# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
羊驼家族的“最强开源代码模型”,迎来了它的“超大杯”——
就在今天凌晨,Meta宣布推出Code Llama的70B版本。
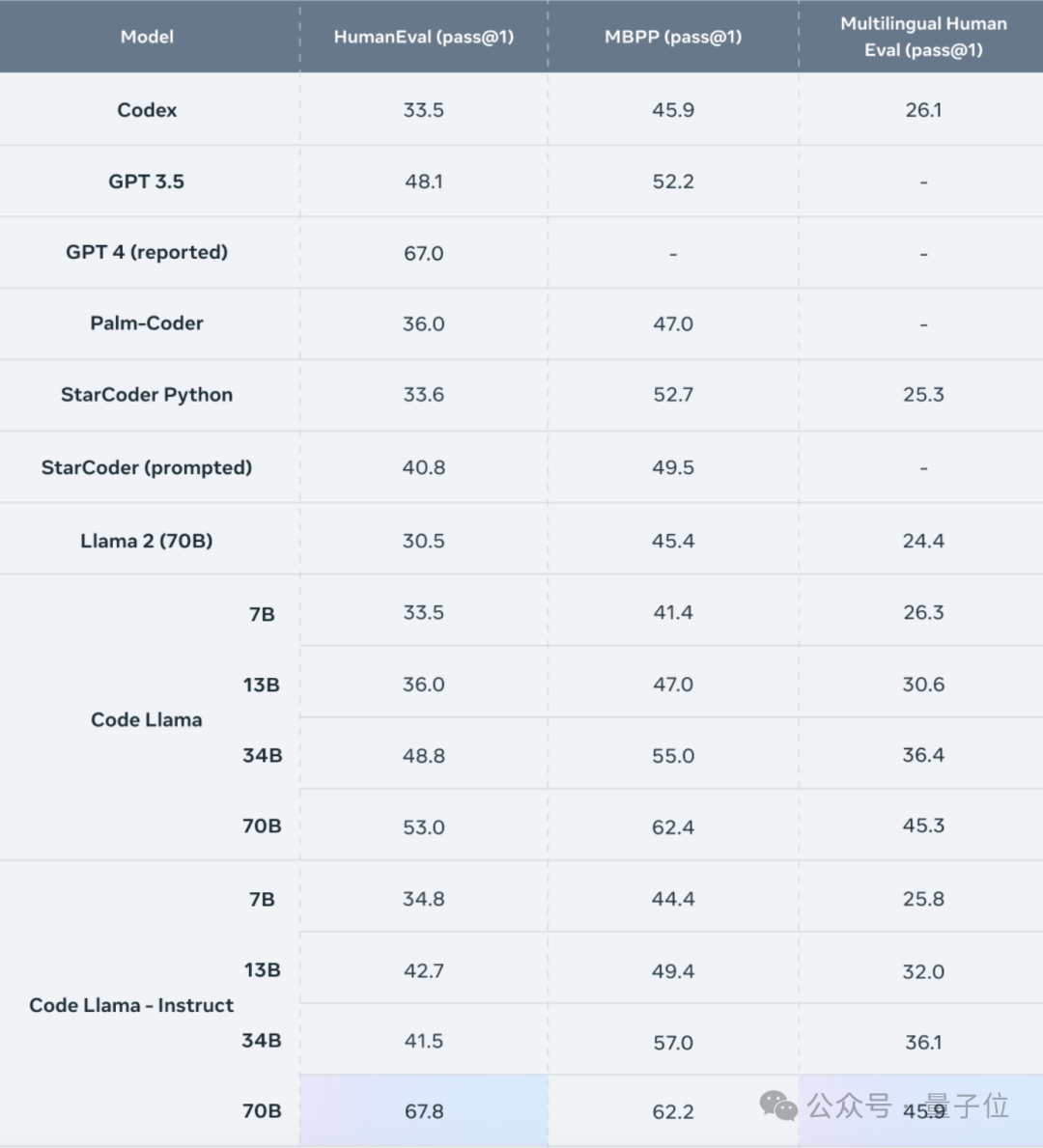
在HumanEval测试中,Code Llama-70B的表现在开源代码模型中位列第一,甚至超越了GPT-4。
此次发布的超大杯,保持着与小号版本相同的许可协议,也就是仍然可以免费商用。

版本上,也和往常一样分为原版、针对自然语言指令微调的Instruct版和针对Python微调的Python版。
其中击败GPT-4的是Instruct版本,它取得了67.8分的pass@1成绩,胜过了GPT-4的67分。
与34B模型相比,基础版和Instruct版的成绩分别提高了8.6%和63.4%。
Code Llama的所有版本均在16000个token的序列上进行训练,上下文长度可达10万token。
这意味着,除了生成更长的代码,Code Llama还可以从用户的自定义代码库读取更多内容,将其传递到模型中。
这样一来就可以针对具体问题的相关代码进行快速定位,解决了用户面对海量代码进行调试时“无从下手”的问题。
Meta CEO小扎也在个人博客中宣布了这一消息,表示为70B Code Llama感到骄傲。

而小扎的这则帖文,也被细心的网友发现了玄机。
等一下……他说的是……Llama……3?
的确,在帖文的结尾处,小扎说希望这些成果能够应用到Llama 3当中。

难道,Llama 3,真的要来了吗?
早在去年8月,有关Llama 3的传闻就已经出现,而直到上周小扎才正式透露,Llama 3的训练过程正在进行。
同时,Meta也在进一步扩充算力,预计到今年年底将拥有35万块H100。
如果将其他显卡也折算成H100,Meta总计将拥有等效于60万块H100的算力。

不过小扎透露的消息似乎没有满足网友的好奇心,关于Llama 3究竟何时能上线的讨论也不绝于耳。
Llama 2的训练用了21天,我们是不是可以期待着Llama 3差不多也是这样呢?
关于这个问题,暂时还没有官方消息,有人推测就在今年第一季度。

但可以确定的是,Llama 3将继续保持开源。
同时小扎还表示,AGI将是下一代人工智能的一大标志,也是Meta所追求的目标。
为了加速AGI的实现,Meta还将旗下的FAIR团队和GenAI团队进行了合并。

除了Llama 3这个“意外发现”,关于Code Llama本身,网友们也提出了不少问题和期待。
首先是关于运行Code Llama所需要的硬件资源,有网友期待在苹果M2 Max等芯片上就能运行。

但实际情况是,由于没有N卡用不了CUDA,Code Llama在M系苹果芯片上的运行结果并不理想。

针对N卡则有人猜测,如果对模型进行量化操作,可能4090就能带动。
也有人质疑这种想法是过度乐观,4090能带动的量化程度可能并不适用于这款模型。
但如果愿意用运算速度换取显存空间,用两块3090来代替也未尝不可。

但即便4090属于消费级显卡,大部分程序员仍然不一定有能高效运行70B模型的设备。
这也就引发了另一个问题——堆参数量,是否真的有必要?
从Pass@1排行榜中,深度求索团队的DeepSeek Coder表现就比Code Llama高出2.3分,但参数量却只有6.7B,不足后者的十分之一。

如果纵向比较,DeepSeek Coder的6.7B和33B版本仅差了2.5分,参数量带来的性能提升并没有Code Llama当中明显。

所以,除了堆参数量,Meta或许还得在模型本身上再下点功夫。

参考链接:
[1]https://twitter.com/aiatmeta/status/1752013879532782075
[2]https://ai.meta.com/blog/code-llama-large-language-model-coding/
[3]https://www.facebook.com/zuck/posts/pfbid0KccyDFLszKeHkWVssrcSJYnigb1VYfsLuExTjxVPKWzDpXgmd9FYMfZ1hcWpyf3Zl
[4]https://news.ycombinator.com/item?id=39178886



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
