
马斯克狂烧14万亿,5000万H100算力五年上线!终极爆冲数十亿
马斯克狂烧14万亿,5000万H100算力五年上线!终极爆冲数十亿马斯克宣布了一个疯狂的计划,将在5年内实现5000万张H100的算力,这是什么概念?这将为人类带来怎样的影响?ASI能否在勇敢者的孤注一掷下现身?
来自主题: AI资讯
8851 点击 2025-08-27 12:45
 搜索
搜索
马斯克宣布了一个疯狂的计划,将在5年内实现5000万张H100的算力,这是什么概念?这将为人类带来怎样的影响?ASI能否在勇敢者的孤注一掷下现身?

今天 ,OpenAI 开源了俩模型:120B/20B 117B 的 gpt-oss-120b 对标 o4-min,按官方说法至少需要 80G 内存,推荐使用单卡 H100 GPU 而刚买的的游戏本,刚好满足gpt-oss-120b 的部署条件
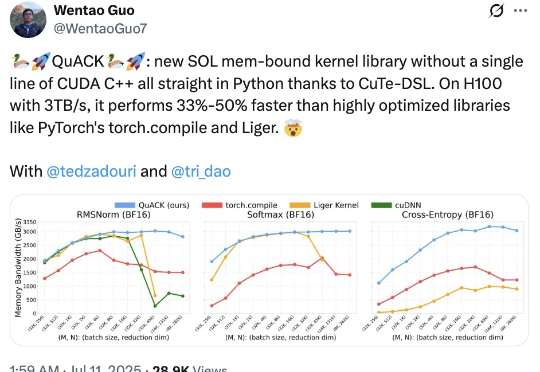
无需CUDA代码,给H100加速33%-50%! Flash Attention、Mamba作者之一Tri Dao的新作火了。

今年,AI大厂采购GPU的投入又双叒疯狂加码——马斯克xAI打算把自家的10万卡超算扩增10倍,Meta也计划投资100亿建设一个130万卡规模的数据中心……GPU的数量,已经成为了互联网企业AI实力的直接代表。

近日,来自SGLang、英伟达等机构的联合团队发了一篇万字技术报告:短短4个月,他们就让DeepSeek-R1在H100上的性能提升了26倍,吞吐量已非常接近DeepSeek官博数据!

超越DeepSeek-R1的英伟达开源新王Llama-Nemotron,是怎么训练出来的?刚刚放出的论文,把一切细节毫无保留地全部揭秘了!

就在刚刚,美国政府曝光了各界对「AI行动计划」的全部政策建议。OpenAI措辞激烈地表示,DeepSeek让我们看到,必须马上锁死中国AI,必须限制高端GPU芯片和模型权重流向中国!Anthropic同样呼吁:必须立马补上H20这一关键漏洞,并且严控H100的门槛。

高端Ai服务器定义,满足以下2个条件:条件1.卡间互联,条件2.显存HBM。以H100为例子,不同的设备比如H100或者H20 为啥差别很大,主要是因为配置不同,成本差别10~20w,所以有差别!
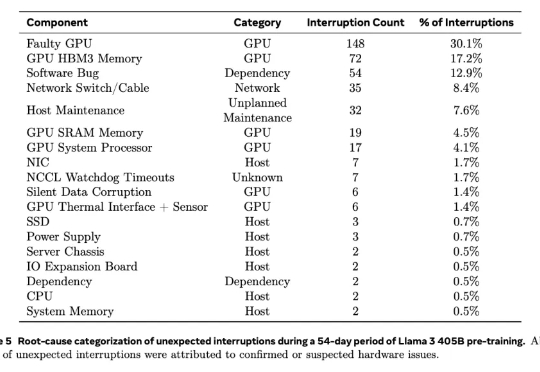
根据去年2024年7月28日Meta公司在训练大模型(Llama 3)时使用“16384 个 英伟达H100 GPU 集群”的经验,该显卡在高负载、大规模集群运行环境下容易出现以下故障点:

原生多模态Llama 4终于问世,开源王座一夜易主!首批共有两款模型Scout和Maverick,前者业界首款支持1000万上下文单H100可跑,后者更是一举击败了DeepSeek V3。目前,2万亿参数巨兽还在训练中。