花几百万买的H100在「摸鱼」?英伟达:别怪显卡,是你的模型「长得丑」
花几百万买的H100在「摸鱼」?英伟达:别怪显卡,是你的模型「长得丑」就在最近,英伟达亲自下场,发布了一篇名为《AI Model Co-Design: Hardware-Friendly LLM Design》的技术博客。整篇文章洋洋洒洒,其实就想点醒行业一件事:别光顾着堆算力了,来看看你们是怎么把顶级显卡逼成“磨洋工”的吧。
来自主题: AI技术研报
8937 点击 2026-07-22 15:21
 搜索
搜索
就在最近,英伟达亲自下场,发布了一篇名为《AI Model Co-Design: Hardware-Friendly LLM Design》的技术博客。整篇文章洋洋洒洒,其实就想点醒行业一件事:别光顾着堆算力了,来看看你们是怎么把顶级显卡逼成“磨洋工”的吧。
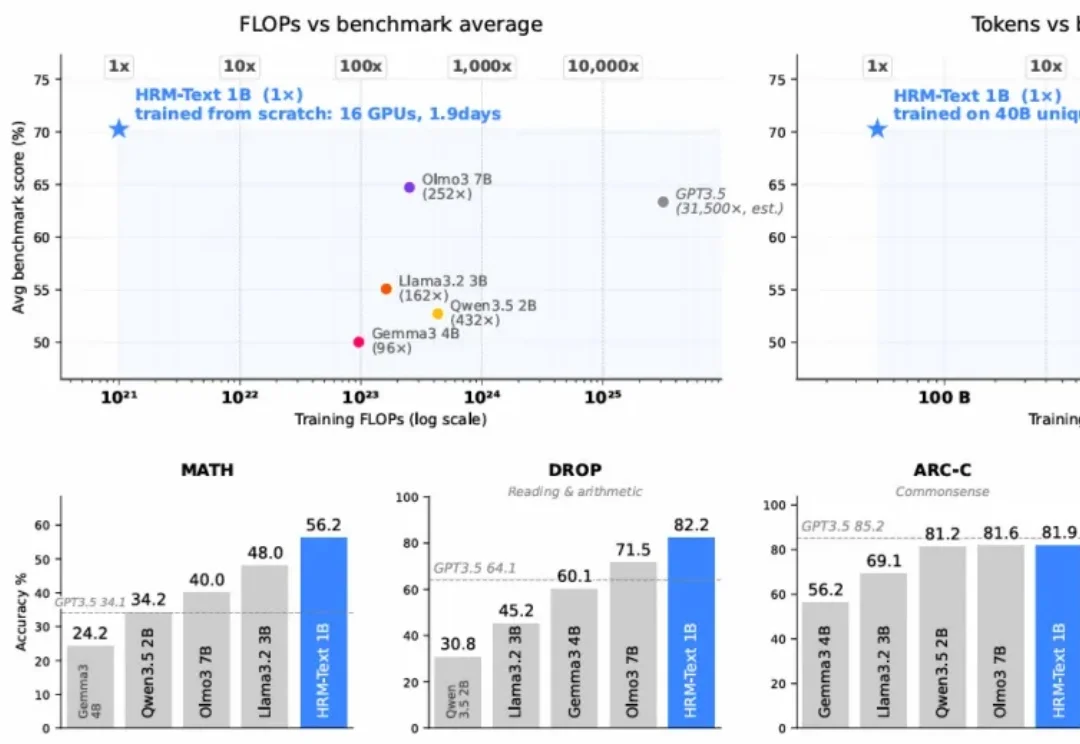
一个约 1B 参数的模型,在 MATH 上拿到 56.2,在 GSM8K 上拿到 84.5,在 ARC-Challenge 上拿到 81.9。训练成本约 1500 美元,16 块 H100 跑了不到两天。

英伟达世界动作模型 DreamZero 训练一次要烧 8 张 H100 整整 25 天,RLinf 从算子融合到 I/O 全链路系统级重构,把训练吞吐拉高近 4 倍——1 个月的活,1 周就能干完。

2026 年 5 月的硅谷,对于 AI 算力的“饥荒”和焦虑,正达到一个前所未有的高度。
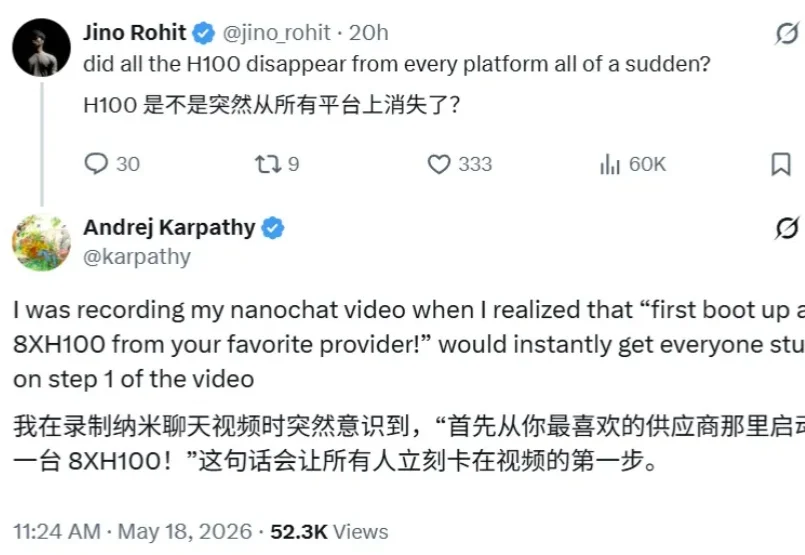
「H100 是不是突然从所有平台上消失了?」

在 AI 工程界,长文本推理一直是个“富贵病”。

“它将成为有史以来产量最高的 AI 芯片之一。”

Soul AI 团队(Soul AI Lab) 发布了新的开源模型 SoulX-LiveAct,技术报告中具体提到,该工作能够在 2 张 H100/H200 条件下,达到 20 FPS 的实时流式推理能力,且支持输入图像、音频和指令驱动,即可生成表情生动、情绪可控、拥有丰富全身动作的实时数字人视频。

元旦期间,DeepSeek 发布的 mHC 震撼了整个 AI 社区。

预测到次贷危机的「大空头」Michael Burry看到数万亿美元涌入AI基础设施,产生深深的怀疑。他预言:英伟达的优势并不持久,可能很快就会被对手战胜。而且,如今全球AI算力已经达到1500万H100 GPU当量,即将引爆严重能源危机!