# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
入坑机器人的春天来了。
众所周知,机器人学本质上是一个多学科交叉的领域,自 20 世纪 60 年代诞生以来,已经取得了前所未有的进步。
尤其是在大模型诞生,多模态大模型等人工智能技术蓬勃发展的当下,机器人领域与过去经典机器人学产生了重大的变化,机器人学习成为了现代机器人学的中流砥柱。
随着机器学习和多模态模型的迅速发展以及大规模机器人数据的拓展,机器人学习逐步转向了基于学习的范式,强化学习、模仿学习,以及研究热门的 VLA 模型,都正在为自主决策的机器人开辟全新的潜力。
值得庆幸的是,HuggingFace 与牛津大学的研究者们为想要进入现代机器人学习领域的新人们提供了了一份极其全面易懂的技术教程。

这份教程将带领读者探索现代机器人学习的全景,从强化学习和模仿学习的基础原理出发,逐步走向能够在多种任务甚至不同机器人形态下运行的通用型、语言条件模型。

更良心的是,这份教程还额外附带了机器人领域的基于 PyTorch 的开源数据集、模型、工具和代码库 LeRobot,收录了许多当前的 SOTA 方法,这些方法已经在模仿学习和强化学习方向上展示了良好的真实机器人迁移能力。
目前,LeRobot 已经提供了一系列预训练模型、包含人工采集示范的数据集,以及模拟环境,用户无需搭建实体机器人就可以开始上手。
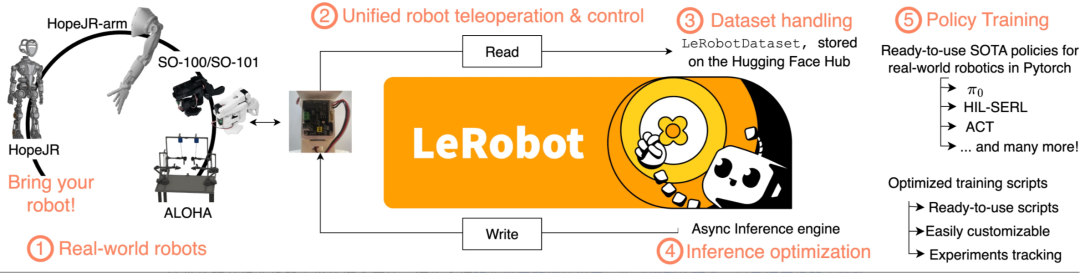
LeRobot 是由 Hugging Face 开发的开源端到端机器人库。该库在整个机器人栈上垂直整合,支持对真实世界机器人设备的低级控制、高级数据和推理优化,以及具有纯 Pytorch 简单实现的 SOTA 机器人学习方法。
这份教程从经典机器人学的概念开始,逐步介绍强化学习和模仿学习,生成模型的理念,以及通用机器人策略。
「技多不压身」,该教程是成为踏入机器人学习领域的一份有价值的起点。
我们将简单介绍一下这份教程涉及的基本内容:
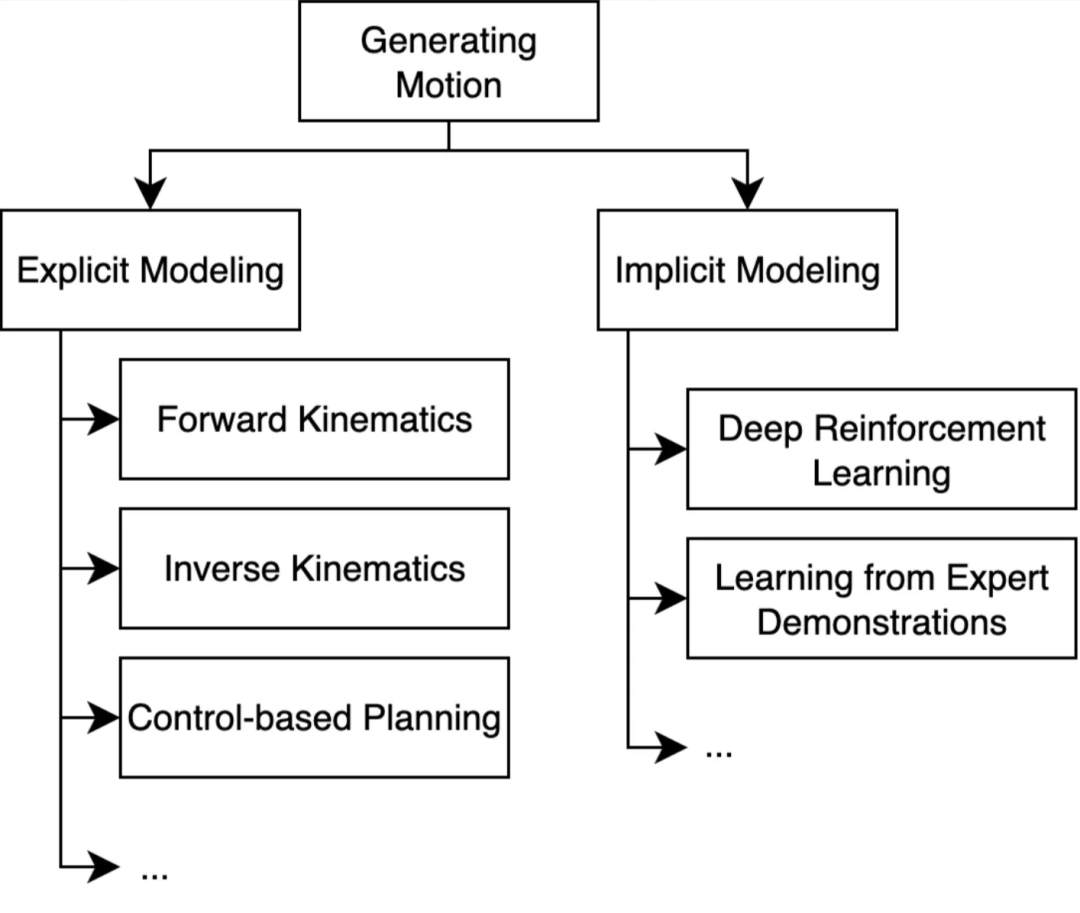
从显式建模到隐式建模的演化,标志着机器人运动生成方式的一次根本性变革。传统机器人技术依赖显式建模,通过正向运动学、逆向运动学以及基于控制的规划来生成动作;而基于学习的方法则通过深度强化学习和专家示范学习,实现了隐式建模。
经典的机器人系统通常遵循一个模块化流水线:感知模块处理原始传感器数据,状态估计模块确定机器人的当前状态,规划模块生成运动轨迹,控制模块则负责执行这些轨迹。
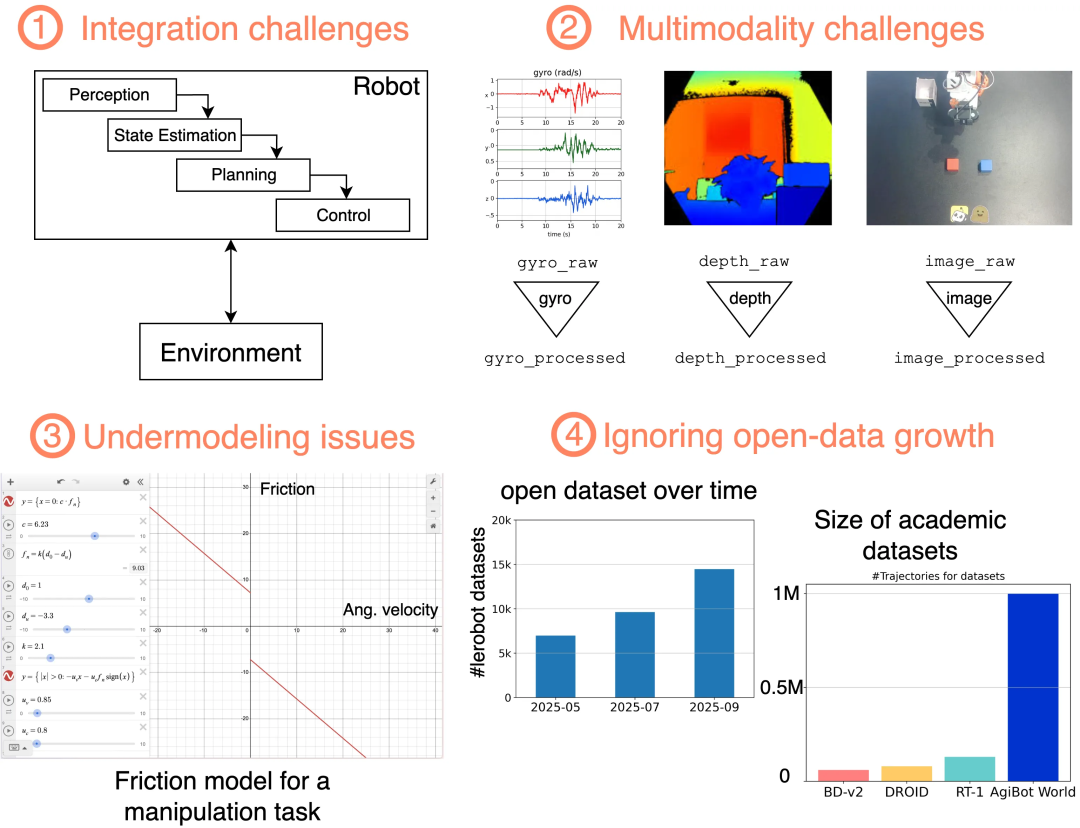
基于动力学的机器人方法存在多方面的局限:
综合来看,这些限制促使人们探索基于学习的方法,这些方法能够(1)更紧密地整合感知和控制,(2)在任务和本体之间进行适应,同时减少专家建模干预,以及(3)随着更多机器人数据的可用性,在性能上扩展。
强化学习通过试错法让机器人自主学习最优行为策略,在许多场景下展现了巨大潜力。
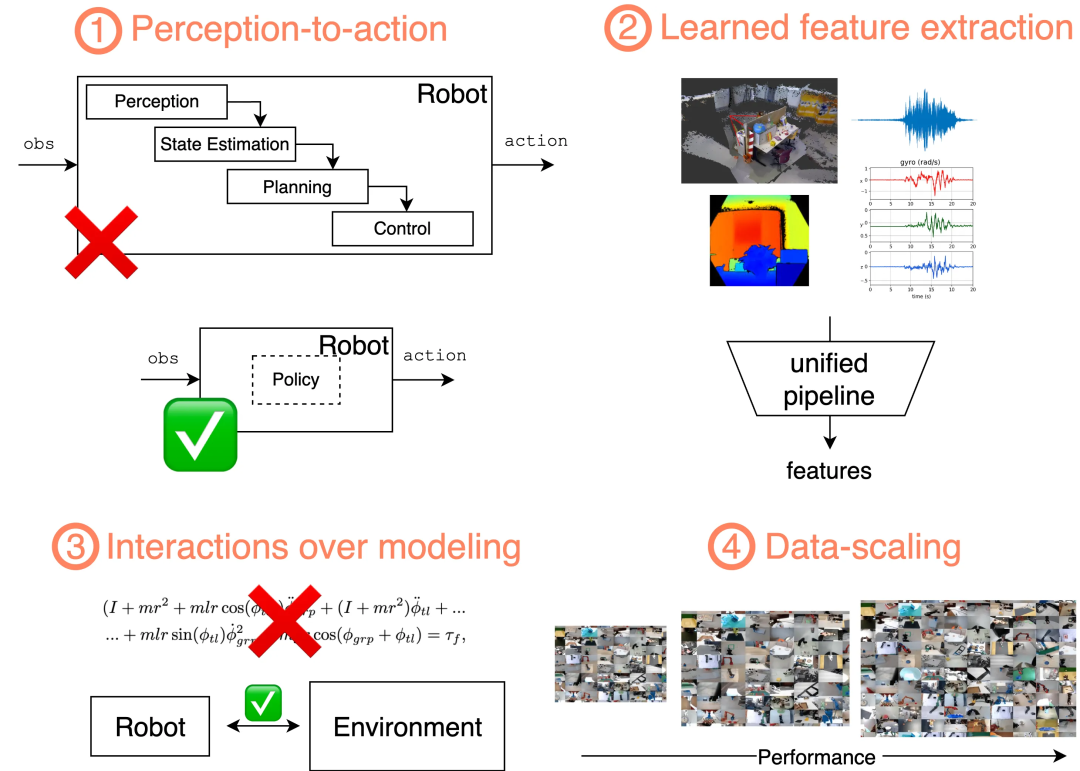
基于学习的机器人学通过训练一个(1)统一的高层控制器,能够直接处理(2)高维、非结构化的感知 - 运动信息,从而简化从感知到动作的过程。学习过程(3)无需动力学模型,而是聚焦于交互数据,并且(4)其效果与所用数据的规模呈经验性正相关。
然而,该教程也明确指出了其在现实世界中面临的瓶颈:一是安全与效率问题,尤其是在训练初期,机器人可能因探索性动作造成硬件损伤;二是高昂的试错成本,尤其是在真实物理环境中。
为解决这些问题,教程介绍了一系列前沿技术,例如通过模拟器训练来规避物理风险,并利用「域随机化」技术来缩小模拟与现实之间的差距。

同一运动任务可在训练阶段于不同(仿真)域中执行(以地形差异为例),从而提升对多样化环境动态的鲁棒性。
此外,教程还重点介绍了「离线到在线」(Offline-to-Online)强化学习框架,该框架利用预先收集的专家数据来引导学习过程,显著提升了样本效率和安全性。
其中,HIL-SERL(Human-in-the-Loop, Sample-Efficient Robot Reinforcement Learning)方法作为典型案例被详细阐述,该方法通过在训练中引入人类监督和干预,使得机器人在短短 1-2 小时内就能掌握复杂的真实世界操作任务,成功率接近 100%。
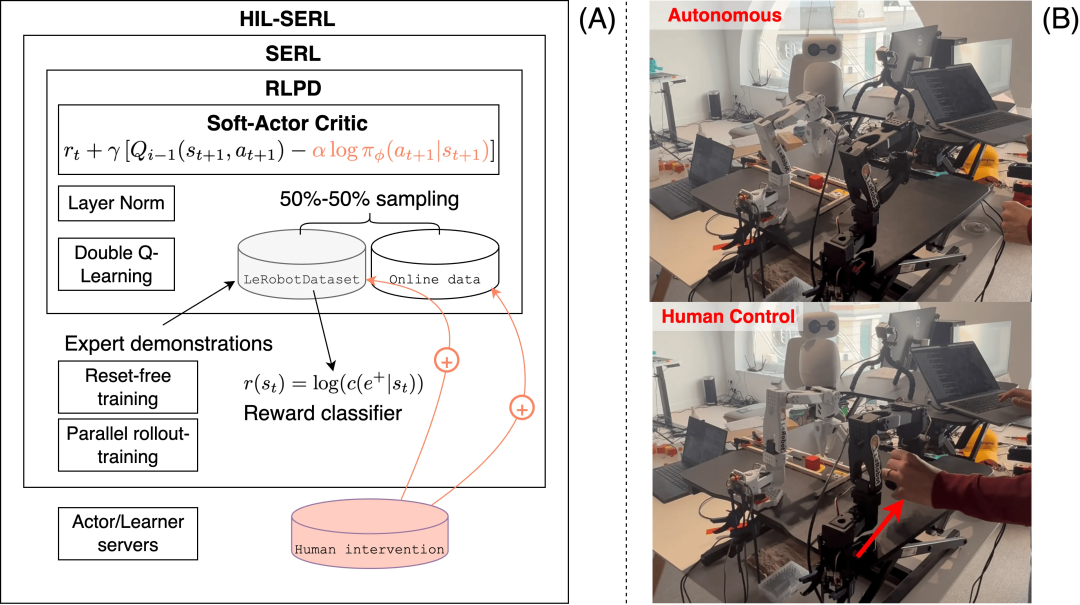
(A) HIL-SERL 通过借鉴 SAC、RLPD 和 SERL 的最新进展,实现了在现实世界中对高性能 RL 智能体的训练。 (B) 在真实 SO-100 上进行 HIL-SERL 训练过程中的人类干预示例。
与强化学习不同,模仿学习为机器人提供了一条更为直接的学习路径,即通过「行为克隆」来复现专家操作。教程指出,模仿学习的核心优势在于它完全规避了复杂的奖励函数设计,并通过直接学习专家数据来确保训练过程的安全性。
然而,简单的行为克隆也面临两大挑战:一是「复合误差」,即微小的预测偏差会在序贯决策中被放大;二是难以处理专家演示中的「多模态」行为,例如,同一个任务目标可以通过多种不同的有效动作序列完成。
教程详细介绍了一系列基于生成模型的先进模仿学习方法。
例如,Action Chunking with Transformers (ACT) 和 Diffusion Policy 等技术,通过学习专家行为的潜在分布而非单一的映射函数,来有效建模多模态数据。
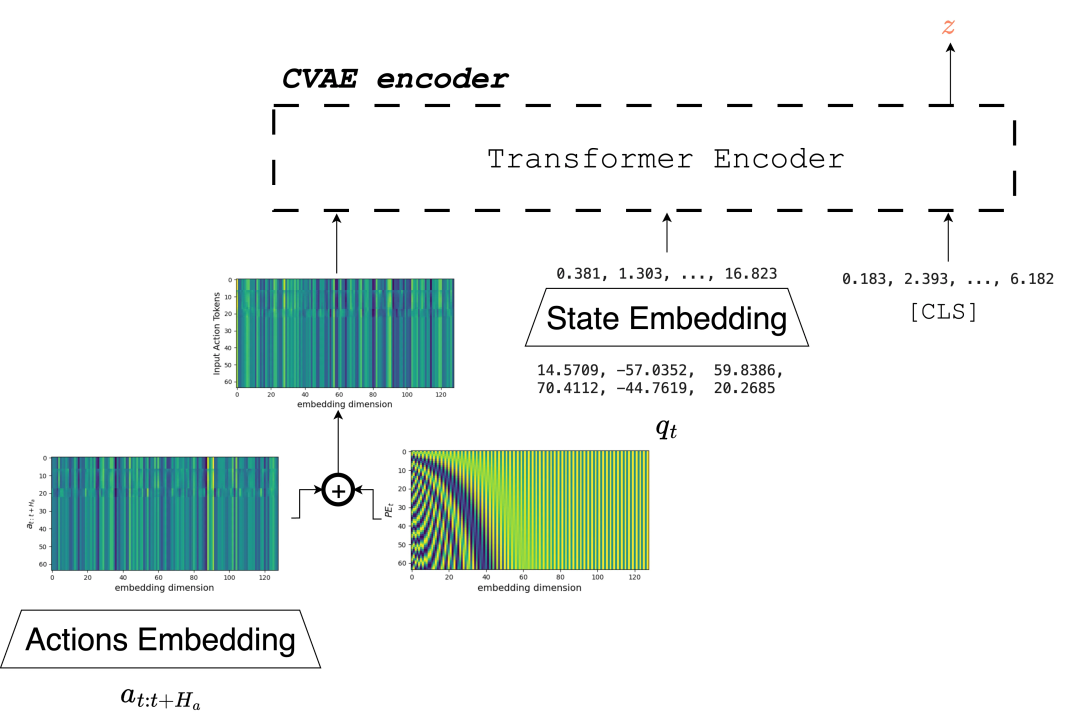
ACT 中使用的 CVAE 编码器。输入的动作块首先被嵌入并与位置嵌入聚合,然后与嵌入的本体感知信息以及一个用于聚合输入层信息并预测风格变量 z 的可学习 [CLS] 标记一起处理。该编码器仅用于训练解码器,在推理阶段完全被忽略。
其中,Diffusion Policy 利用扩散模型生成动作序列,在模拟和真实世界的多种任务中表现出色,仅需 50-150 个演示(约 15-60 分钟的遥操作数据)即可完成训练。
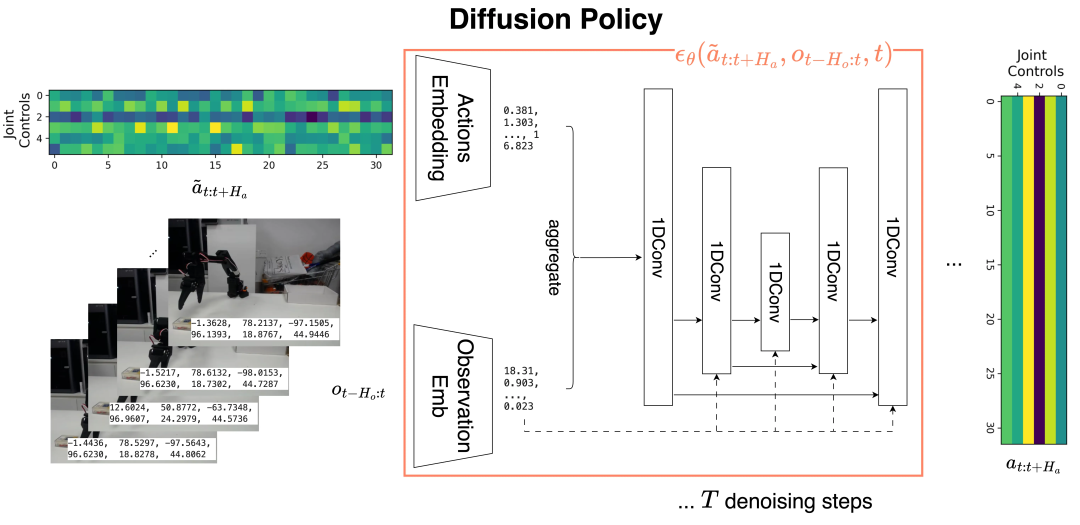
Diffusion Policy 架构。将 H_o 个历史观测堆叠作为外部条件,用于对一组 H_a 个动作进行去噪。条件注入在 U-Net 块的每一层都执行。Diffusion Policy 仅需 T = 10 步去噪即可获得完整的动作块。
此外,教程还探讨了如何通过「异步推理」优化模型部署,有效提升机器人在资源受限环境下的响应速度和计算效率。
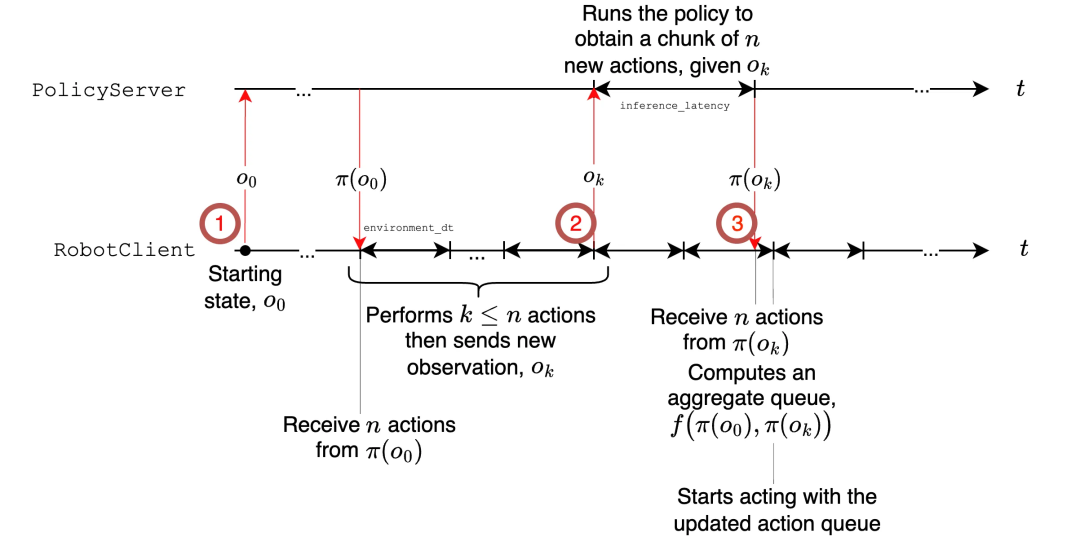
异步推理。异步推理栈示意图。注意,策略可以在远程服务器上运行,可能配备 GPU。
在模仿学习的基础上,教程进一步展望了机器人技术的未来:构建能够跨任务、跨设备的「通用机器人策略」,即机器人领域的「基础模型」。
这一方向的兴起源于大规模开放机器人数据集(如 Open X-Embodiment)的出现,以及强大的视觉 - 语言模型(VLM)的发展。
教程重点介绍了两种前沿的 VLA 模型:π₀ 和 SmolVLA。这两者均采用了混合专家(MoE)架构,将预训练的 VLM 作为强大的「感知主干」,负责理解视觉和语言指令,再结合一个专门的「动作专家」来生成精确的机器人控制指令。
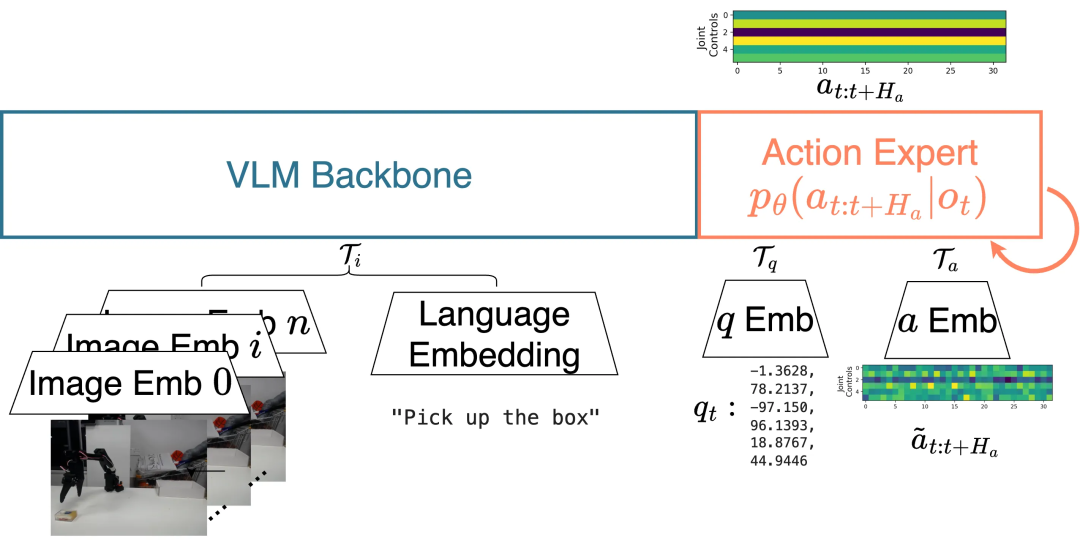
π0 架构。视觉与语言 token 被送入 VLM 主干,该主干被禁止关注机器人本体感知状态与动作 token;后者转而输入架构内一个更小的权重子集,称为「动作专家」。该架构在 1000 万 + 条轨迹上以 Flow Matching 训练,数据来自封闭与公开数据集的混合。
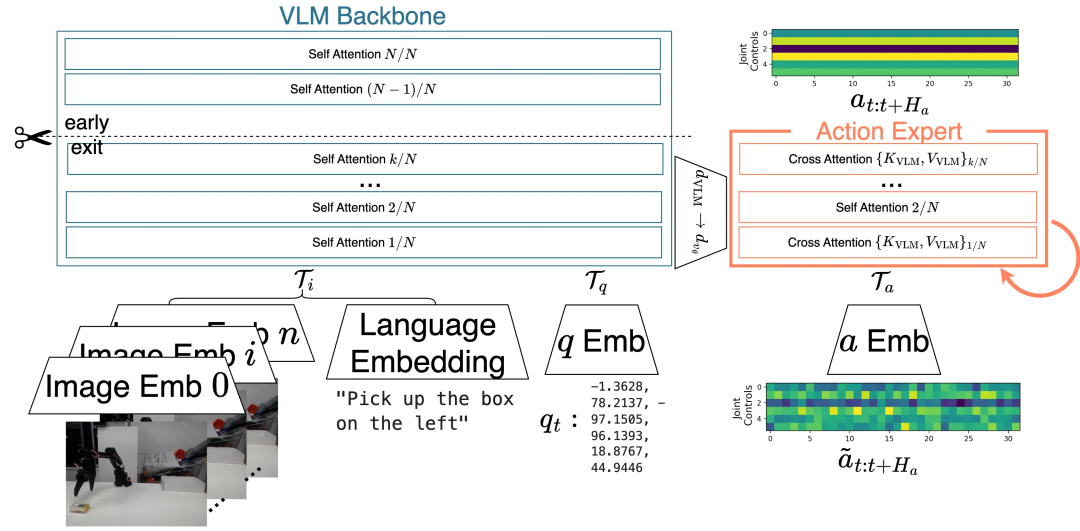
SmolVLA 架构如 @shukorSmolVLAVisionLanguageActionModel2025 所示。它是一个紧凑的 MoE 模型,通过流匹配训练对动作块进行去噪。视觉与语言令牌输入 VLM 主干,通过注意力机制与本体感知及动作令牌共享信息。注意力专家在 VLM 主干视觉特征上交替使用 SA 与 CA 层进一步条件化。SmolVLA 跳过部分计算并压缩视觉令牌,内存占用仅为 π₀ 的 1/7(4.5 亿参数 vs. π₀ 的 33 亿)。
更多细节内容,代码示例等请参阅教程原文。
文章来自于微信公众号 “机器之心”,作者 “机器之心”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
