# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型后训练的痛点:均值优化忽略低概率高信息路径,导致推理能力停滞。RiskPO双管齐下,MVaR目标函数推导梯度估计,多问题捆绑转化反馈,实验中Geo3K准确率54.5%,LiveCodeBench Pass@1提升1%,泛化能力强悍。
当强化学习(RL)成为大模型后训练的核心工具,「带可验证奖励的强化学习(RLVR)」凭借客观的二元反馈(如解题对错),迅速成为提升推理能力的主流范式。
从数学解题到代码生成,RLVR本应推动模型突破「已知答案采样」的局限,真正掌握深度推理逻辑——
但现实是,以GRPO为代表的主流方法正陷入「均值优化陷阱」。
这些基于均值的优化策略,过度聚焦高概率输出序列,却忽略了「低概率但高信息密度」的推理路径:
模型训练早期就会出现熵坍缩,过早丧失探索能力;
面对全错的难题时,优势函数直接归零,模型在薄弱环节完全无法学习。
最终结果是,大模型看似在Pass@1等短视指标上有提升,实则推理边界从未拓宽,更无法应对AIME竞赛题、复杂代码生成这类高难度任务。
如何让模型主动「啃硬骨头」,成为大模型后训练的关键瓶颈。
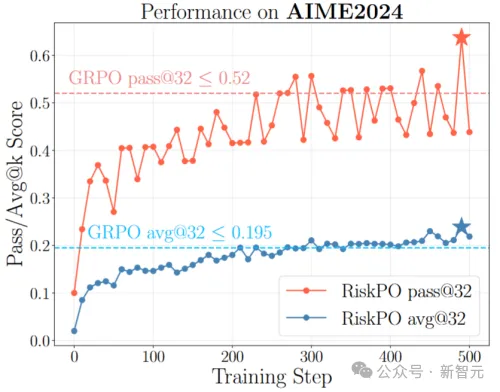
AIME2024上的学习表现
为解决传统均值优化的缺陷,北大团队提出的RiskPO,核心突破在于将风险规避(risk-averse)理念融入优化目标,用「关注奖励分布左尾(难任务)」替代「追求整体均值」,从根本上引导模型突破推理短板。

论文链接:https://arxiv.org/abs/2510.00911v1
代码链接:https://github.com/RTkenny/RiskPO
单位:由北京大学彭一杰教授课题组完成
作者:第一作者为任韬,共一作者为江金阳,其他作者包括杨晖等。
这一思路的核心载体是「混合风险价值(MVaR)」目标函数。

为配合MVaR目标,团队提出「多问题捆绑」策略,将多个问题打包成bundle计算奖励,把稀疏的二进制反馈转化为更丰富的分布信号,彻底解决「难题零梯度」问题——比如将5个数学题打包后,模型能从整体得分中捕捉到「部分正确」的学习信号,而非单个题目非对即错的极端反馈。
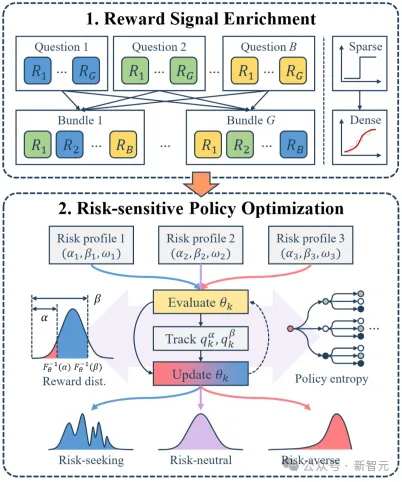
算法架构图
好的技术方案,终要靠硬指标说话。
北大团队在数学推理、代码生成、多模态推理三大领域的10余个数据集上,用数据证明了RiskPO的突破性——
尤其在最能体现推理能力的「硬任务」上,优势远超GRPO及其变体。
在数学推理领域,RiskPO在AIME24(美国数学邀请赛)任务上表现惊艳:
Pass@32得分比GRPO高出近7个百分点,比最强基线DAPO提升6.7个百分点;
即便是相对简单的MATH500数据集,其Pass@1也达到81.8%,超出GRPO2.6个百分点。
更关键的是,随着评估指标从Pass@1转向Pass@8、Pass@16,RiskPO的优势持续扩大——
这意味着模型不仅能给出更优的单条答案,还能探索更多有效推理路径,真正突破了「采样效率优化」的局限。
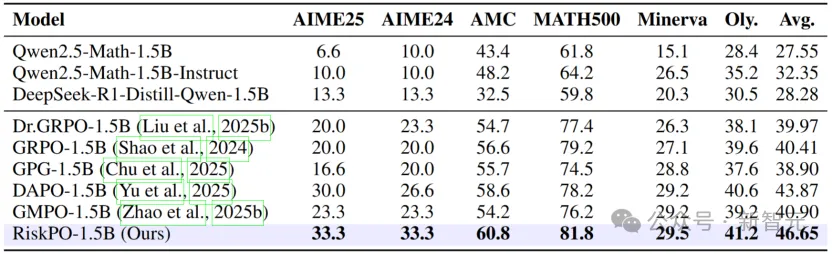
数学推理任务
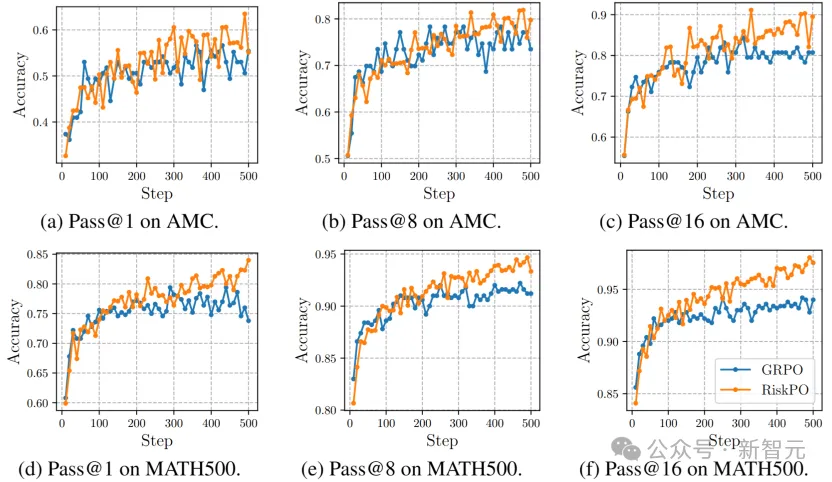
Pass@k学习曲线
在跨领域任务中,RiskPO同样稳定领先:代码生成任务LiveCodeBench上,Pass@1比GRPO提升1个百分点;多模态几何推理任务Geo3K上,准确率达到54.5%,优于DAPO的54.3%。这种「全场景增益」,证明了风险度量优化的泛化能力。
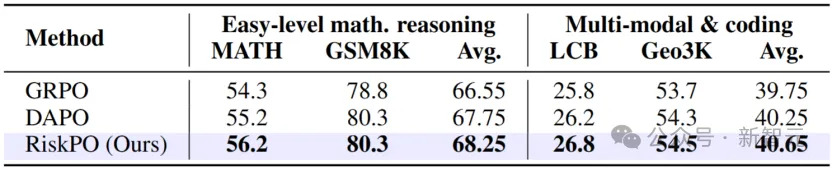
其他任务
RiskPO的性能突破,并非依赖工程调参,而是有扎实的理论支撑和严谨的消融实验验证。
高熵更新定理:
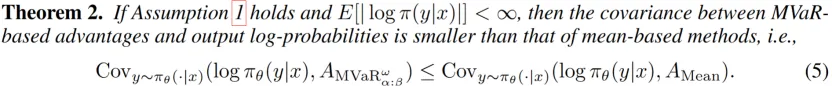
从理论层面,团队证明了「风险规避更新」能有效缓解熵坍缩:通过分析策略熵的变化机制,发现RiskPO的MVaR目标函数能降低「优势-对数概率」的相关性——相比GRPO,模型不会过度强化已掌握的易任务,从而保持更高的熵值和探索能力。实验中也能清晰看到:训练500步后,GRPO的熵值已趋近于0,而RiskPO仍能维持0.2以上的熵水平,确保对难任务的持续探索。
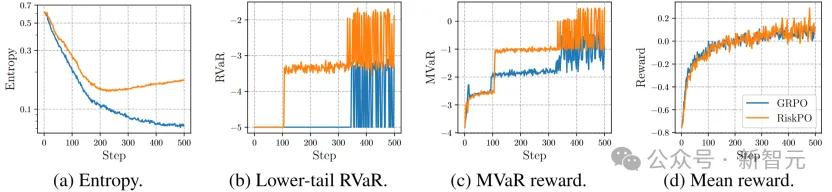
训练集DAPOMATH-17k上的各项指标
值得注意的是,在训练过程中,若仅观察以均值为核心的指标曲线(如平均奖励),GRPO与RiskPO的表现几乎难分伯仲,甚至RiskPO因更高的探索性还伴随轻微波动;但切换到风险敏感指标(如下尾RVaR、MVaR奖励)时,两者差距立刻凸显——RiskPO的曲线始终保持显著领先,且随训练推进持续攀升。
这种「均值相近、风险指标悬殊」的现象,再结合最终测试集上RiskPO在Pass@k(尤其是高k值)、难任务(如AIME竞赛题)上的优势,进一步印证了:均值目标只能让模型在「已知能力范围内优化采样效率」,而风险度量目标才是推动模型突破推理边界、真正提升核心能力的理想方向。
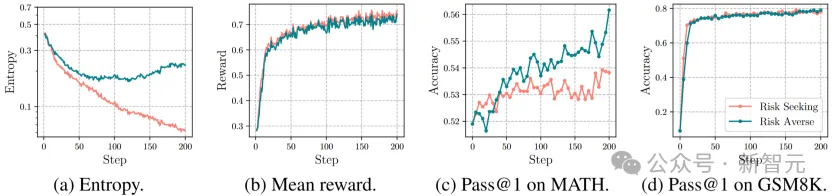
不同风险偏好对比实验
为进一步验证风险规避目标的必要性,团队还设计了「风险寻求(risk-seeking)」对比实验:采用与MVaR结构对称的风险寻求目标,即
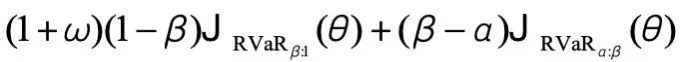
重点关注奖励分布的右尾(易任务)。结果显示,风险寻求模型的熵值在训练早期就剧烈坍缩——训练150步后熵值已降至0.1以下,远低于RiskPO的0.2;性能上,风险寻求模型在训练50步后便进入平台期,MATH数据集Pass@1仅从52%提升至54%,而RiskPO则持续优化至56%,实现1.5倍的提升幅度。
这一对比清晰证明,聚焦易任务的风险寻求策略会加速模型「固步自封」,只有风险规避才能驱动模型突破推理边界。
参考资料:
https://arxiv.org/abs/2510.00911v1
文章来自于微信公众号“新智元”。



