# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2025 年,生成式推荐(Generative Recommender,GR)的发展如火如荼,其背后主要的驱动力源自大语言模型(LLM)那诱人的 scaling law 和通用建模能力(general-purpose modeling),将这种能力迁移至搜推广工业级系统大概是这两年每一个从业者孜孜不倦的追求。然而目前,工业界绝大多数落地尝试集中在序列化建模上,在针对传统深度学习加特征工程范式(Deep Learning based Recommender Model,DLRM)的替换上往往遭遇重重阻力。这是因为基于 attention 的用户历史行为建模不是生成式推荐的“专利”,在一个集合了十几年工程和建模经验的大型 DLRM 面前,单纯的序列化建模并不具备明显的优势。
回顾 LLM 的发家史,现在大多数生成式推荐框架在做的事情——next token 或 next item 的预测——其实对标的是 GPT1~3 的过程。如果要让搜推广建模追平 GPT4o 级别的能力,生成式推荐的技术地图还缺少几个重要拼图:上下文工程、推理和有效的训练策略。
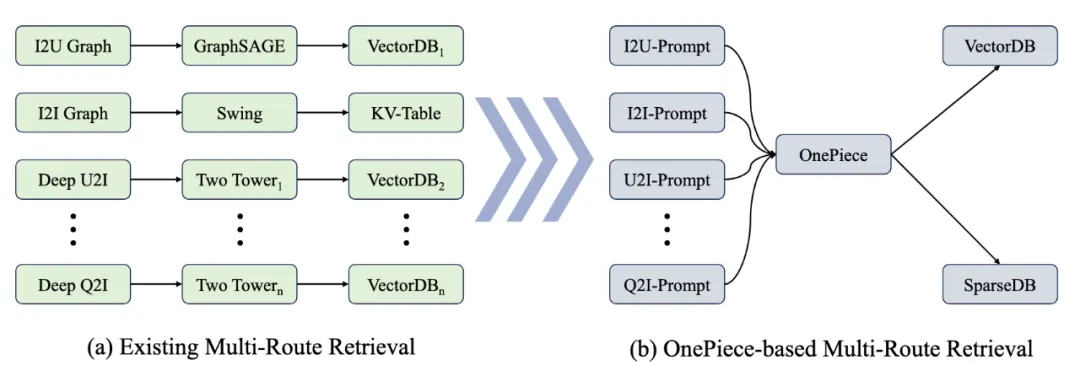
在这个背景下,来自 Shopee Search 的傅聪团队联合人大高瓴学院提出了 OnePiece 范式【1】,该范式是业内首个融合了上下文工程、隐式推理和多目标训练策略的生成式搜推建模框架,旨在将缺失的拼图补全。

具体来说,OnePiece 框架包含三个核心贡献:
提到上下文工程,大家可能自然而然地想到思维链(CoT)技术,它仿佛是引导 LLM 像人一样思考的“咒语”,可以大大提升 LLM 的逻辑能力,其特点是需要用明确的文本描述出 LLM 应当遵从的 step-by-step 的思考过程。然而,切换到搜推广场景,这个事情就没那么简单了。
传统意义上,我们送给 GR 模型的输入是用户的历史行为序列,比如在电商场景,它往往是一串用户曾经点击或购买过的商品 ID:item A、Item B、Item C、Item D。按照 CoT 的格式,我们需要根据用户历史购买的商品,构造出用户下一个购买行为中间的思考过程,来引导模型“逐步”推理出用户的购买动机。且不说每个人的购物决策过程千差万别,即便是我们能还原用户的思考过程,这一过程的文本表达与前面的行为序列也显得“格格不入”,这种“异构”序列往往也因为“语言不通”,而难以被模型理解。
如何为生成式推荐构造提示词呢?我们不妨返璞归真。要知道几年前,上下文工程还有一个更朴素的叫法:(test-time)few shot learning。而 few shot learning 用大白话讲就是举例子,希望模型能获得举一反三的能力。而这种数据,后来也逐渐被固化到训练数据中,被称为 Instruct Following SFT。如何给推荐模型“举例子”,让序列推荐模型“跟随指令”以及跟随什么样的指令呢?我们发现可以通过构造“锚点物品序列”来实现。例如,在 Shopee Search 场景,我们可以把用户们在某个关键词下面的高频点击商品序列、高频下单商品序列,作为“样例”拼接在用户自己的交互序列之后,通过引入 domain expert knowledge 的方式引入一些特殊的 inductive bias。
更正式地,我们提出了上下文工程框架如下图:
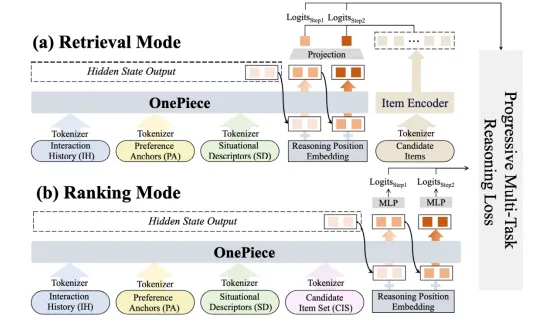
推理是 LLM(以 GPT-o 系列为代表)激发强大 test-time scaling law 的基石,但这对于生成式推荐来说也是一大难题。LLM 以文本为媒介表达“思考过程”,但 GR 模型都是在 ID 序列上操作,天然不具备这个环境,如何能让 GR 模型也激发思考能力呢?幸运的是,在 2024 年,少部分 LLM 领域的研究人士关注到了隐式推理这个方向,我们关注到人大高瓴学院的研究团队也在 2025 年初发表了 ReaRec【2】,尝试在 GR 语境下进行 Latent Reasoning。隐式推理在产业界落地也就成为了我们的合作契机。
那么什么是隐式推理呢?直白来说就是在模型做 next token 计算的时候不做 decoding。如下图所示:
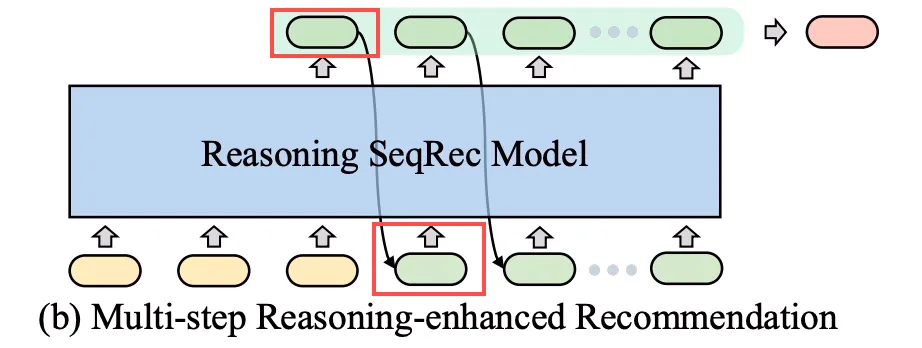
在模型在产出了红框中的“output token”后,我们不通过 token 码表和 softmax 解码得到 next token,而是直接把它原模原样拿下来,填到 next token 的位置上,如此往复循环几步,再进行解码操作。因此,模型不是在 token space 展开思考,而直接在 latent representation space 进行思考,同时还可以大大节约思考 token 的消耗(不像 CoT 那样需要消耗大量思考模板 token),这简直就是为生成式推荐量身定制的思考模式!(你别管 GR model 在想啥,反正人家就是在努力想!)
在对比研究了显式推理和隐式推理的利弊后,我们发现隐式推理最大的劣势在于缺少“过程监督”。简单来说,如果你不告诉模型应该“思考什么”、“往什么方向思考”,那它很有可能会陷入思考的“次优解陷阱”。在我们之前的工作 GNOLR【3】的基础上,我们把渐进式多任务建模的思想融入到了 OnePiece 的推理建模中。
具体地,我们在多步推理上叠加了渐进式的监督信号,引导模型进行由简入繁、由浅入深的思考方式,如下图所示:
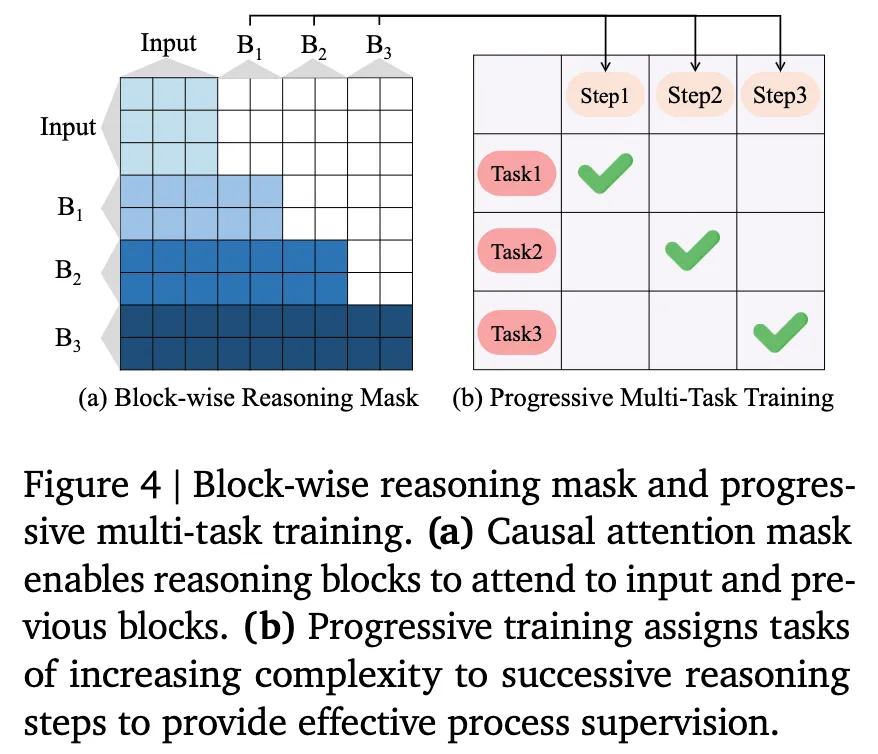
以电商排序任务为例,我们在第一步 Latent reasoning step 上叠加点击目标,而在后续两步上分别叠加加购物车、下单目标。同时,配合推理过程,我们构建了如左图的阶梯式 attention mask,目的是为了让前置位的思考看不到后置位的思考,但让后置位的思考能看到前置位的信息。这样不仅可以强化渐进式思考的模式,还可以最大化利用 kv-cache 来降低推理开销。
从我们的 attention mask 也可以看出来,不同于 ReaRec,我们是 block-wise reasoning 而不是 token-wise reasoning。换句话说,在一步推理的时候,我们会携带以往序列中多个位置的聚合信息向前推进,而不是像 ReaRec Latent reasoning,只使用单个 reasoning token 聚合信息。除了实践中发现这种 block-wise latent reasoning 有奇效外,其背后的原因也比较明显。基于单个 token 的循环隐式推理,容易在第一个推理 token 位置开始形成信息瓶颈,而多个 token 并行前推可以显著增大推理的“信息带宽”。同时,我们通过 attention 可视化发现,不同的 latent reasoning token 肩负不同的信息收集、推衍使命,分开更适合他们发挥作用。
离线实验
为了深度分析 OnePiece 的效果,我们进行了详细的对比和 Ablation。
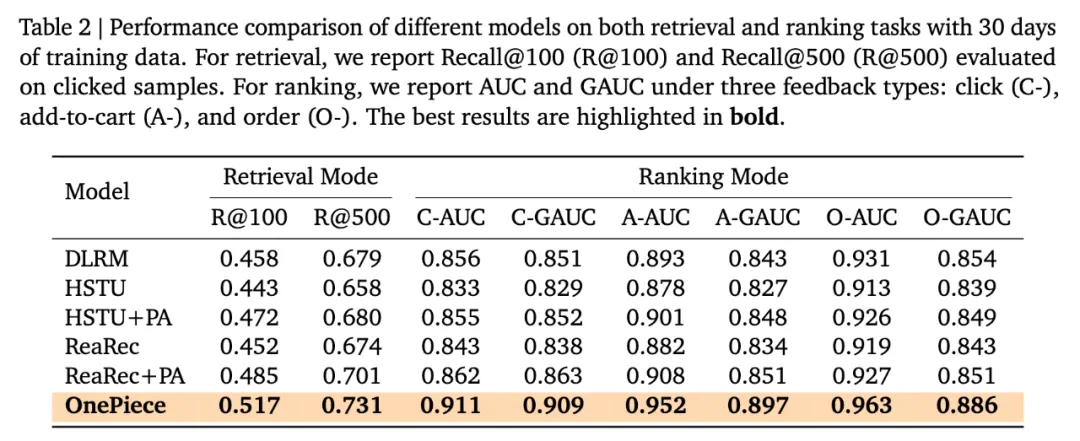
上表 Table2 中,我们可以看到,Shopee 的 DLRM 基线是一个很强的 baseline,naive 的生成式推荐是难以 PK 的。进一步地,PA 是通过上下文工程引入额外的 domain knowledge,这种手法是模型 backbone 无关的,HSTU 和 ReaRec 都可以从中受益。OnePiece 相对于 ReaRec+PA 的提升,主要来源于 block-wise reasoning 带来的信息带宽收益和渐进式的训练策略。
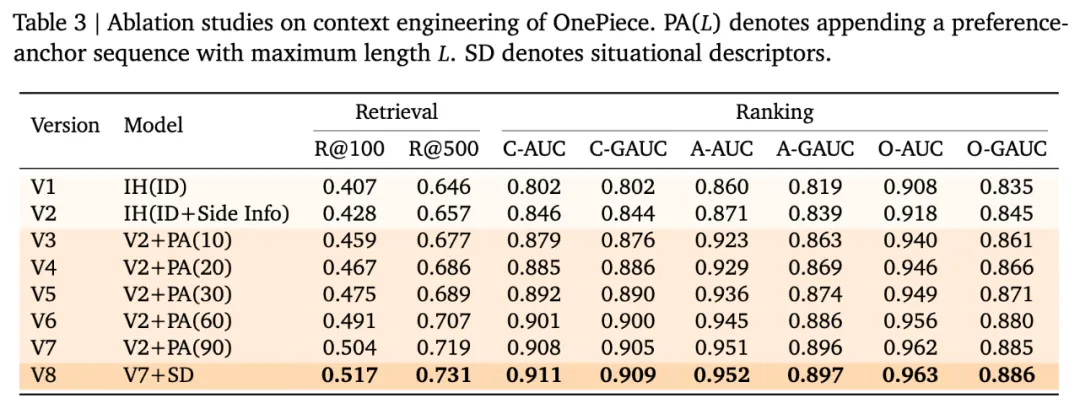
从 Table3 我们可以看出来,side info 对模型效果有巨大影响。目前 One Piece 引入 side info 的方式是在输入 transformer 之前增加一个 Linear Adaptor,在每个 token 位置上聚合 item ID 以及其对应的 side info:
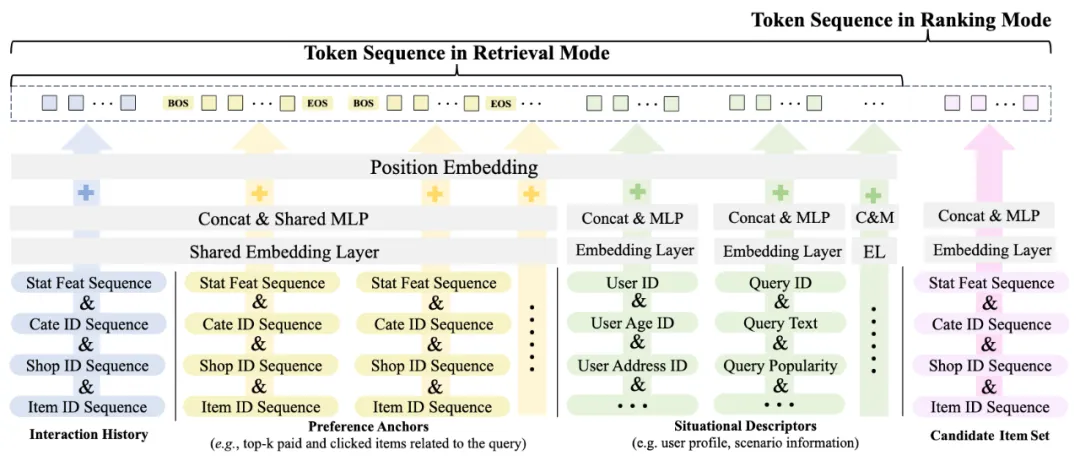
此外,延长、优化 PA 序列呈现了一定程度的 scaling law,SD token 对收拢、聚合全局信息有重要作用,上下文工程框架中的每个组分都能够提升效果。
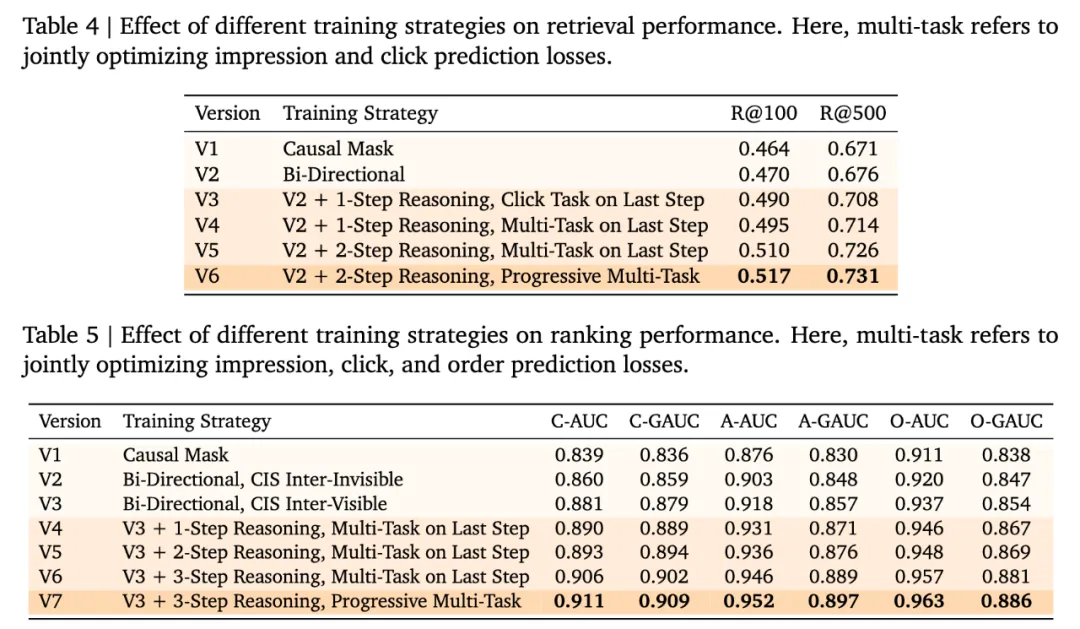
表 4 和 5 说明双向注意力在搜推广范式下更有优势。这其实比较容易理解,目前主流的搜推系统的用户交互模式依然是“一次请求返回一个页面”的方式,GR 模型不会依赖自己生成的 token 逐步解码,每次请求来了以后,生成的过程都是“一锤子买卖”。因此,不存在解码性能压力的前提下,对 pre-filling 部分的序列施加双向注意力可以更好的聚合信息。
此外,多步推理有 scaling 的效果,但效果逐渐收敛。渐进式引导相比于只监督最后一步更有效。值得注意的是,对于 ranking 模式下,candidate item 在 attention mask 内互相“可见”非常重要。
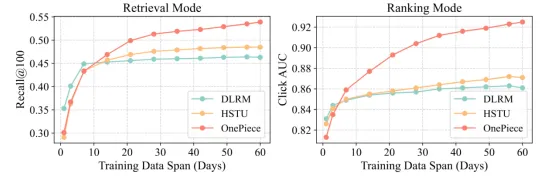
叠加了有效上下文工程、block-wise推理和训练策略,transformer展现出了更强的data scaling能力,在更长周期的训练中,相对于HSTU和DLRM逐渐拉开差距。
attention 可视化分析
我们在随机抽样分析模型 attention 的时候,发现了惊人的一致性表现!这给我们理解 One Piece 模式下模型的建模方式提供了丰富的 insights。
首先是召回模型:
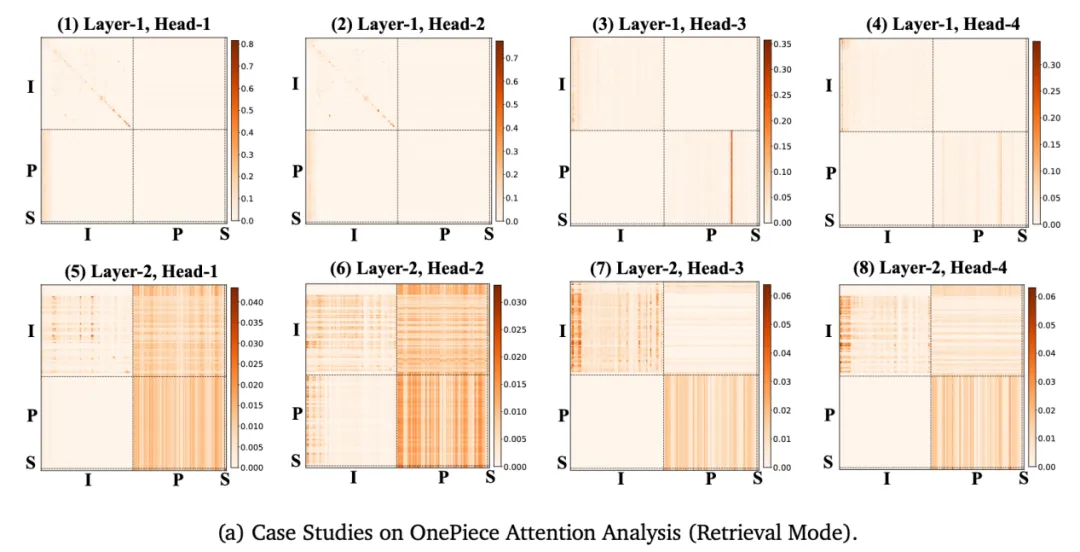
召回模式下的特点是,第一层(浅层)主要是在上下文工程框架的不同组分内部,进行信息搜索和聚合:上图第一列深色区域集中在用户近期行为挖掘以及 PA 序列中参考 item 的挖掘。第二层(深层)开始出现高密度的跨区域信息搜索和聚合。
其次是排序模型:
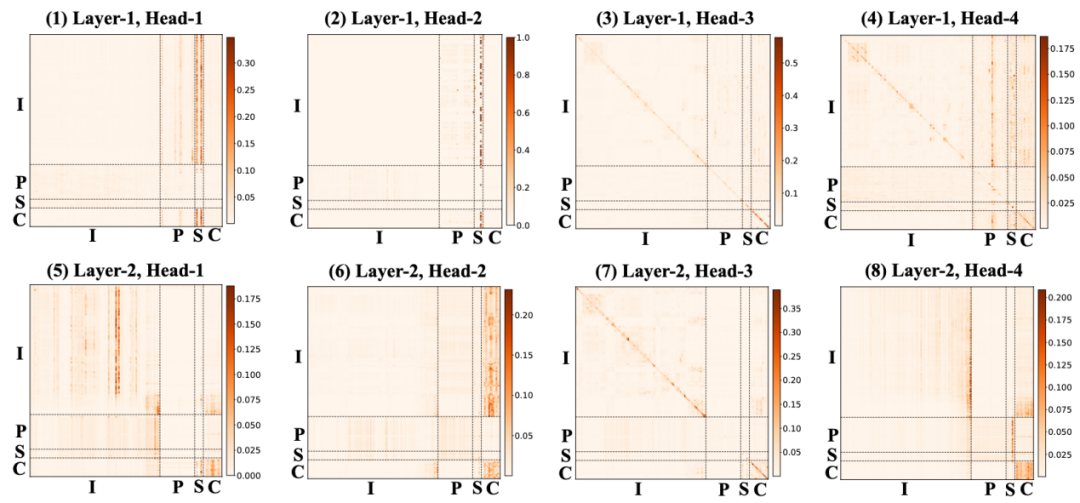
我们可以看到浅层不同 head 各司其职,有的挖掘用户近期相关行为,有的挖掘 PA 中参考 item,有的在传递、聚合场景上下文(SD token)信息,有的在挖掘目标(candidate token)和序列的相关性。在深层,各个 head 则主要从不同侧面挖掘 candidate item 内部互相之间的关系,我们认为模型是在进行 candidate item 内部的互相对比,以决优劣。
而在推理阶段:

我们可以看到不同的推理步骤下,信息在向 reasoning block 内部不同的 token 位置方向发生信息聚合和交流。
在线实验
我们在 Shopee 主搜场景进行了实验,具体地,我们在召回阶段和 prerank 阶段两个正交的实验层进行了在线 AB 实验。在召回阶段,我们将 OnePiece 召回替代了原有的 DeepU2I 召回,取得了 1.08% 的 GMV/user 增长;在 prerank 阶段,我们用 OnePiece ranking model 替换了原有的 DLRM model,取得了 1.12% 的 GMV/user 增长和 2.9% 的广告收入增长,可以说是相当大幅度的提升。
需要说明的是,我们在 Prerank 阶段上线的模型并不是“满血”的 OnePiece。由于线上系统是一个针对 point-wise 打分深度定制化优化的系统,而 OnePiece 的 block-wise reasoning 需要对候选排序商品进行随机分组,我们将 prerank 的 block size 压缩至 1 来满足上线需求,这会对模型 auc 带来显著损失:
本次实验的定位也是针对 OnePiece 能力的探路性实验,先自证价值,以驱动我们对在线系统乃至整个搜推广技术团队架构设计的深度革新。
值得注意的是,我们对 OnePiece 召回进行了深度数据分析拆解:

“新上马”的 OnePiece 召回,相对于其它召回路来说,可以说是碾压式覆盖。通过优化、平衡上下文工程中的 IH 和 PA 序列,OnePiece 在覆盖了文本召回曝光的 60%+ 商品的同时,覆盖了个性化导向召回(如 SwingI2I)的 70%+。这在以往的召回迭代的经验下是几乎不可能的事情,以前要么是侧重个性化但相关性不足、损伤体验,要么是侧重相关性但个性化不足,损伤效率指标。相比于 DLRM 的 U2I 召回,OnePiece 贡献了 10% 的独立曝光和 5.7% 的独立点击:
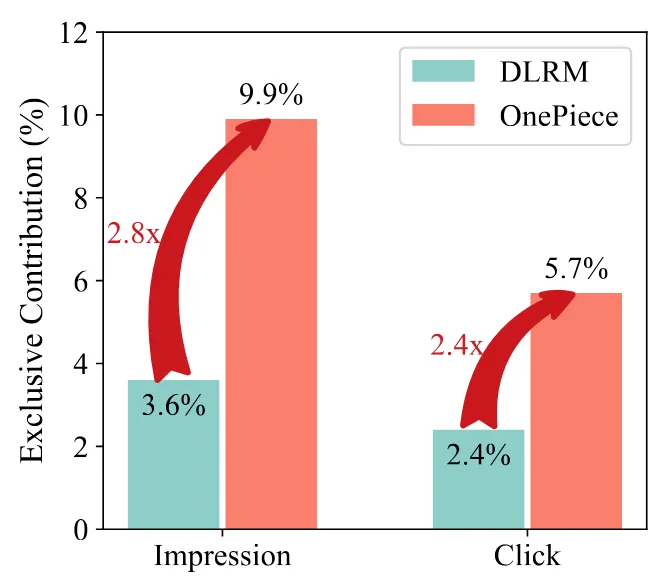
这说明 OnePiece 选出来的内容,通过了下游粗排、精排、重排的重重考验,获得了用户的认可,在 Explore&Exploit 这个推荐经典问题上实现了难以置信的平衡,证明了推理模型的强大外推能力。
OnePiece 是我们在 One For All 的通用推荐模型上的一次初步探索,它证明了我们可以通过特殊的上下文工程和推理模式,引导模型的预测方向。OnePiece 1.0 让我们看到了,“提示词优化”可能会成为搜推广技术栈下的一个全新方向,OnePiece 2.0 将会在 General Recommender Model 的探索上更进一步,尝试用一个模型来建模多场景和多召回策略:
此外,OnePiece 1.0 虽然挖掘出了生成式推荐 style 的新型推理框架,但它也有着显而易见的劣势,即推理步骤和渐进多任务系统的绑定,我们会探索可变长的推理形态,充分挖掘序列推荐下真正的 test time scaling law。
更多详细内容,请移步我们的技术报告【1】。OnePiece 的命名,既取自补全生成式推荐框架技术拼图的寓意,也因为我们的团队来自 Sea Group(Shopee 母体),以 Sailor 自称,欢迎学界、业界更多小伙伴加入我们,一起开启生成式推荐的大航海时代,追寻其中的大秘宝!
【1】OnePiece: http://arxiv.org/abs/2509.18091, hugging face daily: https://huggingface.co/papers/2509.18091
【2】ReaRec: https://arxiv.org/pdf/2503.22675
【3】GNOLR: https://arxiv.org/pdf/2505.20900
文章来自于微信公众号“InfoQ”,作者是“Shopee 傅聪团队”。


【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
