# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

图片来源:a16z
a16z是硅谷最具影响力的风险投资机构之一,它长期深耕人工智能、企业软件等多个领域,支持了包括OpenAI、Databricks在内的全球领先科技企业。作为新一代技术与产业变革的推动者,a16z不仅在资本层面提供支持,更通过研究、行业洞察与政策对话推动技术生态的成熟与落地。本篇文章由a16z团队发表于2025年8月28日,系统性地勾勒了Agents成为未来数字同事的趋势,并进一步展现了他们在生成式AI和未来工作模式探索中的前瞻视野。
想象一下,你被要求为公司寻找新的办公空间——这是个你宁愿避免的任务。现在再想象,你能把整个流程都交给一个AI来完成:从确定需求、调研地点、安排看房、谈判租约,到处理保险和突发问题,全程无需你的参与或明确指令。这样的自主型、任务导向的“AI Agents”,长期以来一直是这一领域的终极目标。
然而,尽管已经投入了大量关注和努力,如今的Agents仍然未能实现这一愿景。目前市面上的Agents更接近于先进的RPA工具,而不是真正的自主系统。虽然LLM在这方面有所突破,但它们通常依赖复杂的prompt engineering、精心编排的模型和预设流程,比如脚本化的CRM记录更新。
不过,最近我们看到了向真正AI Agents迈进的迹象,尤其是在浏览器和桌面环境中的应用。像OpenAI的ChatGPT Agent、Anthropic的Claude、Google的Project Mariner,以及Manus、Context这样的初创公司,正在展示一种可能:经过专门训练、能执行电脑任务的、接近人类水平的Agents。
与单一功能的AI工具不同,这类Agents可以通过MCPs明确接入更多工具,或者通过computer-using的模式完成操作,从而承担完整的端到端数字化流程。例如,它们可以在数据库中找到文件,提取关键信息,更新Salesforce,在Slack上通知同事,并生成合规报告,全程无需人工介入。它们能够处理那些通常消耗人类大量精力的“粘合性工作”。除了通过API像计算机一样操作外,这些Agents还可以像人类一样操作软件——点击界面、登录、传输文件、使用旧版系统——因此能够无缝融入现有工作流,而不必进行大规模IT改造或定制集成。由于这些Agents是以“员工层面”接入的,它们也可以像人类团队一样进行再训练和扩展。
这些进展共同指向一个广泛而有价值的应用前景:AI Agents能够在无人干预的情况下,处理各种各样的数字化工作。
Computer use是真正Agents的关键驱动力。它们的有效性取决于两个因素:能够接入多少工具,以及能否在这些工具之间进行推理。
Computer use显著拓展了这两方面的能力——既赋予Agents使用任意软件的广度,也提升了它们将一系列动作串联成完整工作流的智能。
Computer-using AI Agents的潜力来自工具可达性与推理能力的乘法效应。随着Agents既能接入更广泛的工具,又能更好地加以运用,它们可处理的工作流范围和复杂性呈指数级增长。再加上潜在的涌现能力(例如,Agents可能通过自主探索、检索并综合上下文,完成复杂的context retrieval),其前景更令人期待。
对于初创企业而言,AI的主要机会一直在于自动化工作、替代人工投入。Computer use是迄今为止在人类劳动能力复现上的最大进展。过去的主要瓶颈在于大量软件缺乏API,或者API功能受限,必须依赖人工监督。这在许多企业的核心遗留软件中尤为常见,比如Epic、SAP和Oracle。具备推理能力、能够操作图形化界面的computer-using Agents,正好填补了这些空白,使端到端的工作自动化成为可能。
尽管computer-using Agents前景巨大,但要在企业中大规模落地并不容易。对computer use进行合理的纵向垂直化,并帮助企业完成落地,将会成为初创公司重点探索的方向。
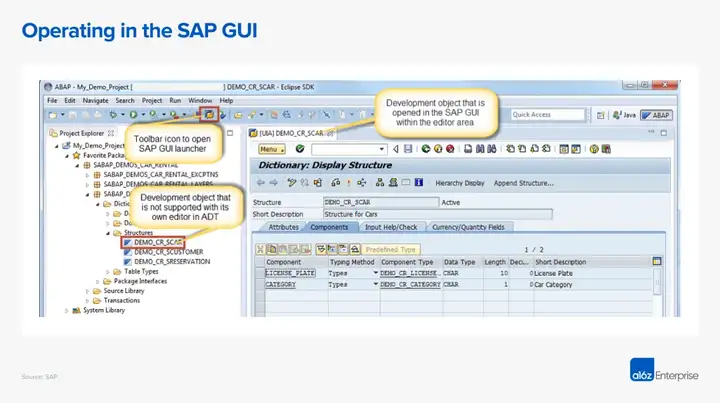
仅依赖于通用软件训练出来的computer-using Agent,例如ChatGPT Agent或Claude,很难在企业级软件环境中即开即用。企业软件往往高度专业化且不够直观,不同公司即便使用相同的软件,也会因为自定义视图、工作流和数据模型而产生差异。要理解这一点,可以对比一下人类在加入新公司或学习新软件时所需的培训量。
正因如此,computer-using model需要有足够的上下文信息,类似于此前的企业chatbot或assistant。没有额外的上下文或训练,ChatGPT Agent几乎不可能直接掌握如何操作某个特定的SAP实例。
图片来源:a16z
但在这种场景下为模型提供上下文其实相当复杂。首先,什么才算是相关的上下文?可能是书面操作说明、入职培训视频、浏览器操作录屏,甚至在某些情况下根本没有任何文档。其次,应该如何把这些上下文提供给模型?这并不像在prompt开头加一段文字那么简单,因为还需要考虑图形化和时间维度。那么在这里,检索和RAG的类比该如何实现?最后一个问题是:旧有流程是否应该决定新的做法?Agents确实需要参考人类的工作方式,但人类的方式往往并不最优——Agents在多大程度上应该忽略既有上下文,从头重构工作流?
能够掌握这些情境化策略的初创公司,将在为企业提供更强大、更定制化的Agents方面具备显著优势。虽然这方面的最佳实践仍在探索中,但高度聚焦的初创公司,而非模型提供方,更有可能解决这些特定行业和企业层面的挑战。
基于这些考虑,我们将话题从“为什么computer use重要”转向“它在实践中如何实现”。接下来的技术栈将展示调优、情境化和可靠性措施分别切入的位置,也因此成为初创公司实现差异化的关键所在。
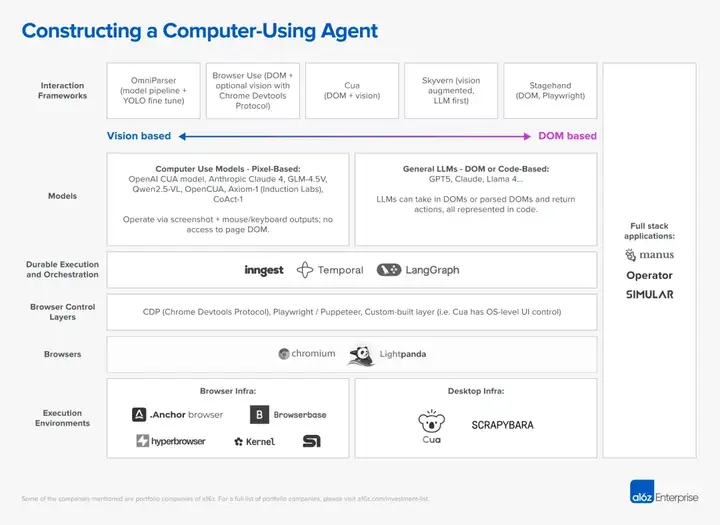
Computer-using Agent的架构仍是一个活跃的研究方向,开发者们尚未就如何在日益强大的模型与辅助工具之间划分职责达成共识。目前大多数方法会将Agent分层,以便将高层目标转化为可执行且可靠的UI操作。至于这些层级中的某些部分——例如交互框架——是否会随着多模态模型能力的增强而逐渐消失,这仍是一个开放问题。当前正在探索的路径包括基于视觉(pixel)和基于结构(DOM/code)的两类流程,如何最佳地融合它们的实践也仍在形成中。尽管如此,下文所描述的分层方式提供了可操作的边界,便于注入领域知识、调优行为和强化可靠性——正好对应前面提到的挑战。
从整体上看,下述技术层展示了computer use Agents如何将推理转化为可靠的执行。交互框架决定了模型如何被引导去感知并操作界面;模型则通过解读像素或DOM结构来生成指令;持久的编排机制确保长时、多步骤的computer use工作流不会中断;浏览器控制层提供自动化接口,而浏览器本身则渲染出Agents所操作的界面;在最底层,执行环境支撑整个系统扩展至可投入生产的基础设施。
图片来源:a16z
更深入地看每一层:
与上述基础设施栈并行,商业化的全流程Agent应用将这些层集成进统一的产品。ChatGPT Agent将CUA与托管浏览器沙箱结合,实现端到端的Web自动化;Manus在持久化Linux环境中编排多个语言模型,自动化企业流程;Simular S2近期在OSWorld上取得领先的自主性评分。新发布的Claude for Chrome则通过浏览器扩展将Claude直接嵌入浏览器,使Agent能代表用户采取操作。这些方案将整个栈抽象在目标导向的界面之后,同时内置安全约束与监督机制。
尽管近年来进展迅速,但当前的Agent依然存在明显局限:在能力上,它们难以应对复杂或陌生的界面;在效率上,它们运行速度慢、成本高,尚不足以与人类操作员竞争。不过,我们预计在未来6到18个月内,这两个方面都会有显著改善。
只有真正解决这些问题,Agent才能成长为真正意义上的Agentic coworkers。最初,它们会在特定的业务功能中表现出色,甚至可以通过落地实施来针对某些公司进行定制。这些Agent能够跨越现有的软件体系,优化更高层级的战略目标(例如,在预算内获取一定数量的用户,或在特定约束下生成预测),而不是局限于团队、个人或具体流程中。它们尤其适用于需要与遗留软件交互,或者在API不存在或受限的场景。一旦新工具和API出现,或现有的发生演进,Agent也能够在无需大量额外开发的前提下快速适配。
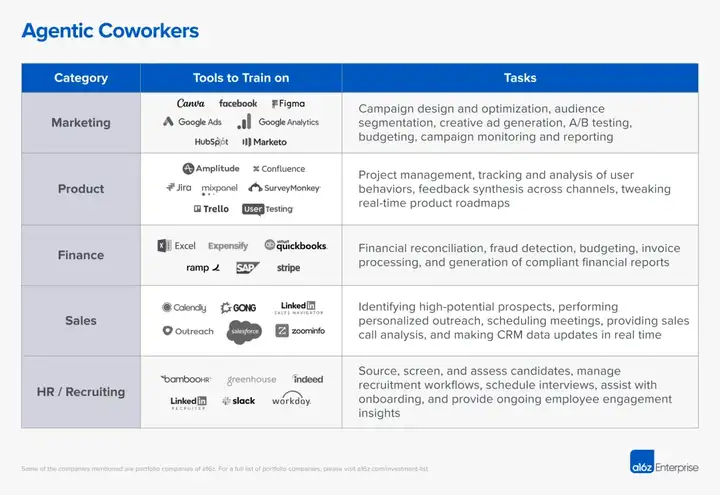
举例来说,可以预见在市场营销、产品管理、财务、销售、人力资源与招聘等领域,会率先出现这些Agentic coworkers:
图片来源:a16z
将这些行业乃至公司特定的能力,与通用型的横向技能相结合——比如网页搜索、邮件管理、通过Slack进行内部沟通、借助Google Drive处理文档、以及在Notion中进行内容整理——将会解锁新的功能。这些Agent还能处理更多定制化或遗留系统中的操作,尤其在API受限的场景下,借助computer use的能力会显得尤为重要。
这种组合带来两个关键优势。第一,Agent在工作中会因为具备更多上下文而变得更高效。它们可以独立收集并整合内外部信息,从而提升任务完成度。比如,一个销售Agent在撰写冷启动邮件时,可以无缝调用Google Drive中的最新产品路线图。第二,这种工具的全面整合简化了部署和实施流程。Agent能够自然融入现有的工作流和工具体系,无需像传统软件那样依赖专门接口或额外平台,从而降低使用门槛。可以预见,在不久的将来,会有大量Agent群体协同工作,并通过现有的记录系统和沟通渠道,与人类同事保持实时同步。
Computer-using Agents代表着一次超越浏览器自动化和RPA的跃迁。通过在现有工具间协作并适配遗留系统,它们让我们离真正意义上的Agentic coworkers更进一步——能够像人类员工一样,在充满碎片化和遗留系统的环境中高效工作。
接下来的挑战不在于证明Agent是否能工作,而在于如何在真实企业环境中对其进行调优、提供上下文,并完成部署。能够掌握这种“情境化能力”的初创公司,将定义第一代Agentic coworkers,并由此树立数字劳动力如何重塑整个产业的标准。
原文:The Rise of Computer Use and Agentic Coworkers
https://a16z.com/the-rise-of-computer-use-and-agentic-coworkers/
编译:Claire Zhou
文章来自于“Z Potentials”,作者“Z Potentials”。



【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
