# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
“大模型排位赛”权威榜单Chatbot Arena刷新:
谷歌Bard超越GPT-4,排名位居第二,仅次于GPT-4 Turbo。
然鹅,众多网友对此却表示“不服”、“不公平”。

原来,谷歌AI掌门人Jeff Dean透露,Bard性能大幅提升,是因为搭载了新版大模型——Gemini Pro-scale。

这也就意味着,打“排位赛”的Bard具备了联网功能。

网友的质疑正是围绕着这一点展开:
在同一个排行榜上混合在线和离线大模型,是极易引起误解的。

Hugging Face的“首席羊驼官”Omar Sanseviero也表示:
既然如此…我也可以向lmsys提交具有搜索功能的Mixtral吗?

面对种种质疑声,Imsys官方做出了回应,其中指出:
对于网友们最关心的被Bard超越的GPT-4是不联网版本的问题,Imsys表示“如果实时数据的接入能够提升用户体验,排行榜将予以体现”。
并且直接@了OpenAI和Bing以及微软高管Mikhail Parakhin,表示非常乐意在竞技场中加入GPT-4联网版或Bing Copilot。
最新消息是,OpenAI的最新模型gpt-4-0125-preview现已入驻竞技场,等待用户参与投票。

Chatbot Arena是一个大模型权威榜单,由UC伯克利研究人员主导的Imsys(Large Model Systems Organization)组织创建。
该排行榜采用匿名1V1battle的投票规则,基于Elo评级系统排名。
具体来说,投票页面如下,两个模型Model A和B均匿名,用户在提出多个问题后对模型的回答打分,总共有四个选项:A更好、B更好、A和B一样好,A和B都不好。

值得一提的是,如果在问答过程中,模型身份泄露,那么该投票作废。

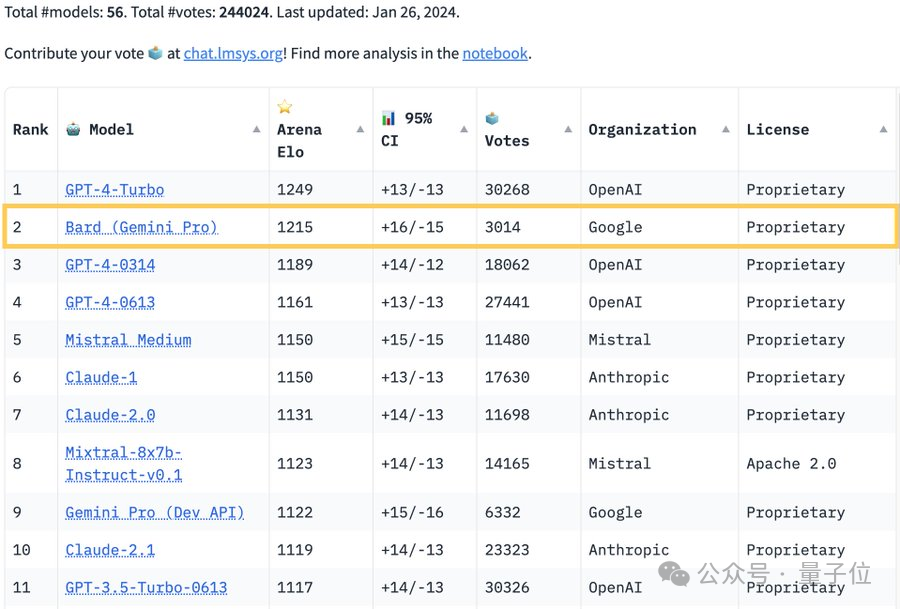
根据当前榜单,竞技场中有56个大模型:

此前GPT-4凭借“遥遥领先”的评分,长期霸榜,然而新版Bard发布后,直接超越GPT-4的两个版本冲到了第二名,和第一名的GPT-4 Turbo只差34分:

更详细一点,在所有没有平局的Model A对B的对决中,Model A获胜的比例如下:

还有每一对模型组合的单挑次数(无平局):

此外,Chatbot Arena排行榜还使用自助法对Elo评分估计进行1000次随机抽样,从而评估置信区间等。

单个模型相对于其他所有模型的平均胜率如下:

不过值得注意的是,Arena排行榜是实时的,Bard目前虽然排名第二,但总共只有3000多票。
相较而言,GPT-4 Turbo的票数已经达到了30000+,被超越的两个版本的票数也都是Bard的数倍。

而现在GPT-4最新版本已入场(虽然还没有在排行榜上更新),后续结果还要再坐等一波~
参考链接:https://twitter.com/lmsysorg/status/1752035632489300239



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
