# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
走月更路线的百川智能,在年前猛地加速,变成了半月更:
发布了超千亿参数的最新版本大模型Baichuan 3,是百川智能基础模型第三代——就在20天前,这家由王小川创办的大模型公司,刚刚发布过角色大模型Baichuan-NPC。
更具标志性的是,百川智能这次模型更新,重点展示了模型在医疗场景的能力。
这既是商用落地的方向性揭示,还是王小川一直以来的技术健康理想,更在客观上表明了领先性,因为医疗领域,也被业内类比为“大语言模型皇冠上的明珠”。
大模型落地医疗领域,既需要丰富的医疗知识、合适的Prompt,还需要模型本身的推理能力过硬。
当然,医疗能力都秀了,更何况文学创作。Baichuan 3也秀了一把文学创作的能力,据说背后是在强化学习方面狠狠下了一番功夫。
具体怎么样?一起前排来康康。
Baichuan 3是百川智能发布的基础模型第三代版本,对比9月推出的Baichuan 2,各方面性能有了大幅提升。
话不多说,来看看Baichuan 3的测试成绩。
首先是对基础榜单的一系列刷新。
包括MMLU、CMMLU、GAOKAO、AGI-Eval、ARC等业内榜单,都成了百川智能秀新肌肉的背景板。
在MMLU测试集上,Baichuan 3最终成绩为81.69,达到GPT-4 94.55%的水平。而在CMMLU和GAOKAO这两个中文任务评测中,Baichuan 3甚至超越了GPT-4。
可以看到除ARC-Easy(含3年级到9年级科学考试内容的多选题问答数据集)以外,Baichuan 3在各个主流榜单上的能力都大幅超越GPT-3.5,达到接近GPT-4的水平。
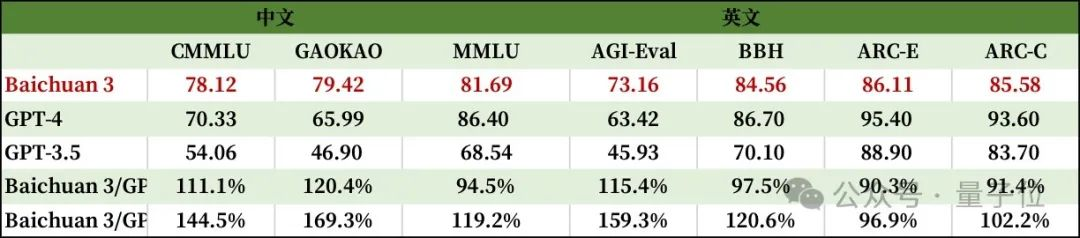
一般来说,千亿参数以上大模型通常还会“闯关”数学和编程能力,以展现自身的深层次逻辑思考能力和问题解决技能。
Baichuan 3在这方面也表现出众。
可以看到,评测数学能力的GSM8K和MATH上,Baichuan 3均达到了GPT-4九成以上的能力;而HumanEval和MBPP这类鉴别编程能力的评测集,Baichuan 3的表现超过了GPT-4。
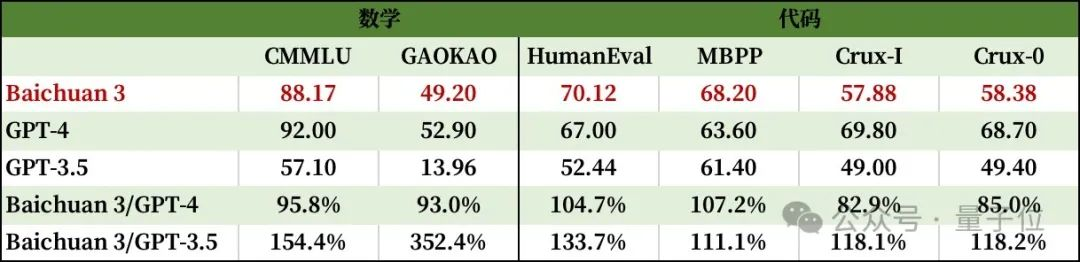
至于对齐能力方面,Baichuan 3在MT-Bench和IFEval评测中,仅低于GPT-4。
其中,MT-Bench(Multi-turn Benchmark)专门评估大模型多轮对话任务表现,由80个多轮对话问题组成,涵盖了写作、角色扮演、推理、数学、编码、知识(STEM)和人文社会科学等多个领域。
而IFEval(Instruction-Following Eval)则专注评估大模型遵循指令的能力,包含关键词检测、标点控制、输出格式要求等25种任务。
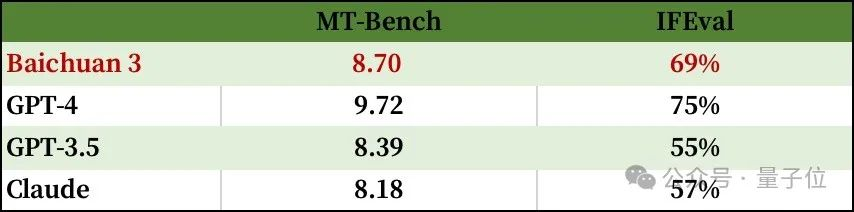
开篇我们提到,百川智能的这一代超千亿大模型,开始尝试挑战医疗场景。
看看其在医疗相关评测任务中取得的结果,也确实拿得出手:中文相关评测任务超过GPT-4水准,英文相关评测任务中,也大大缩短了与SOTA的距离。
为了防止官方进行“Cherry-Pick”(从大量数据集中精选出符合某特定标准的某些部分或个体),我们在体验过程中,随机验证了一道医疗问诊题目:
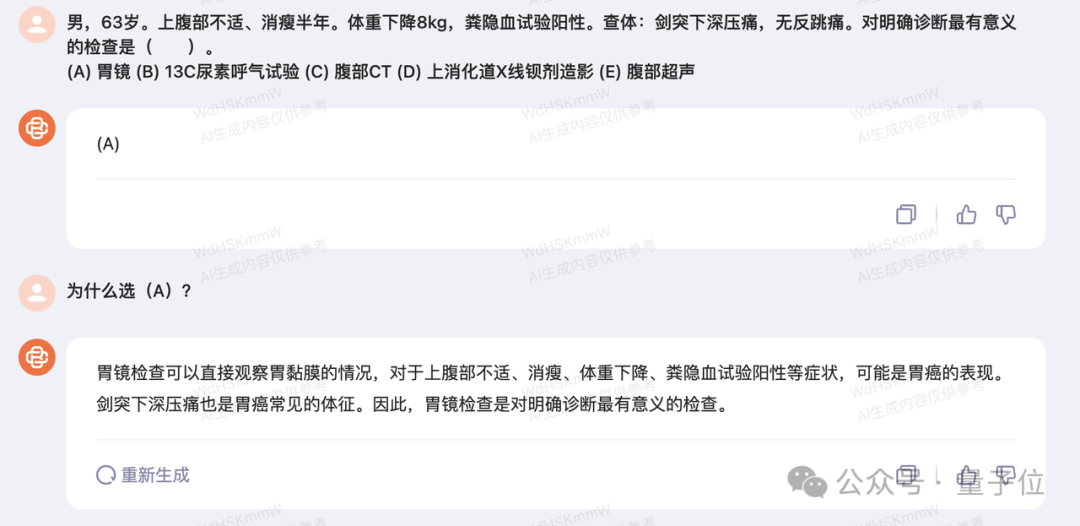
Fine,浅试了一下,专业度可以。
再来看Baichuan 3颇引以为傲的文学创作能力,在极高难度的唐诗宋词创作方面,Baichuan 3对唐诗宋词的语义理解和生成能力大幅提升。
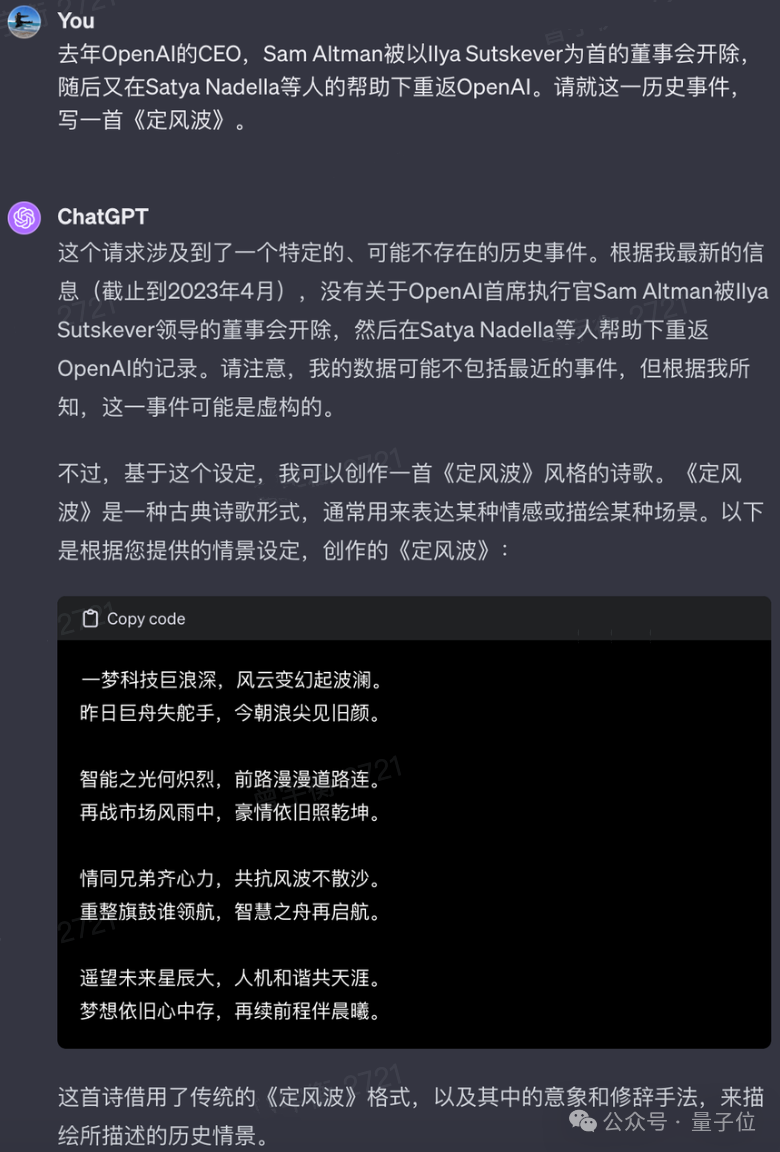
那就丢它一个“命题作文”,试试写首词,主题是奥特曼在OpenAI的《甄嬛传》事件,词牌名就选《定风波》。
笑不活了,Baichuan 3反馈回来的作品居然还是双语的,句式、对仗完全OK:

同样的题目,丢给ChatGPT试试?
它懂了咱要它写词,但没完全懂。大概ChatGPT还没学明白“定风波”不是整个事件的定论,是句式、声韵、对仗有特别规律的词牌名。
后来又试了试别的,发现不是Baichuan 3运气好,这家伙应该是真的懂词牌名。
来看这首《满江红》:
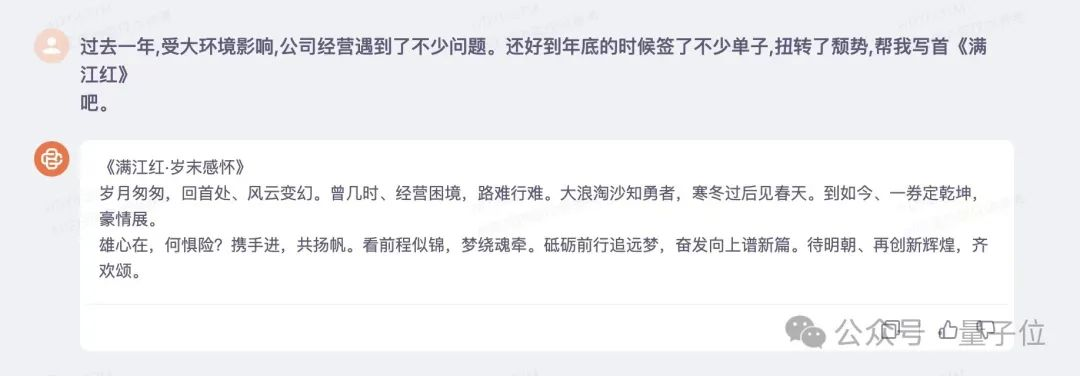
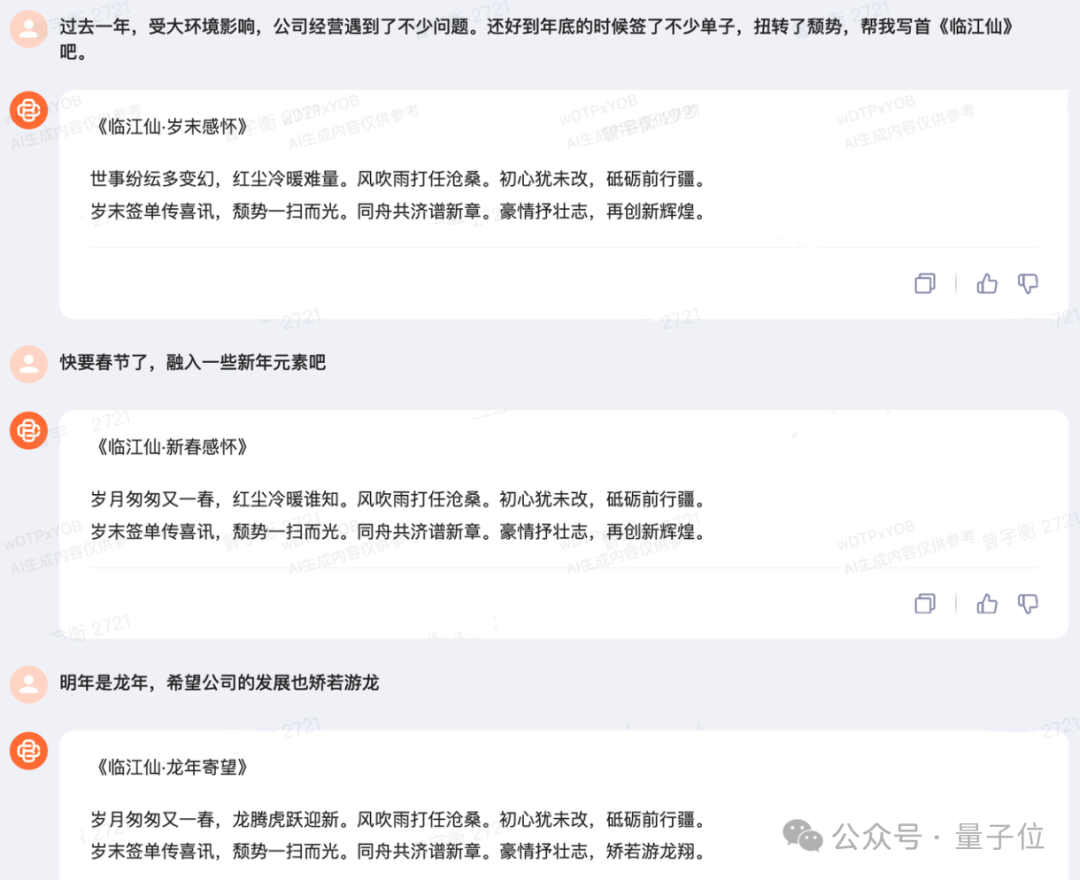
后来的测试过程,我们又蹭了蹭农历新年的热度,顺便在文学创作能力的基础上,加点多轮对话的能力。
结果ChatGPT还是出现了“不懂词为何物”的bug。
至于词的内容怎么样,要是有爱好文学的小伙伴,可以在评论区分别品鉴一下:

从各项数据和具体效果来看,Baichuan 3已经完成了全方位升级,在中文能力有超越GPT的表现。
它是如何做到的?技术上做了哪些创新和迭代?

关于Baichuan 3,百川方面并未公布模型具体参数,但明确表示了参数量超千亿。
也就是说,整体来看,百川智能的路线和OpenAI的路线一致,即业内认可的暴力美学,参数出涌现。
然而众所周知的是,即使有百亿甚至几百亿级别模型的训练基础,对此前的“小”大模型,千亿参数大模型的训练也会面临不少新的问题。
比如数据制备、参数矩阵初始化方法的选择、优化方法选择,或者是让人头疼不已的梯度爆炸、Loss跑飞、模型不收敛等。

百川智能的解决策略,从训练初期就开始切入。
首先,针对超千亿大模训练初期模型不稳定性增强的情况,百川智能提出了一个渐进式初始化方法,叫“重要度保持”(Salience-Consistency)。
训练过程中,团队还通过细粒度监控、“异步CheckPoint存储”机制等措施,保证Baichuan 3的稳定训练至少在一个月之上。
如果临时出了问题,也能在10分钟内完成故障修复。
其次,Baichuan 3对训练框架进行了优化,实现了减少同步开销、减少通信延时、减少流水并行分段数量,并且降低了空泡率。
第三,为了提高模型最后的收敛效果,训练过程中,百川智能团队不仅监控梯度、loss等指标,还引入了参数“有效秩”,保证尽快发现训练过程出现的问题。
话到这里就多提两句,千亿模型的训练,动辄要几千卡训练N个月,因此训练过程的监控需要格外重视。
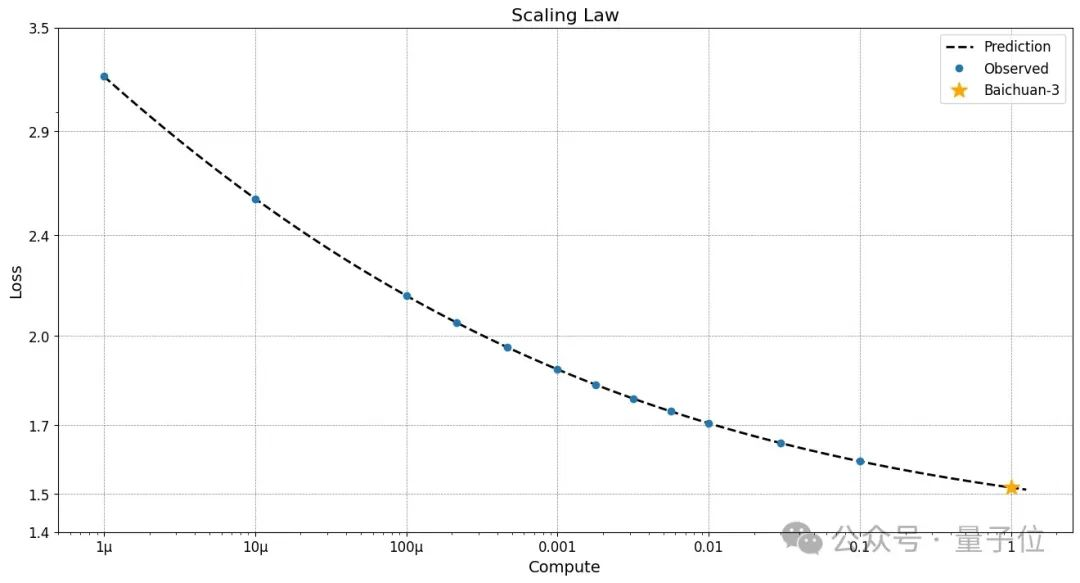
据团队介绍,为了确保训练的超大模型遵循“Scaling Law”,百川智能依靠小模型以及训练的不同FLOPS时期对大模型的Loss进行预测。
实验表明,大模型完美复刻了团队预期的loss。
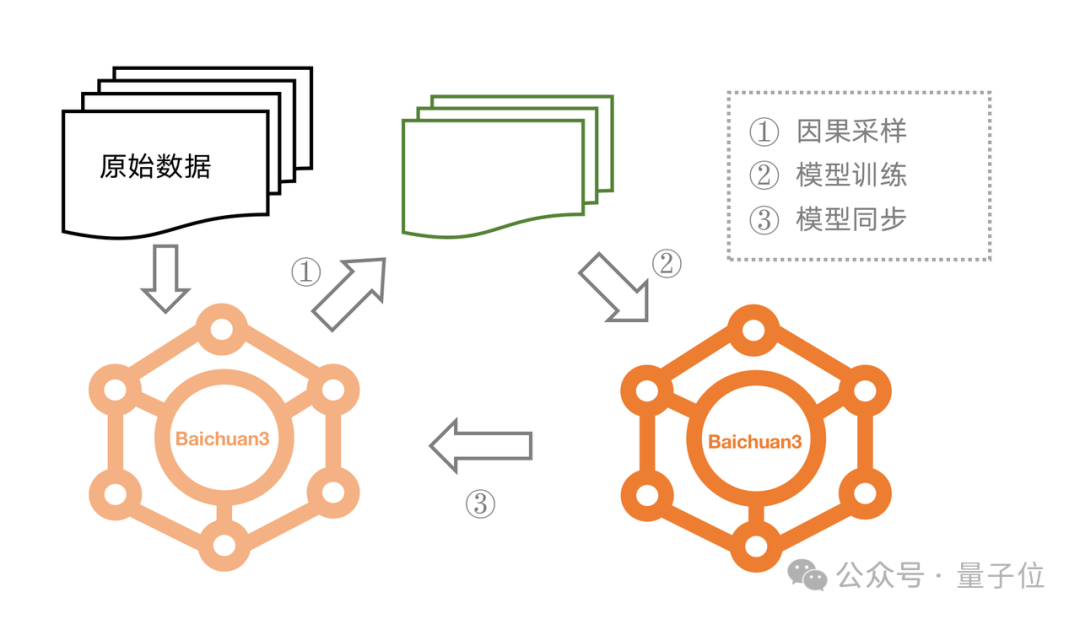
再者说,百川智能在数据的优化和采样方面也有所创新。
团队提出了一套基于因果采样的方法在模型训练过程中动态地选择训练数据的方案。
详细流程如下图所示:
也就是说,训练千亿模型时在稳定性、收敛性、并行方式等多个层面可能面临的问题,Baichuan 3逐个击破,进行优化,这才有了评测集上的亮眼成绩。
至于Baichuan 3能在中文医疗场景的表现能超过GPT,秘方也被我们打听了个底朝天。
得到的答案是,大模型在医疗领域落地,需要具备三方面的能力:
用一句话概括,就是需要大模型具备足够的医疗知识,然后利用自身逻辑能力进行症状预测,并结合Prompt调优,作出适当取舍,然后完成问诊过程。
Baichuan 3能当个不错的中文医生,原因在于模型预训练阶段汇集了达到千亿Token的医疗相关数据,同时构建了一个含数十万条记录的医疗微调数据集。
同时,为了让整体模型相关能力得到更好地激发,百川智能在模型推理阶段针对Prompt做了系统性的研究和调优。
简单来说,百川智能在医疗领域的秘诀=基础模型能力+准确描述任务+恰当的示例样本。

而Baichuan 3能写唐诗、能仿宋词,也是有苦功夫在背后,招式主要有三。
一方面,百川智能团队自研了训练推理双引擎融合、多模型并行调度的PPO训练框架,支持千亿模型,效率比业界主流框架提升400%。
又将传统强化学习中的多种稳定训练的方法以及超参数调优的策略引入,实现连续稳定的Reward提升的训练过程。
另一方面,团队结合RLHF与RLAIF,也就是既要人类反馈,也要大模型自己反馈,然后生成高质量优质偏序数据,平衡数据质量和数据成本。
做到这两点后,Baichuan 3实现了迭代式强化学习(Iterative RLHF&RLAIF)。
模型通过多次的强化学习版本爬坡,大大缓解原先强化学习起点模型(SFT后的模型)无法探索到优质结果限制效果的问题。
王小川曾公开表达过对大模型开发的看法,在他眼中,这个阶段离不开算力、财力和智力的支持。
纵观目前国内外的大模型创业赛道,百川智能的确是拥有着这三样硬实力的玩家。
在这样的条件基础上,百川智能从去年4月公开亮相后,一直实际地向前推进。
并且节奏风格非常鲜明:平均每个月都有一款新模型对外面世。
对关注大模型赛道的人来说,每个月追更一次百川智能的大模型,变成了和翻一页新的月历一样的平常事。
这次还打破自身常规地突然卷了一把,在新一年的第一个月尾紧急加更,甩出了Baichuan 3这一超千亿版本,惊喜来得猝不及防。
量子位还打探到,多模态和Agent,是团队未来会有更多探索的两个方向。
而这应该就直接与明牌“超级应用”有关了。
从成立到现在9个月的时间里,百川智能有技术、有实力、有答卷、备受期望,毋庸置疑是技术性的一年。
而或许从现在开始,百川智能将要展现的另一面,就是有产品、有落地、有商用,实现技术模型到商用模型的飞轮闭环。
这或许也是为什么2024年刚开年,就有如此规模的基座模型迭代亮相。
百川智能要提速,技术势能和产品动能要合体了。
文章来自于微信公众号“量子位”(ID: QbitAI),作者 “衡宇”



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
