# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
根据去年2024年7月28日Meta公司在训练大模型(Llama 3)时使用“16384 个 英伟达H100 GPU 集群”的经验,该显卡在高负载、大规模集群运行环境下容易出现以下故障点:
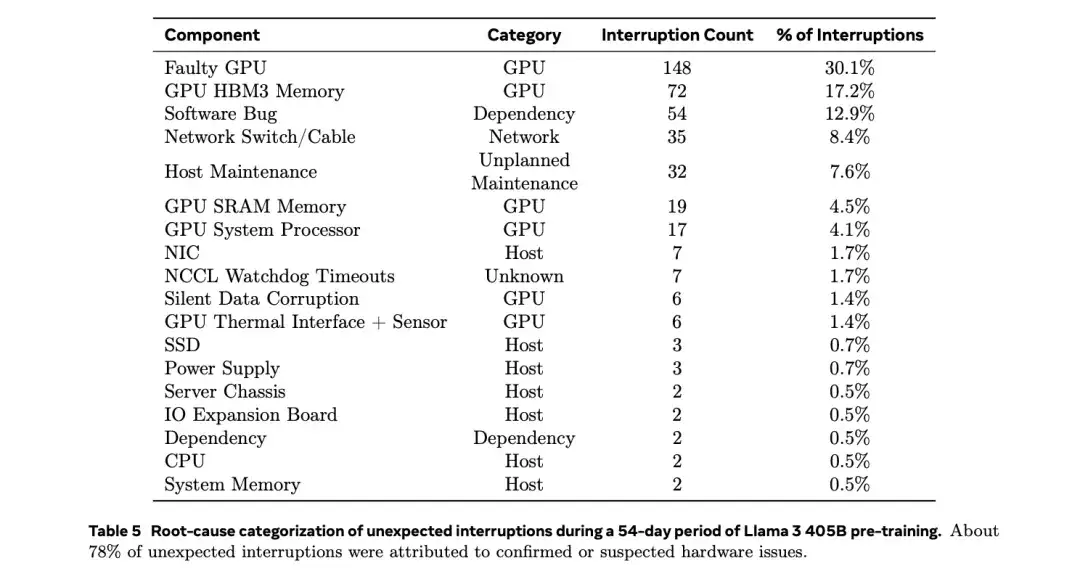
1. HBM3 高带宽内存故障
HBM3 显存是H100的关键组件之一,但在长时间高负载运行时容易出现数据损坏或物理故障。
Meta的16,384块H100集群在54天内发生了72次HBM3内存故障,占比约17.2%。
可能原因包括高温、电压波动或制造缺陷。
2.NVLink 连接问题
H100依赖NVLink 4.0进行GPU间高速通信,但NVLink接口或桥接器可能出连接不稳定或信号错误。
Meta报告148次GPU故障中,部分由NVLink问题引起,占比约30.1%。
故障可能导致训练任务中断,需重新同步计算。
3. GPU核心过热或电源问题
H100的TDP高达700W,长时间高负载运行可能导致GPU核心过热,影响稳定性。
部分故障可能与供电不稳或电源管理模块(VRM)问题有关。
Meta观察到午间温度波动会影响GPU性能,导致1-2%的吞吐量变化。
4. 散热系统故障
数据中心环境下,散热不良可能导致GPU降频或损坏。
部分H100采用液冷方案,若冷却系统失效,可能引发过热问题。
5. 软件/固件兼容性问题
虽然不算“硬件损坏”,但驱动或固件Bug可能导致GPU无法正常工作。
Meta使用PyTorch NCCL飞行记录器来诊断NVLink和RoCE网络的通信问题。
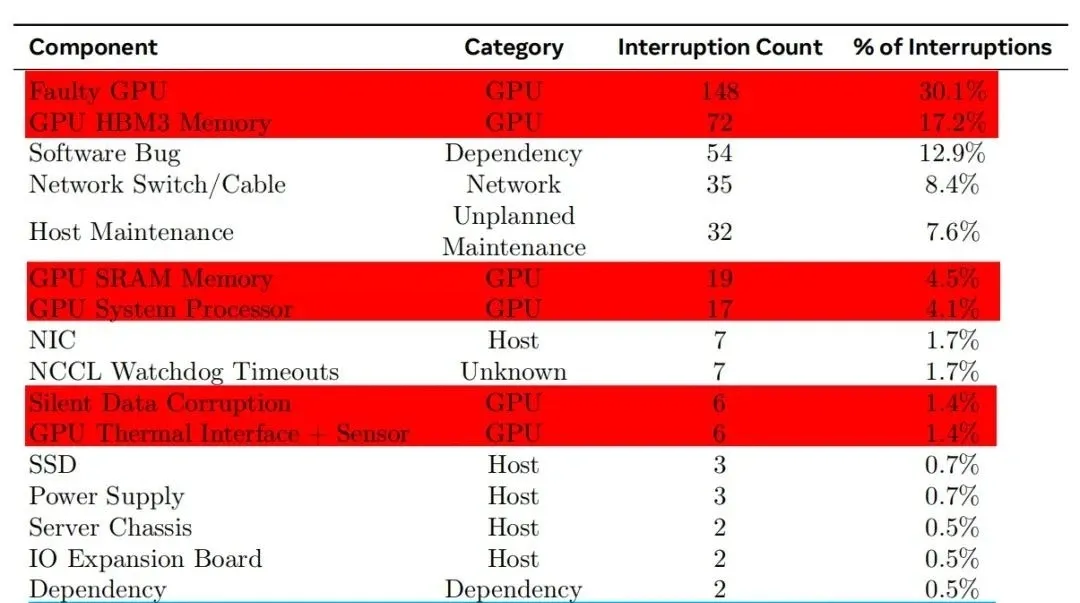
总结:H100最脆弱的组件
1. HBM3显存(易受高温、电压影响)
2. NVLink连接(通信故障率高)
3. 电源/散热系统(700W高功耗带来挑战)
对于企业用户,建议加强散热管理、定期检查NVLink连接,并采用Meta类似的自动化故障检测工具来减少训练中断。
参考链接:
https://www.inspire2rise.com/meta-faces-frequent-gpu-failures-llama-3-training.html
https://www.tomshardware.com/tech-industry/artificial-intelligence/faulty-nvidia-h100-gpus-and-hbm3-memory-caused-half-of-the-failures-during-llama-3-training-one-failure-every-three-hours-for-metas-16384-gpu-training-cluster
https://ai.meta.com/research/publications/the-llama-3-herd-of-models/
文章来自微信公众号 “ OxyAI Studio 李玉侠 “,作者 李玉侠



