# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在最近一篇来自Meta FAIR团队的论文里,研究者找到了一种前所未有的方式——他们能实时看到AI的思考过程。这项名为CRV的方法,通过替换模型内部的MLP模块,让每一步推理都变得「可见」。这不是隐喻,而是可量化的现象。Meta用它让错误检测精度提升到92.47%,也让人类第一次得以窥见AI是怎么想错的。
「Meta刚刚找到一种方法,可以实时观察AI的思维过程崩溃。」
一条看似寻常的推文,在AI圈炸开了锅。

发帖人是研究员@JacksonAtkinsX,他称Meta的新技术能让机器的思维「透明化」——不仅能看到模型在想什么,还能看见它在哪一步彻底「想错」。
在Meta FAIR团队刚发布的论文中,这项被称为CRV(Circuit-based Reasoning Verification)的新方法,就像一台「AI脑部X光机」:
它能追踪语言模型的每一次推理、记录每一条电流路径,甚至捕捉到思维崩溃的瞬间。

论文链接:https://arxiv.org/abs/2510.09312?utm_source
当屏幕上那张电路图突然从整洁的网状,变成混乱的线团——研究者第一次,看见了AI的思维是怎么崩溃的。
Meta刚刚找到一种方法,可以实时观察AI的思维过程崩溃。
当研究员Jackson Atkins发出这条推文时,AI社区瞬间沸腾了
乍一听像科幻小说的桥段。AI在思考的时候忽然断链、炸裂,而研究者却说能直接看到那一刻。
但这不是夸张。在Meta FAIR团队刚发表的论文 《Verifying Chain-of-Thought Reasoning via Its Computational Graph》 中,他们提出了一种新方法:CRV(Circuit-based Reasoning Verification)。
这项技术能让研究者在模型「思考」的过程中,看到它的推理电路。
当模型推理正确时,它的「内部电路图」干净、有条理;一旦模型犯错,电路图立刻变得纠缠、杂乱。
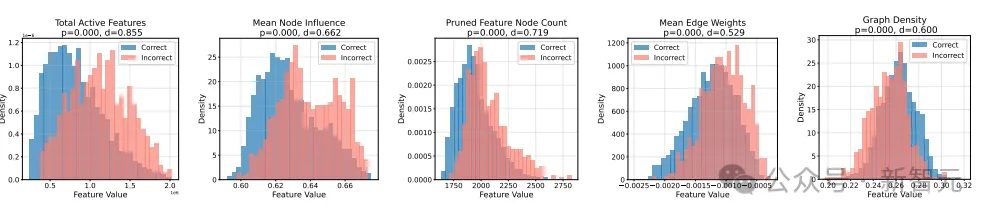
推理指纹特征对比图。错误推理在这些特征上普遍更加分散、混乱。
研究团队将这种电路结构称为模型的「推理指纹(reasoning fingerprint)」。
他们发现,错误并不是随机的,而是有形、有迹可循:只要读取这张「电路指纹图」,就能预测模型是否即将犯错。
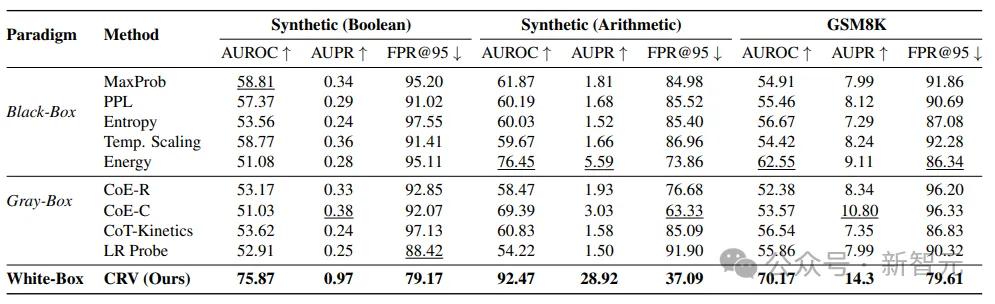
在算术推理实验中,CRV 的检测精度(AUROC)从76.45提升至92.47,误报率从63.33%降至37.09%。
更令人震撼的是,当研究者关闭一个错误激活的乘法特征神经元后,模型立即修正了计算。

例如在表达式 (7 × ((5 + 9) + 7)) 中,模型原本输出105,干预后改为147——完全正确。
错误推理并非随机,而是电路执行过程中的结构性失败。
Meta FAIR的研究者用一句话概括他们的目标:要让AI不仅能「给出答案」,更能「证明自己想得对」。
要想让AI的思维过程变得「可见」,Meta做了一件几乎颠覆常识的事:他们重新改造了语言模型的大脑结构。
这项被命名为CRV(Circuit-based Reasoning Verification)的方法,核心思想不是提升模型性能,而是让AI的每一步推理都能被验证、被追踪。
我们的目标不是让模型更聪明,而是让它的思考过程本身变得可验证。
AI的大脑不再是黑盒:每个「神经元」都能被看见
研究团队首先将模型中的传统MLP模块替换为一种可解释的稀疏结构——Transcoder层。
在不同层将MLP替换为Transcoder后,模型的损失值在短时间内迅速下降并趋于稳定。
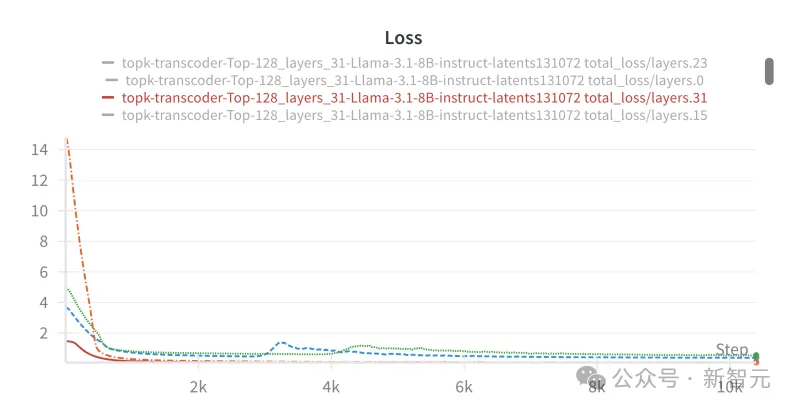
Transcoder层的训练稳定性证明。CRV 不是理论概念,而是可以在大模型上稳定运行的真实工程结构。
每个Transcoder都像一组带标签的神经元,能代表特定的语义特征,例如「加法」「乘法」「括号」或「进位」。
这样一来,研究者就能在推理过程中,看到哪些神经元被激活、何时点亮、如何传递。
论文把这一步称为「X-Ray」,即为模型安装一层「透视皮肤」。
研究者形容它像「在黑箱里装上摄像机」:每一层的计算过程不再是难以解读的向量,而是清晰的电路信号。
AI的思维可以画出来:Meta让推理变成一张电路图
当模型执行一步推理时,系统会绘制出一张归因图(Attribution Graph),节点代表被激活的特征,边表示它们之间的信息流动。
每一次逻辑跳转、每一个概念结合,都会在图上留下痕迹。
这张图不是静态的,而是随推理动态变化的「思维轨迹」。
当模型看到「3+5=」时,研究者可以实时看到「加法特征」从底层被点亮、信息如何层层汇聚到输出。
而当模型出错时,路径就会打结、分叉、环绕——像一条错乱的神经信号。
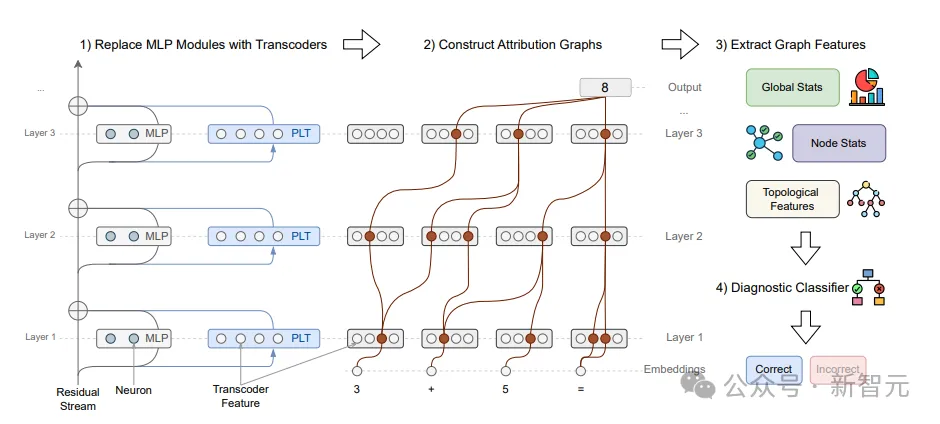
CRV 方法流程示意图中展示了从「替换MLP模块」、构建归因图、提取结构特征,到最后交由诊断分类器判定「正确/错误」的全过程。
让AI自己暴露错误:Meta发现「思维崩溃」的指纹
当思维电路图生成后,Meta提取了大量结构特征:节点数量、图密度、平均边权、路径长度、中心性……
这些数据构成了模型的「思维指纹」。
接着,他们训练了一个分类器——它不读文字,也不看答案,只看结构。在实验中,研究者发现:
当图结构纠缠、分布混乱时,模型几乎一定在推理出错。
也就是说,模型是否思考正确,不必等它说完答案,只要观察那张「电路图」的形态,就能提前判断。
CRV的出现,让语言模型第一次拥有了「可诊断的神经结构」。
Meta并没有让AI更聪明,而是让人类第一次能看见AI是如何出错的。
黑箱不再完全密封,智能第一次露出了自己的「电路断层」。
在Meta公布实验结果后,最直观的震撼来自这组对比图:
CRV与多种验证方法的性能对比。图中展示了不同方法在算术推理任务下的检测表现。
红线代表 CRV,无论是在AUROC(检测精度)、AUPR(正确预测率) 还是FPR@95(误报率)上,都远高于或低于其他方法。
这意味着它不仅能看见推理电路的结构,更能精准判断模型是否会想错。
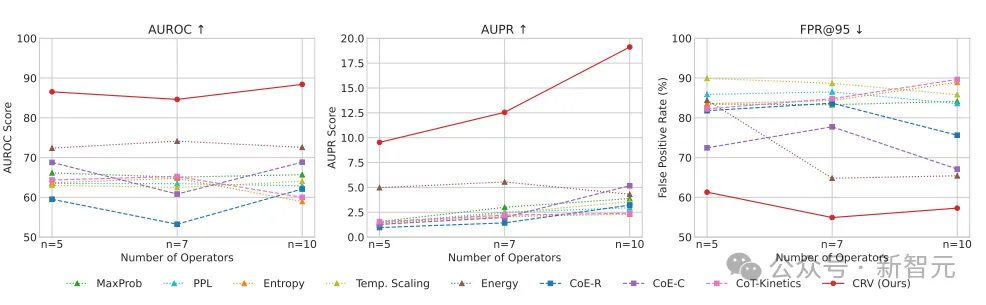
这样的结果让许多研究者意识到:CRV不只是一次模型改造,而是一次观念的翻转。
过去,我们判断一个模型是否推理正确,只能看它的答案。
它写出一段chain-of-thought,人类再去揣测逻辑是不是连贯,结论是不是对的。
这一切都发生在黑箱之外——我们只能看到输出,却无法追踪「它是怎么想的」。
而Meta的CRV,把这条思维链第一次摊在显微镜下。研究者不再靠猜,而是能直接看到模型内部的逻辑路径:
每一次特征被点亮,每一条信号被传递,都能在图上找到对应的「电路」。
他们不是在评估答案,而是在验证思维的结构本身。

更重要的是,CRV让「可解释性」和「可靠性」第一次真正接上了。
在过去的研究里,前者关注看懂模型,后者追求信得过模型,两条路几乎平行——我们能看到热力图,却依然不知道为什么模型会错。
而在Meta的实验中,研究者既能解释模型为什么出错,也能预测下一步它可能在哪出错。
CRV也许是通向「可控智能」的第一步。当推理错误能被结构化地识别,就意味着它可以被预测、干预,甚至被修复。
论文中有一个著名的例子——关闭一个错误激活的神经特征后,模型立刻修正答案。
这说明错误并非偶然,而是电路级的故障。如果未来能实时监测这些特征,我们或许能在幻觉发生前按下「刹车」。
从这一刻起,AI的错误不再是神秘的灵异事件。它们是有形的、可诊断的。
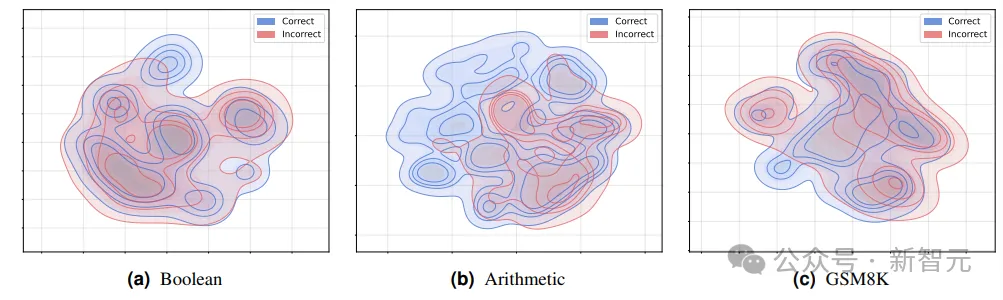
不同任务中正确与错误推理的拓扑特征分布。图中蓝色表示正确推理,红色表示错误推理。
Meta把黑箱的盖子掀开了一条缝——让人类第一次有机会,不只是造出智能,而是看懂智能本身。
就算Meta已经能「看见AI在想什么」,这项技术距离真正落地,仍有一段漫长的路要走。
在论文结尾部分,研究团队自己就坦率地写下了「局限与未竟之处」。
我们的方法目前需要大量计算资源,因为必须将所有MLP层替换为Transcoder层,并计算完整的归因图。
也就是说,要让模型变得可见,代价是巨大的:每一层都要被重建,每一个特征都要被追踪。
光是绘制一次完整的归因图,就可能消耗掉普通训练的数十倍算力。这不是能随意做出的功能,而是需要投入巨大的工程。

更现实的问题是——规模。
实验仅在最大8B参数规模的模型上进行,将其扩展到更大模型仍需后续研究。
CRV目前只在中等体量的模型上被验证,而如今主流的大语言模型动辄上百亿、甚至上千亿参数,要让整个推理电路都能被看见,几乎不可能在短期内完成。
更棘手的是泛化问题。
CRV在算术任务上表现亮眼,但一旦换到自然语言推理、常识问答、代码生成这类复杂任务时,归因图结构的规律会完全不同,错误特征不再稳定,诊断效果明显下降。
最后,Meta团队也提醒读者:
Transcoder架构只是原始MLP的一种近似,并非完美替代。
这意味着,研究者看到的那些「电路轨迹」,其实是经过重新投影后的近似结构。
Meta的CRV不是让机器更聪明,而是让人类第一次得以窥见智能的内部结构。
那些曾被称为「幻觉」的错误、不确定的跳跃、莫名的偏差,如今都能被描摹成一张电路图,被一点点拆解、理解、修复。
或许距离真正「可靠」的AI还很远,但这一步已经改变了方向。
人类不再只是 AI 的使用者,而是它的读者、医生,也是见证者。
当机器的思维第一次被照亮,这束光也照进了我们自己的认知——照见了我们对智能的渴望、恐惧,以及那句始终悬在科学尽头的问题:
我们究竟是在教会机器思考,还是在学会看懂自己?
参考资料:
https://x.com/JacksonAtkinsX/status/1977721832909177032
https://arxiv.org/abs/2510.09312?utm_source=chatgpt.com
文章来自于“新智元”,作者“倾倾”。


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
