# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
让大模型破译从未见过的甲骨文,准确率拿下新SOTA!
来自复旦大学的研究人员提出了一种基于部首和象形分析的可解释甲骨文破译框架——
不仅在公开基准数据集HUST-OBC和EV-OBC上,达到最先进的Top-10识别准确率以及优异的零样本破译能力。
而且面对未破译甲骨文,所提方法也能够输出可解释性的分析文本,从而为考古破译工作提供潜在帮助。

事实上,作为最古老的成熟文字系统,甲骨文长期以来因其稀有性、抽象性和象形多样性,给考古破译工作带来了重大挑战。
当前基于深度学习的方法在甲骨文破译任务上取得了令人鼓舞的进展,但现有方法往往忽视了甲骨文字形与语义之间的复杂关联。
这导致了有限的泛化能力和可解释性,尤其是在处理零样本场景和未破译的甲骨文时。
为此,本文提出了一种基于大型视觉语言模型的可解释甲骨文破译方法,该方法通过联合部首分析与象形语义理解,弥合了甲骨文字形与语意之间的鸿沟。
下面具体来看——
概括而言,团队提出了一种渐进式训练策略,引导模型从部首识别和部首分析,过渡到象形分析,最后进行部首-象形交互分析,从而实现从字形到字意的推理。
论文还设计了基于分析结果的“部首-象形双重匹配机制”,显著提升了模型的零样本破译性能。
为便于模型训练,论文提出了包含47,157个汉字的象形破译甲骨文数据集,其中部分汉字具有相应甲骨文图像和古代字体图像,所有汉字都具备现代楷书图像、部首分析和象形分析标注。
先说数据集。
尽管现有视觉语言大模型在多种任务上表现优异,但仍难以直接应用于甲骨文破译任务。
为解决这一挑战,论文提出了象形破译甲骨文(PD-OBS)数据集,用于训练具备甲骨文象形分析能力的视觉语言大模型,这对甲骨文破译任务具有重要意义。
PD-OBS数据集共包含47,157个汉字。其中,3173个汉字与从公开的HUST-OBC和EVOBC数据集收集的甲骨文图像相关联;10,968个汉字提供了来自字形库的古代隶书图像;所有汉字均配有来自《汉典》的现代楷书图像。
除图像数据外,每个汉字均通过文本形式标注了部首分析和象形分析,这两者均与汉字的语义含义密切相关。
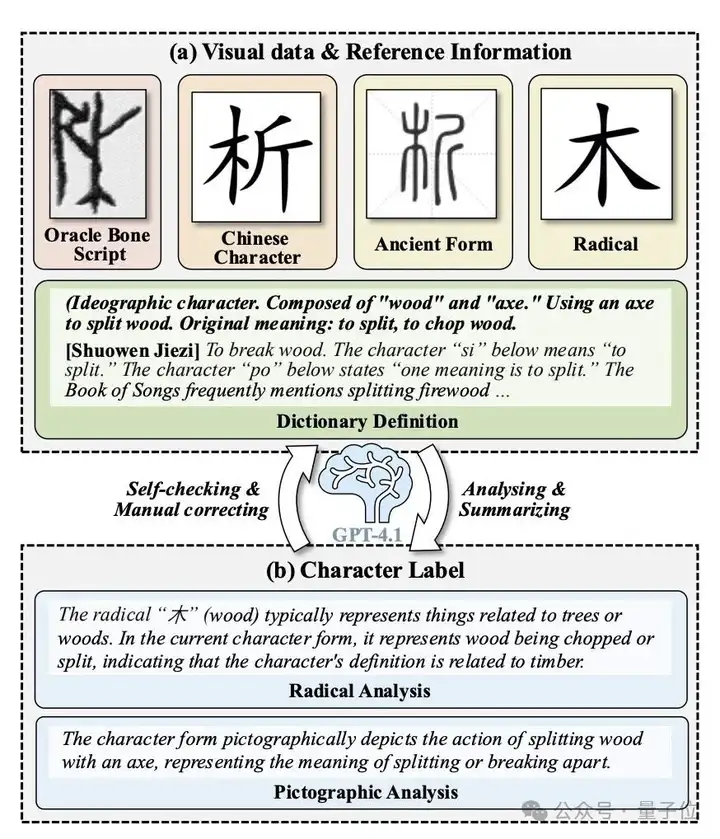
标注过程分为三个阶段,如图1所示。
首先,通过汉典从《说文解字》(一部古代汉语词典)中检索每个汉字的部首标签、定义及解释。
其次,将获取的部首标签及其解释与每个汉字的现代、古代字体和甲骨文图像关联。接着,利用GPT-4.1基于参考的字形图像丰富部首标签,并总结分析内容。
最后,通过GPT-4.1进行自我检查和人工修正来确保数据集的整体质量。
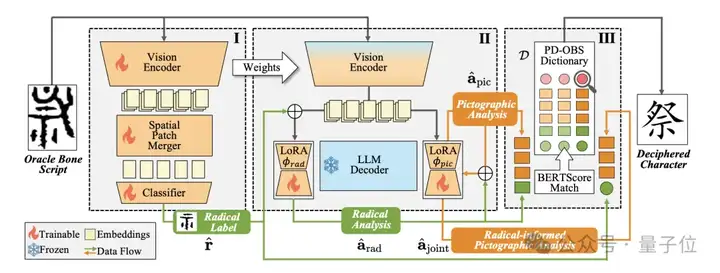
1、模型整体结构
整体框架基于Qwen2.5-VL-7B构建,共享相同的视觉编码器和大型语言模型(LLM)。
如图2所示,研究人员引入了一个空间patch合并模块作为视觉适配器,以及一个分类器来预测部首标签,并且还提出了部首LoRA和象形LoRA模块来分析相应的信息。
此外,研究人员设计了一种渐进式训练方法,从部首识别开始,接着进行部首和象形分析,最终实现联合分析,以逐步引导模型完成甲骨文破译任务。
还提出了一个新颖的部首-象形双重匹配机制,以从数据库中选择最合适的字符。
2、部首识别
在本阶段,研究人员的目标是将视觉编码器适配于甲骨文的独特视觉风格,并预测用于下游推理的关键信息——部首标签。
为此,团队设计了一个空间patch合并模块作为视觉适配器,该适配器将高维视觉特征压缩并聚合为预设维度的特征向量,作为甲骨文的抽象表示。
此外,研究人员基于欧式距离设计了一个三元组损失函数,以明确提升不同部首特征向量之间的区分度。
具体而言,团队实施了一种采样策略,确保每个批次中每个部首类别至少包含两个样本。
在训练过程中,对于批次中的每个样本,将它的特征向量Vn 指定为锚点,然后选择一个正样本(即具有相同根部标签的样本)和一个负样本(即具有不同根部标签的样本)。
三元组损失如下:
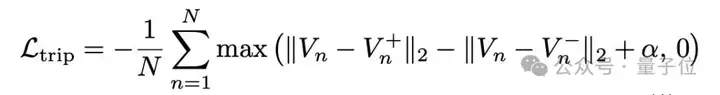
关于分类器,研究人员使用交叉熵损失来优化它。因此,本阶段的整个损失函数可以表示如下:
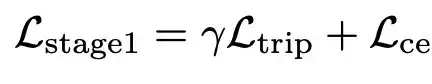
3、部首-象形联合分析
为了在甲骨文中实现字形与意义的关联,研究人员设计了一个渐进式的字形分析过程,以促进破译任务的完成。
在甲骨文和古代汉字中,部首通常决定了字的基本语义,如图3中的Q1&A1所示。
因此,团队利用PD-OBS数据集构建的大量部首分析问答对对模型进行部首分析能力的训练。
接下来引导模型对整个字符进行象形分析,以分析字形蕴含的语意,如图3中的Q2&A2所示。
最后,研究人员设计了一个联合分析步骤,以解决仅凭象形分析可能无法直接预测正确对应现代汉字的情况。此步骤通过部首分析的结果指导象形分析,从而获得更准确的汉字含义,如图3中的Q3&A3所示。此阶段通过交叉熵损失来优化模型。
以下为部首-象形联合分析示意图:

4、部首-象形双重匹配机制
经过前两个阶段后,团队为每个测试字符生成了四个中间结果:预测的部首标签、部首分析、象形分析以及联合分析结果。
研究人员提出了一种基于词典的双重匹配机制用于破译。给定来自PD-OBS数据集的候选词典D,该机制的工作流程如下:
首先,根据预测的部首标过滤候选项,然后根据象形分析之间的语义相似性选择前k个条目。
其次,将预测的部首分析与部首信息增强的象形分析结果进行拼接,并通过相似性进行排序。
最后,将这些候选集合并并重新排序,以获得前k个现代汉字作为破译结果。
所有步骤和符号在图4中详细说明。
值得注意的是,团队采用匹配机制而非直接输出破译结果,这有助于缓解模型在零样本设置下因训练数据中缺乏此类甲骨文而导致的泛化能力不足问题,以及未破译甲骨文带来的影响。
以下为部首象形双重匹配算法:

1、验证集和零样本设定下的破译
研究人员在HUST-OBC和EV-OBC数据集上对所提方法和现有方法进行了评估,从每个数据集中选取200个字符类别作为零样本测试集。
剩余数据以9:1的比例随机划分为训练集和验证集,以评估新框架及现有方法的甲骨文识别能力。
与先前研究一致,团队采用Top-1和Top-10准确率作为评估指标,该指标通常用于各类分类任务。
为了系统地评估新方法在甲骨文破译中的有效性,团队在两个基准数据集HUST-OBC和EV-OBC进行了全面比较,分别在验证集和零样本设置下进行,如表1所示。
注意,每个单元格分别显示Top-1(左)和Top-10(右)的准确率(%)。最佳结果和次佳结果分别以粗体和下划线标注。
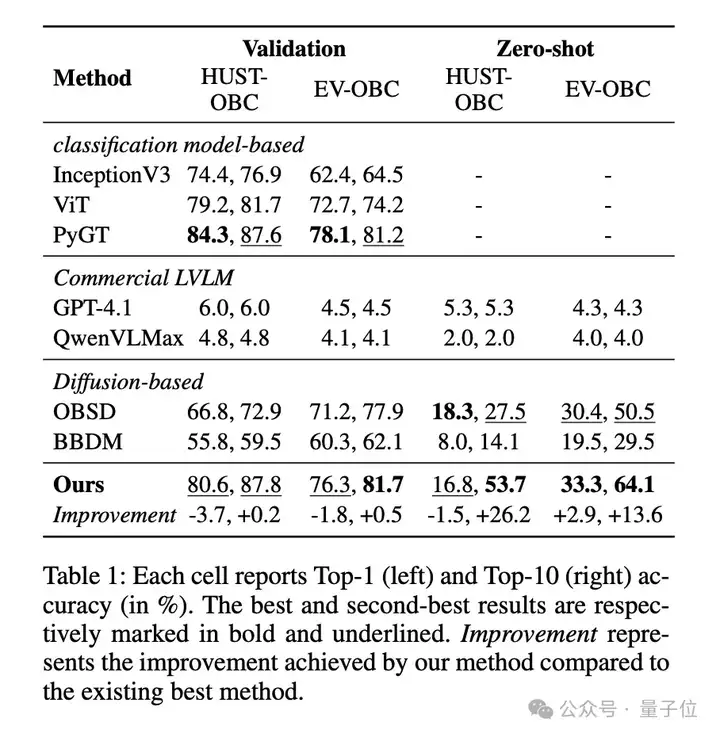
团队采用InceptionV3、ViT和PyGT作为基于分类模型的代表方法,以及OBSD和BBDM作为基于扩散模型的代表方法。由于缺乏开源实现和数据集设置的不一致,现有基于组成式的方法目前未被纳入比较方法。
作为替代,研究人员纳入了强大的商用LVLM,GPT-4.1 和 Qwen-VL-Max用于比较。
相比之下,商用LVLM 在两种设置下表现不佳,Top-1 准确率始终低于6%,这说明了其理解古代文字视觉结构的能力受限。
在验证集上,尽管新方法的Top-1 准确率略低于最佳分类模型基线(如PyGT),但它实现了最高的Top-10准确率,展示了生成高质量候选项的优越能力,并提供了更大的实际用途。
在更具挑战性的零样本场景中,新方法表现出显著的优异性能:
在Top-1准确率方面仍具竞争力,并在Top-10准确率方面显著超越所有方法,在HUST-OBC数据集上比第二好的方法高出26.2%,在EV-OBC数据集上则高出13.6%。
这些结果证实了新方法在未见过的甲骨文上的强泛化能力和可迁移性,突显了其在考古研究中辅助识别未破译甲骨文方面的潜在价值。
2、破译的可解释性评估
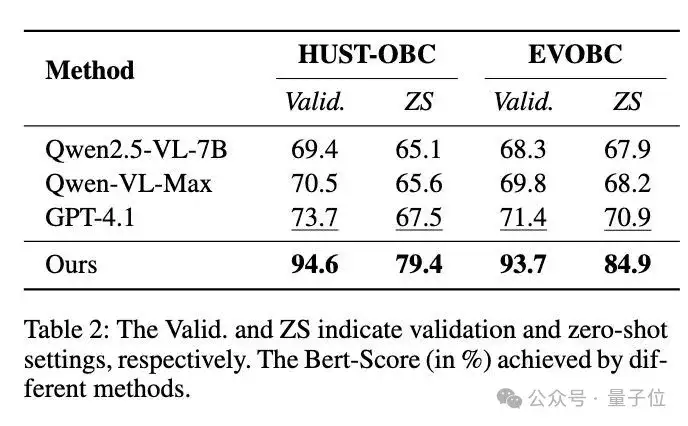
为了定量评估新方法生成的部首分析和象形分析的准确率,研究人员采用BERT-Score来衡量Top-1输出与字典D中真实分析标注之间的相似性。
团队还评估了其他大型视觉语言模型,包括GPT-4.1、Qwen-VL-Max和Qwen2.5-VL-7B,并比较了它们在HUST-OBC和EVOBC数据集的验证集和零样本测试集的平均BERT-Score。
如表2所示,新方法在验证集和零样本设置下,分别平均比最先进的LVLM模型GPT-4.1高出21.60%和12.95%,在两个数据集上。
这一结果表明,新框架生成的分析结果更加可靠。
下表为,不同方法在验证集上获得的Bert-Score(%)。Valid.和S分别表示验证集和零样本测试集。
3、消融实验
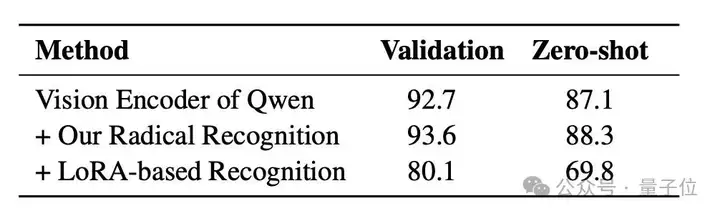
为了评估设计的部首识别阶段的有效性,研究人员以Qwen2.5-VL-7B的原始视觉编码器作为基线,并分别集成部首识别模块以及基于LoRA的识别方法。
其识别准确率在HUST-OBS数据集上进行了验证,并包含验证集和零样本设置。
新方法在基线视觉编码器上引入了空间补丁合并和损失函数Ltrip,分别在验证集和零样本设置下实现了0.9%和1.2%的准确率提升。
基于LoRA的识别方法将识别阶段与部首分析过程合并,并采用基于LoRA的微调进行训练。
实验结果表明,该方法导致部首识别准确率显著下降,从而在部首分析中引入大量错误,因此研究人员在框架中将部首识别保留为独立阶段。
下表为,关于部首识别的消融实验结果:
为了验证团队提出的模块和策略的有效性,他们以Qwen2.5-VL-7B作为基线,并逐步添加每个组件以形成最终模型。
在验证集和零样本设置下的Top-1和Top-10性能如表4所示。
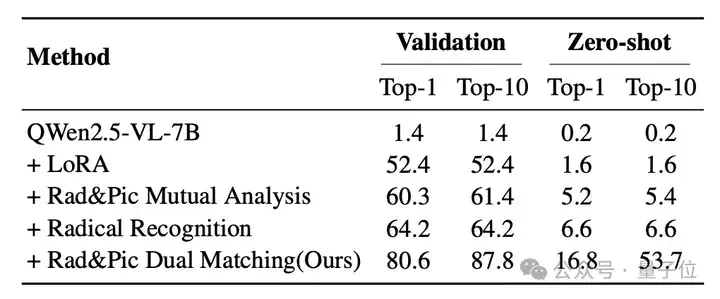
结果表明,LoRA微调(+LoRA)在验证集上实现了基本的破译能力,但在零样本场景下仍缺乏泛化能力。
引入部首-象形互分析与部首识别后,模型在验证集上的准确率持续提升,但零样本能力的提升仍非常有限。
主要原因在于通过LoRA基于监督式微调训练的模型缺乏足够的泛化能力,常无法生成罕见字符——这是零样本场景中的常见挑战。
为解决此问题,团队引入了部首-象形双匹配机制,以替代直接预测。
该策略不仅显著提升了模型的零样本性能,还增强了甲骨文中与语义无关的部首的鲁棒性,确保了解码结果的可靠性和可验证性。
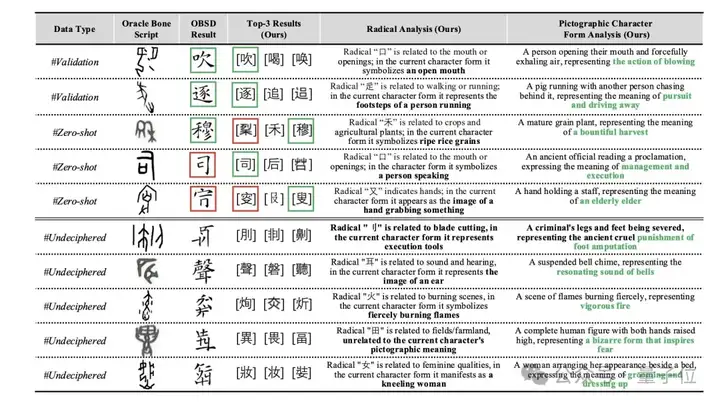
4、定性实验
图5展示了新方法以及OBSD方法在三种设置下的定性结果:验证集、零样本和未破译的甲骨文。
如图所示,团队的模型在验证集上展现出强大的识别能力,并在零样本设置下对未见过的甲骨文也具有良好的泛化能力。
更值得注意的是,对于人类专家尚未破译的字符,模型能够生成语义上合理的预测,并附带可解释的分析。
其设计的部首-象形相互分析在其中发挥了关键作用:部首分析追溯部首的结构起源,并解释其在当前字符形式中的象征功能。
同时,象形形式分析基于字符的整体形状和隐含意义,提供了一个整体的视觉-语义映射。
这些互补的分析共同形成了一条双重推理路径,提升了模型生成语义基础且可解释输出的能力,即使对于尚未破译的字符也是如此。
下表为, 破译结果和可解释性过程展示:
小结一下,在本研究中,团队提出了一种基于部首和象形分析的可解释甲骨文破译框架。
该框架通过三个阶段将字形与意义相连:部首识别与分析、象形分析以及相互分析。
借助提出的部首-象形双重匹配机制,其模型可根据分析结果从字典中筛选出合适的破译候选集,取代直接输出破译结果,从而实现更优的零样本性能。
此外,生成的文本分析可作为可解释内容,为未破译的甲骨文字符提供参考,因此在考古应用中具有巨大潜力。
为支持训练,他们构建了PD-OBS数据集,包含47,157个注释有甲骨文图像和象形文字分析文本的汉字,为未来研究提供了宝贵资源。
实验结果表明,其方法在破译准确性、泛化能力和可解释性方面均表现出强劲性能。
论文地址:https://arxiv.org/abs/2508.10113
项目地址:https://github.com/PKXX1943/PD-OBS
文章来自于“量子位”,作者“复旦大学团队”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
