# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大家好,我是袋鼠帝
今天给大家分享一个关于全自动构建n8n工作流的方案。
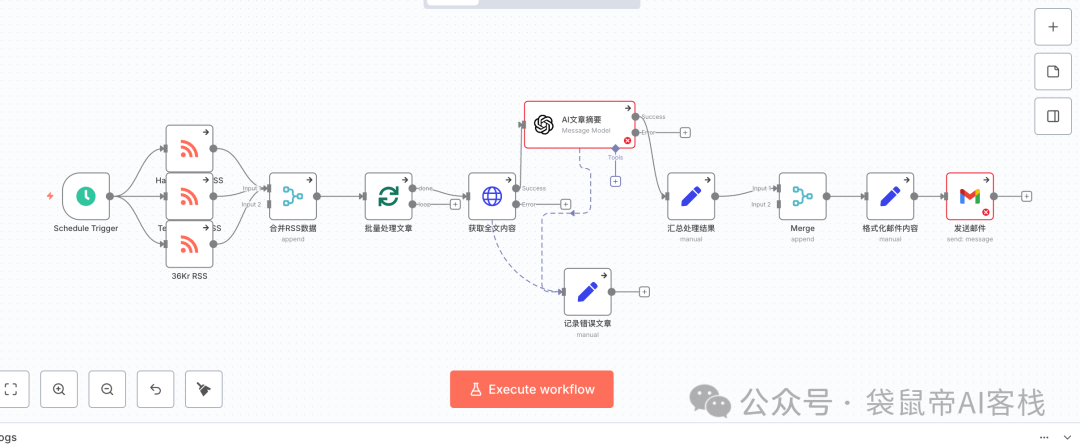
下面这个相对复杂的每日新闻n8n工作流,就是AI花了几分钟,我完全没怎么动脑,AI全自动帮我生成的。
我在之前,我分享了不少关于n8n的文章,也贡献了一些n8n的工作流,但我始终没有详细的教大家如何去搭建一个工作流。
因为我觉得n8n的工作流,其实就是代码,只不过并不是那些主流的编程语言(没有被很好的训练到大模型中),总有一天能够完全让AI帮我们写工作流,就像现在AI编程一样。
我在5月份的文章中也尝试、并分享过,让AI帮我写n8n工作流。
因为n8n可以把工作流导出为json,同样也可以把json导入n8n。
之前那篇文章采用的是喂给AI一些n8n的模板,以及相关资料,作为上下文,让AI直接生成n8n的json,然后我们导入n8n来使用
但是这里面有两个问题:
1.n8n迭代速度非常快,版本一直在更新,有些节点要么被遗弃了,要么语法或者使用方式不同了。导致我们的上下文需要经常手动维护。
2.给的上下文不够全面,导致最终生成的n8n工作流漏洞百出。
现在有一个全新的方案,完全解决了上述的两个痛点
这个方案的核心是一个目前只有7K Star的开源项目:n8n-mcp
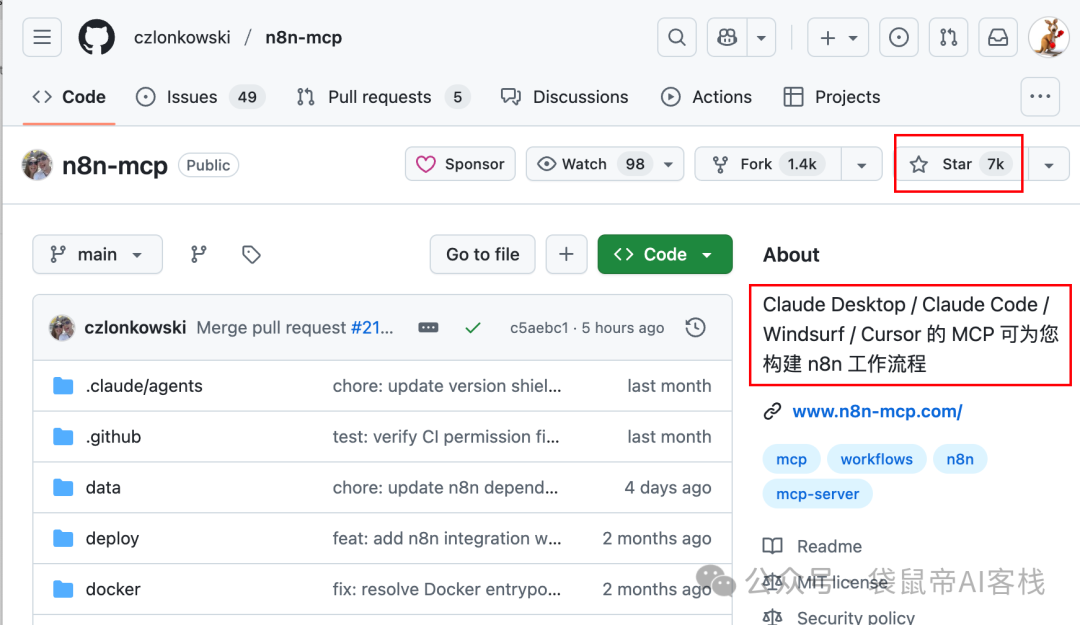
简单来说,n8n-mcp是一个专门为AI Agent(比如Claude Code,Trae,codebuddy,Vecli,codeX等)打造的n8n外挂知识库。
它的核心作用是让AI能够深度理解和使用n8n。
有了它,AI就拥有了一个实时、准确、全面的n8n官方文档和工具信息库。
它可以让AI Agent:
精确查找n8n 的节点(功能模块)。
准确理解每个节点的具体参数和配置。
验证工作流配置是否正确,避免部署后出错。
复用社区里数千个现成的工作流模板。
直接操作你的n8n,自动创建、更新和执行工作流(前提是配置了API和apikey),而不是生成json文件导入使用。
通过Github项目解读神器Zread,可以深度解读这个开源项目:
https://zread.ai/czlonkowski/n8n-mcp
好了,话不多说,到底牛不牛,我们一起看看。
我们以三个cli工具为例,来配置n8n-mcp:
OpenAI的CodeX,腾讯的codebuddy,火山刚出的Vecli
不清楚这几个AI CLI工具的朋友,我帮你们整理了他们各自的官方文档
codeX官方文档:https://github.com/openai/codex
codebuddy官方文档:https://cnb.cool/codebuddy/codebuddy-code
Vecli官方文档:https://www.volcengine.com/docs/83927/1826758
codebuddy的mcp在下面这个文件中配置:
macOS/Linux: ~/.codebuddy.json
Windows: %USERPROFILE%\.codebuddy.json
CodeX的在:
macOS/Linux: ~/.codex/config.toml
Windows: %USERPROFILE%\.codex/config.toml
Vecli的mcp配置文件位置在:
macOS/Linux: ~/.ve/settings.json
Windows: %USERPROFILE%\.ve\settings.json
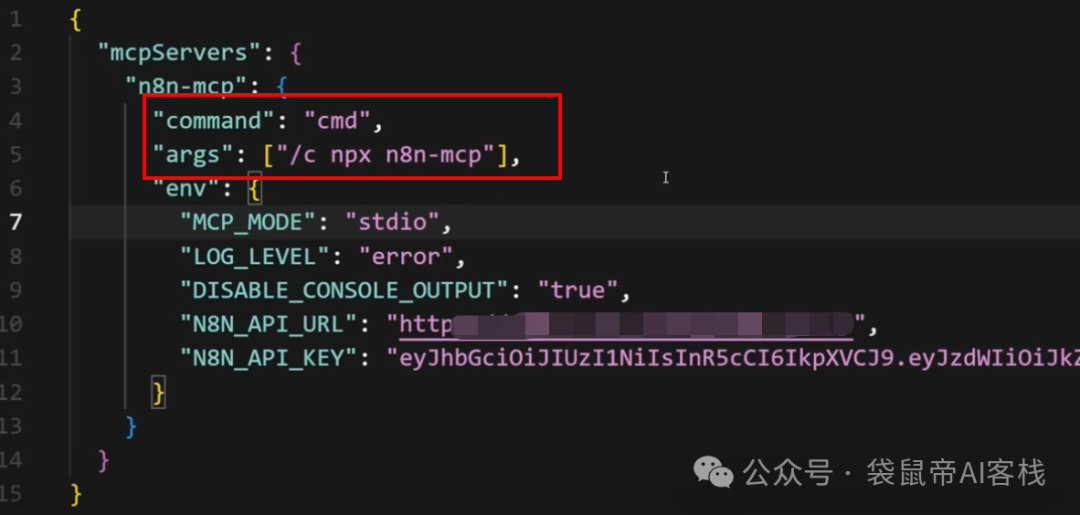
n8n-mcp的配置示例:
{
"mcpServers": {
"n8n-mcp": {
"command": "npx",
"args": ["n8n-mcp"],
"env": {
"MCP_MODE": "stdio",
"LOG_LEVEL": "error",
"DISABLE_CONSOLE_OUTPUT": "true",
"N8N_API_URL": "https://your-n8n-instance.com",
"N8N_API_KEY": "your-api-key"
}
}
}
}
如果是Windows需要把进行下图中两个部分修改
第一步:找到mcp的配置文件位置(以codebuddy为例):
macOS/Linux: ~/.codebuddy.json
Windows: %USERPROFILE%\.codebuddy.json

第二步:编辑.codebuddy.json,把n8n-mcp的配置加进去
从n8n-mcp的配置示例,可以看到有两个重要的配置:
N8N_API_URL和N8N_API_KEY
在获取这两玩意儿之前,我先把我的n8n升级一下,n8n更新太快了,每次打开github都是几小时前更新,更新频率相当高。
目前最新版是1.111.1,修改一下我的n8n docker-compose.yml文件
如果求稳定的话,不建议更新到最新版,最新版可能会有隐藏bug
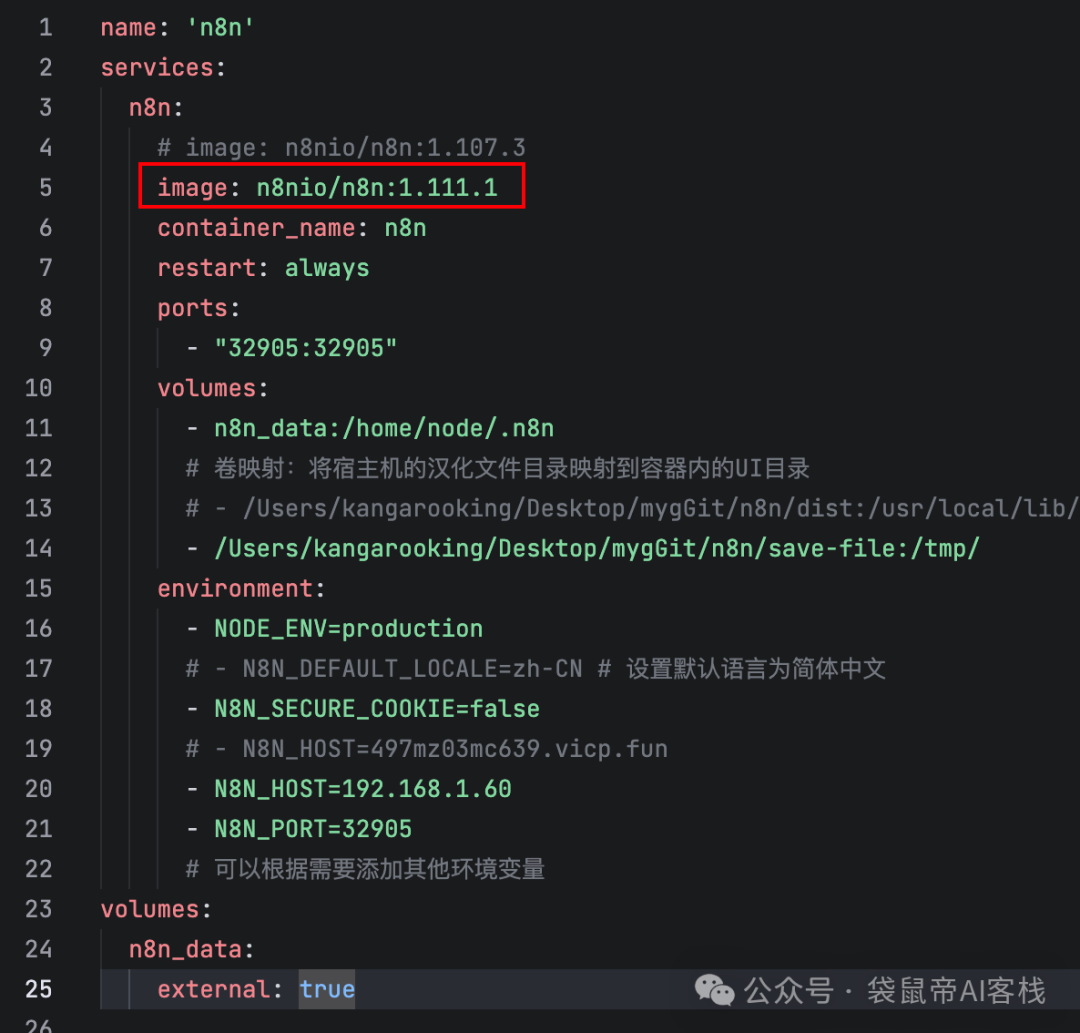
然后在该文件的当前目录的终端执行docker-compose up -d 就可以更新了。
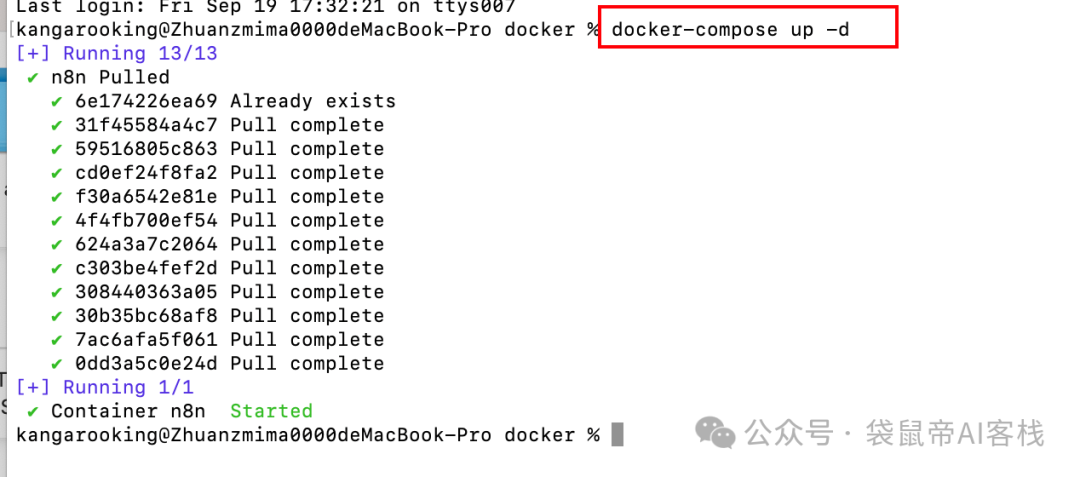
更新成功后访问 http://localhost:32905
而N8N_API_URL就是http://localhost:32905
我的端口改成了32905,正常没有改端口的话,默认是5678
大家最好用默认的,后面我也改回来5678了
n8n的apikey可以在左下角->settings->n8n API这里创建。
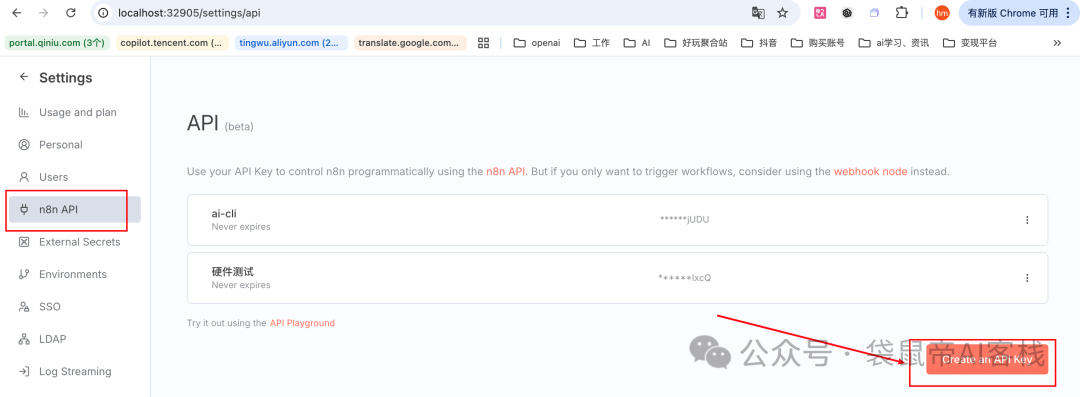
这里创建的apikey,作为n8n-mcp配置里面的N8N_API_KEY
最终.codebuddy.json里面的n8n-mcp配置如下图
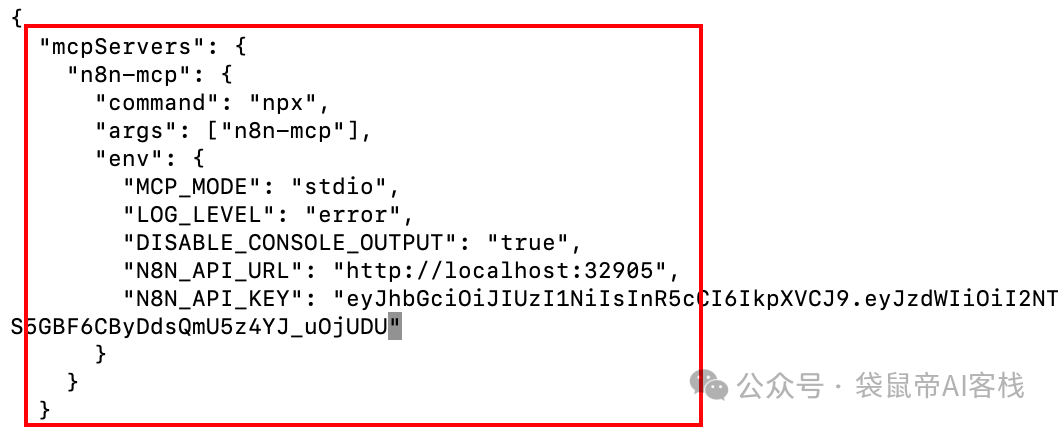
保存,然后我们重新启动codebuddy或者vecli
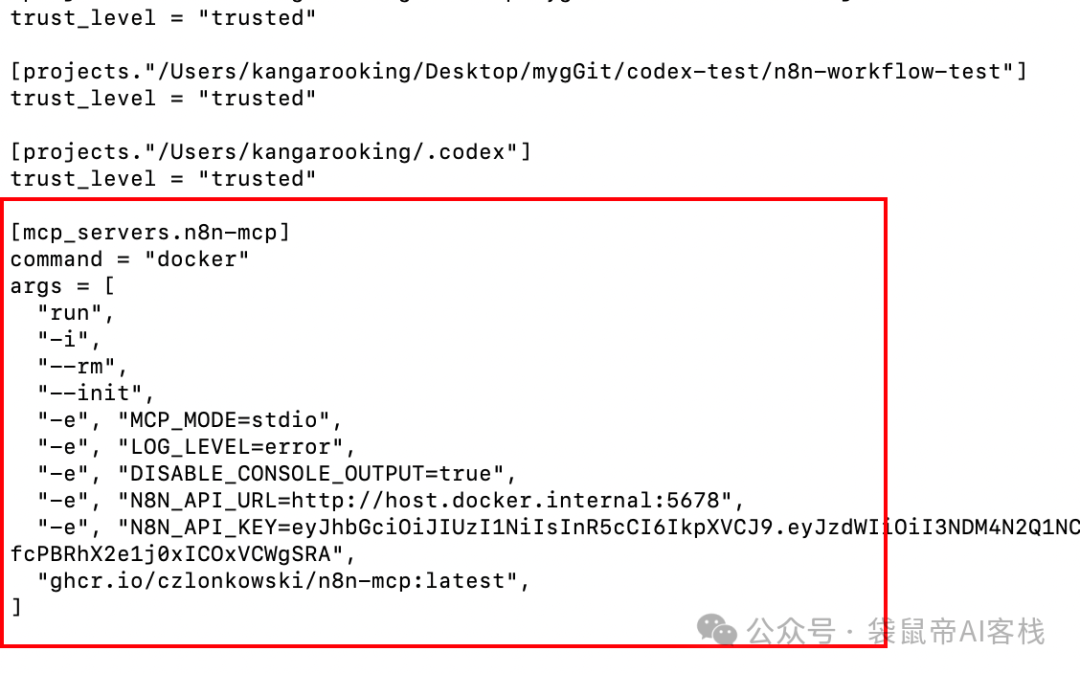
不过codex的config.toml配置mcp的格式跟其他不太一样,不是json而是toml格式,我让gemini帮我转了一下格式,最终配置如下
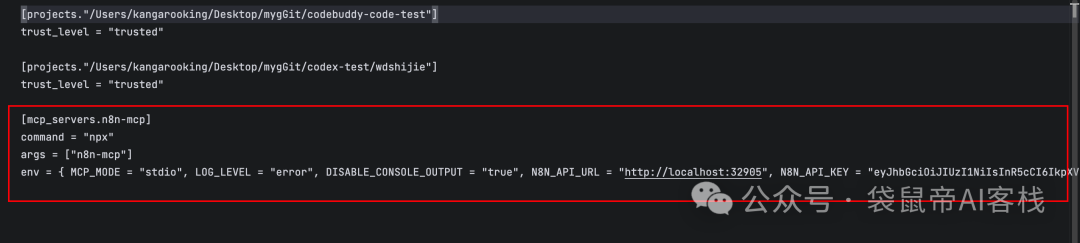
codex的n8n-mcp配置示例:
[mcp_servers.n8n-mcp]
command = "npx"
args = ["n8n-mcp"]
env = { MCP_MODE = "stdio", LOG_LEVEL = "error", DISABLE_CONSOLE_OUTPUT = "true", N8N_API_URL = "https://your-n8n-instance.com", N8N_API_KEY = "your-api-key" }
终端执行codex启动,选择允许Codex在这个文件夹中工作,且不需要每次请求批准
使用OpenAI最近新出的,专门用于Codex的GPT-5-Codex模型

然后,就遇到一个卡点,这个Codex死活都安装不上mcp,用了这么多个AI CLI,头一次遇到这种基础的功能都有bug的情况...
各种查资料,看issues,都没用,每次尝试了一些方案之后,每次都告诉自己,这篇的目的不是解决Codex的bug,而是介绍n8n-mcp
但是作为程序员的那种钻牛角尖的劲上来之后,控制不住自己的想要去解决,不然浑身难受,我知道这样是在浪费时间,但就是忍不住...
最终浪费了我2个多小时,我暂时放弃了
于是我换成codebuddy海外版,以及Vecli我也试了一下,居然都不行。
不知道为啥本地的npm方式就是不行(有清楚的朋友请评论区指点指点,感谢~)。。。
最后我换成了n8n-mcp的docker的方式
先执行:
docker pull ghcr.io/czlonkowski/n8n-mcp:latest
docker方式的mcp配置示例:
{
"mcpServers": {
"n8n-mcp": {
"command": "docker",
"args": [
"run",
"-i",
"--rm",
"--init",
"-e", "MCP_MODE=stdio",
"-e", "LOG_LEVEL=error",
"-e", "DISABLE_CONSOLE_OUTPUT=true",
"-e", "N8N_API_URL=http://host.docker.internal:5678",
"-e", "N8N_API_KEY=your-api-key",
"ghcr.io/czlonkowski/n8n-mcp:latest"
]
}
}
}
codex的配置示例:
[mcp_servers.n8n-mcp]
command = "docker"
args = [
"run",
"-i",
"--rm",
"--init",
"-e", "MCP_MODE=stdio",
"-e", "LOG_LEVEL=error",
"-e", "DISABLE_CONSOLE_OUTPUT=true",
"-e", "N8N_API_URL=http://host.docker.internal:5678",
"-e", "N8N_API_KEY=n8n的apikey",
"ghcr.io/czlonkowski/n8n-mcp:latest",
]
注意:如果你的n8n是在本地docker中启动的,那么
N8N_API_URL是http://host.docker.internal:5678
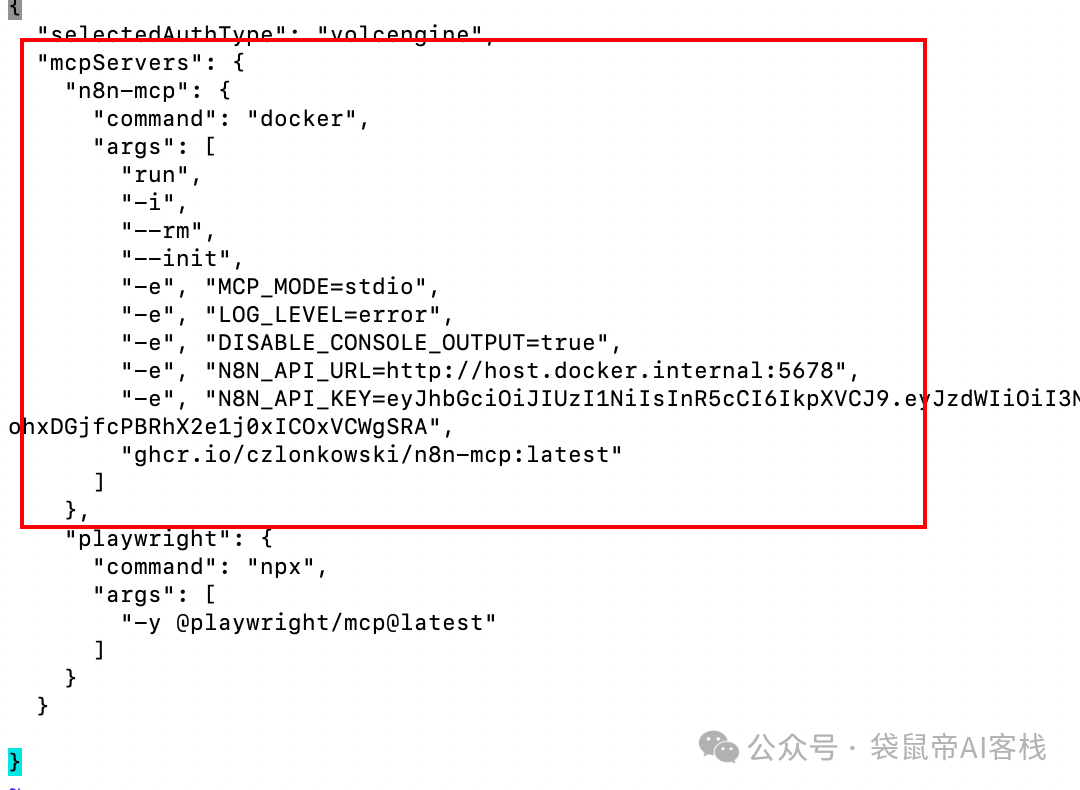
最终vecli和Codex中的配置如下:
左边是json格式,右边是toml格式
接下来就开始测试,还是要先重启这些cli工具。
我发现codex反而有点不稳定,它老是给我生成n8n的json文件。
最后我用codebuddy code,和搭配了kimi-k2的vecli以及搭配glm-4.5的Claude Code跑出了好几个n8n工作流。
从简单到复杂,主要是3个案例
最终生成的工作流如下(完全没有动手,AI直接在n8n里面创建):
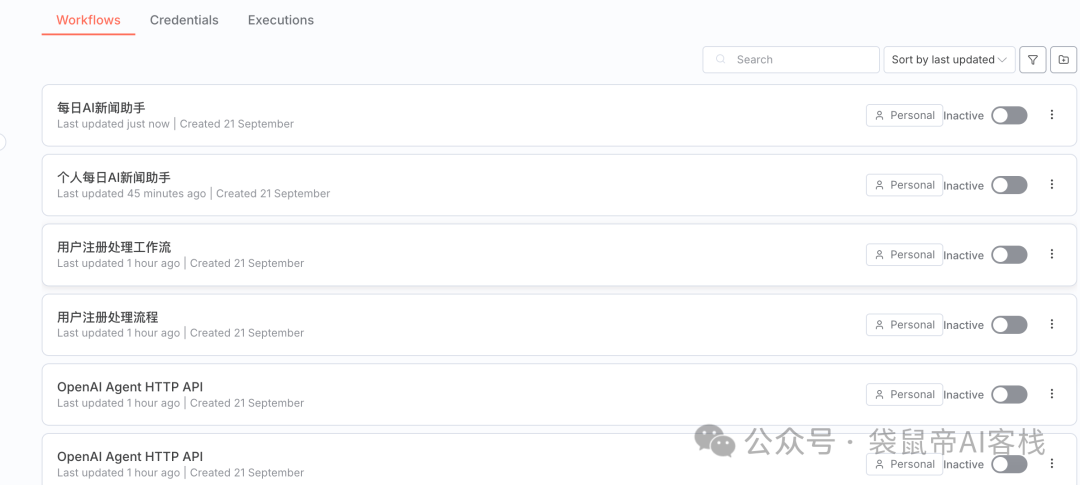
第一个案例,比较简单
帮我创建一个带Agent的n8n工作流,使用OpenAI的大模型,对外提供HTTP调用
它按照要求完成的不错(只不过需要我们配置一下OpenAI的apikey啥的):
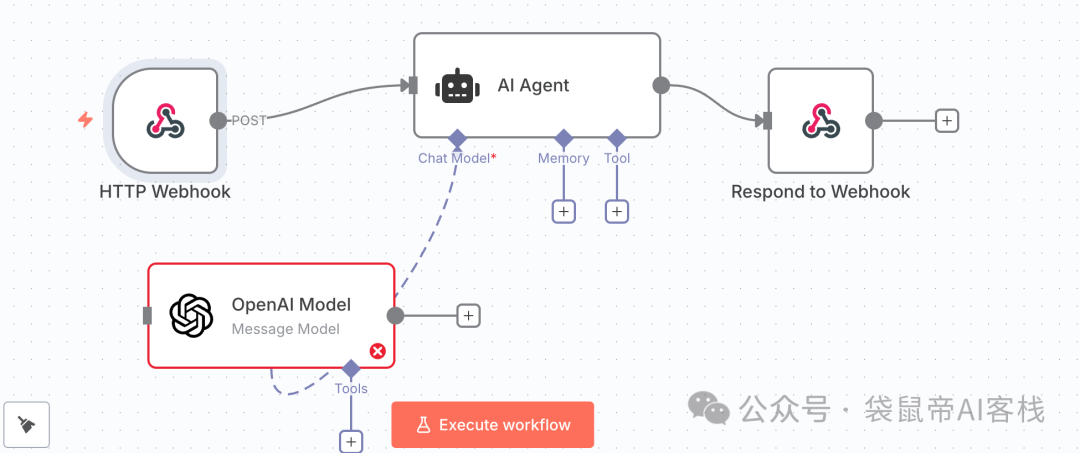
第二个中等难度的案例(提示词由gemini生成):
我需要一个 n8n 工作流来处理用户注册。具体流程如下:
触发器:使用 Webhook 节点接收来自网站表单的 POST 请求,请求的 JSON 数据包中会包含 name 和 email 字段。
条件判断:使用 IF 节点检查接收到的 email 字段。如果邮箱地址不包含 "gmail.com" 并且也不包含 "outlook.com",则判定为真。
操作:当 IF 节点的条件为真时,执行下一步操作,将新用户的 name 和 email 添加到指定的 Google Sheets 电子表格中的新一行。
请生成这个包含 Webhook、IF 和 Google Sheets 节点的自动化工作流,并在 IF 节点中写好判断表达式。
生成效果如下:
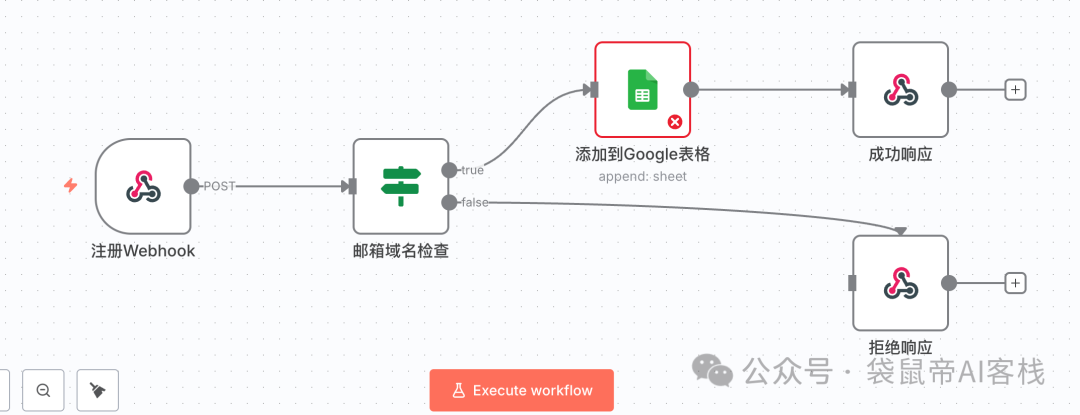
最后一个案例最难(提示词由gemini生成)
我需要创建一个强大的 n8n 工作流,作为我的个人每日新闻助手。它需要能自动完成信息的抓取、AI 总结和汇总发送。具体需求如下:
定时触发:使用 Cron 节点,设定在每天早上 8 点自动运行。
多源信息获取:使用 2-3 个并行的 RSS Feed 节点,分别订阅不同科技新闻网站的 RSS 源(例如 Hacker News, TechCrunch, 36Kr)。
数据合并与循环:将所有 RSS 源获取到的文章条目合并成一个列表,并确保能对列表中的每一篇文章进行逐一处理。
获取全文(关键步骤):对于列表中的每一篇文章,使用 HTTP Request 节点访问其 link 字段对应的 URL,以获取完整的网页 HTML 内容。
AI 总结(核心能力):将获取到的 HTML 全文内容传递给 OpenAI (或其他大语言模型) 节点。给 AI 的指令是:“请从以下 HTML 内容中提取正文,并将其总结为三个核心要点(bullet points),请用中文回答。”
数据汇总:在处理完所有文章后,将每篇文章的标题、原始链接以及 AI 生成的三个核心要点,聚合成一个单一的、结构化的文本块,准备用于邮件发送。
发送摘要邮件:使用 Gmail 或 Send Email 节点,将汇总好的内容以格式化的方式(例如使用简单的 HTML 标签)发送到我自己的邮箱。邮件标题为“今日份 AI 新闻摘要 - [今天的日期]”。
错误处理:在“获取全文”或“AI 总结”的步骤中,如果某篇文章处理失败(例如链接无法访问、AI 返回错误),工作流不应中断。它应该能跳过这篇出错的文章,继续处理下一篇,并最好能记录下失败的文章链接。
所需节点/服务:Cron, RSS Feed, HTTP Request, OpenAI (或同类 LLM 节点), Gmail (或 Send Email), 以及用于数据合并、循环和错误处理的逻辑节点。这个工作流完美地展示了 n8n 在连接 API、处理数据流和集成 AI 方面的强大能力。
这个效果挺让我惊艳的:
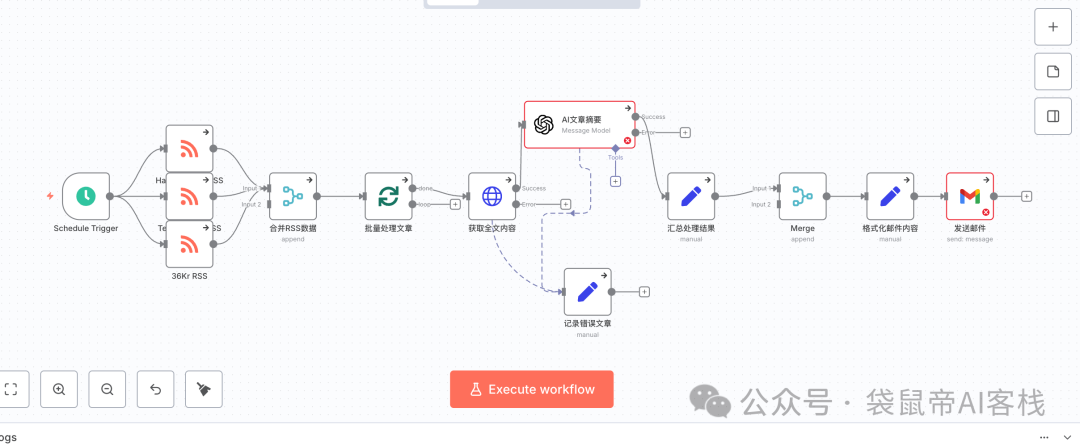
虽然目前使用n8n-mcp还无法一次性生成直接可用的n8n工作流。
但是已经比我几个月前测试的效果好多了
之前是生成n8n的json,中等难度的工作流最多只能完成50%。很多时候线都连不明白...
而现在n8n-mcp不仅给了AI充足的上下文,还结合了n8n的API接口,让AI可以自主操作n8n工作流的搭建。
这种方式一次性生成的简单工作流,大部分时候是可用的。
对于复杂工作流,一次性可以生成75%左右,并且可以边调试,边用AI进一步优化。
如果分模块小步迭代,那么一个复杂工作流,估计可以逐步完成到100%。
而且n8n可以开发子工作流,然后用多个子工作流拼装成整个功能。
这里面有两点原因:
1.是模型各方面能力提升;
2.上下文工程做得更好了(n8n-mcp)。
n8n-mcp对于小白来说它能生成一些简单的工作流用于学习,对于有一定编程基础,或者n8n使用经验的人来说,能极大提高效率。
你可能会有疑问,n8n-mcp里面的n8n节点信息从哪里来?
n8n-MCP获取节点信息的方式,既不是实时从n8n官网抓取,也不是通过API从你部署的n8n实例里获取。
它的信息来源是在项目构建时(build-time),通过解析 n8n 的源代码包和官方文档库来生成的,最终打包成一个预构建的数据库(pre-built database)。
这个过程是这样的:
当n8n-MCP的开发者准备一个新版本时,他们会在项目中引入n8n官方的npm开发包(例如 n8n-nodes-base)。这些包里包含了所有节点的最原始、最权威的定义代码。
n8n-MCP的构建脚本会做以下事情:
n8n的各个节点信息,和使用方式:
程序化读取这些源代码文件。
解析出每个节点的详细信息,比如:
节点名称 (name) 和内部类型 (nodeType)。
所有的属性(Properties),包括它们的类型(字符串、数字、选项列表等)、默认值、是否必需。
所有的操作(Operations),比如HTTP Request节点的GET, POST, PUT等。
属性之间的依赖和显示关系(比如,只有当认证方式选为API Key时,才会显示API Key输入框)。
这是最准确的技术性信息来源,因为它直接来自n8n的核心代码。
n8n的官方文档数据:
为了获取更具可读性的描述和用法说明,构建脚本还会拉取 n8n 的官方文档GitHub仓库(n8n-io/n8n-docs)。
然后,脚本会解析这些文档文件(一般是Markdown格式),提取节点描述、参数说明、注意事项等,并将这些信息与第一步从代码中提取出的节点进行关联。
预构建的数据库
脚本将上述两部分信息整合、处理后,会生成一个轻量级的SQLite数据库文件(约15MB)。
这个数据库就相当于一本n8n的离线百科全书,记录了当前版本n8n的绝大部分信息。
当使用npx或docker运行n8n-mcp时,你下载的包里已经包含了这个数据库。
所以它的响应速度非常快(平均12ms),因为它只是在本地查询这个现成的数据库,完全不需要任何网络请求。
那么,既然是离线的,如何获取最新的n8n节点信息?
答案是通过更新n8n-MCP这个工具本身来完成。
更新流程是这样的:
n8n官方发布了一个新版本(比如增加了新的节点或修改了现有节点)。
n8n-MCP的维护者会更新项目中的n8n源代码包依赖到最新版。
维护者重新运行上面提到的构建脚本,生成一个包含n8n最新信息的新版数据库。
维护者发布一个新版本的n8n-MCP(比如从 2.7.0 更新到 2.8.0),这个新版本里就打包了那个全新的数据库。
我们下一次运行 npx n8n-mcp (它会自动拉取最新版) 或者 docker pull ghcr.io/czlonkowski/n8n-mcp:latest,就获取到了包含n8n最新节点信息的n8n-mcp版本。
n8n-MCP提供的信息是打包在特定版本里的,是静态的。它反映的是其所基于的那 n8n版本的状态。
配置n8n API的作用是操作:
配置中填写的N8N_API_URL和N8N_API_KEY,是用来让AI管理你的n8n工作流的(例如创建、更新、执行)。
最后,我相信随着上下文工程,和大模型的不断发展进步,n8n工作流将完全能交给AI全自动生成。
只要Agent执行速度没有质的提升,稳定性无法达到99.9%,那么工作流就不会被淘汰。
文章来自于微信公众号 “袋鼠帝AI客栈”,作者 “袋鼠帝AI客栈”


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
