# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
对于提升AI能主动发现问题、提出假设、调用工具并执行解决方案,在真实环境里闭环工作,而不只是在对话里“想”的智能体能力(Agency)。在这篇论文之前的传统方法认为,需要遵循传统语言模型的“规模法则”(Scaling Laws)才能实现,即投入更多的数据就能获得更好的性能。

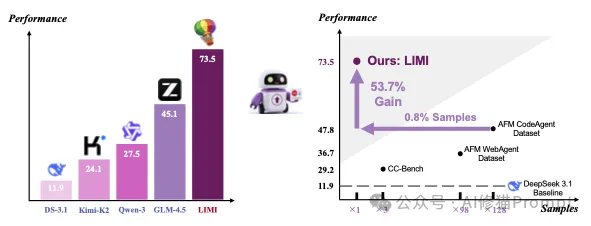
在不久前,来自上海交通大学、SII等机构的研究者们进行了一个巧妙的实验。他们首先拿一个强大的基础模型(GLM-4.5),在一套模拟真实编程和研究任务的综合能力测试(AgencyBench) 上进行评估,其初始得分为45.1%。
但随后研究者们仅仅用了78个精心策划的“专家级”示范案例来对这个模型进行专项训练。结果让模型的得分飙升至73.5%,性能暴涨超过60%!更有具颠覆性的是,当他们用传统的“题海战术”,给另一个完全相同的模型喂了10,000个普通训练样本后,其得分仅为47.8%。78个高质量样本的效果,完胜了10,000个普通样本。这一结果把“规模法则”在智能体能力上的统治地位给撬动了。研究者们也因此得出了一个重要结论:“代理效率原则 (Agency Efficiency Principle)”:机器的自主性不是源于海量数据的堆砌,而是源于对高质量代理行为示范的战略性策划”。
对企业的意义是:核心竞争力从算力转向“流程建模 + 高密度轨迹策展”。谁以后更会策展真实问题与高质量示范,谁就能更稳、更快地把模型训成“会干活的同事”,这对拥有垂直领域私有、稀缺的闭环轨迹的非头部公司,反而是机会。
有朋友可能会问,什么是Agency?和Agent是一个意思吗?答案不是。您也可以看一下《99%的人都理解错了,AI Agent ≠ Agentic AI,康奈尔大学发33页论文澄清关键区别。》Agency 是一种能力维度,描述“在环境中能规划、执行、用反馈迭代并完成可验证目标”的综合行为能力;Agent 是一种系统形态,把模型与记忆、工具、运行环境、调度循环组合起来,用来承载并释放这种能力完成某种目标。
LIMI能够用仅仅78个样本实现“少即是多”的惊人效果,其成功的秘诀不在于样本的数量,而在于一套极其严格和精巧的方法论,旨在最大化每一个样本所蕴含的学习价值。
在开始收集数据之前,研究者首先选择了两个最能体现复杂知识工作的领域:
为什么这一步很重要? 因为这两个领域天然地排除了简单的问答任务,确保了所有的问题都必须通过多步骤的规划、推理和工具使用才能解决。这从源头上保证了数据的复杂性和高质量。
确定了领域后,团队的目标是创造出能够充分模拟真实世界挑战的复杂任务,即“用户查询 (User Query)”。他们通过两种方式来构建最终的78个查询:
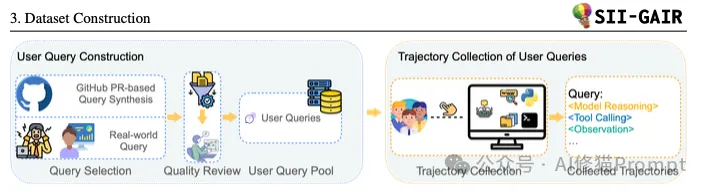

查询特点:这些查询通常是复杂的“长远任务 (Long-Horizon Tasks)”,包含多个相互关联的子任务。例如,上图中展示了一个开发“Gomoku(五子棋)”游戏的用户查询,它被分解为5个子任务:从前端界面开发,到赢棋检测,再到实现不同难度的AI对手。
这是整个方法论中最关键的一步。对于这78个复杂的查询,LIMI的目标不是记录“最终答案”,而是记录下从开始到成功解决问题的完整、多回合的“轨迹 (Trajectory)” 。
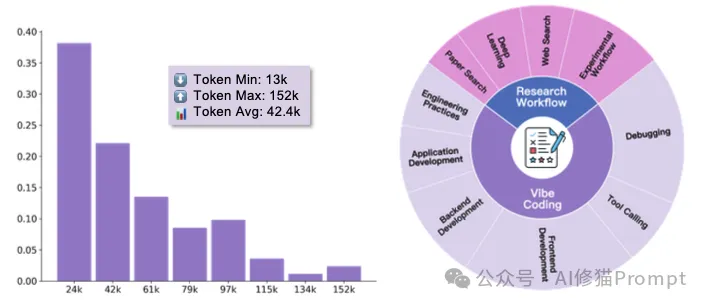
1.<Model Reasoning> (模型推理):AI的思考、分析、规划和决策过程。
2.<Tool Calling> (工具调用):AI执行具体操作,如运行代码、读写文件、搜索网络等。
3.<Observation> (环境观察):工具执行后返回的结果以及人类专家的反馈和修正。
研究者们并没有从零开始训练一个新模型,而是选择了一个已经非常强大的预训练模型,GLM-4.5(355B参数),并在这个基础上进行“微调”。您可以将这个过程理解为:
1.选择“天才学生”:首先,他们选择了一个已经读完整个互联网、知识渊博但缺乏特定实践技能的“天才学生”,也就是基础模型GLM-4.5。
2.提供“专家教材”:然后,他们将前面精心制作的78个高质量“专家案例”(即完整的轨迹数据)作为教材。
3.进行“专项培训”:他们使用一个名为slime的专业框架,对这个“天才学生”进行监督式微调(Supervised Fine-tuning)。值得一提的是,论文中所有的对比实验(包括那个使用10,000个样本的“题海战术”模型)都使用了完全相同的训练框架和配置,这确保了最终的性能差异可以最大程度地归因于训练数据的质量,而非训练过程本身。这个过程就是让模型学习这78个案例中的专家级思考和行动模式,从而掌握“代理智能(Agency)”这项新技能。
经过这个过程,原有的GLM-4.5模型就进化成了LIMI模型 。模型的大小(参数量)没有变,但它内在的能力已经被这78个高质量样本深刻地重塑了。
当然,说得再好听,还得看实际效果,结果是真的有点猛。
LIMI在专门为评测AI代理真实世界协作能力的基准AgencyBench 上,其性能大幅超越了当前所有顶尖的基线模型。

Agency Bench任务一览
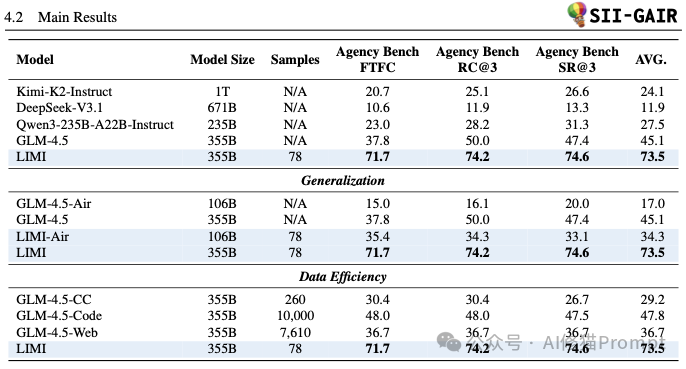
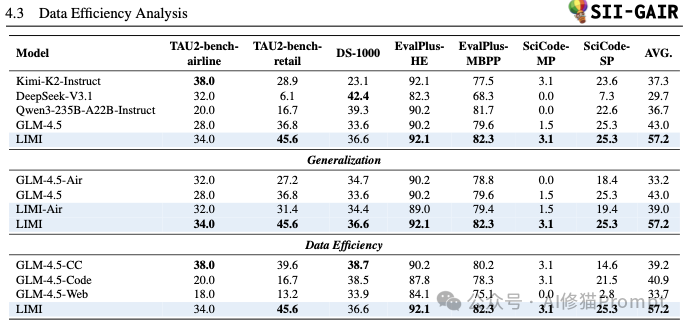
这是支撑论文核心论点的最关键证据。实验结果表明,战略性的数据策划远比扩大数据规模更有效
实验证明,通过LIMI方法学到的能力并非局限于特定任务,而是具有广泛的适用性。
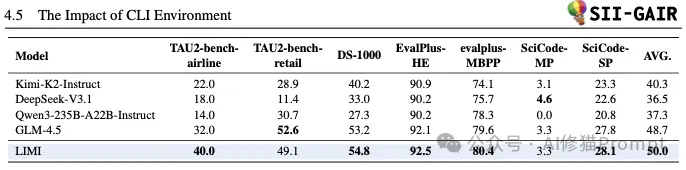
为了排除“性能提升只是因为更会使用特定工具”的可能性,研究者进行了一项重要的对照实验:在不使用SII CLI工具环境的情况下进行测试。
实验结果从性能、效率、泛化性和内在能力等多个维度,全面且有力地验证了LIMI的“少即是多”假说,展示了一条培养AI代理能力的全新、高效路径。
LIMI的成功源于信息密度的巨大差异,它将AI能力提升的关键,从 “数据的丰富度 (data abundance)” 转移到了“高质量示范的战略性策划 (strategic curation of high-quality agentic demonstrations)”。
因此,LIMI的一个样本在培养“代理智能 (Agency)” 方面所能提供的学习价值,可能比成百上千个简单的问答样本还要高。它教会模型的不是零散的知识点,而是一套可以泛化的、自主解决问题的思维框架和工作流程。
文章来自于微信公众号“AI修猫Prompt”。



【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
