# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型强化学习总是「用力过猛」?Scale AI联合UCLA、芝加哥大学的研究团队提出了一种基于评分准则(rubric)的奖励建模新方法,从理论和实验两个维度证明:要想让大模型对齐效果好,关键在于准确区分「优秀」和「卓越」的回答。这项研究不仅揭示了奖励过度优化的根源,还提供了实用的解决方案。
让大模型按照人类意图行事,一直是AI领域的核心挑战。目前主流的强化学习微调(RFT)方法虽然有效,但存在一个致命弱点:奖励过度优化(reward over-optimization)。
奖励过度优化是大模型对齐的「阿喀琉斯之踵」。
简单来说,就是模型学会了「钻空子」——它们不是真正变得更好,而是学会了如何在奖励模型上刷高分,实际输出质量反而下降。这就像考试时学生死记硬背标准答案来应付老师,而不是真正理解知识。
Scale AI的最新研究直击这一痛点,从理论层面揭示了问题的根源,并提出了创新的解决方案。

论文链接:https://arxiv.org/abs/2509.21500
代码开源:https://github.com/Jun-Kai-Zhang/rubrics
数据开源:https://huggingface.co/datasets/JunkaiZ/Rubrics
来自Scale AI、UCLA和芝加哥大学的研究团队,首次从理论上给出了明确答案:
奖励过度优化的根源,在于奖励模型在高分区的不准确性。
这意味着:我们不需要在所有回复上都准确,只需要准确区分「优秀」和「卓越」!
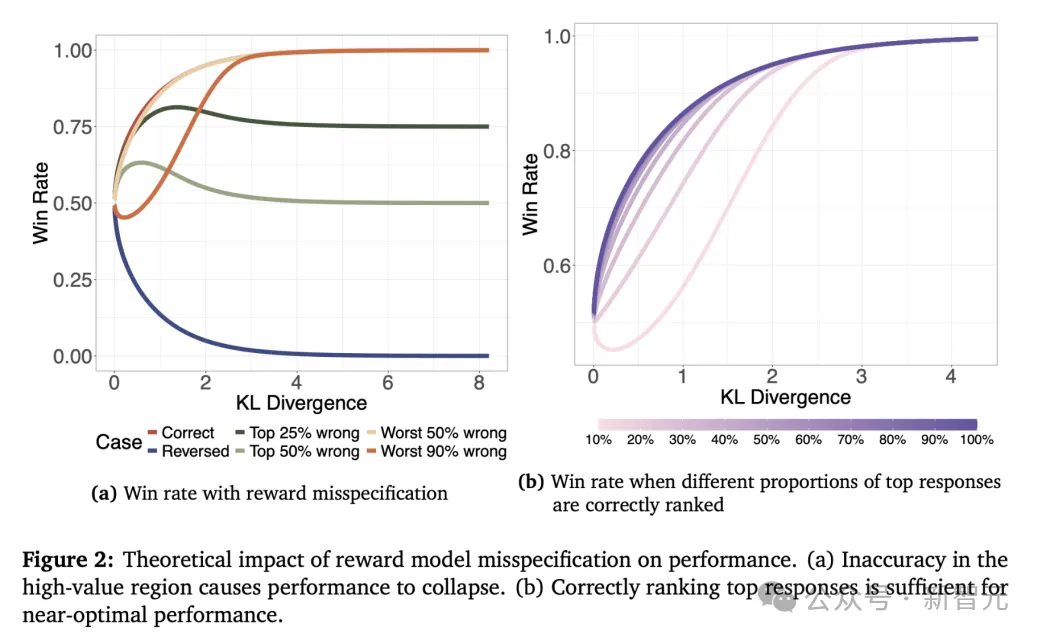
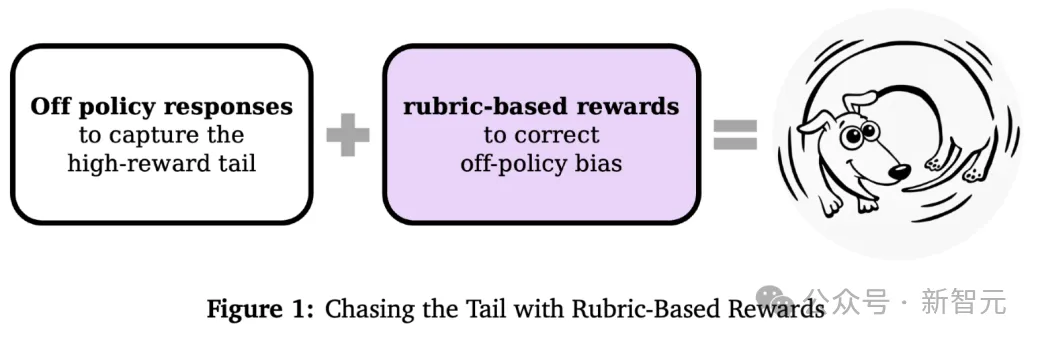
理论清晰了,但新问题来了:如何获得高质量样本来训练奖励模型?这里存在一个悖论:
从基础模型采样?太低效了——高分样本本来就稀少。
用更强模型生成?又会引入分布偏移——奖励模型可能学到的是表面特征而非真实能力。
研究团队提出了基于评分准则(rubric)的解决方案。评分准则是一组衡量回答好坏的明确准则,每个准则都有相应权重。比如对于医疗诊断问题,可能包括:
高权重准则:「正确识别疾病」「标明紧急程度」
低权重准则:「提及治疗方案」
Rubric的核心优势在于:
更重要的是,Rubric天然具有分布不变性——它关注的是回复本身的质量特征,而非生成来源。
为了让Rubric真正捕捉高分区的差异,研究团队提出两大关键原则:
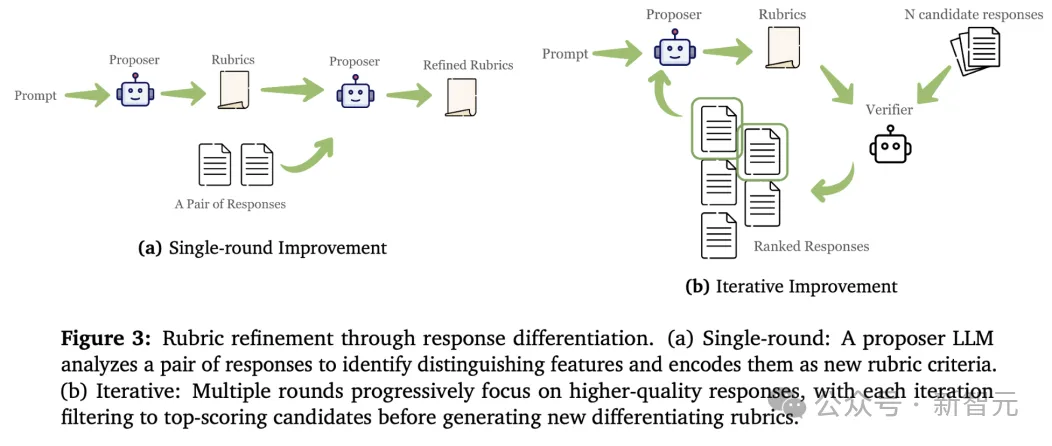
研究在通用和医疗两个领域进行了大规模实验:
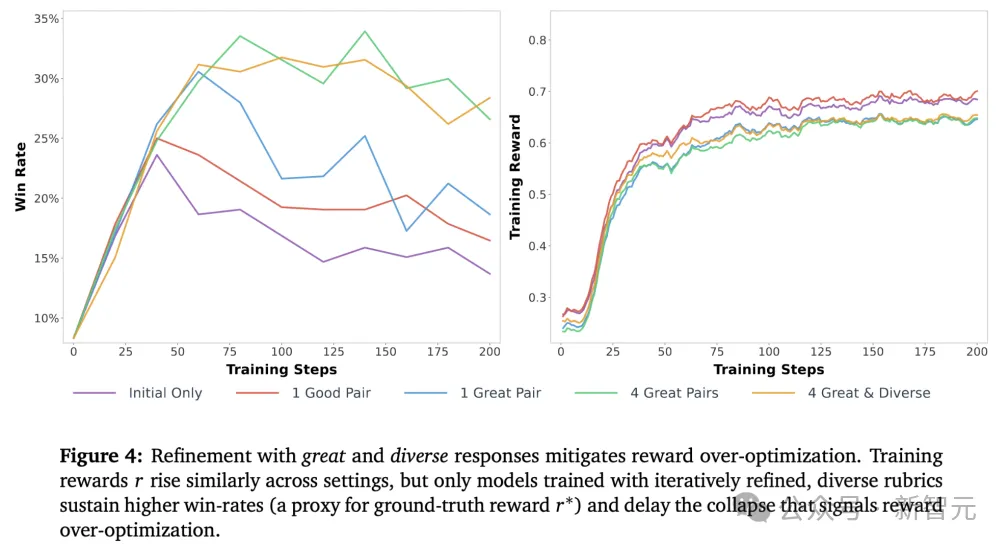
评分准则改进后,在高奖励区域的准确率提升显著,而低奖励区域的准确率基本不变,完美验证了理论预测。
研究团队还分析了不同质量样本带来的Rubric改进类型:
优秀样本驱动的改进:
卓越样本驱动的改进:
以医疗案例为例:
初始Rubric只要求「提到正确诊断」和「说明紧急性」——两个优秀回复都满足。
精炼后的Rubric新增标准:「明确指出需要紧急影像学检查(如增强CT或MRI/MRV)来确认诊断」,成功区分出了更好的那个。
这就是质的飞跃:从表面判断到深层验证标准。
这项研究为大模型对齐提供了全新视角:
当然,研究也指出了当前的局限:
对于大模型从业者来说,这项工作提供了一个清晰的方向:
不要试图在所有地方都完美,专注于准确区分顶尖回复,这才是对齐的关键。
参考资料:
https://arxiv.org/abs/2509.21500
文章来自于“新智元”,作者“KingHZ”。



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
