# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着 AI 模型的参数量越来越大,对算力的需求也水涨船高。
比如最近,Llama-3.1 登上了最强开源大模型的宝座,但超大杯 405B 版本的内存就高达 900 多 GB,这对算力构成了更加苛刻的挑战。
如何降低算力的使用成本和使用门槛,已经成为许多公司寻求突破的关键。Felafax 就是其中的一家创业公司,致力于简化 AI 训练集群的搭建流程。

Nikhil Sonti 和 Nikhin Sonti 创立了 Felafax,他们的口号是在构建开源 AI 平台,为下一代 AI 硬件服务,将机器学习的训练成本降低 30%。
与英伟达相比,AMD 的 GPU,尤其是 MI300X 系列,提供了更高的性价比,按每美元计算,其性能表现更为出色。
最近,Felafax 的联合创始人 Nikhil Sonti 发布了一篇博客,详细分享了如何通过 8 张 AMD MI300X GPU 和 JAX 微调 LLaMA 3.1 405B 模型的方法,所有代码现已开源。
Github 链接:https://github.com/felafax/felafax
机器之心对博客内容进行了不改变原意的编译、整理,以下是博客内容:
JAX 是一个强大的机器学习库,结合了类似 NumPy 的 API、自动微分功能以及 Google 的 XLA 编译器。它在模型并行化方面提供了优秀的 API,因此非常适合像 LLaMA 3.1 405B 这样的超大模型训练。
在使用 AMD 硬件时,JAX 有几个明显的优势:
因此,JAX 成为了我们在非英伟达硬件上的最佳选择。
docker pull rocm/jax:latest
# Pull the Docker Image:
docker pull rocm/jax:latest
# Start the Docker Container:
docker run -it -w /workspace --device=/dev/kfd --device=/dev/dri --group-add video \
--cap-add=SYS_PTRACE --security-opt seccomp=unconfined --shm-size 16G rocm/jax:latest
# Verify the Installation:
python3 -c 'import jax; print(jax.devices())'
python3 -c 'import jax; print (jax.devices ())'
训练使用了一个配备了 8 张 AMD MI300x GPU 的 AMD 节点。每张 MI300x 拥有 192GB 的 HBM3 内存,性能表现与最新的英伟达 H100 GPU 相比非常出色。

与英伟达 H100 的比较,来源:TensorWave
使用 JAX,可以成功地在 AMD GPU 上训练 LLaMA 405B 模型。我们使用 LoRA 微调,将所有模型权重和 LoRA 参数都设为 bfloat16,LoRA rank 设为 8,LoRA alpha 设为 16:
由于硬件和显存的限制,我们无法运行 JIT 编译版本的 405B 模型,整个训练过程是在 JAX 的急切模式下执行的,因此还有很大的进步空间。
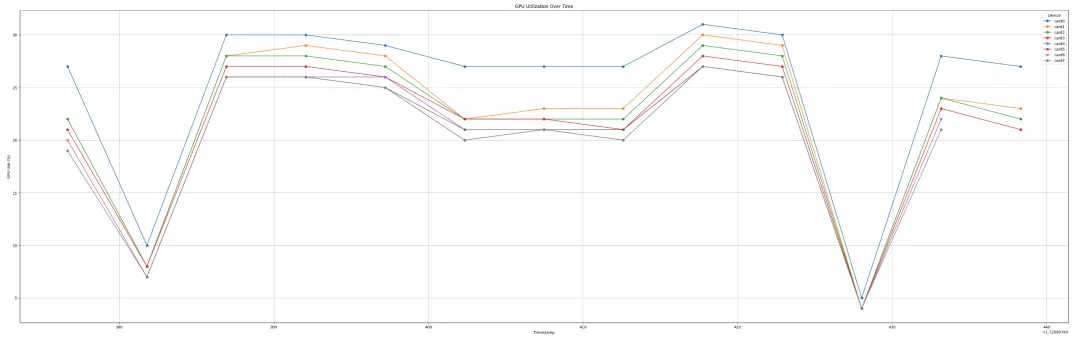
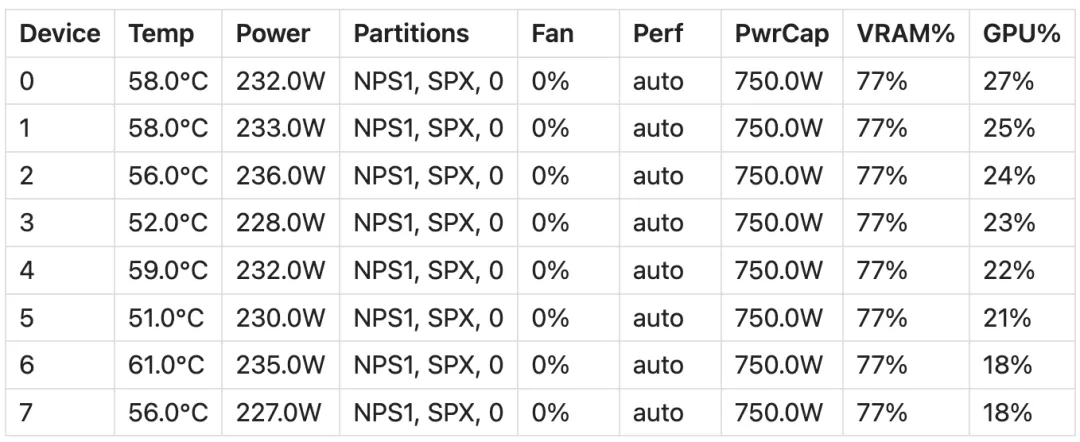
下图中显示了在一次微调训练步骤中,8 张 GPU 的显存利用率和 rocm-smi 输出:
GPU 利用率:
显存利用率:

rocm-smi 输出:
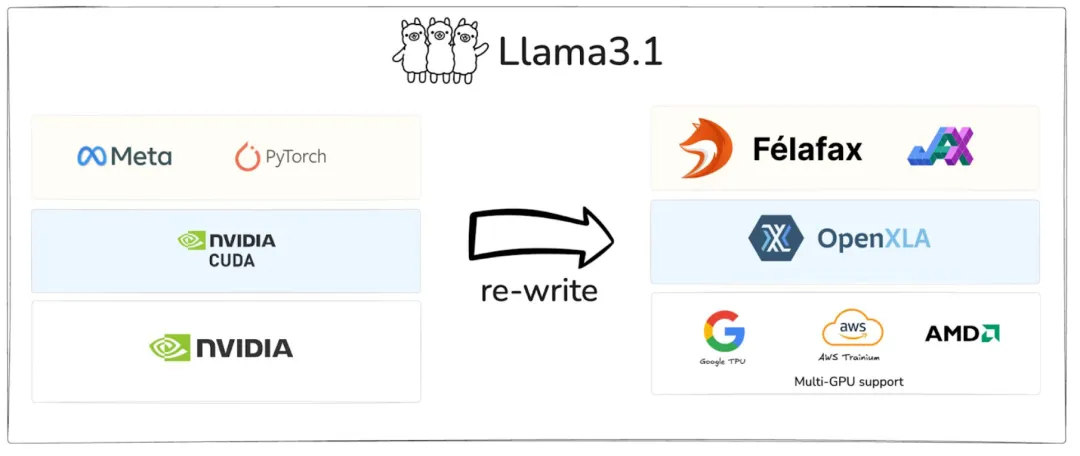
此前,Nikhil Sonti 分享过如何将 LLaMA 3.1 从 PyTorch 移植到 JAX。他指出,目前 90% 的大型语言模型(LLM)都运行在 NVIDIA GPU 上,但实际上还有一些同样强大且性价比更高的替代方案。例如,在 Google TPU 上训练和部署 Llama 3.1 的成本比 NVIDIA GPU 低约 30%。
然而,支持非 NVIDIA 硬件的开发工具较为匮乏。Sonti 最初尝试使用 PyTorch XLA 在 TPU 上训练 Llama 3.1,但过程并不顺利。XLA 与 PyTorch 的集成不够完善,缺少一些关键的库(如 bitsandbytes 无法正常运行),同时还遇到了一些难以解决的 HuggingFace 错误。
为此,他决定调整策略,将 Llama 3.1 从 PyTorch 移植到 JAX,成功解决了这些问题。Sonti 还录制了详细的教程视频,并开源了所有代码:
处理像 LLaMA 405B 这样的超大模型,需要在多个设备之间高效地进行参数分片。以下是如何通过 JAX 实现这一点的。
为了将巨大的 LLaMA 405B 模型高效地分布到 8 张 AMD GPU 上,需要使用 JAX 的设备网格(device mesh)功能。
部署代码:https://github.com/felafax/felafax/blob/e2a96a0e207e1dc70effde099fe33a9e42a7d5cb/llama3_jax/trainer_engine/jax_utils.py#L69
JAX 的设备网格可以帮助我们把可用的设备组织成一个网格,让我们可以指定如何把模型的参数和计算分配到不同的 GPU 上。
在本文的设置中,需要创建一个形状为(1, 8, 1)的网格,并将轴分别命名为数据并行(dp)、全分片数据并行(fsdp)和模型并行(mp)。然后,为模型的每个张量定义特定的分片规则,指定这些维度如何沿着这些网格轴进行分片。
DEVICES = jax.devices ()
DEVICE_COUNT = len (DEVICES)
DEVICE_MESH = mesh_utils.create_device_mesh ((1, 8, 1))
MESH = Mesh (devices=DEVICE_MESH, axis_names=("dp", "fsdp", "mp"))
可以使用以下代码来可视化分片结果,从而方便地验证分片规则是否按预期应用。
jax.debug.visualize_array_sharding
模型不同组件的分片规则如下所示:
参数要在 8 个 GPU 之间分配。例如,LM head(lm_head/kernel)张量有两个轴,按照 PS ("fsdp", "mp") 进行分片。在本例中是 8 和 1,因此可以看到该张量在第一个轴上沿着 8 个 GPU 被拆分。
没有任何分片规范的参数会在所有设备上进行复制。例如,层归一化(attention_norm/kernel 和 ffn_norm/kernel)没有设置分片规范,是 PS (None)。
在加载模型时,使用以下分片函数逐步对模型权重进行分片:
def make_shard_and_gather_fns (partition_specs):
def make_shard_fn (partition_spec):
out_sharding = NamedSharding (mesh, partition_spec)
def shard_fn (tensor):
return jax.device_put (tensor, out_sharding).block_until_ready ()
return shard_fn
shard_fns = jax.tree_util.tree_map (make_shard_fn, partition_specs)
return shard_fns
# Create shard functions based on partitioning rules
shard_fns = make_shard_and_gather_fns (partitioning_rules)
这使得我们能够将每个参数放置在指定的设备上,并按照设定的分片进行处理。
最初,训练 Batch 是正常创建的,但在输入模型之前,需要按照下面的代码在 GPU 上进行分片:
train_batch = jax.device_put ( train_batch,
NamedSharding (self.mesh, PS ("dp", "fsdp")))
在这里,我们指定训练 Batch 应该在 "dp" 和 "fsdp" 轴上进行分片,在本例中分别对应于被分成 1 和 8 份,如果把结果可视化出来,如下所示:
分片前:
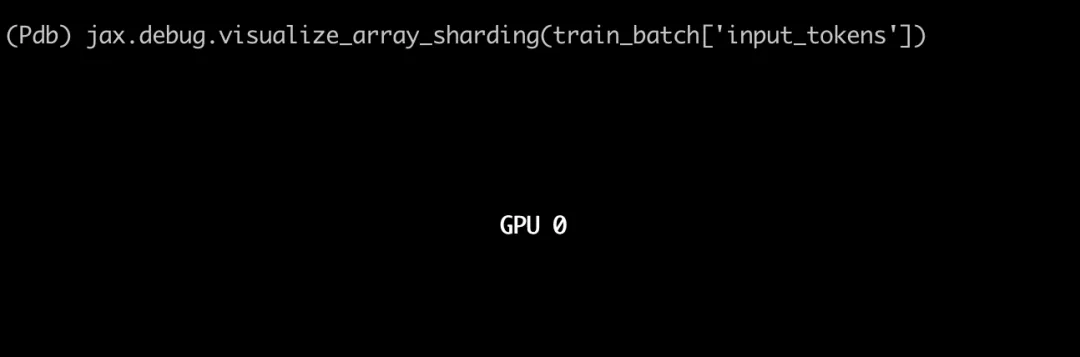
在调用 jax.device_put 之后:

LoRA 通过将权重更新分解为低秩矩阵,减少了可训练参数的数量,这对于微调大型模型特别有效。以下是在 AMD GPU 上微调 Llama 3.1-405 的 LoRA 的要点:
在此设定一个自定义的 LoRADense 层,该层集成了 LoRA 参数:
class LoRADense (nn.Module):
features: int
lora_rank: int = 8
lora_alpha: float = 16.0
@nn.compact
def __call__(self, inputs: Any) -> Any:
# Original kernel parameter (frozen)
kernel = self.param ('kernel', ...)
y = lax.dot_general (inputs, jax.lax.stop_gradient (kernel), ...)
# LoRA parameters (trainable)
lora_a = self.variable ('lora_params', 'lora_a', ..., ...)
lora_b = self.variable ('lora_params', 'lora_b', ..., ...)
# Compute LoRA output
lora_output = lax.dot_general (inputs, lora_a.value, ...)
lora_output = lax.dot_general (lora_output, lora_b.value, ...)
# Combine original output with LoRA modifications
y += (self.lora_alpha/self.lora_rank) * lora_output
return y.astype (self.dtype)
为了高效地在设备之间分配 LoRA 参数,我们也通过 JAX 设定了分片规则,这确保了 LoRA 参数与主模型参数的分片一致,优化了内存使用和计算效率。
LoRA A matrices (lora_a)
LoRA A 矩阵(lora_a)


这种分片策略优化了参数的分配,减少了通信开销,并在训练过程中增强了并行性。它确保每个设备仅持有一部分 LoRA 参数,使得大模型如 LLaMA 405B 的高效扩展成为可能。
为了优化训练,在微调 LLaMA 405B 模型,只计算 LoRA 参数的梯度,保持主模型参数不变。这个方法减少了内存使用,并加速了训练,因为只更新较少的参数。可以移步 GitHub 仓库,查看实现细节。
在训练过程中,每一步都涉及将一批输入数据通过模型进行处理。由于只有 LoRA 参数是可训练的,因此模型的预测和计算的损失仅依赖于这些参数,然后对 LoRA 参数进行反向传播。只更新这些参数简化了训练过程,使得在多个 GPU 上高效微调像 LLaMA 405B 这样的大型模型成为可能。
文章来自于微信公众号“机器之心”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
