# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
7B大小的视频理解模型中的新SOTA,来了!
它就是由达摩院出品的Video LLaMA 3,以图像为中心构建的新一代多模态视频-语言模型。

在通用视频理解、时间推理和长视频理解三个核心维度进行评估的过程中,VideoLLaMA 3均取得优异成绩,超越多数基线模型。
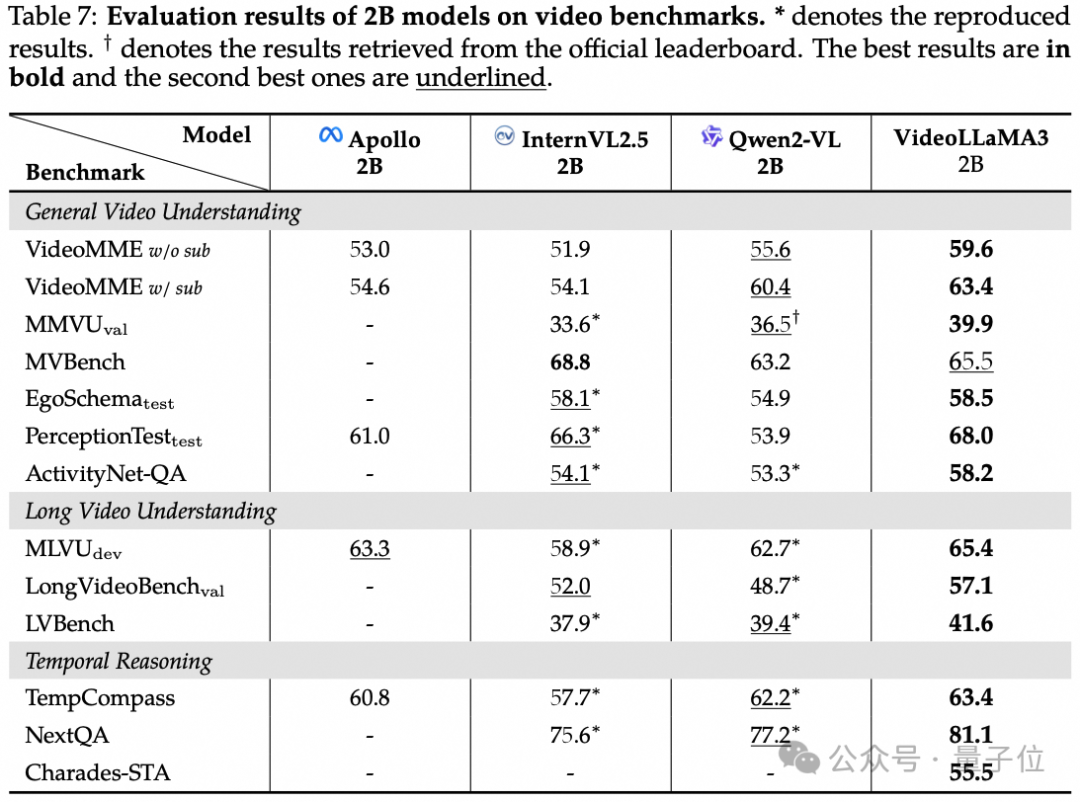
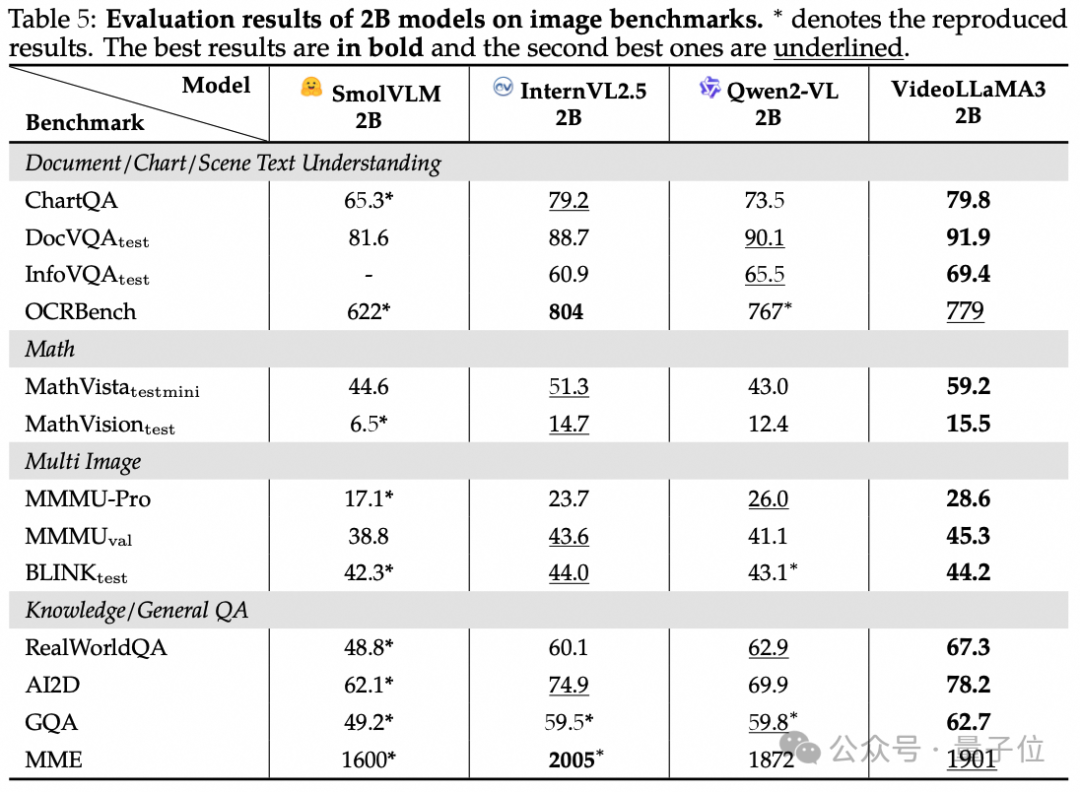
不仅如此,适用于端侧的2B大小的Video LLaMA 3,在图像理解上的表现也是较为出色。
在涵盖文档 / 图表 / 场景文本理解、数学推理、多图像理解和常识问答等多个维度的基准测试,如在InfoVQA中超越之前最好成绩,在MathVista数学推理任务上优势
明显。
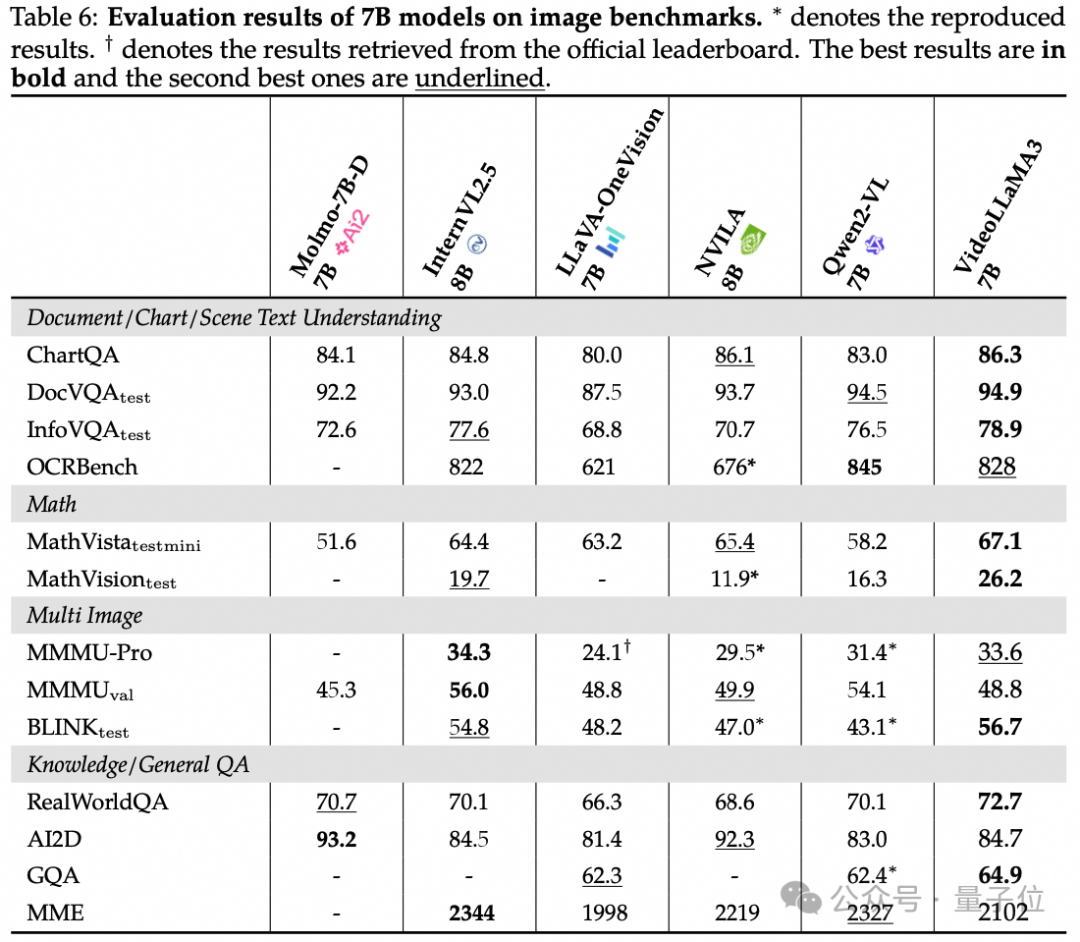
VideoLLaMA 3以图片为中心的设计理念贯穿于整个模型架构和训练过程。
通过高质量的图片文本数据为视频理解打下坚实基础,仅使用3M视频文本数据,实现全面超越同参数量开源模型的视频理解能力。
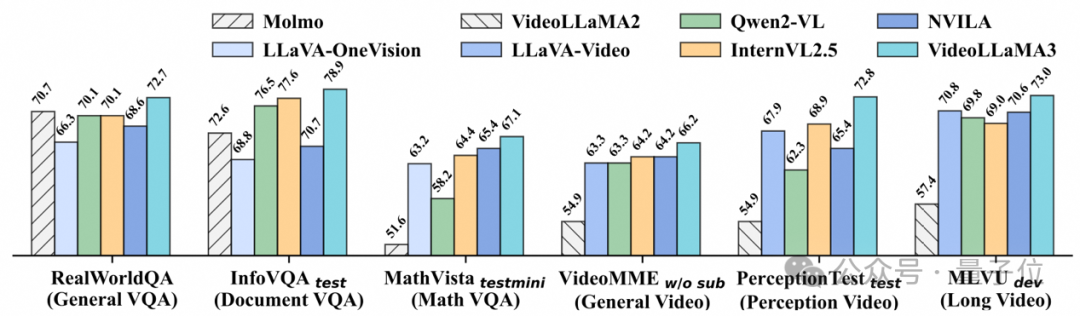
目前,VideoLLaMA 3已经在HuggingFace上提供了图像、视频理解的demo。
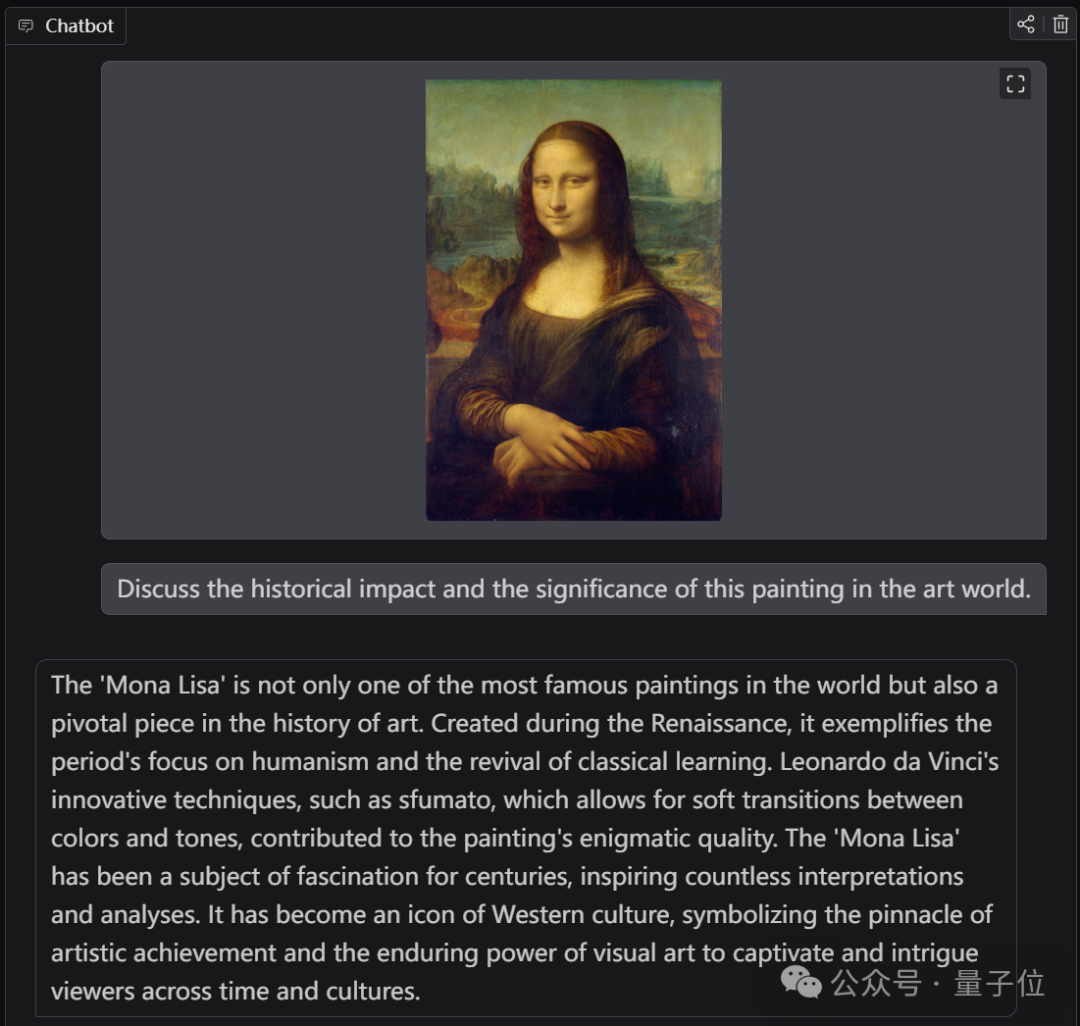
例如我们给一张《蒙娜丽莎的微笑》,并向VideoLLaMA 3提问:
Discuss the historical impact and the significance of this painting in the art world
讨论这幅画在艺术界的历史影响和意义。

VideoLLaMA 3的回答是这样的:
《蒙娜丽莎》不仅是世界上最著名的画作之一,也是艺术史上的重要作品。它创作于文艺复兴时期,体现了该时期对人文主义的关注和古典学习的复兴。列奥纳
多·达·芬奇的创新技术,如在色彩和色调之间进行柔和过渡的模糊手法,为这幅画的神秘品质做出了贡献。几个世纪以来,《蒙娜丽莎》一直是一个迷人的主
题,激发了无数的解释和分析。它已成为西方文化的标志,象征着艺术成就的顶峰,象征着视觉艺术对跨越时间和文化的观众的持久魅力。
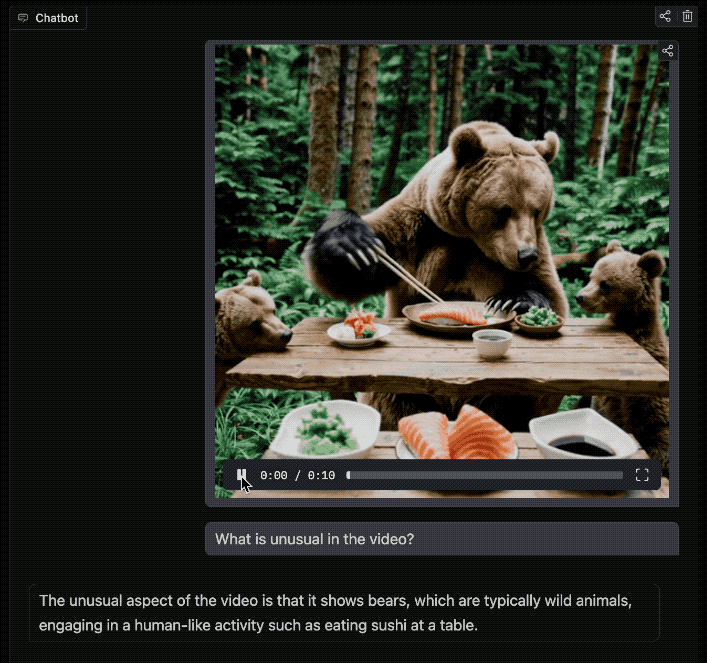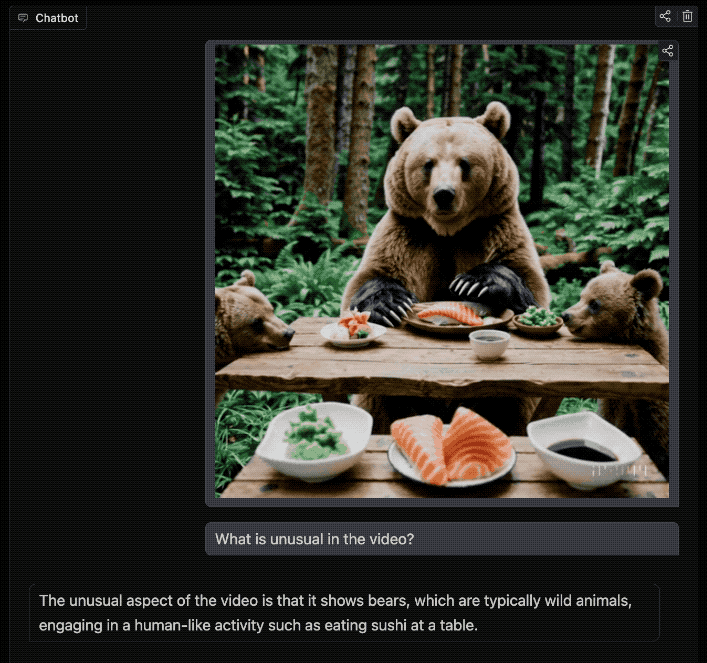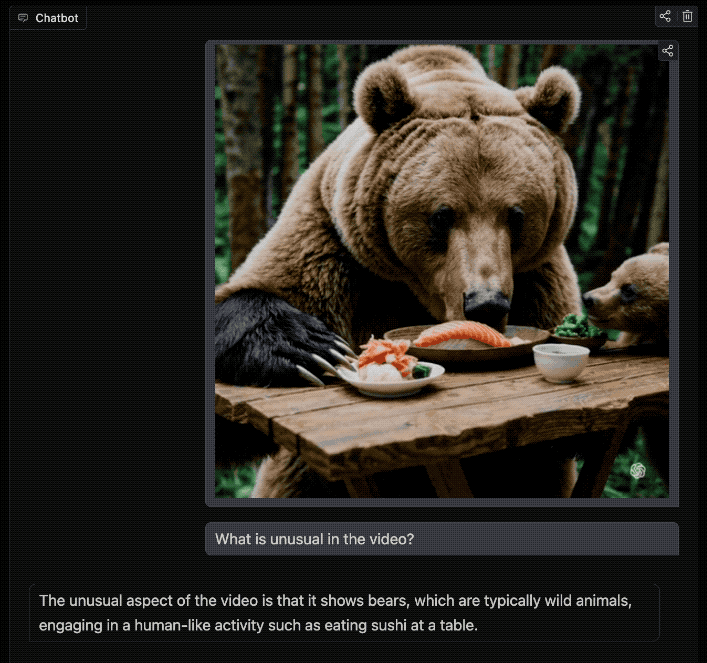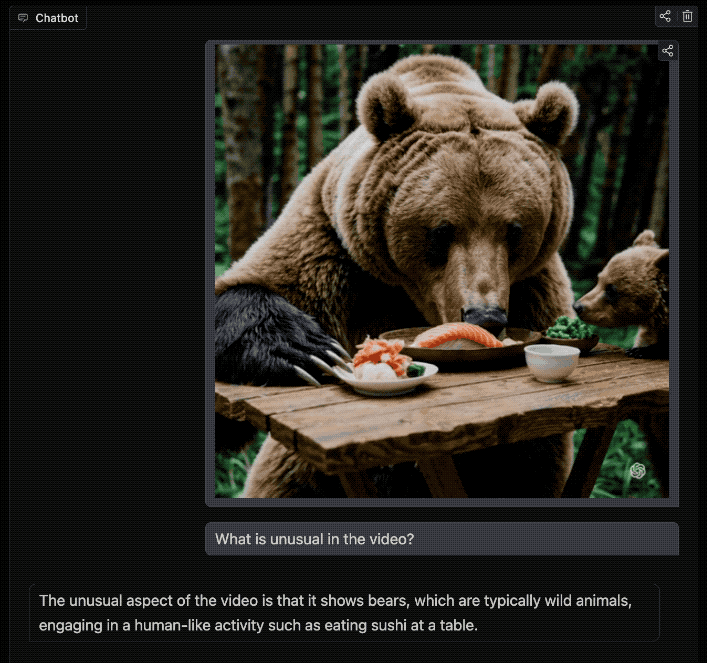
再来看下视频理解的demo,我们的问题是:
What is unusual in the video?
视频中有什么不寻常之处?
对此,VideoLLaMA 3表示:
这段视频的不同寻常之处在于,它展示了熊这种典型的野生动物,正在进行一种类似人类的活动,比如在桌子上吃寿司。
VideoLLaMA 3回答可谓是非常简约且精准了。
并且这个demo在HuggingFace上的操作也是极其简单,只需上传图片或视频,再提出你的问题即可。
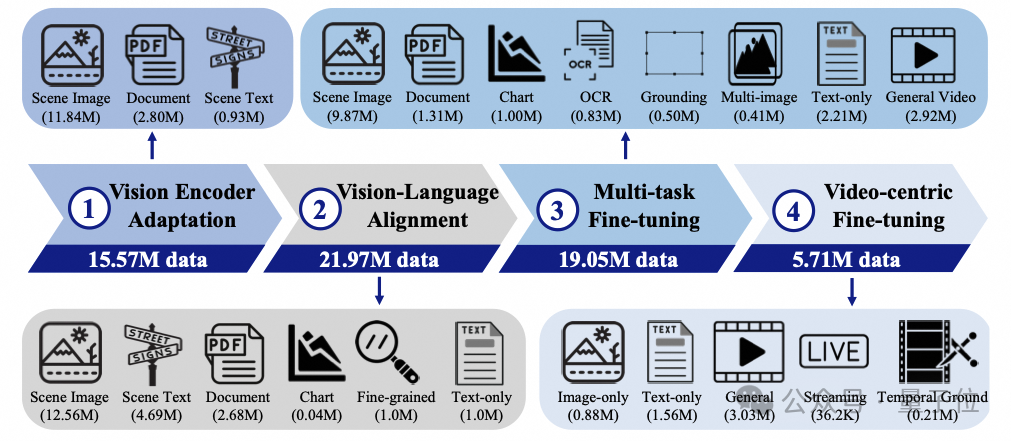
VideoLLaMA 3的关键,在于它是一种以图像为中心的训练范式。

这种范式主要包含四个关键内容:
2.视觉语言对齐:用丰富图像文本数据为多模态理解打基础,利用多种数据增强空间推理能力,同时保留模型语言能力。
3.多任务微调:用图像文本问答数据和视频字幕数据微调模型,提升其遵循自然语言指令和多模态理解能力,为视频理解做准备。
4.视频微调:增强模型视频理解和问答能力,训练数据包含多种视频及图像、文本数据。
从框架设计来看,主要包含两大内容。
首先是任意分辨率视觉标记化(AVT)。
这种方法突破了传统固定分辨率限制,采用2D - RoPE替换绝对位置嵌入,让视觉编码器能处理不同分辨率图像和视频,保留更多细节。
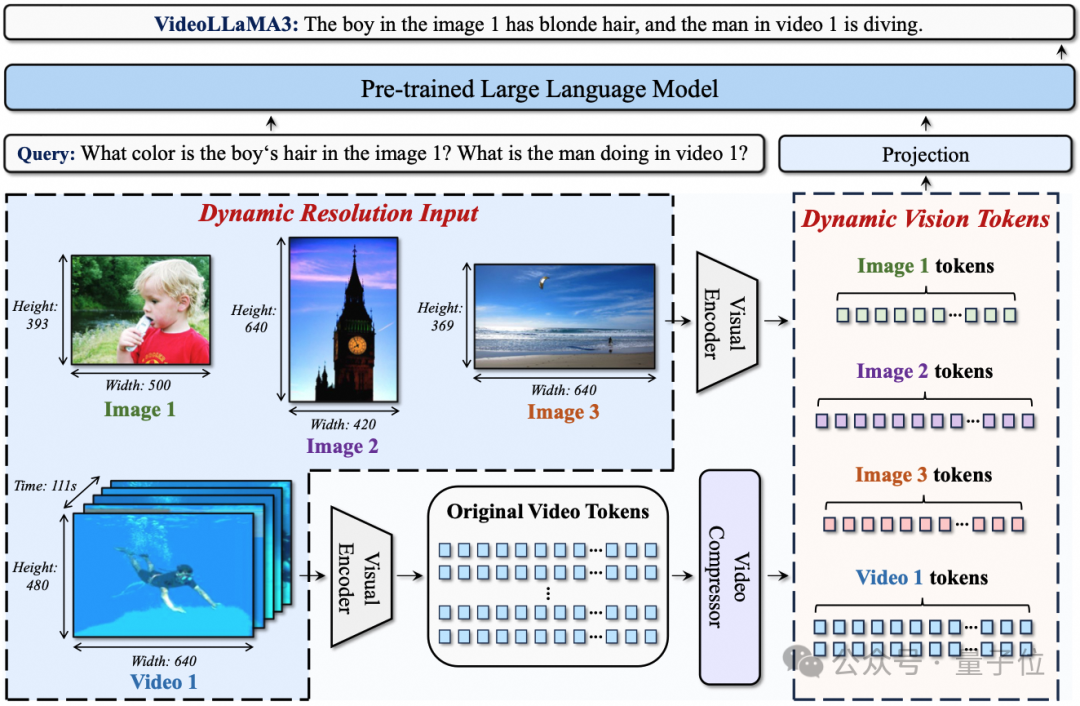
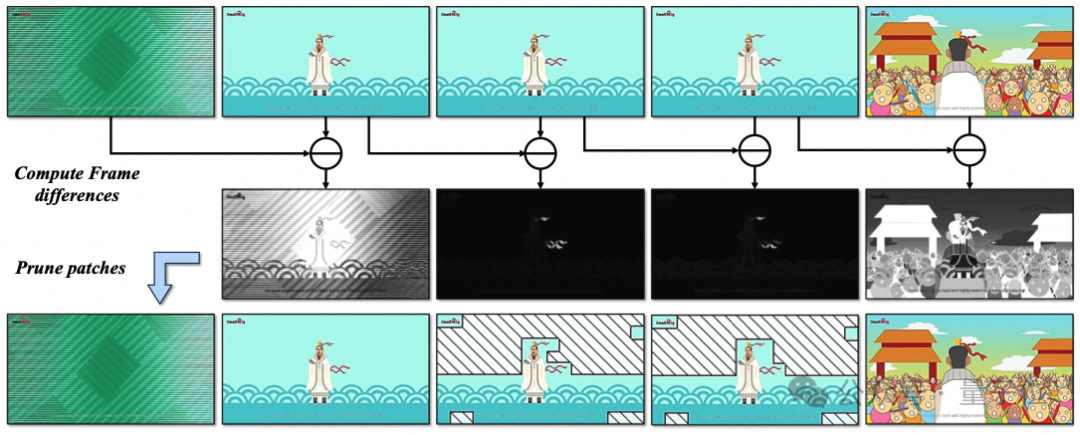
其次是差分帧剪枝器(DiffFP)。
针对视频数据冗余问题,通过比较相邻帧像素空间的1-范数距离,修剪冗余视频标记,提高视频处理效率,减少计算需求。
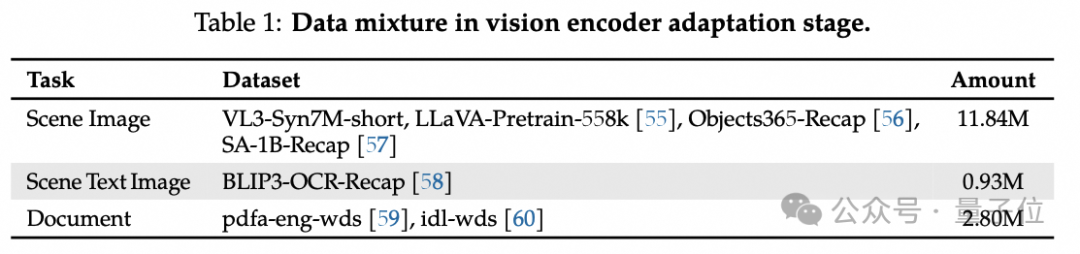
除了框架之外,高质量数据也对VideoLLaMA 3的性能起到了关键作用。
首先是高质量图像重新标注数据集VL3Syn7M的构建。
为给 VideoLLaMA 3 提供高质量训练数据,团队构建了包含700万图像-字幕对的VL3Syn7M数据集。
滤,确保数据集中图像长宽比处于典型范围,为后续准确的特征提取奠定基础。
干扰,保证模型学习到的图像内容和描述质量更高,进而提升模型生成优质描述的能力。
算文本 - 图像相似度,剔除相似度低的图像。这一操作确保剩余图像内容与描述紧密相关,使模型学习到的图文对更具可解释性和代表性。
Visual Feature Clustering(视觉特征聚类):运用CLIP视觉模型提取图像视觉特征,通过k-最近邻(KNN)算法聚类,从每个聚类中心选取固定数量图像。这样既
保证数据集多样性,又维持语义类别的平衡分布,让模型接触到各类视觉内容,增强其泛化能力。
Image Re - caption(图像重新标注):对过滤和聚类后的图像重新标注。简短字幕由InternVL2-8B生成,详细字幕则由InternVL2-26B完成。不同阶段训练使用不同
类型字幕,满足模型多样化学习需求。
其次是各训练阶段的数据混合。
在VideoLLaMA 3的不同训练阶段,数据混合策略为模型提供了丰富多样的学习场景。此外,团队使用统一的数据组织形式以统一各个阶段的训练。
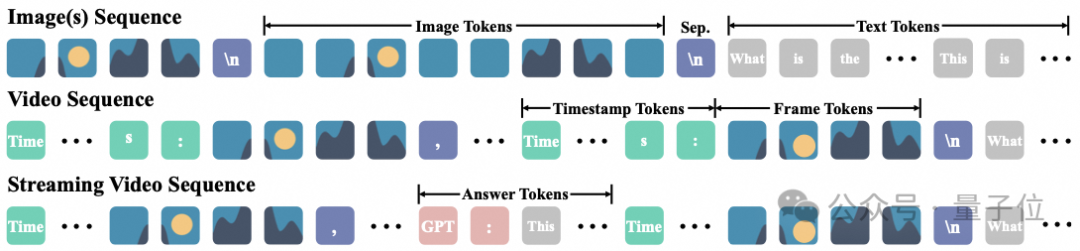
文本图像。
场景图像来源广泛,像VL3-Syn7M-short等,其中Object365和SA-1B数据集的引入增加了数据多样性;场景文本图像来自BLIP3-OCR,其文本内容和简短重新标注
都作为字幕;文档图像选取自pdfa-eng-wds和idl-wds,文档文本内容按阅读顺序作为图像字幕。
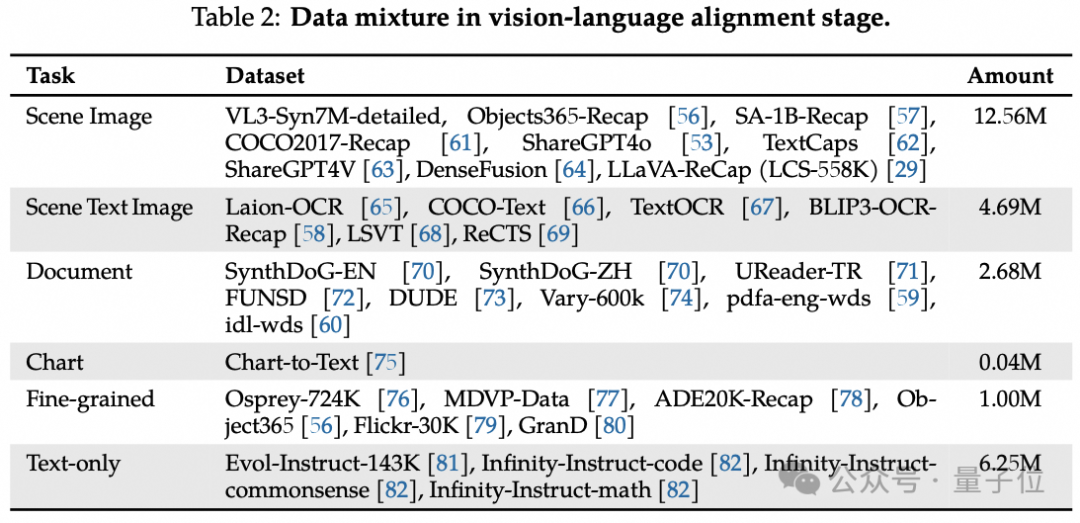
Vision-Language Alignment(视觉语言对齐):该阶段使用高质量数据微调模型,涵盖场景图像、场景文本图像、文档、图表、细粒度数据以及大量高质量纯文本
数据。
场景图像整合多个数据集并重新标注;场景文本图像包含多种中英文数据集,并对LAION数据集中图像筛选形成 Laion-OCR数据集,其字幕包含文本内容和文本位
置的边界框注释。
文档图像除常见数据集外,还加入手写和复杂文档数据集;图表数据虽量少,但来自Chart-to-Text 数据集;细粒度数据包含区域字幕数据和带框字幕数据,增强模型
对图像细节的理解。
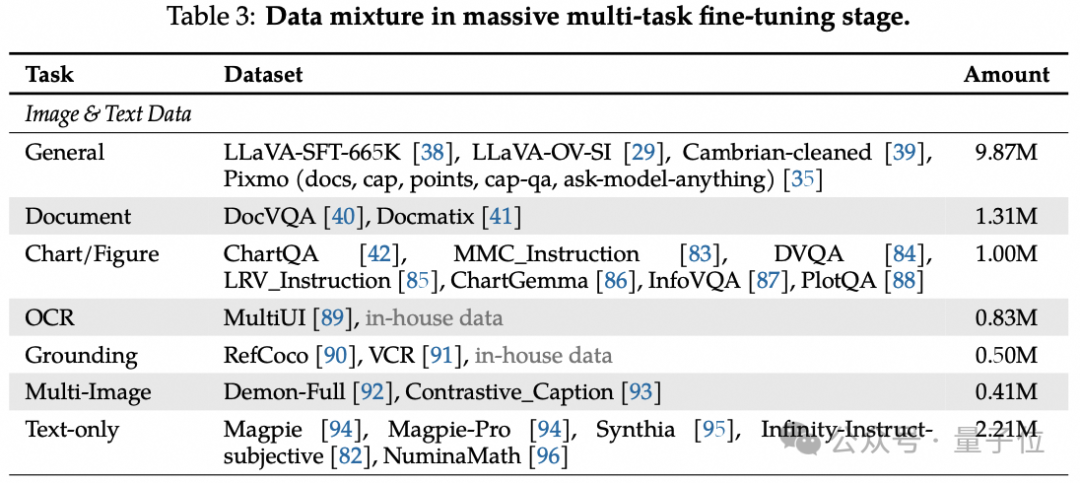
Multi-task Fine-tuning(多任务微调):用指令跟随数据进行指令微调,数据混合覆盖多种任务。
图像数据分为一般、文档、图表 / 图形、OCR、定位和多图像六类,每类针对特定视觉理解方面。同时包含大量纯文本数据,提升模型处理涉及视觉和文本输入的指
令跟随任务的能力。
视频数据则结合常用高质量视频字幕数据集、少量问答数据,以及VideoLLaMA2的内部数据和内部时间定位数据,增强模型视频理解能力。
Video - centric Fine - tuning(视频微调):此阶段聚焦提升模型视频理解能力,收集多个开源数据集中带注释的视频数据,还通过合成特定方面的密集字幕和问答
对扩展数据规模。
此外,引入流媒体视频理解和时间定位特征,同时使用一定量的纯图像和纯文本数据,缓解模型灾难性遗忘问题。

论文和demo地址放在下面了,感兴趣的小伙伴可以去体验喽~
论文地址:
https://arxiv.org/abs/2501.13106
GitHub项目地址:
https://github.com/DAMO-NLP-SG/VideoLLaMA3/tree/main?tab=readme-ov-file
图像理解demo:
https://huggingface.co/spaces/lixin4ever/VideoLLaMA3-Image
视频理解demo:
https://huggingface.co/spaces/lixin4ever/VideoLLaMA3
HuggingFace地址:
https://huggingface.co/collections/DAMO-NLP-SG/videollama3-678cdda9281a0e32fe79af15
文章来自于 微信公众号“量子位”,作者 :达摩院



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
