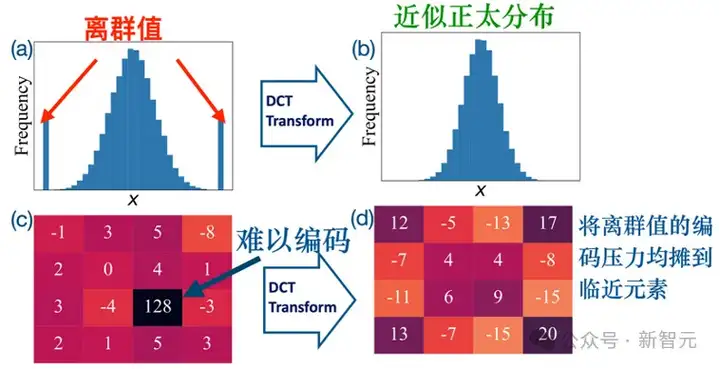
正交编码均摊离群值(Outlier)的编码压力
在信息论领域,高效压缩服从正态分布的数据早已涌现出众多成熟方案。
然而,对现代大模型而言,无论是权重还是激活,往往呈现「正态主体+离群值」的混合分布(见图a、c),既跨度大又要求对分布中心保持高分辨率。
这种「宽动态范围+高精细度」的双重需求让传统压缩/量化方法进退维谷:不是浪费大量比特覆盖离群值,便是牺牲中心区域精度,或直接截断离群值,结果都难以令人满意。
然而视频编解码器中的正交变化(如H.264中的DCT)为此提供了一条更为优雅途径。
有时候,模型参数中会出现一些特别大的数字,就像炒菜时放进一大块盐,如果没拌匀,整道菜就会忽咸忽淡。
而DCT(离散余弦变换)就像一把把盐搅拌均匀的勺子,把「盐味」分散到周围,让整锅菜的味道更均衡、协调。如图a→b所示,DCT先把含离群值的分布「整形」成更规整的近正太分布。
从具体例子来说,在图c→d过程中,DCT可以将「128」这一极端值的能量分散到邻近系数,把原本集中的编码压力均匀摊薄。
最终,虽然整体幅值略有升高,但离群值被彻底吸收,后续的编码管线的复杂度和存储开销都大可以大降低。
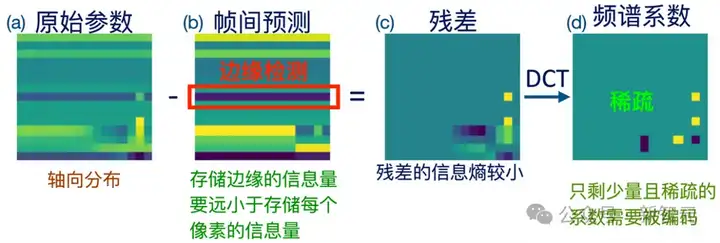
帧间预测+残差编码
谈及视频编码,首先必须提到其灵魂技术——预测编码。正是预测编码,使得视频压缩效率达到了前所未有的水平。预测编码的核心思想是「预测而非直接存储」。
如果我们能够依据已有信息对待编码的数据块进行精准预测,那么该块本身就无需再存储;即便预测并不完美,也无需担心,只要能够得到数据块的大致轮廓,随后计算出真实数据与预测之间的残差,并仅保存能量更低的残差信息即可。
相比直接保存完整数据块,仅存残差便能大幅缩减所需比特数。
上图概述了视频编码器在张量压缩中的工作链路。编码器首先对输入帧进行边缘预测(见图b):一旦判断出存在连续边缘,便直接记录「从(x₁,y₁)到(x₂,y₂)的像素均为蓝色」这类几何描述,而非逐像素存储。
凭借这种轮廓级表达,数据体积骤减,压缩比随之倍增。类似地,LLM的权重、激活和梯度张量也蕴含可视化意义上的「边缘」。
这些张量通常呈轴向分布,即沿同一轴方向的数据整体偏高或偏低(见图b)。
视频编码器可以把这类轴向结构视作「可预测」的边缘区域,先用预测值勾勒大致轮廓,再只编码预测与真实之间的低能量残差(见图c)。
对残差先进行正交变换,再进行量化后,其信息熵会进一步降低(见图d),于是需要传输或存储的比特数大幅减少,压缩率显著提升。
实验结果表明,在几乎所有模型压缩的场景中,无论是推理还是训练,也不论是单卡还是分布式环境,使用视频编解码器对张量进行压缩都能取得显著的效果。
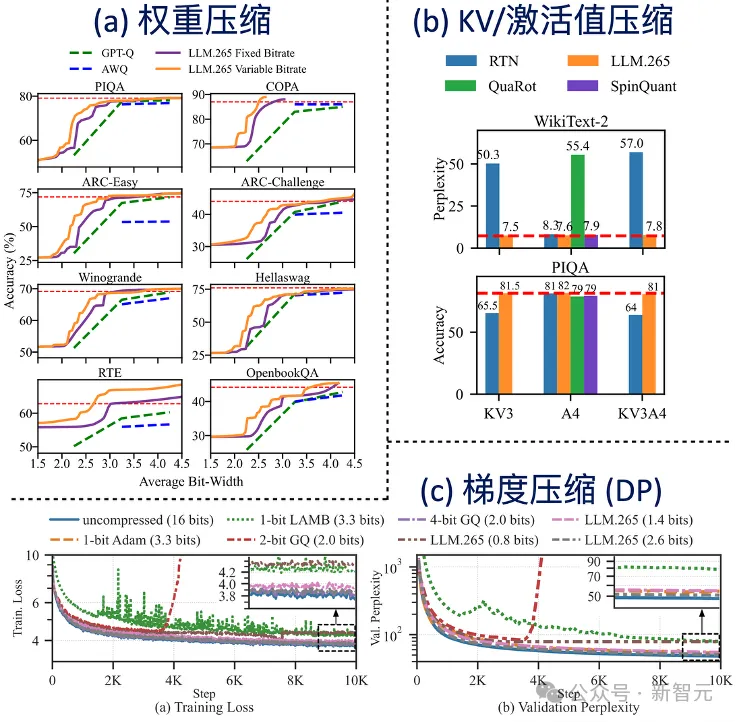
针对权重压缩的实验,LLM.265将传统的4 bit量化进一步推进至2.5 bit,在仅用2.5 bit的预算下仍能够实现与原来4 bit相当的性能,几乎与全精度基准线持平,未出现可感知的精度下降。
在训练过程中,LLM.265将每参数的平均通信比特从之前的3.5 bit降至1.4 bit,通信量因此缩减约2.5倍,同时收敛速度也超过了此前的最先进方法。这些结果充分说明视频编解码器在张量压缩方面具备卓越的潜力。
用更多计算换更小数据量会越来越划算
随着模型规模的持续扩大,摩尔定律的效应趋于衰减,计算能力的提升相对受限,而通信和内存带宽的瓶颈在硬件成本、能耗以及可扩展性方面表现得尤为突出。
在此背景下,数据压缩作为一种「用计算量换取更小数据规模」的技术手段,对缓解内存和通信压力具有重要意义。
研究结果发现,视频编码模块在芯片上占用的面积不足GPU面积的百分之一,这意味着在现有GPU上额外集成若干视频编码单元即可显著提升系统级能效,降低整体成本;若进一步研发专用于张量的编码单元,效益将更加突出。
不再强求无损压缩,有损有更高的自由度
过去的压缩加速器研究大多聚焦于无损方案,而无损压缩的理论上限通常不超过两倍的压缩率。
LLM.265的实验表明,在允许适度有损的前提下,只要在性能与精度之间进行合理的权衡,就可以实现远高于无损的压缩率,同时在训练和推理阶段仍能保持模型效果和精度的可接受水平。
更重要的是,有损压缩方案往往只需对现有硬件进行少量改动,即可在需要时切换回无损模式,保持灵活性。
通用还是专用,that is the question
LLM.265的实验提示可以从两条路径进行探索:
一是将现有视频编码器精细化为专门的张量编码器,去除与张量无关的功能模块,强化对张量有价值的部件,并加入针对张量特性的专用模块,以追求极致性能;
二是将张量编码的功能融入视频编码器之中,利用视频、图像以及通用文件压缩流水线之间的高度相似性,实现硬件压缩加速器的模块共享。
若能够构建一个能够服务多种压缩场景的共享加速器,则有望在硬件资源利用率和系统整体效率上获得更大收益。
通用抑或专用,计算体系结构自诞生伊始便笼罩着激烈的争论。千位架构师、千种应用,恰似千人千面、千个哈姆雷特,孕育出万般设计。
正是这种无限的自由度,造就了体系结构与架构设计的独特魅力,也促成了芯片史上无数大胆、疯狂的创新。
然而,架构师面对的并非舞台上「文无第一」的妙语横生,而是「武无第二」的沙场血战。
在无数基准测试的天平下,所有的架构设计都高下立判。每一次架构抉择,都足以左右一个企业的兴衰存亡——此为即决高下,也决生死。我想,这正是芯片架构设计最令人着迷之所在。
参考资料:
https://arxiv.org/abs/2407.00467
文章来自于“新智元”,作者“LRST”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
