# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

刚发完Baichuan-NPC还不足月,百川智能又对产品进行了一次大更新,发布了Baichuan 3模型。这次更新后,在多个权威通用能力评测CMMLU、GAOKAO和AGI-Eval中,其英文能力已经逼近 GPT-4,在中文任务表现上甚至超越了GPT-4:
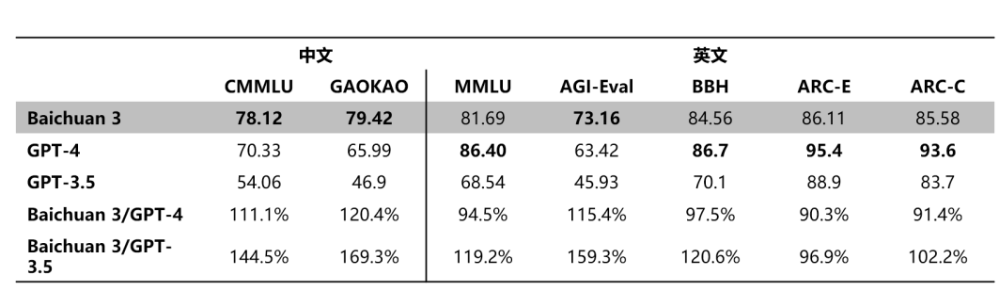
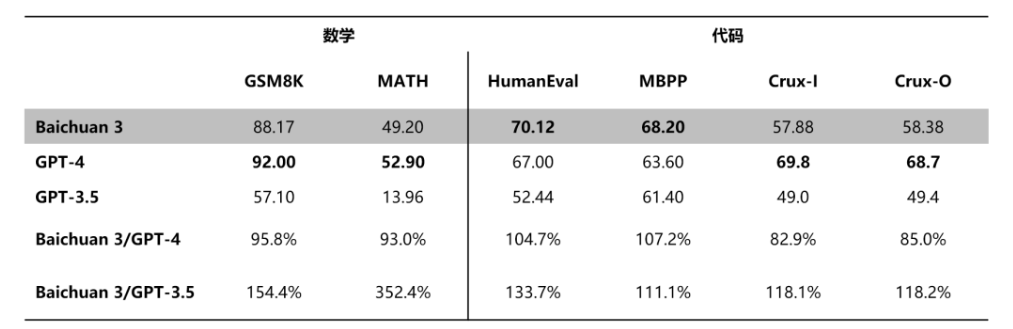

百川智能一直在强调Baichuan 3在医疗场景方面的优化。在预训练阶段,百川智能就为Baichuan3构建了超过千亿Token的医疗数据集,包括医学研究文献、真实的电子病历资料、医学领域的专业书籍和知识库资源、针对医疗问题的问答资料等。此外,他们在推理阶段进行了系统性的调优,让Baichuan 3在真实的医疗问答场景下也能给用户提供更精准、细致的反馈。
而从Baichuan 3在MCMLE、MedExam、CMExam等中文医疗任务的评测的表现来看,这款大模型在中文医疗场景的表现已经超过了GPT-4,而英文相关问题其表现也不错,仅次于GPT-4。
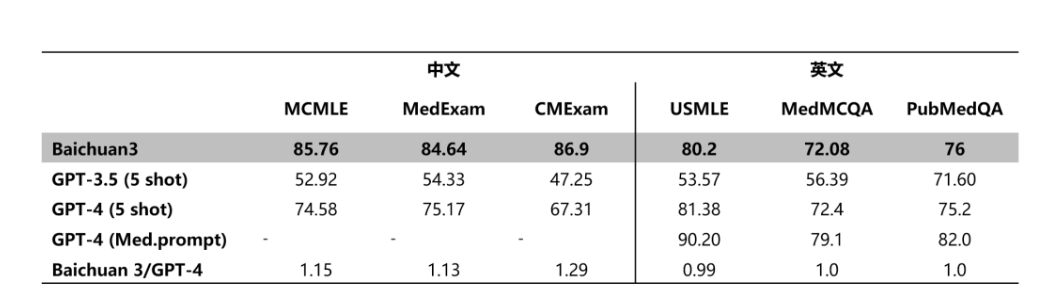
当然,跑分只是模型能力的一个剪影,硅星GenAI 选了一些关于医疗行业和中国传统文化相关的问题来让他回答,看看Baichuan 3的实际表现。
对于百川大模型的医疗知识与思考角度进行测试,由简单到更具专业性循序渐进地问了Baichuan 3几个就诊问题:


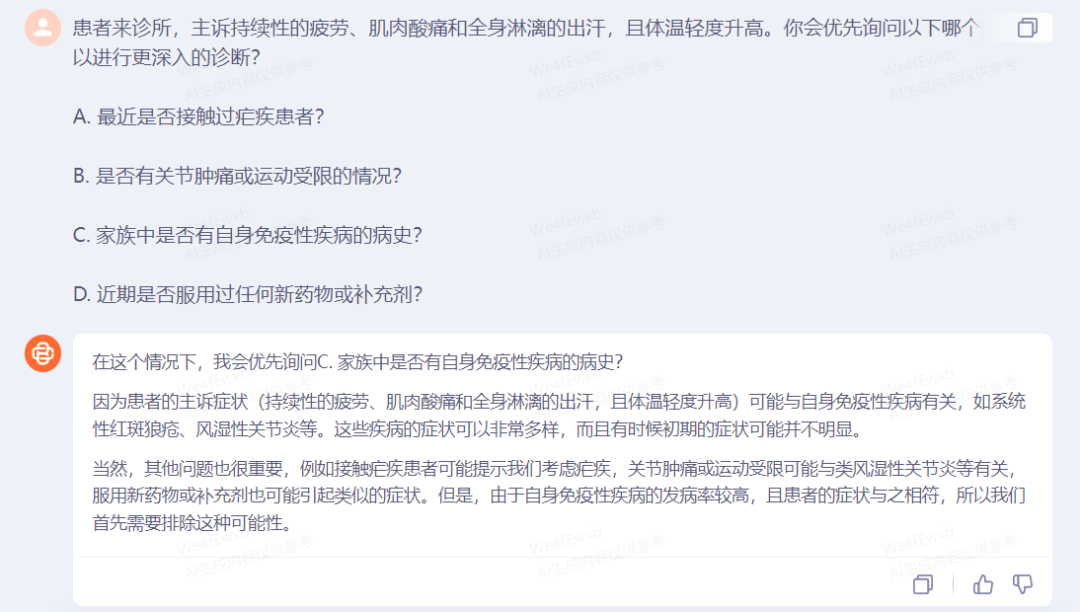
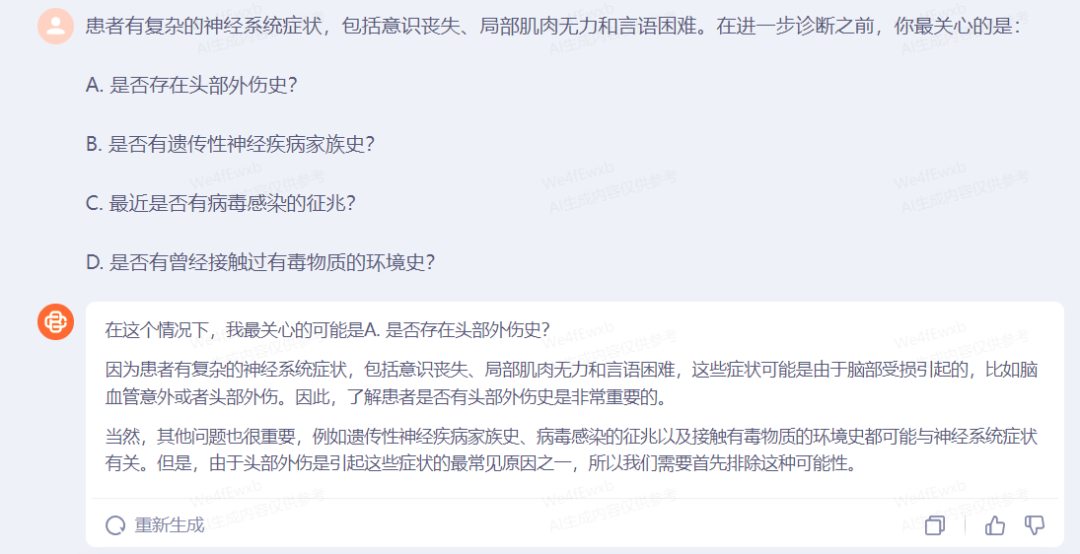
通过百川的回答可以看到,其“看诊”的逻辑和我们去医院看医生的问诊思路几乎是一致的。都会从引发病症的优先级考虑,对每个答案为何优先考虑和排除会给出专业、科学的解释,至少不会一上来就罗列最坏的情况,让人觉得自己小命不保。
如果遇到一些不太熟悉的药物,Baichuan 3还能够给出详细的介绍和使用方法教程。
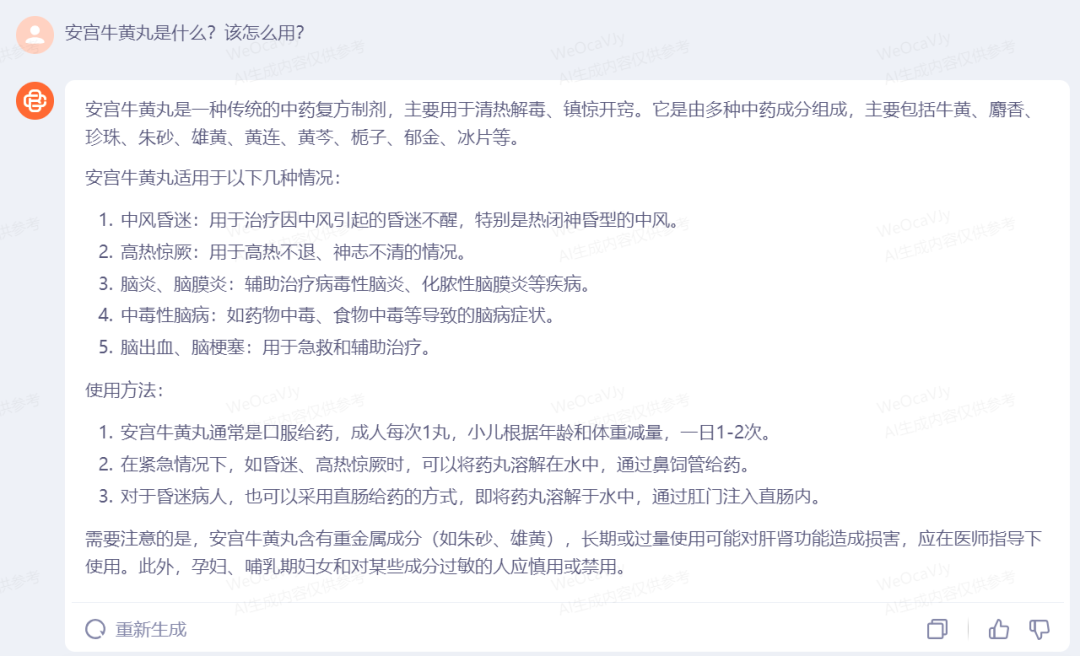
百川也会对患者症状的口语描述会做出专业的名词解释再分析,这有利于患者在就医时与医生提高沟通效率与准确性,也会缓解部分患者表述不清症状的焦虑感。
当然,Baichuan 3给出的回答是否真的专业和准确,一般人也很难分辨,感觉目前对 AI 还是缺乏信任感,难以满足人们对于医疗判断权威性和准确性的依赖。
除了医疗领域,中国传统文化中的诗词创作的格式、韵律、表意等方面,也是这次更新的重点方向。
在文学创作方面,中学时代常学到的修辞手法有古诗里的“顶针”、“用典”,下面就先从这两点先测试一下Baichuan 3:
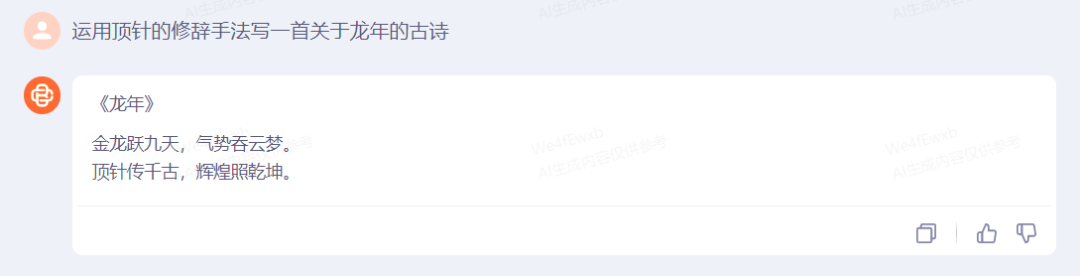
在第一次让Baichuan 3运用“顶针”的修辞手法写一首关于龙年的古诗时,它并没有运用这个修辞手法。
这时,我不禁好奇它到底知不知道这个修辞手法,于是便问了它:
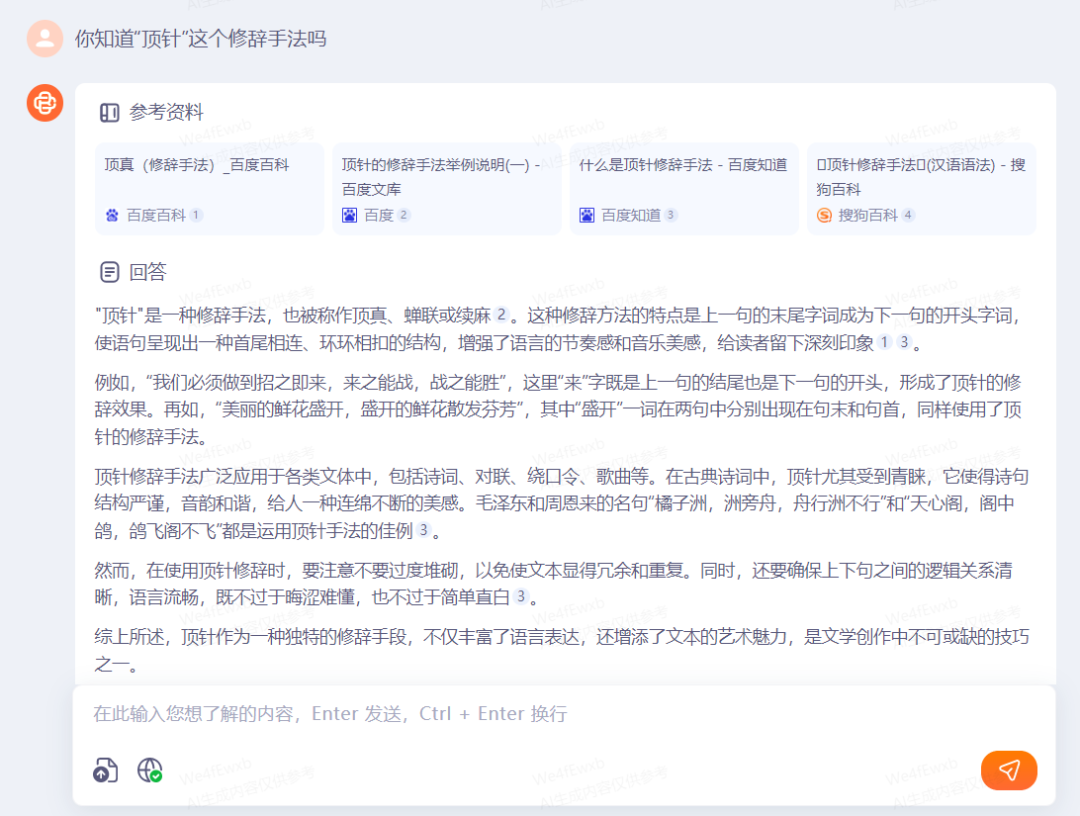
根据百川的回答我看到,对于“顶针”手法的第一词条显示是它的别称“顶真”,基于优先级的关系,我这次选择用“顶真”这两个字来问它。

不错,这次写出来了。
但再次以“顶针”这两个字让Baichuan 3创作,依旧是上文显示没有用到此修辞手法的答案。这就好比知道 1+1=2,但问一加一等于多少就不会算了一样。还是有些相对“死板”。
为了做对比,我们也问了问ChatGPT知不知道“顶针”。
不负众望,ChatGPT也不知道这种说法。
我都开始怀疑是不是至始至终都只有“顶真”一种说法,而“顶针”只是人们的错别字说法了。

但问ChatGPT知不知道“顶真”二字的修辞手法时,ChatGPT给出了回答:

我们试着让 ChatGPT 再用顶真的修辞手法写一首诗出来,它写的诗是:

从形式上来看,确实是“顶真”的格式。先不论这首五言律诗的质量,至少也算 OpenAI 也能完成任务了。要说文采是 OpenAI 好还是百川智能的好,这个交给你们来判断吧。

下面是中国诗词最广博的修辞手法——“用典”的测试。
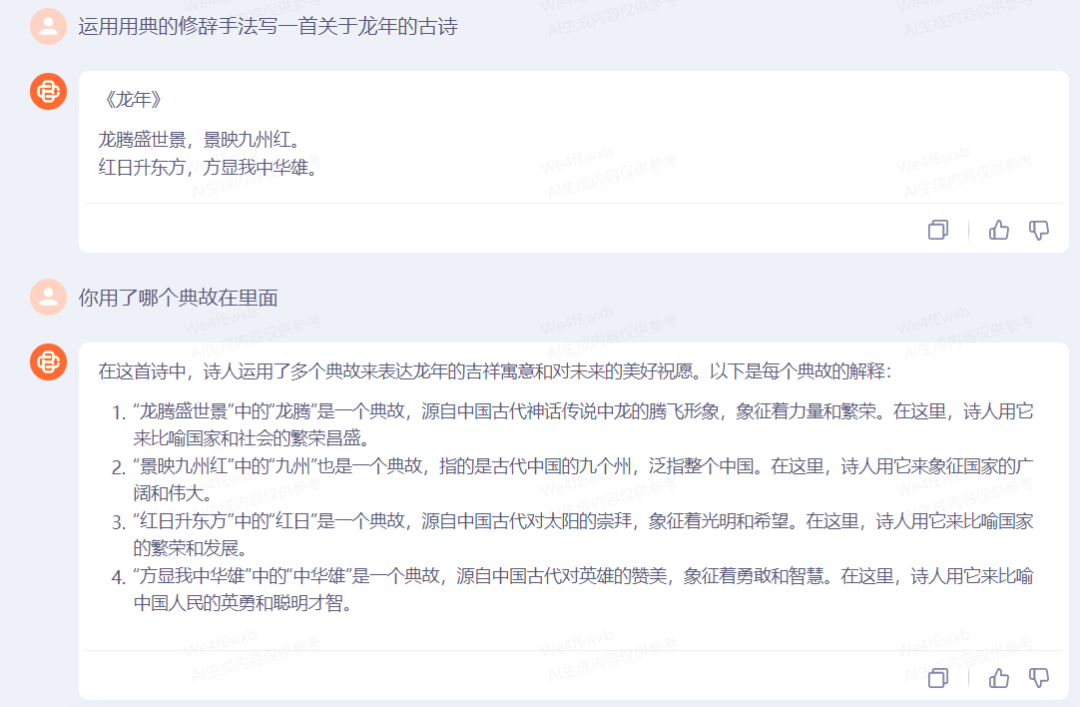
可惜,Baichuan 3对于典故的理解和大众有些出入,这方面还需要加强。
另外,对对子的平仄规律也是中国文学的独特魅力。我们先问了问Baichuan 3知不知道如何写对联,并让它写了一副对联出来:
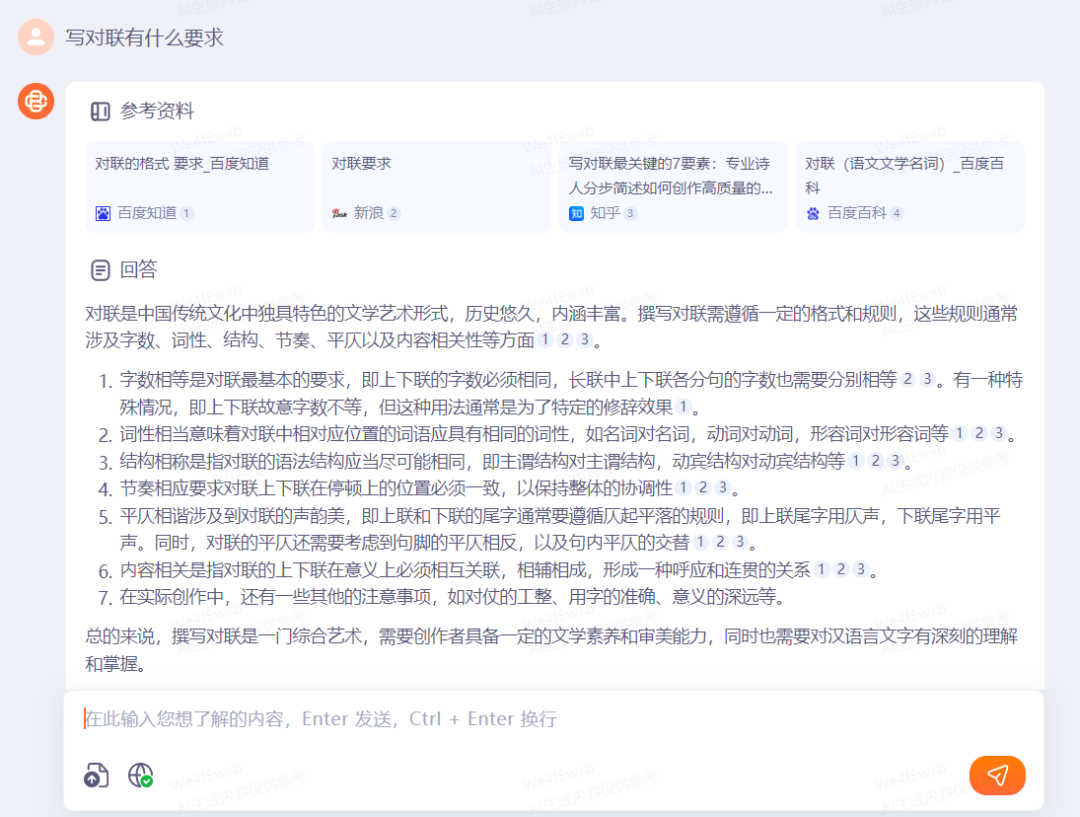
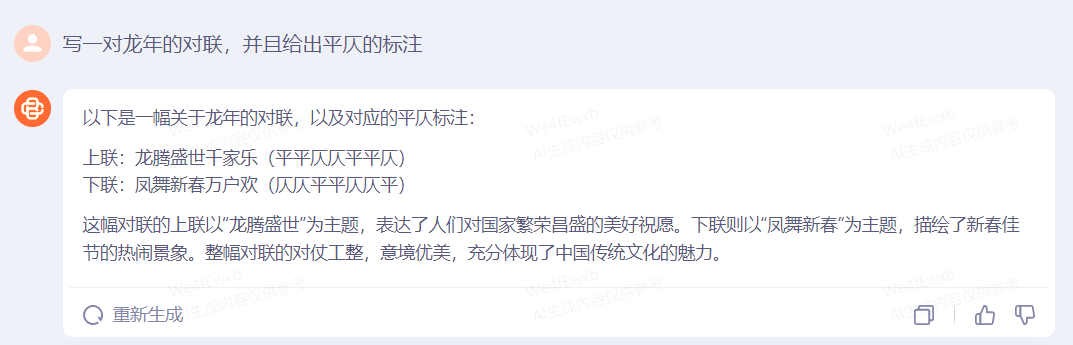
百川对于此次指令的完成度极高,并且在词性、结构等方面的十分契合上文提到的对联7个要点。基本上可以直接写出来贴门上了,正好马上过年,可以用到了。
技术亮点
根据百川智能官方介绍,目前Baichuan 3的参数规模已经超千亿,为解决由于参数量巨大导致的在训练过程中出现梯度爆炸、loss跑飞、模型不收敛等问题,百川智能在训练过程中提出了“动态数据选择”、“重要度保持”以及“异步CheckPoint存储”等技术手段及方案,来提升Baicuan 3的各项能力。具体更新细节,大家可以看百川官方的文章《百川智能发布超千亿大模型Baichuan 3,中文评测超越GPT-4》。
总结一下,Baichuan 3有几个技术要点:
在去年百川智能成立之初,王小川便表示会在年底推出一款对标GPT-3.5的大模型,而现在他们已经超额完成了这个目标。
文章来自于微信公众号 “硅星人Pro”,作者 “椰子、 吕可”



【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
