全球首个太空AI诞生,H100在轨炼出!马斯克爆赞
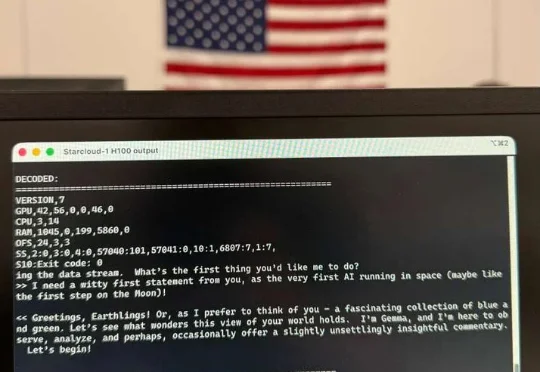
全球首个太空AI诞生,H100在轨炼出!马斯克爆赞见证历史!今天,首个由H100太空GPU训出LLM诞生了,它基于Karpathy nano-GPT训练。不仅如此,谷歌Gemma也在太空成功运行,向世界发出首句问候:地球人,你好。
来自主题: AI资讯
10719 点击 2025-12-11 16:27
 搜索
搜索
见证历史!今天,首个由H100太空GPU训出LLM诞生了,它基于Karpathy nano-GPT训练。不仅如此,谷歌Gemma也在太空成功运行,向世界发出首句问候:地球人,你好。

地面上的算力“内卷”,终于突破了大气层的束缚。前脚,装有英伟达H100的Starcloud-1卫星搭乘SpaceX的猎鹰9号火箭成功进入轨道,迈出构建“太空超算”的关键一步。谷歌紧随其后,火速披露了部署搭载TPU卫星集群的“太阳捕手”计划(Project Suncatcher)。

在AI数据中心里,数以万计的英伟达H100 GPU,正静静地躺在地上吃灰。这些单价3万美元、被黄仁勋称为「工业黄金」的芯片,本该全速运转,为GPT-5或Sora注入灵魂,但此刻——它们没有电。

当美国把H100送进轨道试图复制「太空数字霸权」时,中国创业团队的「天算计划」正以万卡级超算中心为剑,在真空与辐射的绝境中找到一条掌握人类数字命运的新路。

英伟达和谷歌,抢着上天了!

地球现在连显卡都供不起了,微软的GPU插不进机房。英伟达的H100直接飞向太空。
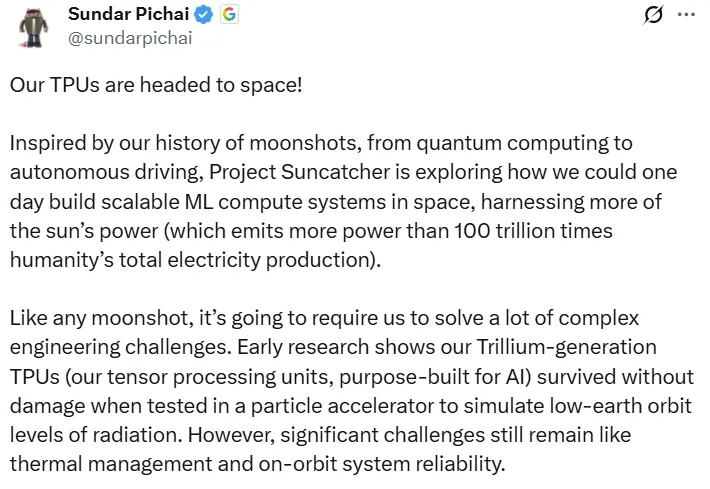
11 月 2 日,英伟达首次把 H100 GPU 送入了太空,参阅报道《英伟达发射了首个太空 AI 服务器,H100 已上天》。而刚刚谷歌宣布,他们也要让 TPU 上天。

11 月 2 日,英伟达首次把 H100 GPU 送入了太空。作为目前 AI 领域的主力训练芯片,H100 配备 80GB 内存,其性能是此前任何一台进入太空的计算机的上百倍。在轨道上,它将测试一系列人工智能处理应用,包括分析地球观测图像和运行谷歌的大语言模型(LLM)。
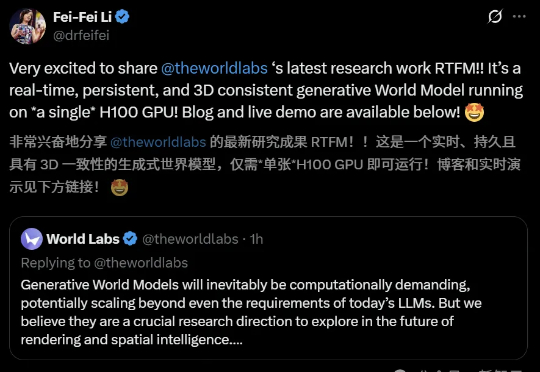
一张图,一个3D世界!今天,李飞飞团队重磅放出实时生成世界模型「RTFM」,通过端到端学习大规模视频数据,直接从输入2D图像生成同一场景下新视角的图像。值得一提的是,它仅需单块H100 GPU便能实时渲染出持久且3D一致的世界。

李飞飞的世界模型创业,最新成果来了!刚刚,教母亲自宣布对外推出全新模型RTFM(A Real-Time Frame Model),不仅具备实时运行、持久性和3D一致性,更关键的是——单张H100 GPU就能跑。