# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI医疗,已不再局限于一时一地的竞赛场,正凝聚为全球共识。
因为,这是一场关乎未来百年,人类生命健康的革命。
不论是谷歌、微软在内的科技巨头,还是硅谷AI初创公司、顶级风投机构,纷纷重仓这一赛道。
就在两天前,成立仅三年的初创OpenEvidence拿下2亿美金新融资。其核心产品「OpenEvidence」深受欢迎,每月处理的临床咨询量高达1650万次。

同一天,Anthropic官宣了「Claude生命科学版」,助力科研人员在生命科学领域的研究。
不仅如此,整个科学界正以前所未有的力度,推进医疗AI的探索——
中国队的力量,同样不容小觑。
今年8月,Baichuan-M2首发后,凭借击败gpt-oss-120b的性能,坐上了开源医疗AI的头把交椅。
时隔两月,Baichuan-M2系列迎来最强迭代。
今天,百川智能重磅发布「首个循证增强的医疗大模型」——Baichuan-M2 Plus。

新模型将「循证医学」理念深度融入训练和推理,通过首创「六源循证范式」,模拟人类医生思维,有效辨别不同层级医学证据、评估其可靠性,并在回答中优先引用高等级证据。
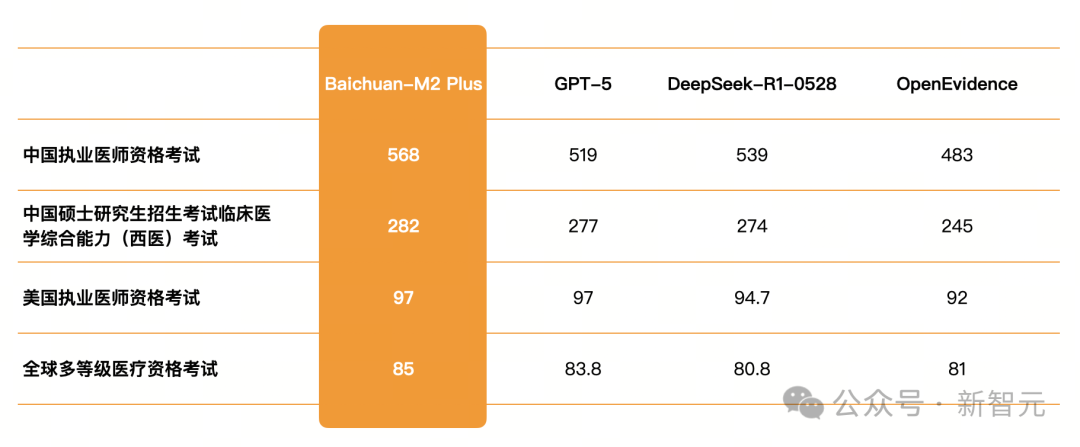
在多项权威医学考试中,M2 Plus成绩直接拉满,医学知识运用能力远超人类平均线。
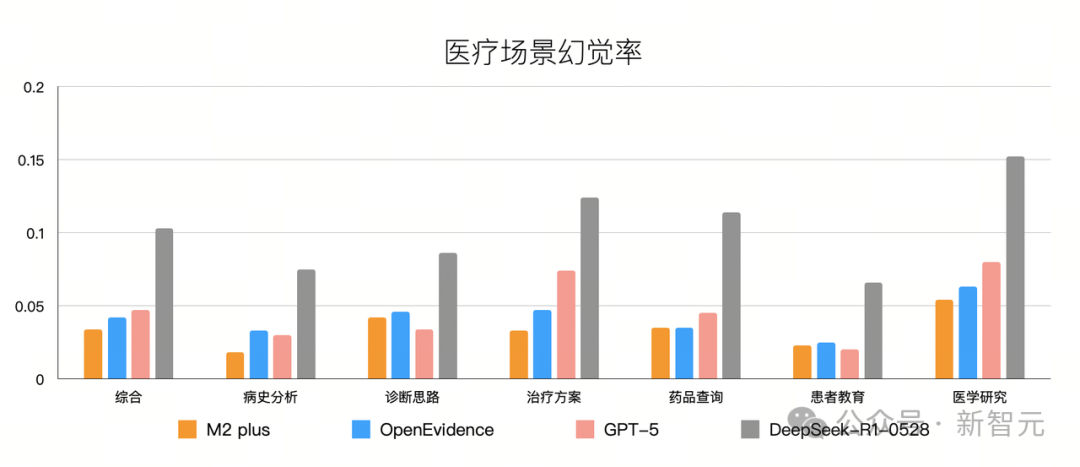
此外,这种「循证驱动」的生成逻辑,使其有效避免了无中生有的幻觉,让可信度比肩资深临床专家的水平。
在多场景医疗评测中,M2 Plus幻觉率指标,较Deepseek-R1低3倍,并且显著领先美国最火医疗产品OpenEvidence。
从今天起,M2 Plus全面上线「百小应」APP,同时开放API接口,所有开发者皆可使用。
是临床「超级外挂」
也是医学科研神器
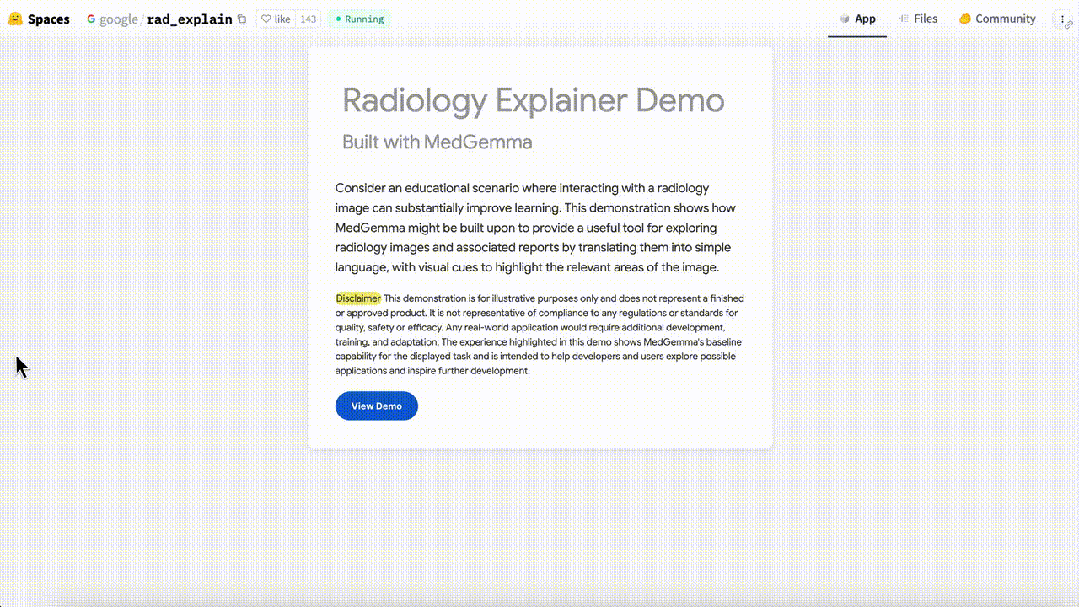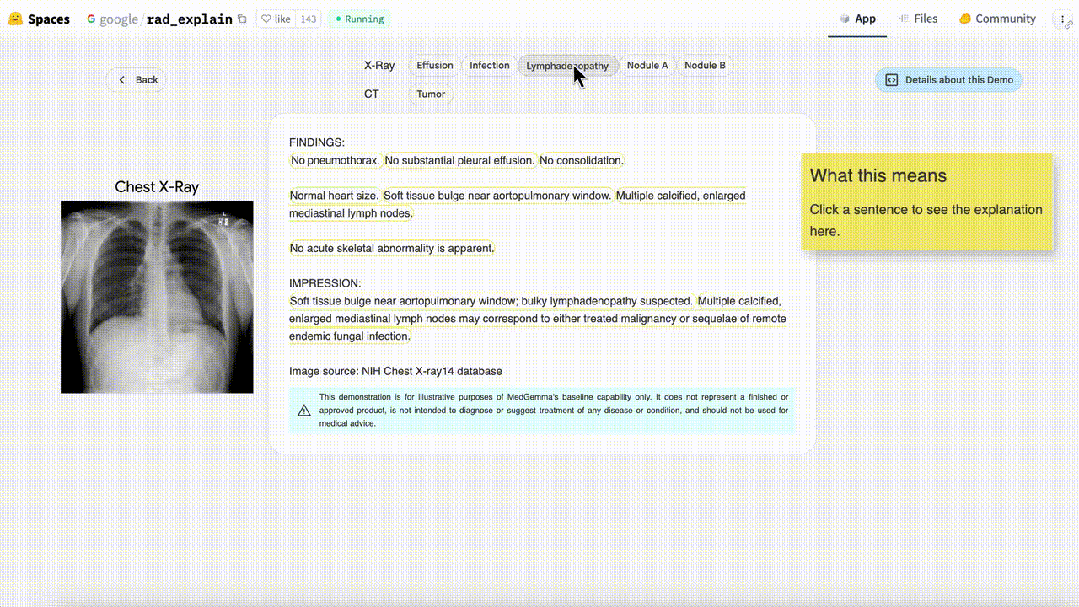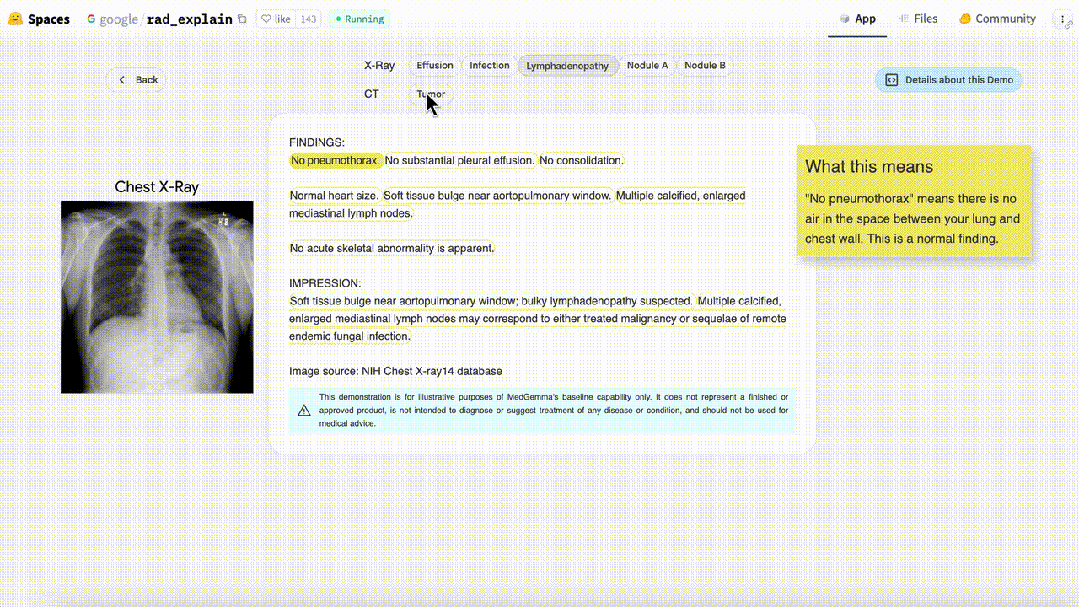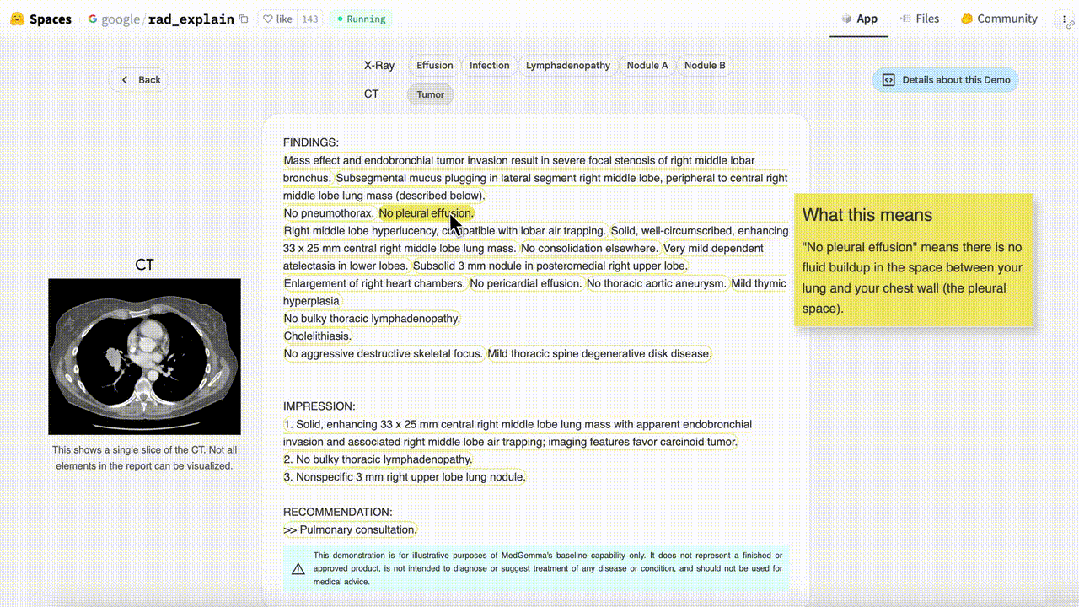
Baichuan-M2 Plus在真实临床场景中表现如何,上手一测便知。
传送门:ying.ai
精准定位靶向药,破译罕见病谜题
举个真实案例,广州医科大学附属第一医院的呼吸科医生遇到一位哮喘患者表现为嗜酸性粒细胞升高、呼出气一氧化氮升高、总IgE升高,并伴有鼻窦炎,吸入治疗效果不佳。
在这种情况下,往往需要考虑「生物靶向」治疗。然而,目前哮喘生物靶向药物种类繁多,比如IgE单抗、IL5/IL5R单抗、IL4R单抗、TSLP单抗。
面对众多选择,如何根据患者的病情,去选择最合适的靶向药物,是临床中的常见挑战。

过去,医生查阅相关临床研究、对比分析,需要耗费大量时间。再加上临床工作繁忙,难以抽出足够时间深入研究文献。
这时候,Baichuan-M2 Plus就派上用场了。
收到医生的问题后,它直接给出了首选和次选推荐,还用表格把每种靶向药的适应症、作用机制列得清清楚楚。

在问答最下方,它还清晰给出了所有引用的链接,方便信息溯源和查证,真正做到了可信。
这位医生对百小应赞叹不已,认为M2 Plus能有效结合患者实际情况,简化靶向药选择过程,足以成为临床工作的小助手。

科研一把抓,最短时间呈递最新科研成果
临床场景之外,Baichuan-M2 Plus在科研上也是一把好手。
比如,作为一名科研工作者或者在读的医学生,想要了解——目前PACAP在偏头痛中的研究进展如何?
在海量文献中,找到真正有价值的,不仅在临床中,甚至在科研中并不容易。
M2 Plus就像一个「文献管家」一样,直接把PACAP与偏头痛领域的动态捋出,省得研究者淹没在PubMed的汪洋里。
如下图所示,不到1分钟,M2 Plus便整合出了不同来源的最新研究结果,还自动按主题聚类与逻辑归纳。
比如,提炼关键临床信息,包括机制、标志物、药物试验结果等等。

这样好处在于,科研人员不用分散精力读取大量文献,直接聚焦核心证据,一看就抓到痛点,避开那些误导性解读。
当他们不再忙于琐碎的文献搜索,就会有更多时间,聚焦在提炼出生物学逻辑与新假设上。
值得一提的是,M2 Plus还能将最新临床试验,如LuAG09222、PAC1抗体研究的结果,与患者特征匹配,给出基于循证医学的治疗建议。
Baichuan-M2 Plus牛就牛在,它让科研者可以用最短时间,找到最有力证据,并为患者做出最科学的决策。
再比如,在肾脏病研究这块儿,尤其是足细胞相关的遗传病治疗,简直就是科研界的「硬骨头」。
对于科研人员来说,需要翻阅一堆文献才能摸清门道。
M2 Plus在很短时间内就能结构化阐述核心关注点,直奔主题并收集呈递最新科研成果。

不得不说,有了M2 Plus,科研苦差就能走上快车道,直奔转化应用,加速从实验室向临床的跳跃。
不论在科研,还是临床中,M2 Plus表现同样惊艳,背后的核心秘诀是什么?
核心技术揭秘
首创「六源循证推理范式」
通用大模型像一个「博学但不可靠」的专家,即便有搜索增强,也会因为知识来源混杂不符合循证医学范式。
为解决这一问题,百川智能结合对循证医学的专业理解,引入了「循证增强」(EAR, Evidence-Agumented Reasoning)技术。
其首创的「六源循证范式」,构建了权威、专业和高可靠度的知识体系,让模型在医疗决策中「有据可依」。
20世纪90年代,加拿大麦克马斯特大学学派革新了医学思想,提出了循证医学(Evidence-Based Medicine, EBM),奠定了现代医学知识体系的核心范式,也是确保医疗决策可信的关键。
遵循这一原则,百川团队提出「六源循证」推理范式,以「证据分层+PICO搜索+动态更新」为核心,让模型能够像医生一样,区分不同层次的医学证据、评估可靠度,并在回答中自动优先引用高等级证据,把循证做「全」、检索做「准」、推理做「对」。
六源证据分层,构建完整医学证据体系
循证医学强调有据可依,而互联网数据鱼龙混杂。
因此,在知识的收集阶段,团队主动屏蔽了互联网的非专业信息来源,只使用权威来源的医学证据。
在此基础上,团队构建了由六层证据类型构成的知识体系,使模型「有据可依」:
· 原始研究层:索引海量医学期刊论文4000万篇,超过PubMed收录数量,涵盖基础与临床研究成果,是循证链条的起点;
· 证据综述层:整合系统评价和Meta分析等高等级证据,提供经过汇总的研究结论;
· 指南规范层:引入国际和国内权威机构发布的临床指南、专家共识和行业标准,确保回答符合最新规范;
· 实践知识层:包含临床病例报道、一线专家经验和诊疗技巧等实用知识,贴近医疗实践场景;
· 公共健康教育层:汇集权威科普和公共卫生知识,如疾病预防宣教、健康指导等内容,服务大众健康教育;
· 监管与真实世界层:涵盖药监部门公告、临床试验登记及大规模真实世界研究数据等信息,以反映最新的监管动态与人群研究结果;

这「六源」,层层演化,实现了从「语言可信度」到「知识可信度」的跃迁:
原始层:回答「事实是否存在」
证据层:回答「结论是否一致」
指南层:回答「行业如何规范」
实践层:回答「医生应如何决策」
公共层:回答「患者应如何理解」
真实世界层:回答「是否存在新风险」
在模型的训练和推理过程中使用六源循证范式,核心解决的是「知识从哪里来问题」。
而如何「快速找到正确证据」?
核心关键——专为医疗设计的PICO检索框架。
循证检索: 三步精准锁定「铁证」
PICO是循证医学常用的检索框架。
PICO框架核心包括四要素:研究人群(Patient)、干预措施(Intervention)、对照(Comparison)和结局(Outcome)。
相较于传统的RAG检索聚焦「找得到」,循证检索则聚焦「找得准」。
为了让大模型真正「能循证」,M2 Plus专门强化了循证医学场景下的搜索能力,使用PICO框架思维,将查询转化为结构化医学问题。具体技术创新包括:
强化学习驱动的多层PICO查询生成:多PICO拆解策略,本质是在语义空间中展开一个「证据采样网络」。
在Baichuan-M2 Plus的查询生成过程中,团队引入强化学习方法进行策略优化。
百川发现,在大量医疗文献学习后,Baichuan-M2已具备基础循证知识,能够进行MeSH、SCR、PT等标准化表述概念的拆解。
因而,团队先使用上下文蒸馏(Context Distillation)和拒绝采样(Reject Sampling),初始化了带有PICOCot能力的策略模型;
随后,为了进一步提升Baichuan-M2 Plus的查询生成能力,团队将多维度循证质量奖励信号和PICO格式信号接入Verifier System进行强化学习训练。
循证质量奖励信号维度:相关性、覆盖面、权威性、时效性的多维度
经过优化后,百川团队发现,M2 Plus不仅能够按PICO原则,抽象复杂用户查询问题,还展现出多查询策略覆盖,精度和覆盖面平衡的效果。
例如,Prompt
GLP-1受体激动剂能否帮助肥胖的2型糖尿病患者减重?
经过模型的结构化理解与检索意图建模,M2 Plus自动将问题分解为多个语义不同但互补的PICO查询。
这种多层PICO查询生成机制让模型在生成查询时不仅关注单一命中率,更实现了语义空间的「密集采样」:
核心查询聚焦精确匹配权威证据,外围查询扩展潜在相关研究,从而在 精度与召回 之间取得动态平衡。
PICO语义感知与精准匹配:
在搜索算法上,百川开发了Medical Contextual Retrieval技术。
不同于传统的通用分片方式,百川利用医学预训练模型自动识别PICO语义边界。
将属于同一临床语境的句段视为一个检索单元,从而保留跨段落的临床因果关系与证据上下文,避免信息割裂。
在检索阶段,系统采用稠密向量检索与短语匹配融合机制:
在精排阶段,百川团队训练了PICO-aware重排序模型,综合考虑:
通过显式加权机制,使得循证等级更高、PICO匹配更完整的文献段落,在排序中优先呈现。
在此基础上,M2 Plus仅需三步精准锁定「铁证」:
第一步,智能提问:自动将用户问题拆解成多个专业的PICO查询,进行「地毯式」证据搜索,兼顾精度与广度;
第二步,精准锁定:通过自研的Medical Contextual Retrieval技术,完整保留文献的临床因果链,避免信息割裂;
第三步,证据排序:内置「审稿人」模型,自动评估证据等级(如RCT、Meta分析),将最可信、最相关的「铁证」优先呈现;
循证推理:让模型学会引用而非臆测
如果说「六源循证」解决了医疗AI知识从哪来的问题,「PICO智能检索」解决了如何快速找到正确证据的问题,那么最关键的一步是如何确保AI在手握证据时,不会「自由发挥」、脱离事实胡乱回答。
百川智能在M2 Plus中引入「循证增强训练」机制,为模型的回答过程「上了一道锁」,从根本上改变了其生成逻辑,让它学会「引用,而非臆测」:
首先,在训练中奖励「引用」,惩罚「臆测」,准确引用权威来源(如指南、文献)时会获得高分,一旦回答脱离了检索到的证据就会受到惩罚;
其次,内置「证据评估器」,模型被训练得能够自动评估检索到的证据质量,优先采纳高可信度的信息(如RCT、Meta分析),并将其无缝嵌入到推理链中;
最后,句句有据,可回溯、可验证:经过训练,M2 Plus的回答风格发生了根本性改变,在输出关键结论时,会自动附上参考文献、指南出处等来源,这赋予了AI回答更高的可解释性与可信赖度。
幻觉率最低,比Deepseek-R1降低3倍
当前的AI模型就像一个知识渊博但有时会凭空想象的学生,其普遍存在的会「一本正经地胡说八道」的问题一直困扰着用户。
这种普遍的「幻觉」问题在医疗和科研等准确性要求极高的领域,尤其无法接受。
百川智能凭借「循证驱动」的生成逻辑,让M2 Plus几乎杜绝了无中生有的内容。
在多场景评测中,其综合幻觉率在所有大模型当中最低,相较 Deepseek R1最新版降低3倍,显著领先OpenEvidence。
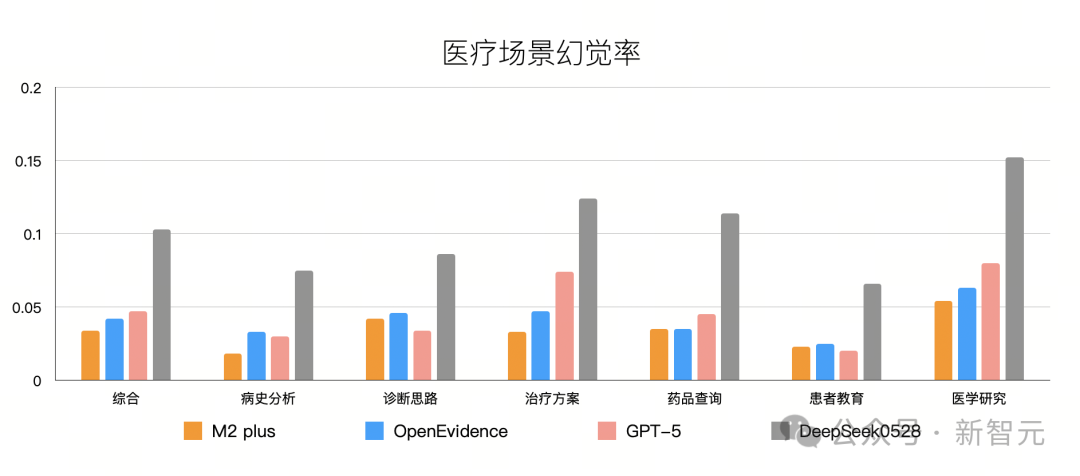
不仅如此,在病史分析、诊断思路、治疗方案等真实复杂的核心医疗场景中,达到了与人类资深临床专家同等的可信度。
北京天坛医院的熊医生便是一个典型的案例,他在研究目前PACAP在偏头痛中的研究进展如何时发现,头痛相关的研究越来越多,想找到真正有价值的文献并不容易,多数大模型给出的答案都因幻觉问题而不可用。
他试用百小应时发现,「这款医疗应用非常专业,能梳理全球PACAP偏头痛研究,从机制到III期临床试验自动串联证据链,不仅回答问题,更让医生站在未来看科研进展。」
多国医考断崖领先
医学能力超越人类医生
「循证增强」代表了未来大模型发展的一个重要方向——从追求「无所不知」到追求「言之有据」,推动AI向更可信、更负责任的阶段迈进。
评测表明,Baichuan-M2 Plus在「循证增强」训练后,其医学知识储备、医学知识利用能力大幅领先人类顶尖医生。
美国执业医师资格考试(USMLE)是评估临床知识和推理能力的黄金标准,即便是经验丰富的临床专家,要突破90分也极具挑战。
在此项考试中,M2 Plus取得了惊人的97分,不仅远超人类考生平均水平,更与GPT-5的成绩持平,稳居全球第一梯队,展示了其世界级的临床问题解决能力。
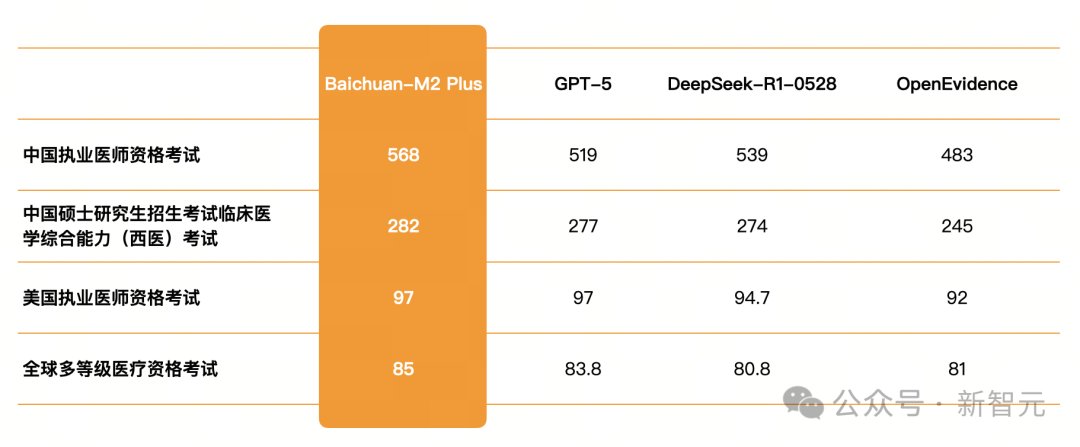
中国执业医师资格考试(NMLE)及格线为360分,对于广大医学生而言,能考到450分以上已是高分,超过500分则被视为「学神」级别。
M2 Plus取得了568分的「碾压级」成绩,在所有公开测试的主流大模型中位列第一,充分证明其对中国临床指南和医疗实践的掌握已炉火纯青。
如果说执医考是「从业门槛」,那么中国硕士研究生招生考试临床医学综合能力(西医)考试则是顶尖医学生竞争的「华山论剑」。
该考试不仅知识面广,且题目设计极为复杂,对临床思维要求高。通常,能考到280分以上的考生,都是协和、北医等顶尖学府的头部学霸。
M2 Plus在此项考试中取得了282分。同时,在日本、英国、澳大利亚等国高级医师职称晋升考试中,准确率85%以上,远超各国及格线。
这些压倒性的成绩充分说明,M2 Plus 在复杂医学知识运用上的能力,已经超越了人类医生水准。
千亿美金赛道,百川再下一棋
Baichuan-M2 Plus的正式发布,再一次成为AI与医疗深度融合的催化剂。
从医生的视角来看,传统医疗中,医生往往针对一位患者的疑难杂症,需要自查文献,耗费大量精力查证。
而随着大模型的普及,医生又有了新的挑战:患者用DeepSeek自诊和带着DeepSeek就医的现象越来越多。
医生虽然知道大模型可能有幻觉和偏颇,但没有时间和精力去甄别哪句对哪句错。
而M2 Plus的「六源循证推理范式」则能实时整合多源权威证据,在短时间内,给到精准的诊疗建议。
目前,百小应已接入最新版本的 Baichuan-M2 Plus 作为核心医疗问答引擎,在各大手机应用商店更新,为方便电脑端使用,其网页版(ying.ai)也同步上线。
它不仅能够成为医生的「专属武器」,也能让患者及家属在希望深入理解诊断、治疗、预后、病因、检查等背后科学逻辑时,便捷的获得最新最权威的知识、顶尖专家的思维和视角和无限耐心的专业解答。
同时,Baichuan-M2 Plus也提供了标准化API接口,医院信息化部门、互联网医疗、大健康服务等各类泛医学机构,以及从事医疗AI行业的开发者,则可以通过API将循证推理接入服务场景,提升AI服务的医学专业性。
M2 Plus的上线,标志着医疗大模型正从「答得快」迈向「答得对、有依据」可信可用的新阶段。
文章来自于微信公众号 “新智元”,作者 “新智元”


【开源免费】MONAI是一个专注于医疗影像分析的深度学习框架,它可以让医院高效、准确地从医疗影像数据中提取有价值的信息,以辅助医生进行诊断和治疗。
项目地址:https://github.com/Project-MONAI/MONAI?tab=readme-ov-file
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
