# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大型语言模型(LLM)训练的核心基础设施是 GPU。现如今,其训练规模已达到数万块 GPU,并且仍在持续扩大。同时,训练大模型的时间也越来越长。例如,一个 405B 参数模型 LLaMA 3 的预训练,动用了 16,384 块 NVIDIA H100 GPU,耗时 54 天。字节跳动曾使用 12,288 块 GPU 训练了一个 175B 参数的模型。最近,xAI 建立了一个拥有 100,000 块 GPU 的集群以进一步扩大训练规模。
资源规模的扩张也带来了故障的普遍发生(例如 CUDA 错误、NaN 值、任务挂起等),这对训练的稳定性构成了巨大挑战。Meta 曾报告称,在 16,000 块 GPU 上训练大模型时,硬件故障大约每 2.78 小时发生一次。
对于 LLM 训练,当前的故障诊断和处理实践通常依赖于在发生「故障即停止」 (fail-stop) 事件后进行日志分析和退出码评估,或者独占整个集群进行压力测试。一旦确定了根本原因,训练任务会通过重新调度的资源和并行配置来恢复,并从远程文件系统重新加载通常由 TB 级数据组成的检查点 (checkpoints)。这种「故障 - 停止-诊断-恢复」的流程会产生不可忽视的开销,耗时从几小时到几天不等。随着模型和资源规模的扩大,故障频率增加,这极大地限制了有效训练时间比率 (ETTR,即有效训练时间与任务总运行时长的比值)。
因此,任何大规模 LLM 训练基础设施都应致力于实现最小化的训练中断、高效的故障诊断和有效的容错能力,以支持高效率的连续训练。
近日,字节跳动一篇论文介绍了他们 LLM 训练基础设施 ByteRobust,引发广泛关注。现在,在训练基础设施层面上,我们终于知道字节跳动会如何稳健地训练豆包了。

值得注意的是,这项研究共有六位共一作者:Borui Wan、 Gaohong Liu、Zuquan Song、Jun Wang、Yun Zhang、Guangming Sheng。
ByteRobust 是字节跳动基于生产环境中的观察和经验构建的,力求稳健。
其关键目标是:以最小的非生产时间实现高效的事件诊断和处理,即在大规模 LLM 训练中获得高 ETTR。ByteRobust 经过精心设计,用于监控和管理 LLM 训练的全生命周期,以便大规模地自动高效处理训练事件。
ByteRobust 由两个核心组件构成:控制平面 (control plane) 和数据平面 (data plane)。
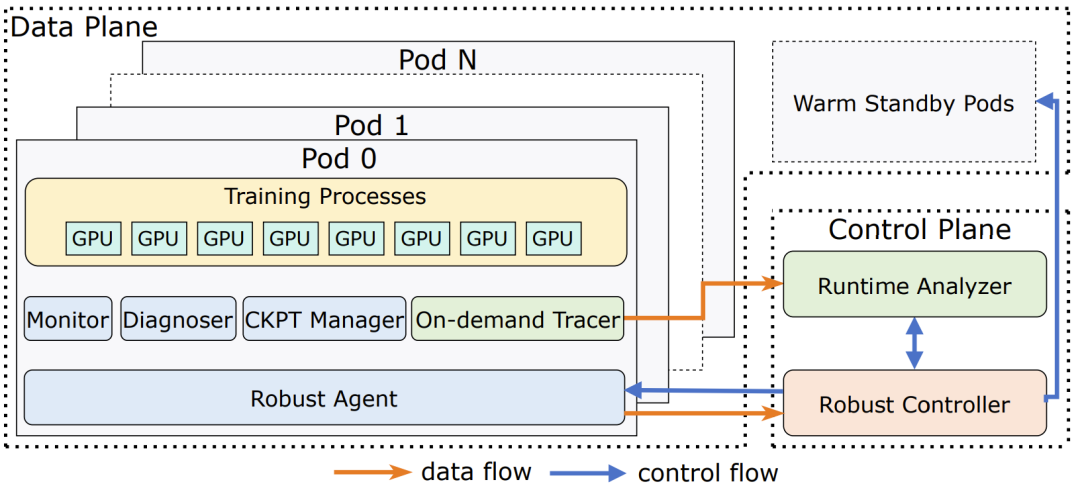
ByteRobust 的架构
控制平面在训练任务外部运行,负责协调稳健的事件处理策略,包括检测异常、定位故障并触发适当的恢复操作。
其中,Robust Controller 负责协调一个自动化的故障缓解框架,利用实时监控和「停止 - 诊断」来处理大多数事件。为了实现可控的快速恢复,当没有机器被驱逐时,它使用一种「原地热更新」机制来重启训练。当决定驱逐某些机器时,它会请求经过自检预验证的「温备用」机器来恢复任务。
Runtime Analyzer 则通过聚合来自训练 Pod 的堆栈跟踪来隔离和(过度)驱逐可疑机器,以解决任务挂起和性能下降问题。
数据平面驻留在每个训练 Pod 内部,集成了监控、诊断、检查点管理和堆栈跟踪捕获等模块,提供实时可观测性、中断时的即时诊断、快速的检查点回滚以及按需的聚合分析。
Robust Agent 守护进程在每个训练 Pod 中运行,处理来自稳健控制器的控制信号,并管理以下四个子模块:
与传统的 GPU 管理和容错系统(通常在 Kubernetes Pod 级别运行)不同,ByteRobust 是将 LLM 训练任务的清单扩展到包含细粒度的进程管理,能够利用运行时信息进行故障检测并实现快速恢复。ByteRobust 通过一套全面的技术实现了这一目标,其新颖的系统设计理念总结如下。
ByteRobust 倾向于快速的故障隔离,而不是详尽的定位。在超大规模的 LLM 训练中(通常涉及数千块 GPU),精确定位故障可能会导致大量 GPU 闲置。
为了最大化 ETTR,字节跳动的做法是将轻量级的实时检测与分层的「停止-诊断」相结合,以最小的开销快速甄别出故障机器。
当这些方法不足以解决问题时,ByteRobust 会应用一种数据驱动的方法,对运行时的堆栈跟踪进行聚类分析,以在定义的故障域(即并行组)内隔离可疑机器,宁可「过度驱逐」它们,也不去追查确切的根本原因。
与标准的深度学习训练任务不同,长达数月的 LLM 训练涉及数据、算法和工程代码的持续更新,这加剧了系统的脆弱性。
认识到人为错误是不可避免的故障来源,字节跳动提出了一个自动化容错框架。
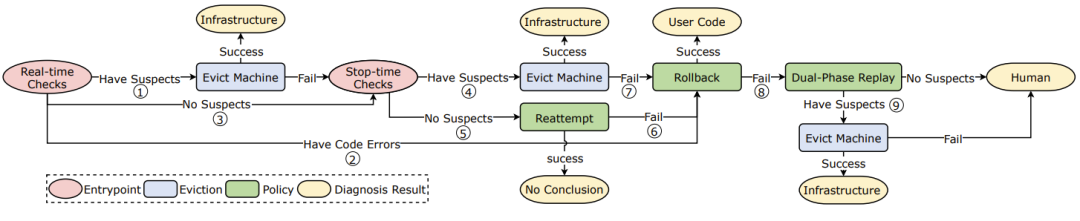
ByteRobust 的自动化容错机制
该框架结合了用于即时检测常见错误的实时检查、用于深入分析复杂故障的「停止-诊断」、用于从瞬时故障中恢复的原地重试、用于从有缺陷的用户代码中恢复的代码回滚,以及用于解决如 SDC 等极端情况的回放测试。
此外,通过一种「延迟更新」的方法,用户代码的变更可以与确定性故障的恢复过程合并,从而利用了故障的必然性和高频率。
故障源于硬件缺陷和软件错误,并且机器在长时间运行的任务中可能会性能退化。因此,在代码升级和恢复过程中确保稳定性至关重要。
对于不改变机器分配的变更,字节跳动使用一种「原地热更新」机制来保留运行时环境并简化诊断。
为确保可控且快速的恢复,ByteRobust 利用预先配置的「温备用」 (warm standbys) 机器,这些机器在交付前会执行自检,以避免整个任务的重新调度。
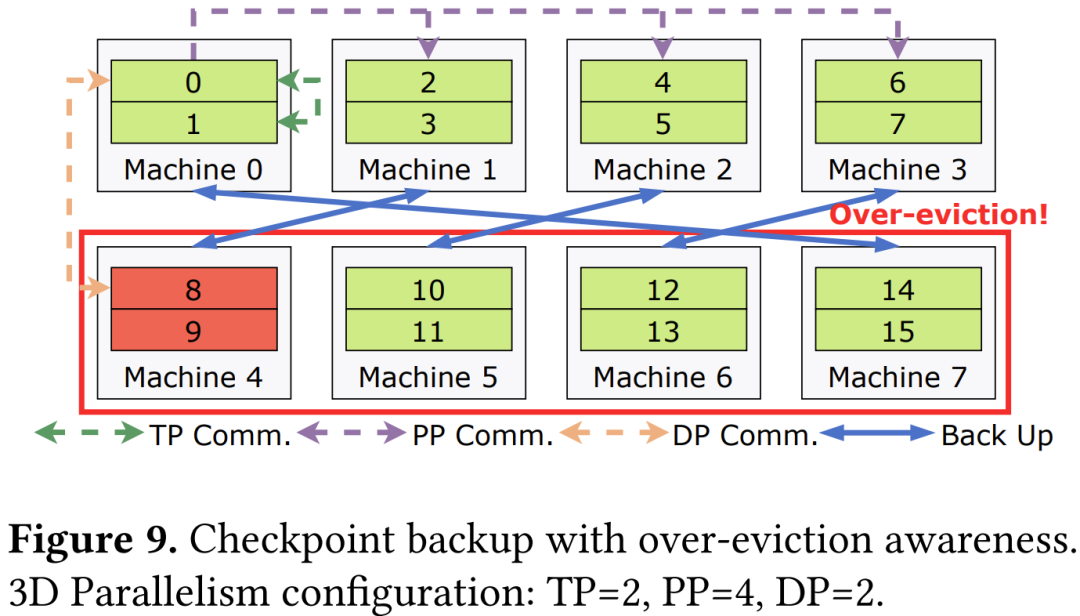
最后,字节跳动的检查点模块通过将备份分布在不同的并行组中(位于任何单个故障域之外),与故障域紧密结合,消除了对远程文件系统的依赖,从而实现快速重启。
字节跳动表示,ByteRobust 已经实现并已实际部署超过一年时间,用于支持字节跳动在高性能生产 GPU 集群中的内部 LLM 训练。字节跳动表示,ByteRobust 可以有效减少事件检测时间,并通过自动容错框架和聚合分析解决事件。
在为期三个月的时间里,ByteRobust 通过其自动化容错训练框架识别了 38,236 次显式故障和 5,948 次隐式故障。
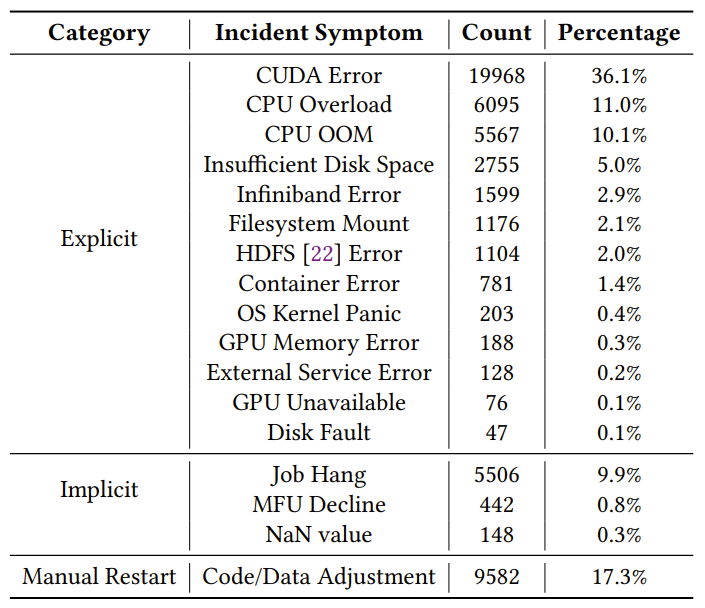
字节跳动在三个月期间收集的训练事故统计数据,涵盖了 778,135 个 LLM 训练任务。
字节跳动在 16,384 块 GPU 上的微基准测试实验表明,温备用和热更新机制在恢复速度上分别实现了高达 10.87 倍和 11.04 倍的提升。
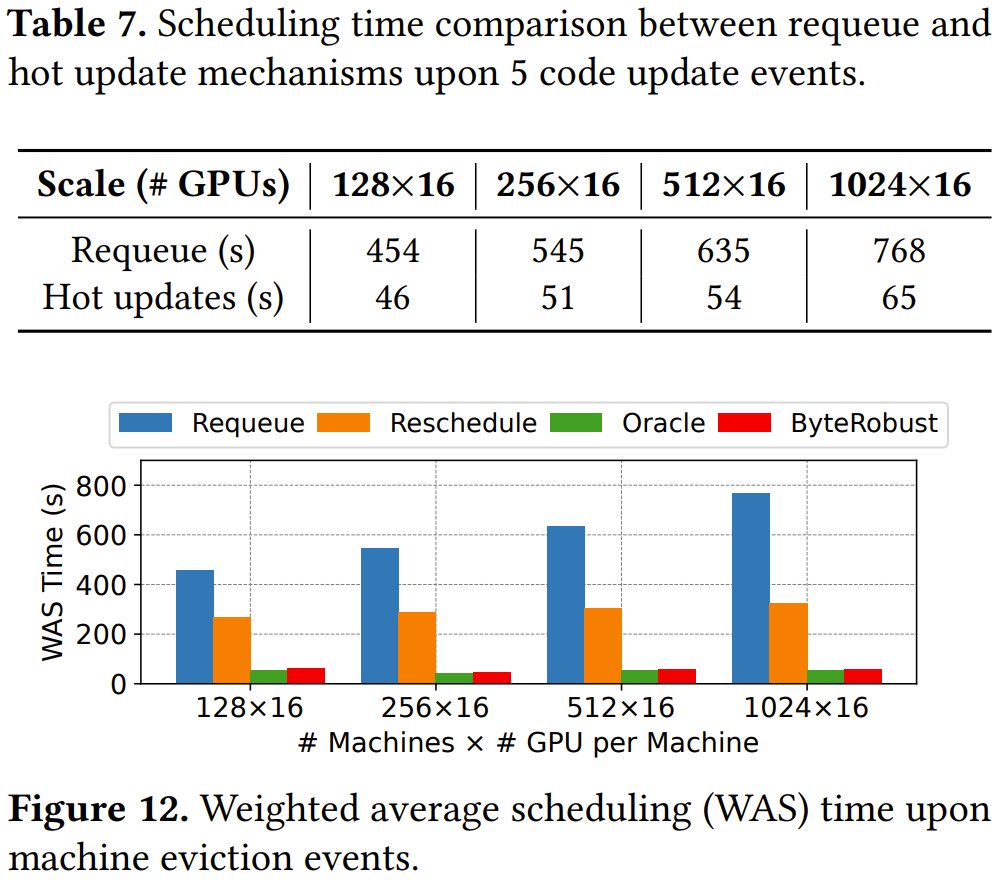
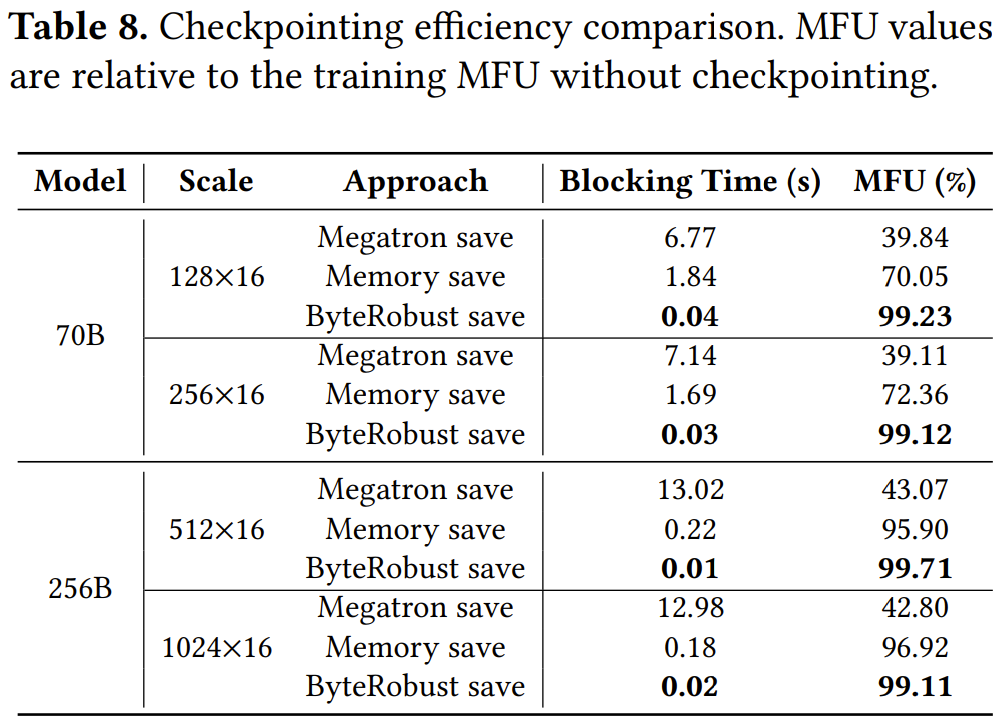
ByteRobust 中高效的检查点机制实现了「每步检查点」(every-step checkpointing),其开销低于 0.9%,从而加速了故障切换。
部署实验表明,在一个为期三个月、使用 9,600 块 GPU 的密集模型(类似 Llama,70B+)训练任务中,ByteRobust 实现了高达 97% 的 ETTR。
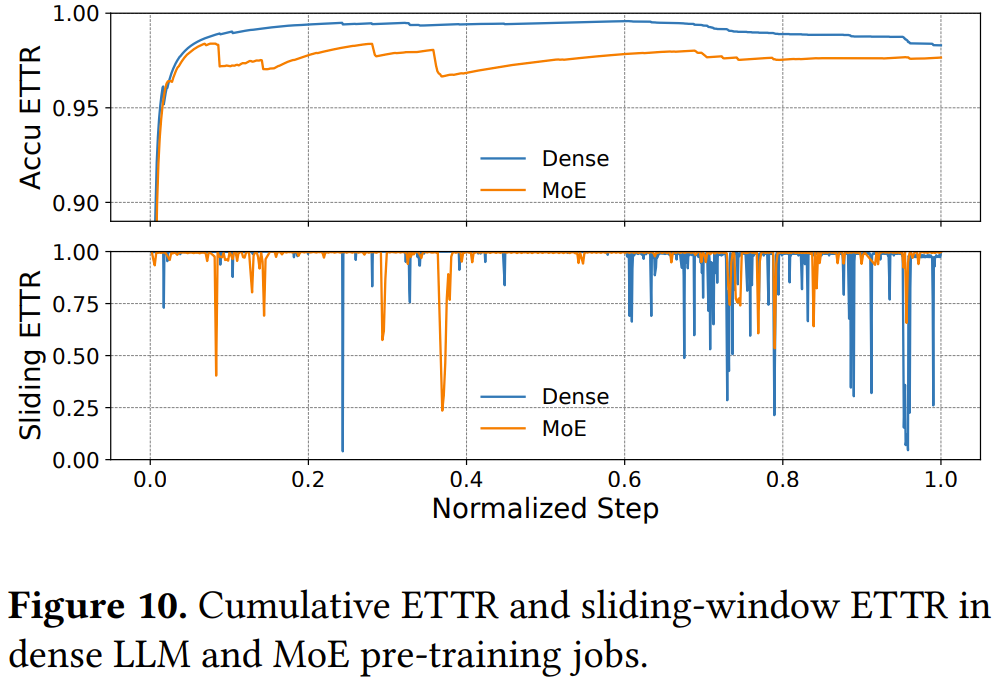
Cumulative ETTR 和 sliding-window ETTR 是字节跳动引入的新指标,其中前者是累积的有效训练时间与任务运行的累积总时长的比率,而后者在一个小时的窗口内计算的 ETTR,能更准确地反映间歇性故障的影响。
另外,他们也进行了一个为期一个月的 MoE 模型(Doubao-1.5-pro,200B+)训练任务,ByteRobust 的表现同样非常不错。
同时,随着训练的进行,两个任务的相对 MFU(Model FLOPs Utilization)持续增长。在训练期间,字节跳动最初在集群上部署了一个朴素版本的预训练代码,然后不断地调整和优化其学习过程和计算效率。
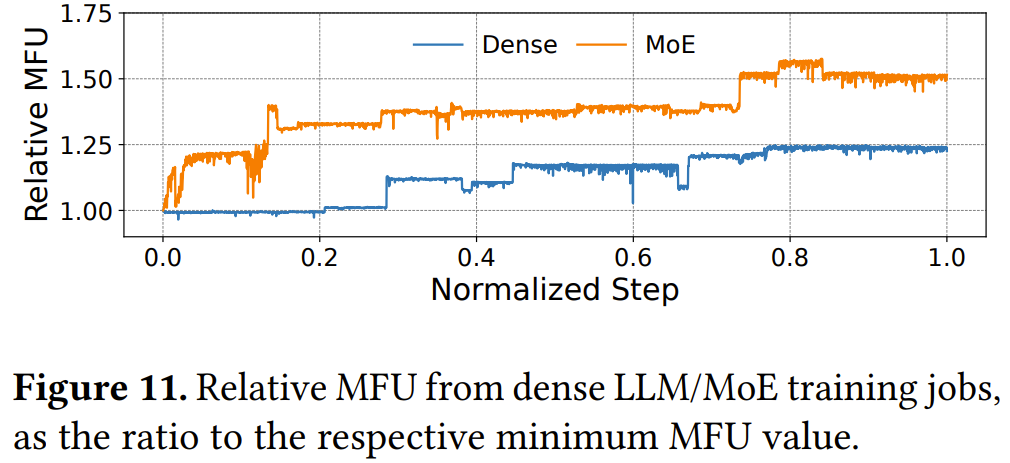
在上图中,MFU 曲线的每一次跃升都表明,一个更高效的训练代码版本通过 ByteRobust 的热更新机制部署了,而这对 ETTR 造成的降低微不足道。与初始运行时相比,字节跳动在密集模型和 MoE 任务中分别实现了 1.25 倍和 1.58 倍的 MFU 提升。
字节跳动还观察到,与密集模型相比,MoE 训练的 ETTR 相对较低。
密集模型的训练性能通常已由社区充分优化,而 MoE 训练则不同,它通常涉及大量自定义优化,如 GPU 内核调优、计算与通信重叠以及负载均衡策略。虽然这些优化对于提高训练效率是必要的,并表现出更高的 MFU,但它们也引入了额外的复杂性,增加了代码回滚和手动重启的可能性。
更多详情请参阅原论文。
文章来自于微信公众号 “机器之心”,作者 “机器之心”


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
