
Meta大逃杀!小扎「地狱模式」曝光,不拼命搞AI就滚蛋
Meta大逃杀!小扎「地狱模式」曝光,不拼命搞AI就滚蛋面对Llama3系列的失利,小扎将2025年定义为Meta的「高强度之年」,不仅在AI上投入数百亿美金,还开启一系列「闪电战」,包括重金挖人、成立MSL、收紧绩效考核,削减元宇宙投入等。年关将近,小扎的「高强度之年」能救Meta吗?
来自主题: AI资讯
9194 点击 2025-12-27 10:38
 搜索
搜索
面对Llama3系列的失利,小扎将2025年定义为Meta的「高强度之年」,不仅在AI上投入数百亿美金,还开启一系列「闪电战」,包括重金挖人、成立MSL、收紧绩效考核,削减元宇宙投入等。年关将近,小扎的「高强度之年」能救Meta吗?
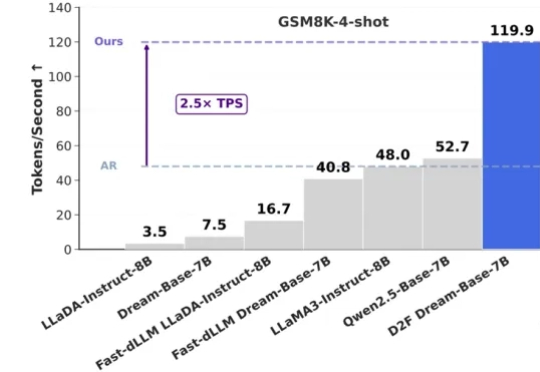
在大语言模型(LLMs)领域,自回归(AR)范式长期占据主导地位,但其逐 token 生成也带来了固有的推理效率瓶颈。此前,谷歌的 Gemini Diffusion 和字节的 Seed Diffusion 以每秒千余 Tokens 的惊人吞吐量,向业界展现了扩散大语言模型(dLLMs)在推理速度上的巨大潜力。
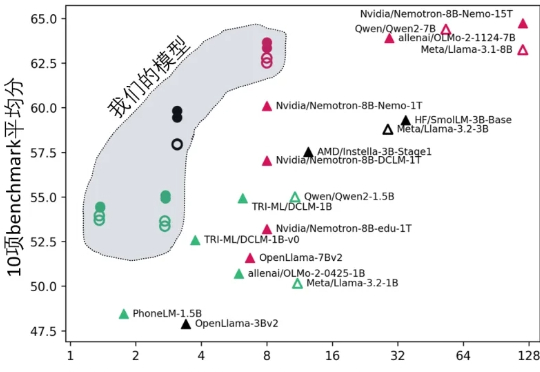
《Physics of Language Models(语言模型物理学)》,正是将AI研究带入“物理学范式”的项目,由Meta FAIR研究院的朱泽园概念化发起,并统筹设计。

来自英伟达和UIUC的华人团队提出一种高效训练方法,将LLM上下文长度从128K扩展至惊人的400万token SOTA纪录!基于Llama3.1-Instruct打造的UltraLong-8B模型,不仅在长上下文基准测试中表现卓越,还在标准任务中保持顶尖竞争力。
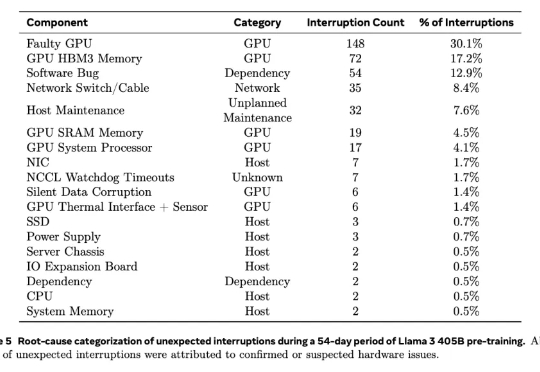
根据去年2024年7月28日Meta公司在训练大模型(Llama 3)时使用“16384 个 英伟达H100 GPU 集群”的经验,该显卡在高负载、大规模集群运行环境下容易出现以下故障点:

7B大小的视频理解模型中的新SOTA,来了!

IBM 正式发布了其新一代开源大语言模型 Granite 3.1,这是一组轻量级、先进的开源基础模型,支持多语言、代码生成、推理和工具使用,能够在有限的计算资源上运行。这一系列模型具备 128K 的扩展上下文长度、嵌入模型、内置的幻觉检测功能以及性能的显著提升。
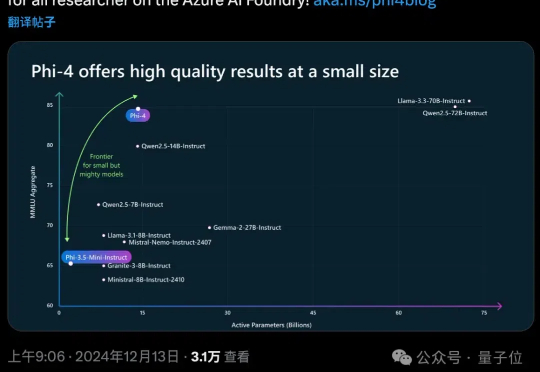
OpenAI谷歌天天刷流量,微软也坐不住了,推出最新小模型Phi-4。 参数量仅14B,MMLU性能就和Llama 3.3/ Qwen2.5等70B级别大模型坐一桌。

Llamacoder是Claude Artifacts的开源实现。 最大的亮点就是,左侧AI写代码,右侧实时渲染。 之前给大家推荐过一个基于Claude做的,Llamacoder是用了Meta 的 Llama 3.1 405B 作为底层语言模型。
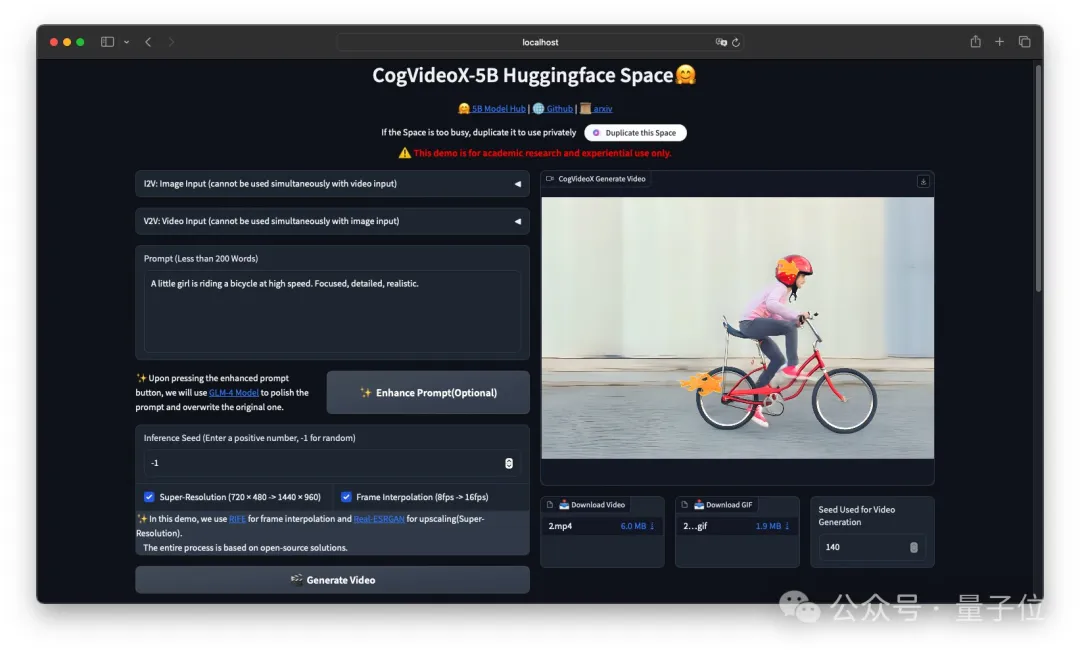
刚刚,智谱把清影背后的图生视频模型CogVideoX-5B-I2V给开源了!(在线可玩) 一起开源的还有它的标注模型cogvlm2-llama3-caption。