# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
CoT思维链的下一步是什么?
DeepMind提出帧链CoF(chain-of-frames)。
逐帧视频生成类似于语言模型中的链式思维。就像链式思维(CoT)使语言模型能够用符号进行推理一样,“帧链”(CoF)使视频模型能够在时间和空间上进行推理。
以上观点来自DeepMind最新公开的Veo 3论文,类比语言模型中的CoT,他们首次提出了CoF这一概念。

并且,团队通过大量测试发现——
以Veo 3为代表的视频模型正在发展通用视觉理解能力,可以零样本解决从“看”到“想”的全链条视觉任务,而且进步飞快,未来有望成为机器视觉的“通用基础模型”。
更简单粗暴的总结就是,“Veo 3是视觉推理领域的GPT-3时刻”。

Anyway,要想深入理解这一新概念以及其价值意义,还是先来看看论文原文吧——
据论文介绍,CoF的提出源于DeepMind团队的一个好奇:
视频生成模型能不能像ChatGPT这类大语言模型(LLM)一样,不用专门练某个任务,就能搞定各种视觉工作,最终变成“通用视觉基础模型”?
为什么追求通用?主要是现在的机器视觉领域还停留在“NLP的老阶段”——
要分割物体就得用“Segment Anything”、要检测物体就得用YOLO、换个任务就得重新调模型、甚至重训……

既然现在的视频生成模型和LLM用的是同一套底层逻辑——用海量数据“大力出奇迹”,那说明通用视觉并非无稽之谈。
为了验证这一猜想,团队用了一个非常简单粗暴的方法:只给提示,不搞特殊训练。通过Google的API,给模型“一张初始图(当第一帧)+ 一段文字指令”,让模型生成8秒、720p的视频。
这和LLM“用提示替代专属训练”的逻辑完全一致,目的就是为了验证模型的原生通用能力,纯靠模型自己去完成任务。
而通过一系列测试,团队发现视频模型真的具备通用潜力。
具体而言,他们以Veo 3为实验对象,发现其具备四大能力(层层递进):
第一,不用专门训练,Veo 3就能搞定很多经典视觉任务,具备感知能力。
无论是基础任务(如把模糊图变清晰),还是复杂任务(如在一堆东西里找“蓝色的球”),它都能轻松应对。


第二,光看明白还不够,Veo 3还能“建立视觉世界的规则”,具备建模能力。
这体现在它既懂物理(如知道石头会沉),又懂抽象关系(如把能装进背包的东西放进去)上。


第三,基于“看明白”和“懂规律”,Veo 3还能主动改变视觉世界,具备操控能力。
比如改改图(给小鸟加上围巾、置身雪景),或者搞3D和模拟(让骑士从朝前变成单膝跪地)。


第四,整合前面的能力,Veo 3可以实现跨时空视觉推理,也就是所谓的CoF帧链。
给它一道解迷宫的难题:让红点从起点沿白色路径走到绿点。
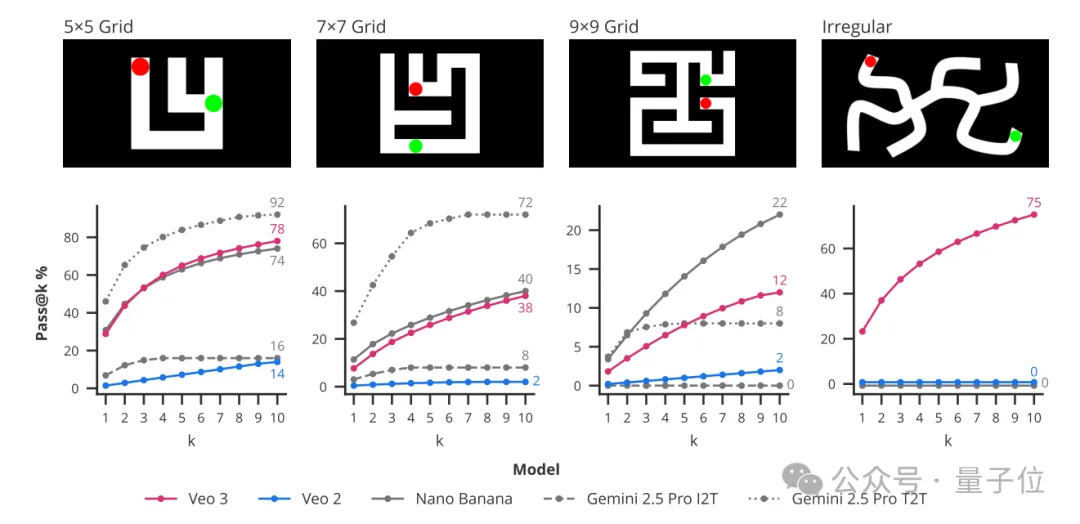
Veo 3能生成红点一步步规划路径的视频,不碰黑墙。5×5迷宫玩了10次,Veo 3成功率78%,Veo 2才14%。
更多推理测试也表明,虽然推理能力还不完美(复杂的旋转类比会出错),但已经能看到“视觉智能的雏形”了。
整体而言,团队通过测试得出了以下三个核心结论:
1、经过对62项定性任务和7项定量任务中生成的18384个视频的分析,团队发现Veo 3能够解决许多它未曾接受过训练或调整的任务。
2、Veo 3利用其感知、建模和操作视觉世界的能力,展现出了类似“帧链(CoF)”的视觉推理的早期形态。
3、尽管针对特定任务定制的模型在零样本视频模型中表现更优,但团队观察到从Veo 2到Veo 3的性能有了显著且一致的提升,这表明视频模型的能力正在迅速发展。
此外,基于Veo 3当前的表现以及成本可能持续下降的预测,DeepMind也大胆开麦:
在视频模型领域,未来“通才”会取代“专才”。
具体而言,Veo 3作为通用视频模型,在特定任务上确实仍落后于专用SOTA模型,如边缘检测精度不及专门优化的算法。
但从发展趋势看,这种差距正随模型能力快速提升而缩小,类似早期大语言模型(如GPT-3)虽整体不如任务微调模型,但通过架构、数据与训练方法的演进,最终成长为强大的通用基础模型。
比如相比前一代Veo 2,Veo 3在短期内全面升级。这证明模型的通用视觉与生成能力正处于快速上升期,类比2020年前后LLM的突飞猛进阶段。
其次,通过多尝试(pass@10) 策略,即同一任务多次生成并择优,Veo 3性能显著高于单次生成,且随着尝试次数增加仍有提升空间,无明显上限。而且结合推理时缩放、RLHF指令微调等技术,Veo 3性能仍有望进一步提升。
此外,尽管目前视频生成的成本高于专用任务模型,但根据Epoch AI的数据——LLM推理成本每年下降9~900倍,且NLP早期通用模型(如GPT-3)也曾因成本被质疑,但最终因“通用价值+成本下降”替代了专属模型。
因此,大概率机器视觉会走上同样路径,未来视频模型的成本问题将逐步得到解决。
总而言之,DeepMind对通用视频模型可谓信心满满。
而此次提出的新概念CoF,也正如网友所言,有望和当初的CoT一样,为视频模型开辟出新的道路。

论文:
https://papers-pdfs.assets.alphaxiv.org/2509.20328v1.pdf
参考链接:
[1]https://x.com/AndrewCurran_/status/1971997723261075905
[2]https://simonwillison.net/2025/Sep/27/video-models-are-zero-shot-learners-and-reasoners/
文章来自于微信公众号“量子位”,作者是“一水”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
