# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文第一作者谢之非,共同第一作者马子阳皆是来自于南洋理工大学的博士生。通讯作者为新加坡国立大学特聘教授颜水成和南洋理工大学数据与科学系校长讲席教授苗春燕。共同作者为腾讯AI首席专家叶德珩和新加坡国立大学博士后研究员廖越。
两千多年前,孔子说过「三思而后行」。这句古老箴言,其实点出了人类面对复杂问题的核心智慧:一步步推理,层层拆解,最终做出可靠的决策。
现在,已有诸多模型在复杂推理方面展现出显著进展,如 DeepSeek-R1 和 OpenAI o1,部分多模态系统甚至能够处理跨领域的复杂任务,展现出解决复杂现实问题的潜力。然而,在端到端对话模型中,推理能力尚未解锁。
原因并不复杂。深度思考意味着模型往往需要在输出前生成完整推理链,而这直接带来延迟。对于语音对话系统而言,速度与质量同样关键。一旦停顿过长,哪怕答案再精妙,也会破坏交互的自然感。
设想一个场景:你问语音助手「这份研究报告的结论可靠吗?」。如果模型沉默十秒才给出语音的回复,则完全失去对话的体验;若它立刻回答,但推理缺乏深度,又容易显得表面化。问题在于:要么得到一个「强大但反应迟钝」的助手,要么得到一个「迅速但思维简单」的助手。鱼与熊掌,似乎不可兼得。
基于这一挑战,我们提出了 Mini-Omni-Reasoner——一种专为对话场景打造的实时推理新范式。它通过「Thinking-in-Speaking」实现边思考边表达,既能实时反馈、输出自然流畅的语音内容,又能保持高质量且可解释的推理过程。

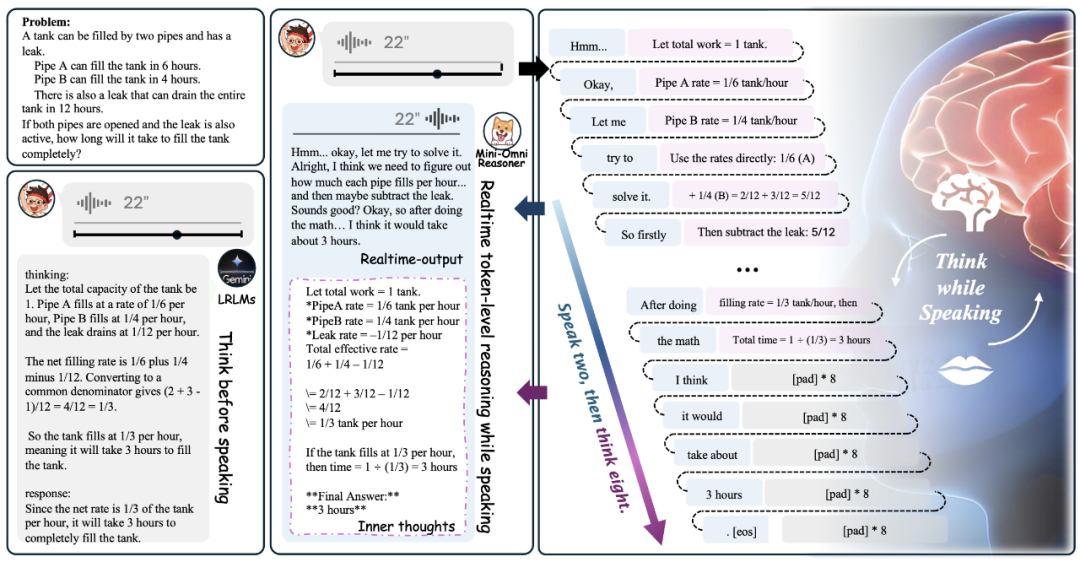
Mini-Omni-Reasoner 正是受到这一启发,探索「边思考,边表达」的新范式。它允许模型在生成回答的同时进行内部推理,实现 token 级别的思维流与输出流交替生成。这样既能保留逻辑深度与可解释性,又能提供自然、低延迟的交互体验。
「Thinking-in-Speaking」推理范式:传统推理模型遵循「thinking-before-speaking」路线:先完整生成推理链,再一次性给出答案。逻辑虽完整,但交互性差,用户必须等待较长时间。尤其在语音交互场景下,这种长时间的停顿极大削弱了使用体验。
Mini-Omni-Reasoner 提出的则是「thinking-in-speaking」范式。模型在生成过程中同时维护两条流:回答流(response stream)和推理流(reasoning stream)。二者像两支交错前进的队伍,一边输出用户可听到的回答,一边在后台继续进行逻辑演算。
通俗理解为:模型循环输出 p 个回答 token + q 个推理 token,直到完成任务。用户感受到的是自然、几乎无停顿的对话,而模型在内部始终维持严谨的推理链。整个推理过程如下。
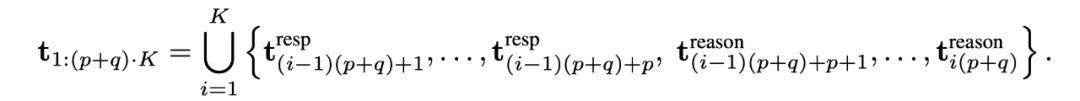
这种机制突破了「要么快,要么准」的二元困境,让「会想、会说」真正成为可能。
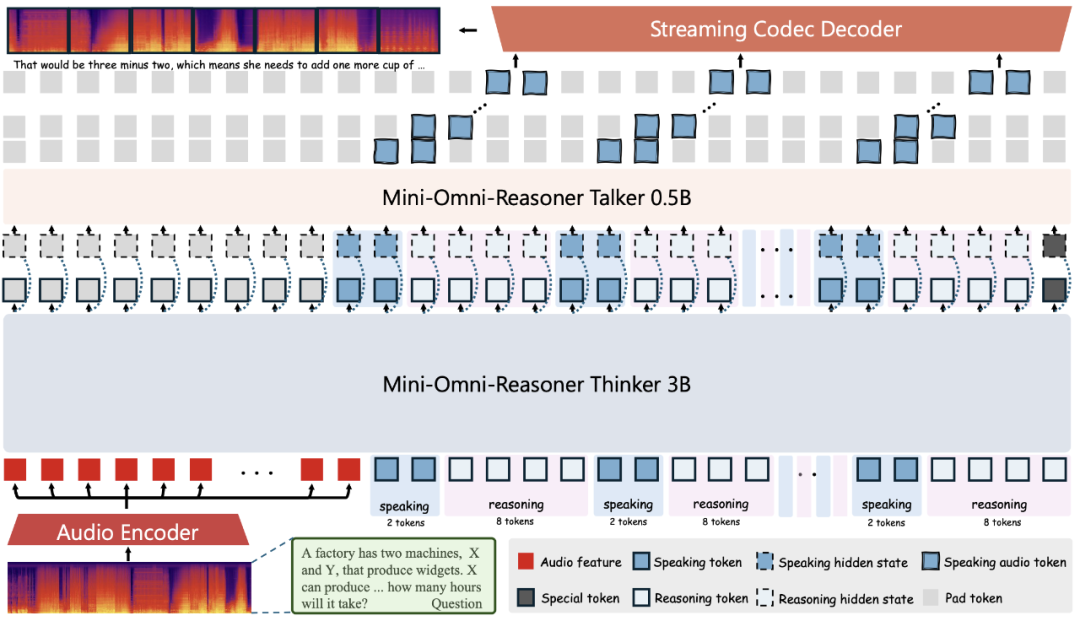
模型架构:Mini-Omni-Reasoner 采用了 Thinker-Talker 架构,像一对分工明确的搭档:
这种解耦方式的好处很直观:Thinker 全力搞逻辑,Talker 专心搞对话,谁也不分心。
2:8 Token 交替设计:我们最终选择了 2:8 的回答–推理 token 比例,背后有几层考量:
结合实验结果,我们发现推理链长度大约是回答的 2~3 倍,因此 2:8 是一个平衡点:既保证推理深度,又能保持实时语音合成的流畅性。比如,当模型每秒生成 50 token,就能给用户带来 10 个回答 token——对实时对话来说已经非常充裕。
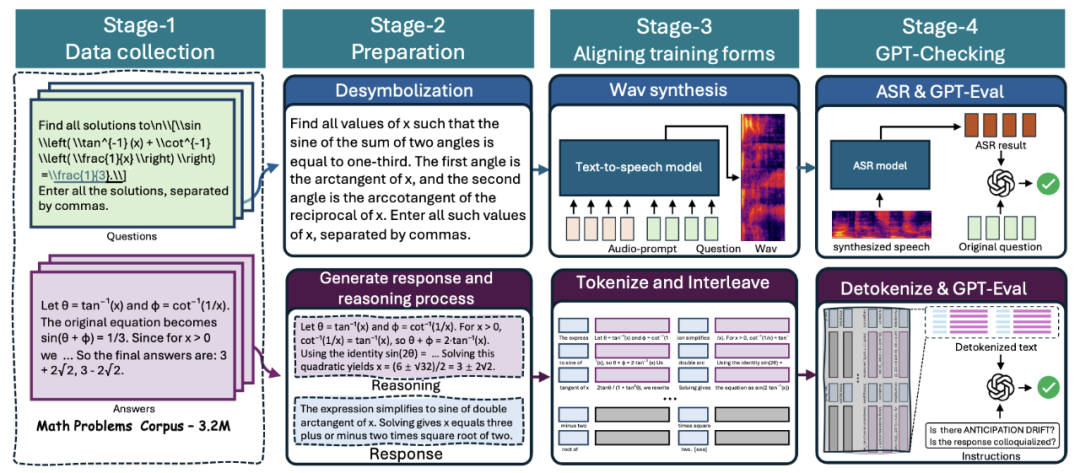
仅有架构还不够,要真正掌握「边思考边表达」,还需要精心设计的数据与训练流程。为此,我们构建了 Spoken-Math-Problems-3M 数据集,并设计了严谨的数据管线。
在数据构建中,我们面临一个核心挑战——解决**「逻辑错位」(Anticipation Drift)**问题。即如何防止模型在回答时「抢跑」,说出推理流中尚未得出的结论。我们为此设计了两大核心策略:
通过上图中的四阶段数据管线,我们为 Mini-Omni-Reasoner 提供了超过百万份高质量的训练数据。
训练 Mini-Omni-Reasoner 需要一个精心设计的五阶段管线,因为模型不仅引入了定制化架构,还采用了全新的输出形式。为了确保稳定收敛并有效将文本推理能力迁移到语音,我们将训练过程分解为五个逐步递进的阶段,总体思路为先在文本模态中保持或增强推理能力,再将其与语音模态对齐。
为了验证 Mini-Omni-Reasoner 的有效性,我们在 Spoken-MQA 数据集上测试了模型与多种不同类型方法的对比,模型相比于基座模型 Qwen2.5-Omni-3B 有明显的性能提升。
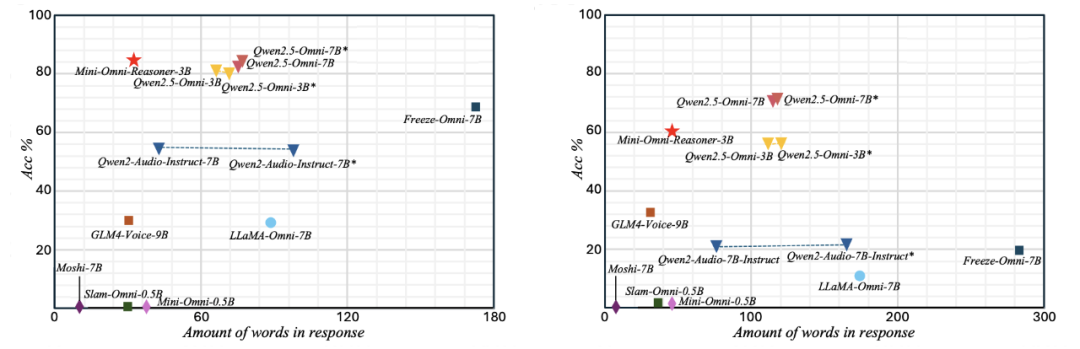
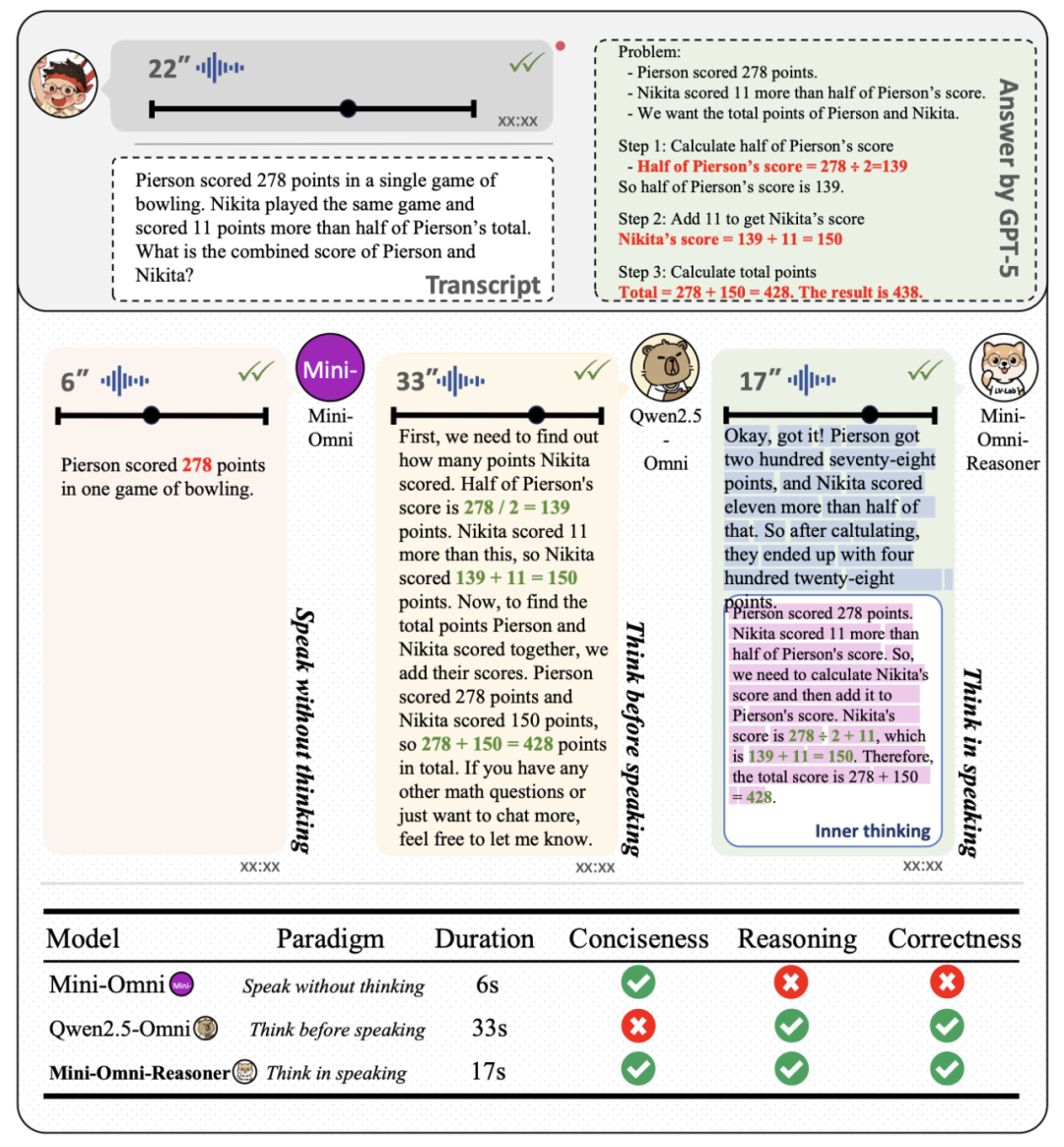
为了进一步展现 Mini-Omni-Reasoner 与传统的对话模型和基础模型 Qwen2.5-Omni 模型的区别,我们分析了针对同样问题不同模型的回答结果:实验证明「Thinking-in-Speaking」方法可以有效地在保持回复内容自然简洁的情况下保持高质量的推理过程。
当下,大模型的推理能力已逐渐成为解决复杂问题的核心驱动力。但遗憾的是,这一能力在对话系统中仍未被真正释放。为此,我们提出了 Mini-Omni-Reasoner——一次早期的尝试。诚然,它距离成熟应用还有很长的路要走,但「thinking-in-speaking」的实时推理机制,我们相信正是对话模型迈向复杂问题解决的必经之路。
展望未来,我们认为至少有几个值得深入探索的方向:
总的来说,Mini-Omni-Reasoner 并非终点,而是一个起点。我们更希望它能成为抛砖引玉,引发学界和产业界对「对话中的推理能力」的持续关注与探索。
文章来自于微信公众号 “机器之心”,作者 “机器之心”


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
