# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
红杉资本的报告曾指出,AI产业的年产值超过6000亿美元,才够支付数据中心、加速GPU卡等AI基础设施费用。而现在一种普遍说法认为,基础模型训练的资本支出是“历史上贬值最快的资产”,但关于GPU基础设施支出的判定仍未出炉,GPU土豪战争仍在进行。尤其是,以OpenAI为代表的大模型公司在训练+推理上的支出超过了收入,最近他们在有史以来最大的风险投资轮中筹集了66亿美元,同时预计2026年的亏损将达到140亿美元。
近期,NVIDIA的新一代Blackwell系列芯片交付给了OpenAI,他们还表示接下来一年的产品已经售罄,NVIDIA CEO黄仁勋指出这可能是行业历史上最成功的产品。与此同时,AMD CEO苏姿丰推出了MI325X,而AI推理芯片公司Cerebras提交了IPO申请。
随着数十亿美元投入到AI基础设施层,这会促进AI上层的繁荣还是泡沫?现在,是时候深入探讨GPU市场的时候了。
本文作者Eugene Cheah深入研究了H100市场,可能为即将到来的Blackwell芯片的未来走向提供一些参考。他指出,由于预留计算资源的转售、开放模型的微调以及基础模型公司的减少,市场上的H100算力已经供过于求,尤其是H100从去年以8美元/小时到现在多家算力转售商以低于2美元/小时的价格出租。经过深度分析后,他建议用户在需要时租用而不是购买算力。
(作者 Eugene Cheah是AI推理服务供应商Featherless.AI的联合创始人,也是RWKV开源基础模型项目的联合负责人。
原文:https://www.latent.space/p/gpu-bubble)
2022年11月30日,基于A100 GPU系列训练的GPT3.5与 ChatGPT仿佛一夜之间吸引了全世界对 AI 的想象,并开启了AI竞赛。2023年3月21日,随着惊人的AI势头,H100很快就来了。
如果OpenAI可以用“旧”的A100构建智能,那么使用新推出的性能高3倍、价格多2倍的H100,你也能够构建一个更大、更好的模型,甚至可能超越OpenAI率先到达AGI——如果你的财力比OpenAI还雄厚。
第一个成功实现这一目标的AI公司,将获得新AI经济中的一大块份额——每一个分析师的粗略计算都表明,取代通用的人类智能将意味着数万亿美元的市场。如果能够成功,你将比地球上一半的国家或历史上任何王国都要富有。怀着这样的渴望,有100亿到1000亿美元的资金投入到AI公司和创始人身上,以推动新一轮科技革命,这导致H100的需求突然激增。
市场价飙升,H100的初始租赁价格约为4.70美元/小时,但实际价格超过了8美元/小时。所有急切的创始人纷纷涌入,急于训练他们的模型,以说服投资者进行下一轮亿级美元的融资。
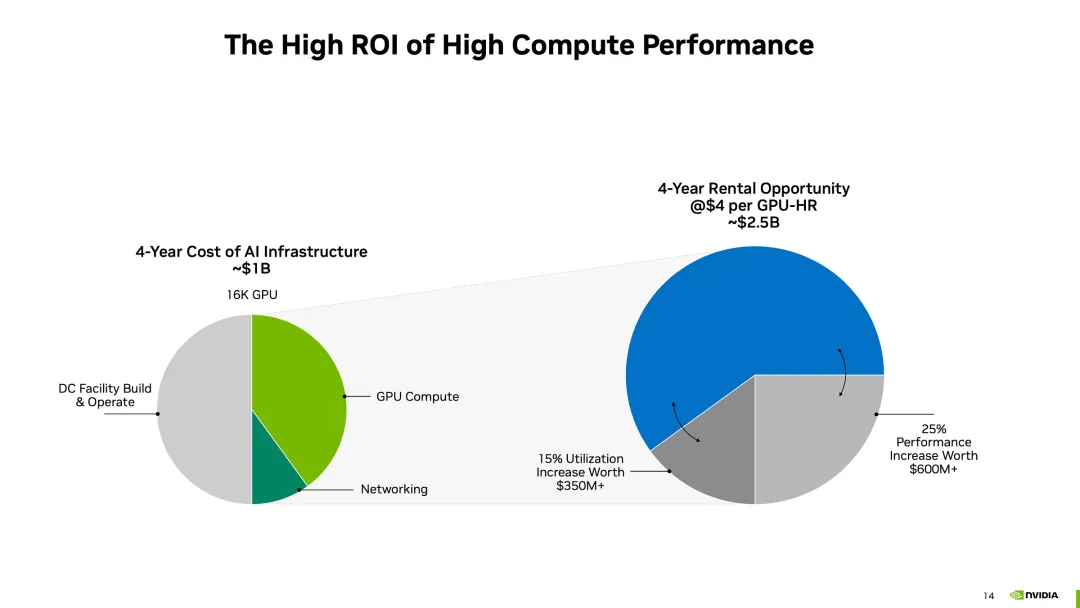
在2023年的投资者会议上,英伟达向他们的投资者和数据中心客户推介了以4美元/小时的价格出租H100的“市场机会”。
对于GPU农场来说,这感觉像是不劳而获的钱——如果你能让这些创始人以4.70美元/小时或更高的价格租用你的H100 SXM GPU,甚至让他们提前支付,投资回报期将少于1.5年。从那以后,每个GPU每年将带来超过10万美元的现金流。
由于GPU需求似乎没有尽头,他们的投资者同意了,甚至进行了更大规模的投资……

《郁金香狂热》——描绘了有记录以来历史上第一次投机泡沫,郁金香价格在1634年持续攀升,并于1637年
与数字商品不同,实物商品会受到延迟发货的影响,尤其是在多次发货延迟的情况下。2023年的大部分时间里,H100的价格感觉会永远高于4.70美元/小时以上(除非你愿意支付一大笔预付款)。2024年初,H100的价格在多个供应商那里降至大约2.85美元/小时。
然而,随着更多供应商的加入……我开始收到这样的邮件:
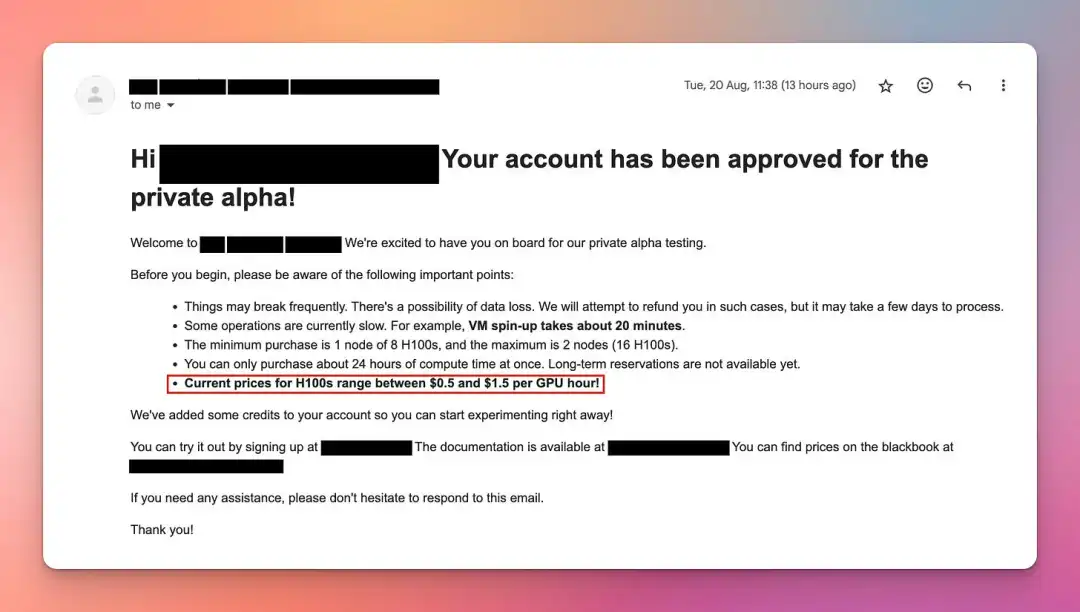
虽然我未能以4美元/小时的价格获得H100节点(8个H100),但我多次确认,你可以以8到16美元/小时的价格获得。
2024年8月,如果你愿意竞拍一小段时间的H100使用时间(几天到几周),你可以找到1-2美元/小时的H100。
尤其对于小型集群而言,我们正面临着每年至少40%的价格下跌。NVIDIA预测的4美元/小时的GPU价格在4年内保持不变,但不到1.5年就烟消云散了。
这非常可怕,因为这意味着有人可能会被套牢——尤其是如果他们刚刚购买了新的GPU。那么,到底发生了什么?
这里将重点关注经济成本和租赁的ROI,对比不同的市场价格,不包括机会成本或业务价值。
在数据中心,平均一张H100 SXM GPU的设置、维护和运营成本(即大部分资本支出)为50000美元或更多,不包括电费和冷却的运营成本。本文后面将提供更详细的计算方法。
但对今天的单元经济和投资意味着什么?特别是假设GPU的使用寿命为5年的情况下。
通常,H100的租赁业务模式有两种,我们将会覆盖这两种模式。
1.短期按需租赁(按小时、周或月)
2.长期租赁(3-5年)
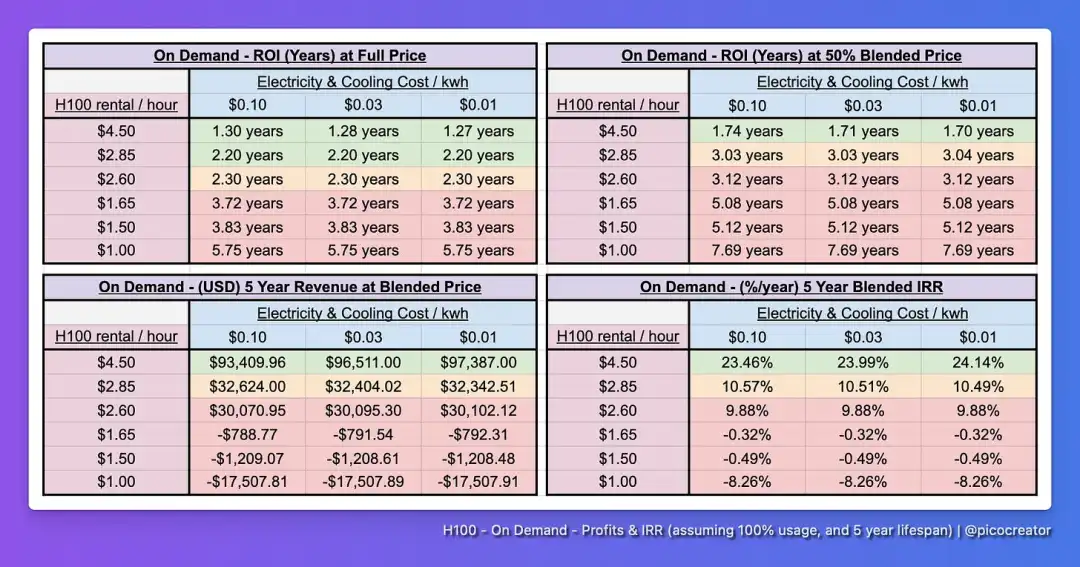
新的H100 ROI(2024年8月)
总结来说,对于按需工作负载:
对于上述ROI和收入预测,我们引入了“混合价格(blended price)”,假设租赁价格在5年内逐步下降50%。
鉴于我们目前看到的每年价格下降>=40%,这可以被视为一个保守/乐观的估计,但这是一种通过考虑一定比例的价格下降的同时来预测ROI的一种方法。
在4.50美元/小时的情况下,即使考虑混合价格,我们也能看到NVIDIA最初对数据中心提供商的承诺,即在2年后几乎可以“印钞”,内部收益率(IRR)超过20%。
然而,在2.85美元/小时的情况下,IRR刚刚超过10%。
这意味着,如果你今天购买新的H100服务器,并且市场价低于2.85美元/小时,你的投资回报率几乎只能勉强与市场基本回报水平持平,并且假设使用率是100%(这是一个不合理的假设)。任何低于这个价格的情况,作为投资者,投资H100基础设施公司不如投资股市。
如果价格降至1.65美元/小时以下,作为基础设施提供商,在5年内使用H100注定会亏损,特别是如果你今年刚刚购买了节点和集群。
许多基础设施提供商,尤其是那些较老的公司,并不是对此一无所知——因为他们曾经亲身经历过GPU租赁价格在加密货币时代大幅上涨后的急剧跳水,他们已经经历过这种周期。
因此,在这一周期中,去年他们大力推动3-5年的前期承诺和/或支付,价格在4美元/小时以上(通常预付50%到100%)。今天,他们推动的价格范围在2.85美元/小时以上,以锁定他们的利润。
这种情况在2023年AI高峰期尤为明显,尤其是在图像生成领域,许多基础模型公司被迫签订高价的3-5年合同,只是为了在新集群客户中排在前面,成为第一个推出目标模型的公司,以促进完成下一轮融资。
这可能不是最经济的举措,但可以让他们比竞争对手更快地行动。
然而,这导致了一些有趣的市场动态——如果你在未来3年内以3美元或4美元/小时的价格签订了合同,那么你将被合同绑定。当模型创建者完成模型训练后,他们不再需要这个集群后会怎么做?——他们转售并开始收回部分成本。
从硬件到AI推理/微调,可以大致分为以下几个方面:
1.硬件供应商与Nvidia合作(一次性购买成本)
2.数据中心基础设施提供商及合作伙伴(出售长期租赁,包括设施空间和/或H100节点)
3.风险投资基金、大型公司和初创公司:计划构建基础模型(或已经完成模型构建)
4.算力转售商:如Runpod、SFCompute、Together.ai、Vast.ai、GPUlist.ai
5.托管AI推理/微调提供商:使用上述资源的组合
虽然堆栈中的任何一层都可能实现垂直整合(例如跳过基础设施提供商),但关键驱动因素是“未使用算力资源的转售商”和“足够好”的开放权重模型(如Llama 3)的兴起,这些因素都是当前H100经济压力的主要影响因素。

开放权重模型的兴起,其性能与闭源模型相当,正在导致市场发生根本性的变化。
对AI推理和微调的需求增加:由于许多“开放”模型缺乏适当的“开源”许可证,但仍然被免费分发和广泛使用,甚至用于商业用途。在这里,我们将统称它们为“开放权重”或“开放”模型。
总体而言,随着各种大小的开放权重模型的不断构建,对这些模型的推理和微调的需求也在增长。这主要由两个重大事件推动:
1. GPT-4级别的开放模型的出现(例如,4050亿参数的LLaMA3,DeepSeek-v2)
2. 小型(约80亿参数)和中型(约700亿参数)微调模型的成熟和采用
如今,对于大多数企业可能需要的用例,已经有现成的开放权重模型。这些模型在某些基准测试中可能略逊于专有模型,但提供了以下优势:
所有这些因素都导致了当前开放模型的持续增长和采用,以及对推理和微调需求的增长。
但这确实带来了另一个问题……
基础模型创建市场萎缩(小型和中型):我们用“模型创建者”来统称从零开始创建模型的组织。对于微调者,我们称他们为“模型微调者”。
许多企业,以及多个小型和中型基础模型创建初创公司——尤其是那些以“更小、更专业领域模型”为卖点的公司——都是没有长期计划或目标从零开始训练大型基础模型(>= 700亿参数)的群体。
对于这两个群体,他们都意识到,微调现有的开放权重模型比“自行训练”更经济和高效。
这最终导致了对H100需求的三重打击!
1. 微调比从零开始训练便宜得多
2. 减少对基础模型的投资(小型和中型)
3. 预留节点的过剩算力资源正在上线
1. 大型模型创建者离开公共云平台
另一个主要因素是,所有主要的模型创建者,如Facebook、X.AI,以及OpenAI(如果你认为它们是微软的一部分),都在从现有的公共云提供商转向,通过构建自己的数十亿美元规模的集群,从而减少了对现有集群的依赖。
这一转变主要出于以下几个原因:
随着需求逐渐分阶段减少,这些集群正在进入公共云市场。
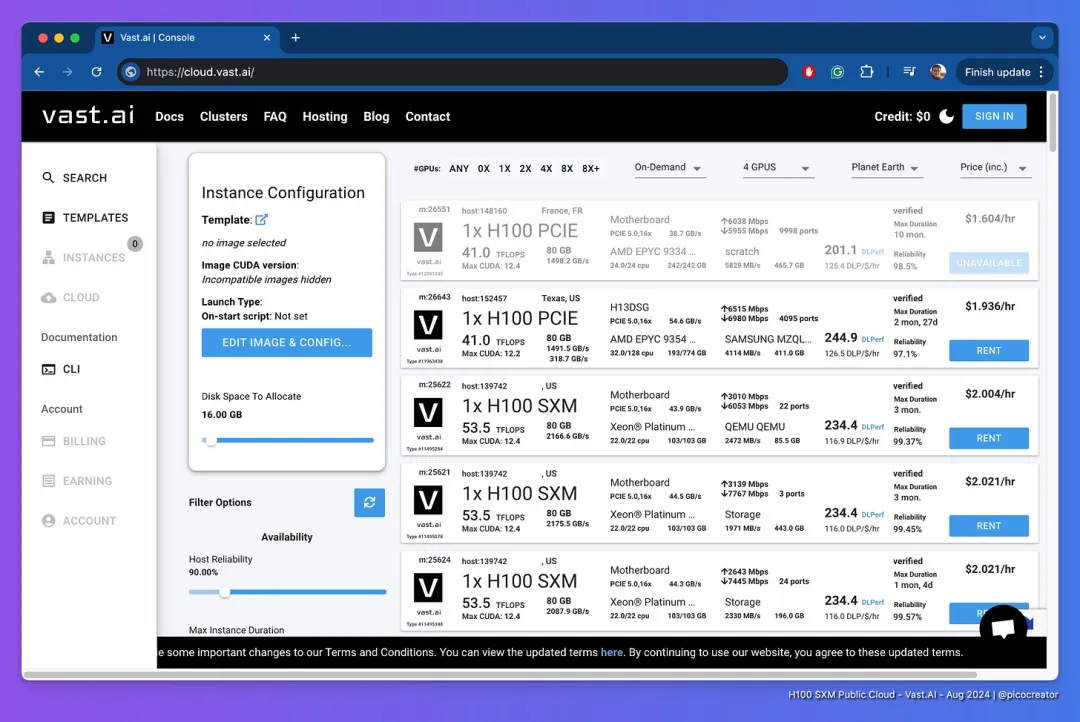
Vast.ai 基本上实行的是自由市场系统,全球的供应商被迫相互竞争。
2. 未使用/延迟供应的算力上线
回忆一下2023年的H100大批量发货延迟,或6个月或更长时间?这些延迟的算力供应现在正在上线,同时还有H200、B200等芯片。
这还伴随着各种未使用的算力资源上线(来自现有的初创公司、企业或风险投资公司,如前所述)。
这些资源的大部分是通过算力转售商上线的,例如:together.ai、sfcompute、runpod、vast.ai等。
在大多数情况下,集群所有者拥有的是一个小型或中型集群(通常为8-64个节点),这些集群的利用率较低。而购买这些集群的资金已经“花掉”了。
为了尽可能收回成本,他们更愿意以低于市场价的方式保证资源的分配,而不是与主要提供商竞争。
这通常通过固定费率、拍卖系统或自由市场列表等方式实现。后两种方式通常会推动市场价格下降。
3. 更便宜的 GPU 替代品(特别是用于推理)
另一个主要因素是,一旦你离开训练/微调领域,特别是如果你运行的是较小的模型,推理领域充满了替代方案。
你不需要为H100的Infiniband和/或Nvidia的高端功能支付溢价。
a) Nvidia市场细分
H100的高端训练性能已经反映在硬件价格中。例如,Nvidia自己推荐L40S,这是一个在推理方面更具价格竞争力的替代方案。

H100 Infiniband集群(2024年8月)
L40S的性能是H100的1/3,价格是H100的1/5,但不适合多节点训练。这在一定程度上削弱了H100在这个细分市场的竞争力。

b) AMD和Intel的替代提供商
AMD和Intel的MX300和Gaudi 3虽然进入市场较晚,但已经经过测试和验证。我们使用过这些系统,它们通常具有以下特点:
缺点?它们在训练时存在一些驱动问题,且在大型多节点集群训练中尚未得到验证。
然而,正如我们前面所讨论的,这在当前市场中并不重要。除了少数不到50个团队外,H100市场已经转向推理和单节点或小集群微调。
这些GPU已经证明在这些用例中表现良好,能满足大多数市场的需求。
这两个竞争对手是完全的即插即用替代方案,支持现成的推理代码(如VLLM)或大多数常见模型架构(主要是LLaMA3,其次是其他模型)的微调代码。
因此,如果你已经解决了兼容性问题,强烈建议你考虑这些方案。
c) 加密货币/Web3领域GPU使用量的下降
随着以太坊转向权益证明(Proof of Stake, PoS),ASIC在比特币挖矿中占据主导地位,用于加密货币挖矿的GPU使用量呈下降趋势,在许多情况下甚至无利可图。这导致了大量的GPU涌入公共云市场。
虽然这些GPU中的大多数由于硬件限制(如低PCIe带宽、网络等)无法用于模型训练,甚至不适合用于推理,但这些硬件已经涌入市场,并被重新用于AI推理工作负载。
在大多数情况下,如果你的模型参数少于100亿,你可以以非常低的价格通过这些GPU获得出色性能。
如果你进一步优化(通过各种技巧),甚至可以在这种硬件的小集群上运行4050亿参数的大型模型,成本低于一个H100节点。
H100的价格正在变得像大宗商品一样便宜。甚至有些时候是以低于成本的价格出租——如果是这样,接下来该怎么办?
中立观点:H100集群价格的分层
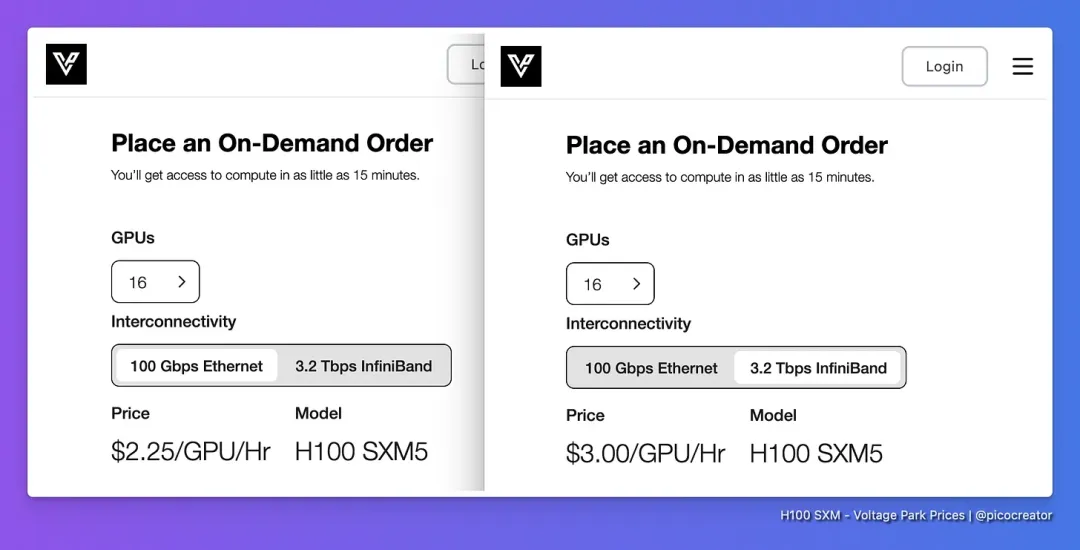
从宏观层面来看,预计大型集群仍然会收取溢价(>=2.90美元/小时),因为对于真正需要它们的客户来说,没有其他选择。
我们已经开始看到这种趋势,例如在Voltage Park,配备Infiniband的集群被收取更高的费用。而基于以太网的实例,对于推理任务来说已经足够好,其价格则定得较低。根据不同的使用场景和可用性调整价格。
尽管基础模型团队的数量总体上有所减少,但很难预测随着开放权重的增长和/或替代架构的出现,是否会迎来复苏。
同时,预计未来我们将看到按集群规模进一步分层。例如,一个拥有512个节点且配备Infiniband的大型集群,其每块GPU的收费可能会高于16个节点的集群。
消极观点:新的公共云H100集群进入市场较晚,可能无利可图——一些投资者可能会遭受损失。
如果你将价格定在2.25美元以下,根据你的运营成本(OPEX),你可能会面临潜在的无利可图的风险。如果你将价格定得过高,比如3美元或以上,你可能无法吸引足够的买家来最大化使用算力资源。如果你进入市场较晚,可能无法在早期以4美元/小时的价格收回成本。
总体而言,这些集群投资对于关键利益相关者和投资者来说将非常艰难。
虽然我怀疑这种情况会发生,但如果新集群在AI投资组合中占据了很大一部分,我们可能会看到由于投资者遭受损失而对融资生态系统产生连锁反应。
中立观点:中型到大型模型构建者,已经通过长期租赁榨取了算力价值
不同于消极看法,一种中立看法是,一些未使用的算力资源的模型构建者实际上已经支付了费用。资金市场已经将这些集群及其模型训练的成本计算在内,并“榨取了其价值”,用于他们当前和下一轮融资的筹码。
其中的大多数算力购买是在算力转售商流行之前进行的,成本已经计包含在内。如果有什么影响的话,他们是从多余的H100算力资源中获得的当前收入,而我们获得的是降价的算力资源,这对双方都是有利的。
如果情况确实如此,市场负面影响将是最小的,整体上对生态系统来说是一个净正收益。
正面观点:便宜的H100可能加速开放权重AI的采用浪潮
鉴于开放权重模型已经进入GPT-4级别的领域,H100价格的下跌将成为开放权重AI采用的倍增器。
对于业余爱好者、AI开发者和工程师来说,运行、微调和探索这些开放模型将变得更加实惠。特别是如果没有GPT-5++这样的重大飞跃,这意味着开放权重模型与闭源模型之间的差距将变得模糊。
这是非常必要的,因为目前市场是不可持续的。应用层缺乏为付费用户创造价值的能力(这会影响到平台、模型和基础设施层)。
在某种程度上,如果大家都在造铲子,而没有构建能够吸引付费用户的AI应用(并且没有产生收入和价值)。但当AI推理和微调变得比以往任何时候都便宜时,这可能会激发AI应用的浪潮——如果这一趋势还没有缓慢开始的话。
在新H100硬件上的支出很可能是亏损的。除非你有以下某种组合:折扣的H100、折扣的电力,或者有一个主权AI的需求(即你的GPU所在地对客户来说至关重要)。或者你有数十亿美元,需要一个超大型集群。
如果你在投资,建议考虑投资其他领域。或者投资股票市场指数以获得更好的回报率。
参考来源:
文章来自于“OneFlow”,作者“Eugene Cheah”。



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
